LangChain是一个基于大语言模型(如ChatGPT)用于构建端到端语言模型应用的 Python 框架。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,以便在不同的应用程序中使用。LangChain可以让LLM来学习您自己的结构化或者非结构化的数据,这些数据包括pdf,text,youtbe,database等,这样就可以很方便的打造一个个性化的智能AI机器人。下面是LangChain可以学习的数据的种类和类型:
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
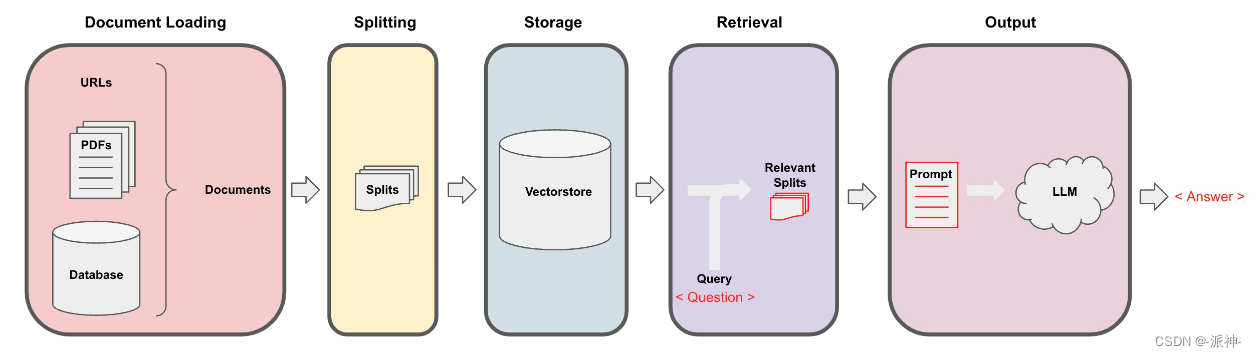
Document Loading
在检索增强生成(Retrieval augmented generation,RAG)中,Langchain可以让LLM检索外部数据集中内容:

要实现对外部数据的检索,首先需要对各种外部数据的加载且对于不同类型的数据时Langchain提供了不同类型的数据加载器, 不过在实现加载外部数据之前,首先我们还是要做一些基础性工作,比如设置openai的api key:
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']PDFs
下面我们让langchain加载吴恩达老师的著名课程《机器学习》的课程讲义的pdf文档:
#! pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()下面我们查看一下文档的页数:
len(pages)
接下来我们查看该文档第一页的部分内容,由于文本内容太长,所以我们只展示前500个字符的内容:
page = pages[0]
print(page.page_content[0:500])
与实际内容做比对:

下面查看该页的元数据
page.metadata
YouTube
langchain的另外一个重要的功能就是它可以读取youtube视频里的内容,langchain可以读取youtube视频内的音频数据,并将其转换成文本:
# ! pip install yt_dlp
# ! pip install pydub
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
#视频链接
url="https://www.youtube.com/shorts/13c99EsNt4M"
#视频保存路径
save_dir="docs/youtube/"
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir),
OpenAIWhisperParser()
)
docs = loader.load()
上面我们已经完成了对youtube视频的加载,并且将其中的音频转换成了文本,下面我们查看一下转换好的文本:
docs[0].page_content[0:500]
URLs
除了从youtube中加载数据,Langchain还可以加载web网页的内容,下面我们看一个例子:
from langchain.document_loaders import WebBaseLoader
url="https://mp.weixin.qq.com/s/RhzHa1oMd0WHk0JamdfVRA"
#创建webLoader
loader = WebBaseLoader(url)
#获取文档
docs = loader.load()
#查看文档内容
text=docs[0].page_content
text=text.replace("\n",'')
print(text)
我们对照一下实际网页的内容:

文档分割(Document Splitting)
前面我们简单介绍了通过Langchain来加载和读取各种类型外部数据的方法,当数据被加载以后,接下来就来到了Splitting, 由于外部数据的数据量可能比较大,如pdf、text文档,youtube视频等产生的文档的数量或者说体积比较大,因此需要对外部数据文档进行分割(Splitting),文档被分割成块(chunks)后才能保存到向量数据库中:
Langchain提供了很多文本切割的工具,其中langchain默认使用RecursiveCharacterTextSplitter:
- CharacterTextSplitter():按字符来分割文本。
- MarkdownHeaderTextSplitter():基于指定的标题来分割markdown 文件。
- TokenTextSplitter():按token来分割文本。
- SentenceTransformersTokenTextSplitter() : 按token来分割文本
- RecursiveCharacterTextSplitter():按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- Language() - 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter():使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter() - 使用 Spacy按句子的切割文本。
RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter是Langchain的默认文本分割器,它按不同的字符递归地分割文档,同时要兼顾被分割文本的长度和重叠字符,RecursiveCharacterTextSplitter默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记,下面对RecursiveCharacterTextSplitter()方法的参数说明如下:
- chunk_size:被切割的字符串的最大长度
- chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
这里需要说明一下chunk_overlap参数,为了保持字符串中语义的连贯性,就需要保持前后两段被分割的字符串有部分重叠,这就好比老师在上课的时候先回顾一下上一节课的内容,这样可以做到温故而知新,这就是设置重叠字符川的意义,下面我们看个例子:
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=26, #块长度
chunk_overlap=4 #重叠字符串长度
)
text1 = 'abcdefghijklmnopqrstuvwxyz'
r_splitter.split_text(text1)
这里我们使用RecursiveCharacterTextSplitter方法来切割字符串a-z,由于我们设置chunk_size的值为26,也就是每26个字符会被切块,但是因为a到z的字符串正好是26个字符,所以没有被切开下面我们在26个字母的后面再加上a到g试一下:
text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
r_splitter.split_text(text2)
这里我们看到由于我们在a到z的后面又增加了a到g 8个字符所以现在字符串总长变成了34,但是RecursiveCharacterTextSpliterr还是会在每26个字符串的位置进行切割,所以原字符串被切割成了两段,同时由于我们还设置了chunk_overlap参数为4,所以前一个字符串的最后4个字符串会被加到后一个字符串的开头,这样做的目的是为了增强语义的连贯性。下面我们再看一个例子,这次我们在原来a到z的字符串中间,在字母和字母中间加入空格,所以字符串长度由原来的26变成了51:
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
r_splitter.split_text(text3)![]()
这里我们发现字符串被切割成了3段,前2段每段都只有25个字母,这是因为前两段字符串其实还有一个空格,我们设置的chunk_size参数是26,所以它只会在每26个字符的位置进行切割,所以当第26个字符是空格的时候,该空格会被扔掉,不会被保留下来,所以造成前两个字符串都只有25个字母,但是在计算重叠字符时改空格仍然会保留下来,这就造成后一个字符串的开头包含了前一个字符串的最后四个字符(包括空格在内)。
CharacterTextSplitter
上面我们解释了RecursiveCharacterTextSplitter文档切割器,它是Langchain默认的文档切割器,接下来我们还可以来尝试另外一款文档切割器CharacterTextSplitter,这是一款比较的简单的按字符数来切割文档的文档切割组件,下面我们看一个例子,在下面的例子中我们任然设置了chunk_size为26和chunk_overlap为4这两个参数:
c_splitter = CharacterTextSplitter(
chunk_size=26,
chunk_overlap=4
)
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
c_splitter.split_text(text3)![]()
我们看到,默认情况下CharacterTextSplitter是忽略空格的,也就是说在默认情况下CharacterTextSplitter不会把空格当初字符,所以没有切割原来的字符串,任然输出包含空格在内的26个字母。我们再看下面的例子:
c_splitter = CharacterTextSplitter(
chunk_size=26,
chunk_overlap=4,
separator = ' '
)
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
c_splitter.split_text(text3)
当我们在CharacterTextSplitter的参数中增加一个separator = ' '的参数,此时空格将不会被忽略,空格会被当成字符来对待,所以原字符串最后被切割成个3段,这类似于RecursiveCharacterTextSplitter。
递归分割细节
前面我们介绍了RecursiveCharacterTextSplitter,它是Langchain默认使用的文本切割器,也是Langchain推荐使用的文本切割器,它可以根据特定的标记,如双换行符(\n\n),单换行符(\n)等来分割文本,因此它可以将完整的语义保留在一个段落中,同时设置了重叠字符确保了语义的连贯性。下面我们来看一个例子,在这段文本中存在一个双换行符\n\n:
some_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""下面我们看一下文本的总长度:
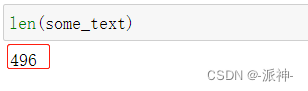
该段文本的中长度为496个字符。下面我们分别用CharacterTextSplitter和RecursiveCharacterTextSplitter来切割该段文本:
c_splitter = CharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap=0,
separators=["\n\n", "\n", " ", ""] #默认
)这里需要说明的是CharacterTextSplitter默认的字分割符是双换行符即\n\n, 这里我们将分隔符改成了空格,而RecursiveCharacterTextSplitter的默认字分割符是一个列表即["\n\n", "\n", " ", ""],因此它会用分割符列表中从左至右的顺序的分割符依次去搜索目标文档中的分割符,然后再分割文档,比如先搜索目标文档中的双换行符\n\n,如果存在,则切割文档,然后依次搜索单分隔符\n,空格等,下面我们首先尝试用CharacterTextSplitter来切割文档,这里我们CharacterTextSplitter的chunk_overlap值设置为0,也就是不设置重叠字符的意思:
c_splitter.split_text(some_text) 
这里我们看到,CharacterTextSplitter按字符串长度将切割成了2段,因为我们设置了separator 为空格,所以它一定是在空格处来切割文本,并且长度要尽量满足我们设置的chunk_size=450的长度,所以第一段的长度应该是<=450的最大值:
ds=c_splitter.split_text(some_text)
len(ds[0])![]()
这里我们看到第一段的长度是448,满足不大于450的要求。下面我们用RecursiveCharacterTextSplitter来切割文本:
r_splitter.split_text(some_text) 这里我们看到RecursiveCharacterTextSplitter也将文本分割成了两段,只不过它是在原文本中的双换行符处切割的,这是因为RecursiveCharacterTextSplitter的分割符是一个列表,其中的双换行符\n\n优先级最大,因此凡事在文本中出现双换行符的位置都会被分割,并且被分割的文本长度不能大于chunk_size的设定值。接下来我们在RecursiveCharacterTextSplitter的分隔符列表中增加一个句号作为分隔符,我们再来看看分割的结果。
这里我们看到RecursiveCharacterTextSplitter也将文本分割成了两段,只不过它是在原文本中的双换行符处切割的,这是因为RecursiveCharacterTextSplitter的分割符是一个列表,其中的双换行符\n\n优先级最大,因此凡事在文本中出现双换行符的位置都会被分割,并且被分割的文本长度不能大于chunk_size的设定值。接下来我们在RecursiveCharacterTextSplitter的分隔符列表中增加一个句号作为分隔符,我们再来看看分割的结果。
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "\. ", " ", ""]
)
r_splitter.split_text(some_text) 
这里我们看到文本被分割成了5段,并且是按双换行符\n\n和句号这两个分割符来分割的,只是句号出现在了各段的句首位置,这明显是错误的,句号应该是出现在上一段的句尾才对。下面我们调整一下分隔符列表中的正则表达式:
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
r_splitter.split_text(some_text)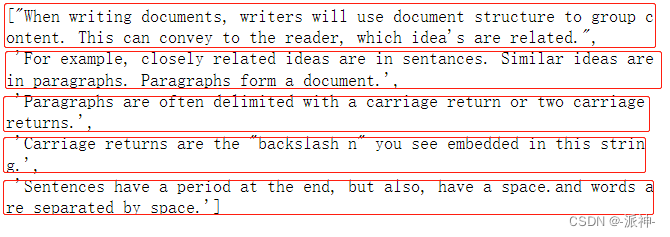
我们在分隔符列表中增加了正则表达式"(?<=\. )",它的意思是保证句号前面一定会存在字符,这样就避免了句号被保留在句首的情况。
接下来我们使用一个现实的pdf文件来实际测试一下文档分割功能:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()这里我们使用langchain的PyPDFLoader文档加载器来加载pdf文件,它是按页来加载pdf文件的,也就是说如果原来pdf文件中一共有10页,那么在执行load()后生成的pages也包含了这10页:
len(pages)![]()
这里我们看到原pdf文档里一共有22页,我们加载好以后生成的pages对象的长度也是22。下面我们用CharacterTextSplitter来分割这个文档并设置如下参数:
- separator="\n" : 设置单换行符作为分隔符
- chunk_size=1000:设置块的大小为1000个字符
- chunk_overlap=150:设置重叠字符为150个字符
- length_function=len :长度函数设置为python的len函数
from langchain.text_splitter import CharacterTextSplitter
#创建分割器
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=150,
length_function=len
)
#分割文档
docs = text_splitter.split_documents(pages)下面我们看看分割好的文档docs包含多少段文档:
len(docs)![]()
我们看到原来22页的pdf文档经过分割后变成了77段的文档。
Token 分割
除了按字符分割以为,Langchain还提供了按token来分割文本的方法,所谓token可以理解为含义简单的最小词语单位,这里一个token大约由4个字符组成。因为大型语言模型(LLM),通常是以token的数量作为其计量(或收费)的依据。所以采用token分割也有助于我们在使用像chatGPT这样的LLM的同时更好的控制成本。下面我们看一个例子:
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)![]()
在使用token分割文本时英语中的一些非常用单词如这里的bazzyfoo会被分割成多个token,如这里将bazzyfoo分割成了4个token,它们分别是b, az, zy, foo。再看一个例子:
text2="what can I do for you ?"
text_splitter.split_text(text2) ![]()
基本上常用的英语单词都会被分割成单独的token.下面我们将之前的pdf文档进行token分割:
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
len(docs)
这里我们将chunk_size设置为10,也就是说每一段里最多只保留10个token, 最后docs中包含了1557个chunk,且每个chunk中的token数量<=10. 下面我们查看一下docs中的内容:
docs[0]
docs[100] 这里我们看到docs里面的内容都很短,都不超过10个token。
这里我们看到docs里面的内容都很短,都不超过10个token。
上下文感知分割(Context aware splitting)
对文本分割的目的旨在将具有共同语义的上下文的文本放在一起。文本分割通常使用句子或其他分隔符将相关文本保持在一起,但许多文档(例如 Markdown)具有可以在拆分中显式的结构(如标题)。我们可以使用 MarkdownHeaderTextSplitter 来保留块中的标题元数据:
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = """# Title\n\n \
## Chapter 1\n\n \
Hi this is Jim\n\n Hi this is Joe\n\n \
### Section \n\n \
Hi this is Lance \n\n
## Chapter 2\n\n \
Hi this is Molly"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)这里我们设置了抽取指定标题(如标题1, 标题2,标题3) ,且同一标题内的的数据他们被放置在同一个块内.
md_header_splits[0]
md_header_splits[1] 
这里我们可以看到MarkdownHeaderTextSplitter将同一标题下的文本放在了同一个块(chunk)中,而文本对应的标题信息则被存储在块的元数据中了。
总结
今天我们学习了文本的加载与分割,Langchain提供了丰富的外部数据加载器,这些外部数据可以是结构化的,也可以是非结构化的,其中我们还介绍了从网页和youtube视频中加载文本的方法,这个挺有意思的,大家可以尝试一下,由于外部数据量可能比较大,如pdf, text文档等,因此当我们加载了外部数据以后,我们还需要对数据进行分割处理,我们介绍了几种文本分割的方法,其中有按字符分割的CharacterTextSplitter分割器,和递归分割的RecursiveCharacterTextSplitter分割器。以及token分割器和markdown分割器,这里langchain默认使用RecursiveCharacterTextSplitter分割器,其中RecursiveCharacterTextSplitter默认使用一个分割符列表来分割数据,同时还要兼顾块的大小和重叠字符。
参考资料
PDF | 🦜️🔗 Langchain
Markdown | 🦜️🔗 Langchain
Recursively split by character | 🦜️🔗 Langchain
Split by character | 🦜️🔗 Langchain
Split by tokens | 🦜️🔗 Langchain
MarkdownHeaderTextSplitter | 🦜️🔗 Langchain



![[書籍]思考的框架](https://img-blog.csdnimg.cn/f760243b169842d582d46b02420fa09c.png)