目录
边读边存
优化成一维数组——倒序没用了?

从上往下存,最大值存在最后一行,最后遍历最后一行得到最大值的写法
边读边存
边读边存,可以有效降低时间复杂度
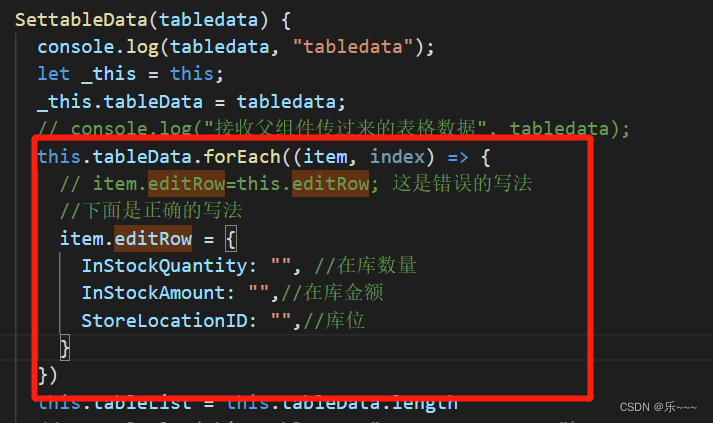
#include<iostream>
using namespace std;
int dp[1005][1005] = { 0 };
//dp[i][j]表示前面的路径(包括dp[i][j]点本身)能取得的最大值
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
//由于题目数据量较大,上面两行代码可以加速35%左右
int r, j = 0, cnt = 2, MAX = -1;
cin >> r;
cin >> dp[1][1];
//下面的内层循环比较特殊,因为树每往下一层,元素都递增一个
//所以用cnt来记录每层元素的个数
for (int i = 2; i <= r; ++i)
{
while (++j <= cnt)
{
cin >> dp[i][j];
dp[i][j] += max(dp[i - 1][j], dp[i - 1][j - 1]);
//由于是二叉树,因此每个节点只需判断它前面两个结点的值哪个最大即可
//因为是从dp[1][1]开始存入数据,所以i-1和j-1均不会越界
}
++cnt;
j = 0;
}
//遍历最后一行判断谁是最大值
for (int i = 1; i <= r; ++i)
{
MAX = max(MAX, dp[r][i]);
}
cout << MAX;
return 0;
}优化成一维数组——倒序没用了?
在上一篇文章(【洛谷】采药(01背包问题))将二维数组优化成一维数组的过程中,内层循环我们是采用倒序的方式计算dp[ i ][ j ],这是因为如果正序存储dp[ i ][ j ],就会覆盖掉dp[ i-1 ][ j ],这样就无法通过状态方程计算dp[ i ][ j ]。在这道题中同样要避免覆盖掉dp[ i-1 ][ j ],不过为了保证时间复杂度,必须保留边读边存的做法。
接下来尝试一下倒序的方式在这题中是否适用(这么问了肯定不适用,正确答案请移步最后)
int r, j = 3, cnt = 2, MAX = -1;
cin >> r;
cin >> dp[1];
for (int i = 2; i <= r; ++i)
{
while (--j >= 1)
{
cin >> dp[j];
dp[j] += max(dp[j], dp[j - 1]);
}
++cnt;
j = cnt;
}首先要注意一点,我们是逆序输入,也就是说如果原来输入 3,10,9,那么在数组的里存放的顺序应该是9,10,3(假设单纯的存进去,不进行运算)
那么输入的树应该是镜像的,比如
7
3 8
8 1 0
2 7 4 4
会变成:
7
8 3
0 1 8
4 4 7 2
这两棵树在这道题中其实没有区别,因此不影响。
然后我们输入下面这组数据
4
7
3 8
8 1 0
2 7 4 4
当输入到
4
7
3
时,树的结构如下:

接着输入8之后,以下两种情况,你觉得是哪一种?

是下面的那种。看代码中下面这部分
在cin>>dp[1]的时候,已经把dp[1]覆盖成8了,因此公式变成了8+=max(8,0),这样一来答案就错了。不过到这一步,怎么改错也很明显了,既然不想被覆盖,那就引入一个变量来保存一下原本的dp[ j ]就行了嘛。
#include<iostream>
using namespace std;
int dp[1005] = { 0 };
int main()
{
ios::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
int r, j = 3, cnt = 2, MAX = -1, x = 0;
cin >> r;
cin >> dp[1];
for (int i = 2; i <= r; ++i)
{
while (--j >= 1)
{
cin >> x;
x += max(dp[j], dp[j - 1]);
dp[j] = x;
}
++cnt;
j = cnt + 1;
}
for (int i = 1; i <= r; ++i)
{
MAX = max(MAX, dp[i]);
}
cout << MAX;
return 0;
}于是空间成功从4MB多降到了800KB
当然,还可以从下往上计算,最后的结果保存在dp[1][1],这样减少了最后遍历整个数组的过程,但是输入的时候没法实现边读边存,最终时间复杂度没有差别。这里引用一下原题下方大神linlin1024的题解