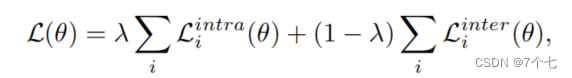0.文献地址
2017 Localizing Moments in Video with Natural Language
1.摘要
- 提出了Moment Context Network(MCN)有效地定位视频中的自然语言查询
- 又提出了唯一识别对应时刻的文本描述的数据集DiDeMo
2.引言
作者提出了问题如果查询特定的时间段,例如当女孩摔倒后又开始有弹性地跳起来时,仅仅通过动作、对象或属性关键字来引用时刻可能不能唯一地标识它。也就是说时刻并不是由单个对象或活动来定义的,而是可以由与其他操作相关的特定操作发生的时间和方式来定义。
于是作者提出了用自然语言来定位视频中特定的时刻。因此,我们提出了时刻上下文网络(MCN),它包括一个全局视频特征来提供时间上下文和一个时间端点特征来指示视频中何时发生一个时刻。
3.模型结构
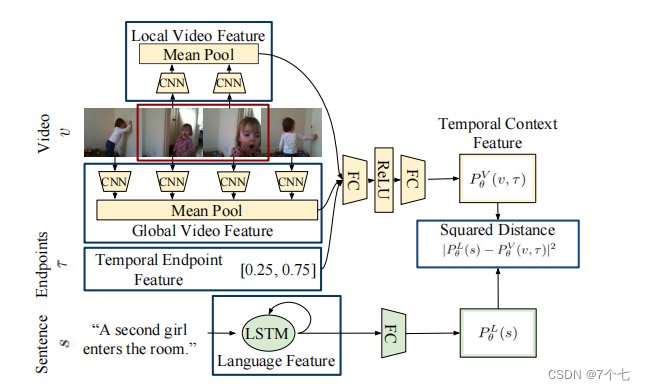
3.1Visual Temporal Context Features
-
local video features
-
global video features
-
temporal endpoint features
首先使用深度卷积网络为每个视频帧提取高级视频特征,然后在特定的时间跨度内对池视频特征进行平均。局部特征是通过在特定时刻内汇集特征来构建的,而全局特征是通过对视频中的所有帧进行平均来构建的。
当视频中出现一个时刻时,可以象征一个时刻是否与一个特定的查询相匹配。为了对这个时间信息进行编码,我们包含了时间端点特征,它表示一个候选矩的起始点和端点(归一化到区间[0,1])
local video features,global video features,temporal endpoint features三合一
提取RGB帧(记为Pθ V)和光流帧(记为Pθ F)的时间上下文特征时,可以学习单独的权值。
3.2Language Features
用LSTM
3.3模态融合
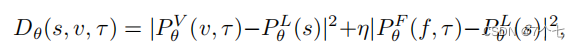
3.4Rank损失函数
- intra-loss:在同一个视频内不同的时间节点进行对比
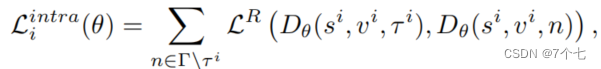
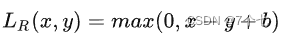
τ_i表示正样本,也就是与查询相关的视频片段。而Γ\τ_i,表示所有的负样本集合,也就是不相关的视频片段 - inter-loss:在不同的视频同一个时间节点进行对比
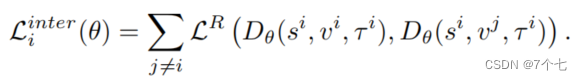
intra-loss和inter-loss组合: