2023无监督摘要顶会论文合集
- 写在最前面
- ACL-2023
- Aspect-aware Unsupervised Extractive Opinion Summarization 面向的无监督意见摘要(没找到)
- Unsupervised Extractive Summarization of Emotion Triggers *情绪触发(原因)的 *无监督 *抽取式 摘要(有代码)
- 论文地址和代码
- 任务
- 动机
- 数据集COVIDET-EXT
- 步骤
- 公式表示
- 指标表现
- Emotion-agnostic基线。
- Emotion-specific基线。
- (插一个上篇论文的同团队姊妹篇EMNLP-2022)Why Do You Feel This Way? Summarizing Triggers of Emotions in Social Media Posts你为什么会有这种感觉?(生成式)总结社交媒体帖子中的情绪触发(原因)
- 论文地址和数据集、代码
- 动机
- 数据集
- 方法
- 结果
- Unsupervised Summarization Re-ranking 无监督总结重新排名
- 代码
- 背景
- 主要挑战
- Disentangling Text Representation With Counter-Template For Unsupervised Opinion Summarization 基于反模板解纠缠文本表示 用于无监督意见摘要(没找到)
- ACL-2022
- Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization 从搜索中学习非自回归模型 用于无监督的句子摘要(有代码)
- 出发点
- 优点
- 方法
- 指标表现
- 代码
- ACL-2021
- Unsupervised Extractive Summarization-Based Representations for Accurate and Explainable Collaborative Filtering
- Improving Unsupervised Extractive Summarization with Facet-Aware Modeling
- EMNLP-2022
- Unsupervised Opinion Summarisation in the Wasserstein Space
- Unsupervised Entity Linking with Guided Summarization and Multiple-Choice Selection
- Learning From the Source Document: Unsupervised Abstractive Summarization. 4194-4205
- Unsupervised Multi-Granularity Summarization. 4980-4995
- NeurIPS-2021
- WWW-2023
- AAAI-2021
- Unsupervised Opinion Summarization with Content Planning 基于内容规划的无监督观点摘要(有代码)
- 数据集
- 摘要生成
- 知识点补充:hinge loss
- 训练
- 评估
- 2
- Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes 面向面对面对话的无监督抽象式对话摘要
- Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders 基于主题排序和上下文感知自动编码器的聊天日志无监督摘要
- Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes 面向面对面对话的无监督抽象式对话摘要
- 其他
- 判断抽取式和生成式摘要
- 主要方法
- 无监督的抽取式摘要。
- 评估
写在最前面
和老师一起确认了大的研究路线,目前学习【无监督摘要】相关领域的论文和代码,以期能用到我们的论文研究中
这篇博文梳理各篇文章的主要脉络,初步标注后期深入学习的思路和板块
问题+动机+解决问题的方法
前言:查找了近三年顶刊中【文本摘要】的所有论文,并根据论文名字 & 摘要进行了初步归类,现在看看无监督的论文,留个初步印象
(dblp中好像不能二次检索?不好分期刊查找论文)
(老师带着花两个下午 整理的相关文献,get一个找参考文献的新方法O(∩_∩)O~)
ACL-2023
Aspect-aware Unsupervised Extractive Opinion Summarization 面向的无监督意见摘要(没找到)
Unsupervised Extractive Summarization of Emotion Triggers *情绪触发(原因)的 *无监督 *抽取式 摘要(有代码)
论文地址和代码
https://arxiv.org/pdf/2306.01444v1.pdf
https:/lgithub.com/tsosea2/CovidET-EXT
任务
了解在大规模危机中(在COVID-19危机的背景下)触发情绪的原因,作用:
1、可以为表达情绪提供基础
2、进而提高对正在发生的灾难的理解。
开发新的无监督学习模型,可以联合检测情绪并总结其触发因素(对触发情绪的原因进行总结,形成摘要)


动机
最近的方法(Zhan等人,2022)训练监督模型,通过抽象总结来检测情绪并解释情绪触发因素(事件和评价)。
然而,获得及时和定性的抽象摘要是昂贵和极其耗时,需要经过高度训练的专家注释者。在时间敏感、利害攸关的情况下,这可能会阻碍必要的响应。
相反,我们追求从文本中提取触发因素的无监督系统。
数据集COVIDET-EXT
COVIDET-EXT:
1、基于Zhan等人(2022)的COVIDET
2、用与每个抽象摘要相对应的手动注释的提取摘要来增强。
描述:
1、包含1883篇关于COVID-19大流行的Reddit帖子的数据集,用7种细粒度的情绪(来自COVIDET)及其相应的提取触发器手动注释(图1)。
2、对于帖子中存在的每一种情绪,突出显示总结情绪触发器的句子,总共产生6,741个提取摘要。
COVIDET-EXT提供了一个理想的测试平台,以促进提取(监督或无监督)技术的发展,用于危机背景下的情绪检测和触发总结任务。
对数据集的定性分析表明,标注者之间具有良好的一致性,后续人工验证标注也显示出很高的正确性。
步骤
1、引入COVIDET-EXT数据集
2、开发了新的无监督学习模型,可以联合检测情绪并总结其触发因素
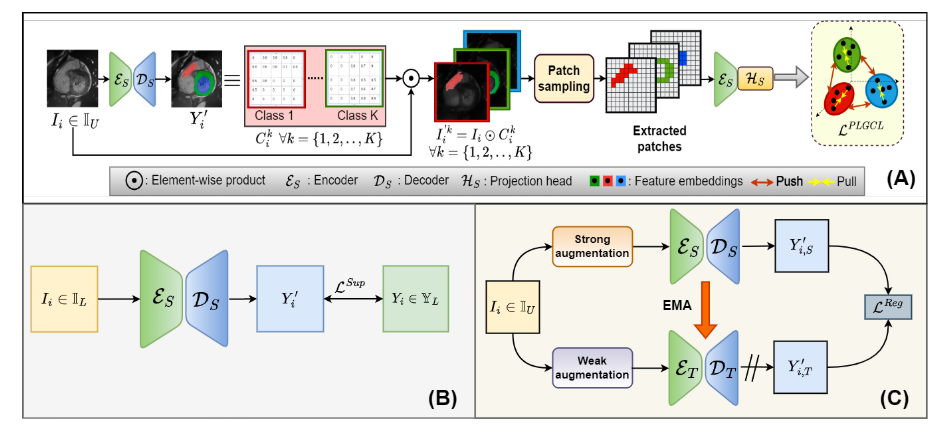
我们的最佳方法名为情绪感知的Pagerank,将来自外部来源的情绪信息与语言理解模块相结合
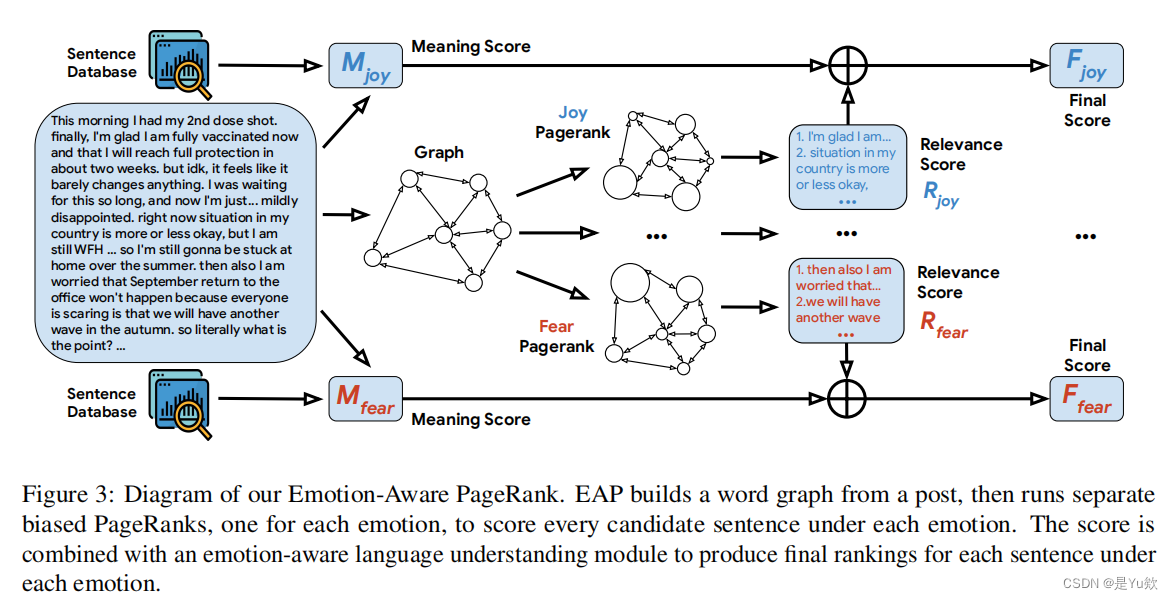
图3:我们的情绪感知PageRank图表。EAP从一篇文章中构建一个词图,然后运行独立的有偏见的pagerank,每种情绪一个,对每种情绪下的每个候选句子进行评分。该分数与一个情感感知语言理解模块相结合,为每种情感下的每个句子产生最终排名。
EAP将单词而不是句子视为图中的节点,并使用多个独立的有偏见的PageRank (Haveli-wala, 2003)为每个单词计算特定于情感的分数,该分数与句子相似度模块相结合,产生每个情感的一个句子分数,表明每个情感下句子的显著性。
公式表示


指标表现
Emotion-agnostic基线。
两个标准的启发式基线,即:
1)提取帖子中的第一句话(1次发送)
2)提取帖子中的前三句话(3次发送)。
设计了三种基于图中心性度量的方法:
3)PacSum (Zheng and Lapata,2019),
4) PreSum (Liu and Lapata, 2019)和word-level
5) TextRank (Mihalcea and Tarau,2004)。
请注意,这些方法是情感无关的,生成的摘要对于不同的情感将是相同的。
Emotion-specific基线。
首先采用了两种基于词汇的方法:
6)EmoLex——使用EmoLex(穆罕默德和Turney, 2013)词汇来识别表明情绪表达的词汇线索。
如果一个句子包含一个与情感e相关的单词,我们认为这个句子表达了eoe的最终摘要包含了表达e的所有句子。
7)EmoIntensity——利用NRC情感强度词典(穆罕默德,2018)来建立一个更细粒度的方法来识别一个句子是否表达了情感。
对于每个句子和情感,我们计算平均情感词强度,并将其与预定义的阈值t进行比较。如果e的平均强度高于t,我们将句子标记为e。t是我们根据验证集性能选择的可调参数。
结果:优于强大的基线。
(插一个上篇论文的同团队姊妹篇EMNLP-2022)Why Do You Feel This Way? Summarizing Triggers of Emotions in Social Media Posts你为什么会有这种感觉?(生成式)总结社交媒体帖子中的情绪触发(原因)
论文地址和数据集、代码
https://arxiv.org/pdf/2210.12531.pdf
一二作互换,三四作互换
数据集COVIDET和代码:
https://github.com/honglizhan/CovidET。
动机
coVID-19大流行等危机持续威胁着我们的世界,并以不同的方式影响着世界各地数十亿人的情感。
了解导致人们情绪的触发因素至关重要。
社交媒体上的帖子可以是这种分析的一个很好的来源,但这些文本往往包含多种情绪,触发器分散在多个句子中。
该文采用了一个新颖的视角,即情绪检测与触发词摘要,旨在检测文本中的感知情感,并总结触发每种情感的事件及其评价。
数据集
CoVIDET的时间跨度为2021年6月至2022年1月,记录了疫情期间发生的各种重大事件以及人们对这些事件的情感评价。
本文提出CovIDET (Covid19期间的情绪及其触发原因),一个与COVID-19相关的1883英语Reddit帖子的数据集,其中包含手动注释的
①感知情绪,每篇文章都被标注了7个细粒度的情感标签
②帖子中描述的(情绪)触发器的抽象摘要。对于每种情者,标注者都提供了一个简洁、抽象的摘要,描述了该情绪的触发因素。
与之前只考虑句子级别文本(Soseaand Caragea,2020;Demszky et al.,2020)或(短)推文(Sosea et al.,2022; Abdul-Mageed and Ungar,2017)的情感研究相比,CovIDET具有挑战性,因为它包含明显更长的文本。

Figure 1: 一个来自COVIDET的例子,识别了感知
到的情绪并总结了它们的触发因素。
方法
开发了强大的基线来联合检测情绪并总结情绪触发器。
采用了单独的情绪检测和触发摘要模型,以及设计的联合模型,以同时检测情绪和生成触发摘要。
COvIDET具有各种独特的特性,从它的长序列和宝贵的上下文到任务本身的性质。
对为情感触发摘要量身定制的触发摘要的人工评估
表明,所提出模型在捕捉帖子的潜在触发因素方面是有效的
开发了强大的基线来联合检测情绪并总结情绪触发器。
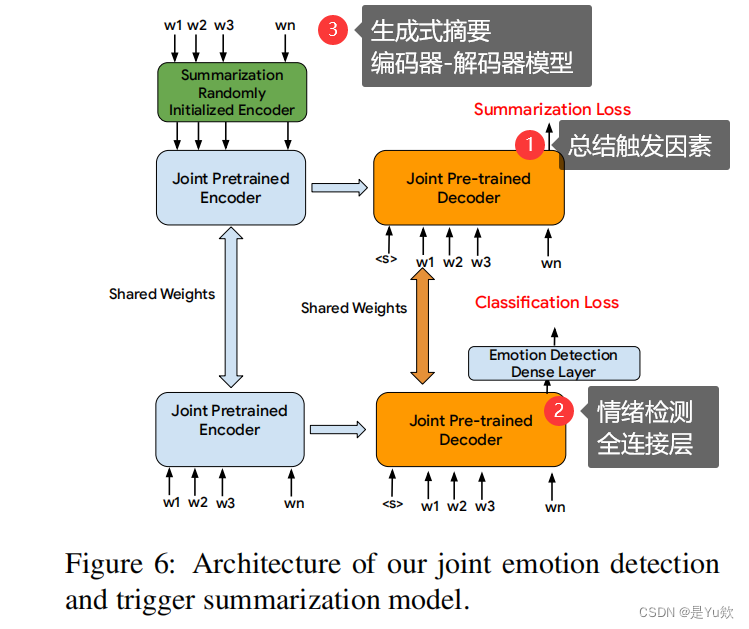
Figure 6: 情感检测与触发摘要联合模型的架构。
结果
分析表明,CoVIDET在特定情绪摘要和长社交媒体帖子中的多情绪检测方面提出了新的挑战。
因此,与我们的方法相比,通用情绪检测或摘要模型在性能上明显落后。
Unsupervised Summarization Re-ranking 无监督总结重新排名
代码
https://github.com/ntunlp/SummScore
背景
随着特定任务预训练目标的兴起﹐PEGASUS等抽象摘要模型在下游摘要任务中提供了吸引人的零样本性能。
然而,这种无监督模型的性能仍然明显落后于有监督的模型。
与监督设置类似,我们注意到这些模型的摘要候选项之间的质量差异非常大,而只有一个候选项被保留为摘要输出。
本文提出以无监督的方式对摘要候、选人重新排序,旨在缩小无监督和有监督模型之间的性能差距。该方法在ROUGE四个广泛采用的摘要基准
主要挑战
主要的挑战在于:
重新排序者也必须不接受任何监督。所提出的模型没有训练任何神经模型,而是简单地计算表明摘要质量的特征来对每个候选摘要进行评分,其中一些还利用了源文档。
使用这些特征的加权平均值进行候选重排序,并探索了几种估计特征权重的方法。
该方法名为SummScore:
1、轻量级、快速和易于使用,因为它不依赖于神经网络。
2、由于它完全是无监督的,重新排序的结果可以为预训练模型提供更精细的自我监督,用几轮自我训练来补充预训练。
优点:
1、本文提出SummScore,第一个在无监督设置和以无监督方式对摘要候选人重新排序的系统。
2、通过持续的性能改进证明了SummScore的力量:PEGASUS最高可达7.27% , ChatGPT最高可达6.86%2在ROUGE四个无监督摘要数据集上的平均收益,在30个零样本迁移设置上的平均收益为7.51%ROUGE 。
3、利用re-ranker,推导出一种原始有效的自训练方法﹐不断改进基本的无监督摘要模型,使PEGASUS从35.47提高到39.76ROUGE-1(+12.09%)。
Disentangling Text Representation With Counter-Template For Unsupervised Opinion Summarization 基于反模板解纠缠文本表示 用于无监督意见摘要(没找到)
ACL-2022
Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization 从搜索中学习非自回归模型 用于无监督的句子摘要(有代码)
出发点
最近,Schumann et al.(2020)提出了一种基于编辑的无监督摘要方法。他们的模型最大化了启发式定义的评分函数,该函数评估生成摘要的质量(流畅性和语义),比循环一致性方法实现了更高的性能。
1、然而,搜索方法在推理过程中速度很慢,因为每个数据样本需要数百个搜索步骤。
2、此外,他们的方法只能从输入句子中选择词序保持不变的词。因此,由于搜索算法的局部最优性,它受到限制并可能产生噪声摘要。
优点
为解决上述缺点,本文提出一种非自回归的无监督摘要方法(NAUS)。其想法是执行Schumann et al.(2020)中的搜索,并受Li et al.(2020)的启发,训练一个机器学习模型来平滑这种噪声并加快推理过程。与Li et al.(2020)不同,本文建议利用非自回归解码器,由于以下观察,它并行生成所有输出标记:
1、非自回归模型比自回归生成快几倍,这在部署系统时很重要。
2、摘要任务的输入和输出具有很强的对应关系。非自回归生成支持仅编码器的架构,它可以更好地利用这种输入-输出对应关系,甚至在摘要方面优于自回归模型。
3、对于非自回归模型,可以设计一种基于动态规划的长度控制算法来满足长度约束,这在摘要应用中很常见,但在自回归模型中很难实现。
方法
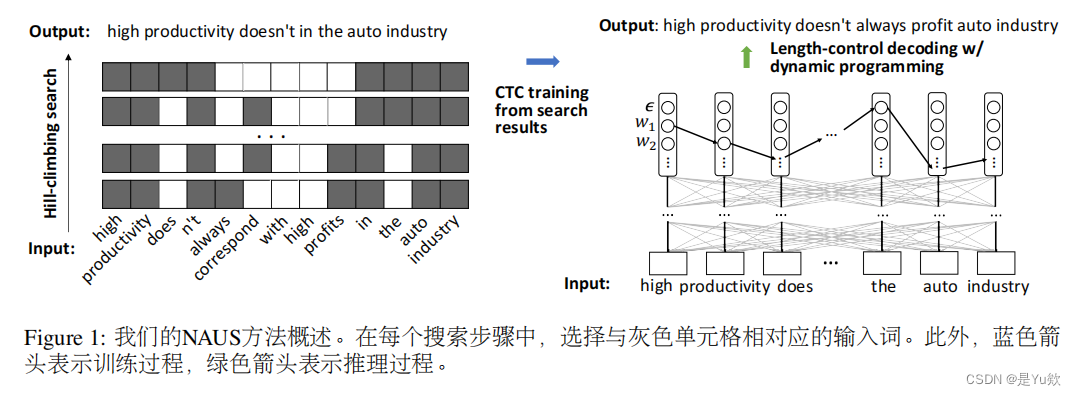
本文提出一种非自回归无监督摘要(NAUS)方法,不需要并行数据进行训练。
1、NAUS首先对启发式定义的分数执行基于编辑的搜索,并生成一个摘要作为伪基础真理。
2、然后,基于搜索结果训练一个仅编码器的非自回归Transformer。
本文还提出了一种长度控制解码的动态规划方法,该方法对于摘要任务非常重要。
指标表现
在两个数据集上的实验表明,NAUS在无监督摘要方面取得了最先进的性能,但大大提高了推理效率。此外,该算法能够执行显式长度转移摘要生成。
代码
https://github.com/MANGA-UOFA/NAUS
ACL-2021
Unsupervised Extractive Summarization-Based Representations for Accurate and Explainable Collaborative Filtering
Improving Unsupervised Extractive Summarization with Facet-Aware Modeling
EMNLP-2022
Unsupervised Opinion Summarisation in the Wasserstein Space
Unsupervised Entity Linking with Guided Summarization and Multiple-Choice Selection
Learning From the Source Document: Unsupervised Abstractive Summarization. 4194-4205
Unsupervised Multi-Granularity Summarization. 4980-4995
NeurIPS-2021
WWW-2023
无监督
XWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
https://dl.acm.org/doi/10.1145/3543507.3583405
AAAI-2021
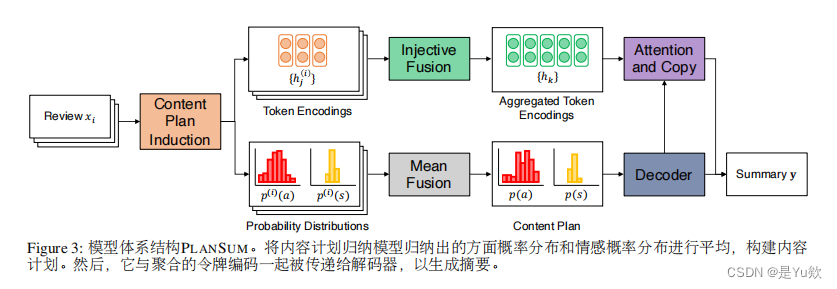
Unsupervised Opinion Summarization with Content Planning 基于内容规划的无监督观点摘要(有代码)
代码:https://github.com/rktamplayo/plansum
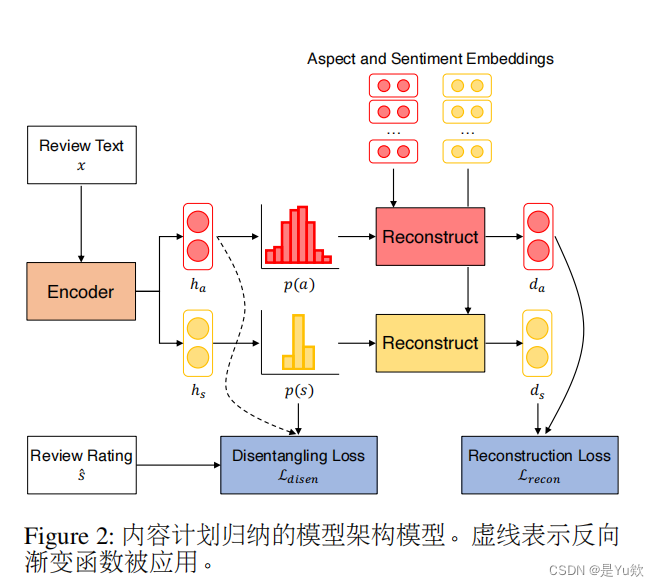
数据集
最近深度学习技术在生成式摘要方面的成功,是基于大规模数据集的可用性。
在总结评论(例如,对产品或电影)时,这种训练数据既不可获得,也不容易获取,这激励了依赖合成数据集进行监督训练的方法的开发。
(优势)将内容规划明确地纳入摘要模型中,
1、可以产生更高质量的输出,
2、创建更自然的合成数据集,类似于真实世界的文档-摘要对。
采取方面和情感分布的形式,这些形式是从不需要访问昂贵注释的数据中归纳出来的。
通过从内容规划器参数化的狄利克雷LDA主题分布中抽样伪评论来创建合成数据集。
摘要生成
而模型根据输入评论和诱导的内容计划生成摘要。

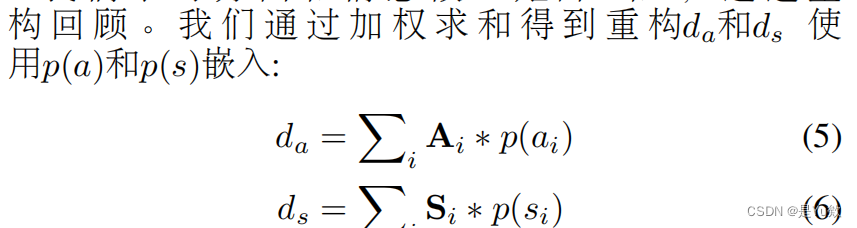


知识点补充:hinge loss
参考:https://zhuanlan.zhihu.com/p/347456667
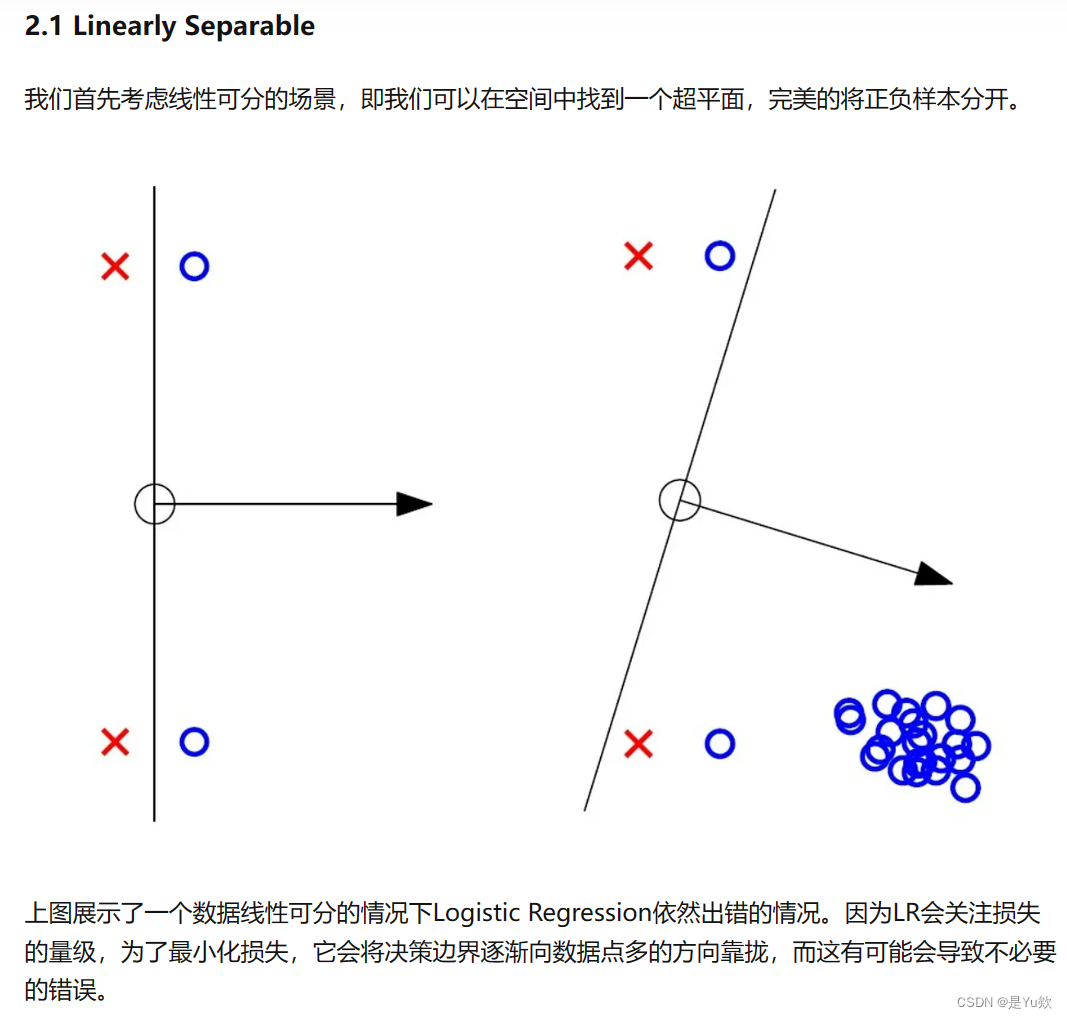
LR中Logistic Loss的推导更加统计向,那么SVM中的Hinge Loss的推导则更像在做数学建模。
在空间中,它处于正负样本的正中间,可能能够对正负样本的局部扰动更加鲁棒。
那么怎么将这个思路数学化呢?
Margin:距离决策边界最近的点,到决策边界的距离
若能在约束条件下,找到一个能够最大化Margin的超平面,那么就能够实现上述的思路,使得其位于正负样本的正中间。

训练

评估
在三个数据集上进行实验(Wang and Ling 2016; Chuand Liu 2019;Bra2inskas,Lapata,and Titov 2019)代表不同的领域(电影、业务和产品评论)摘要需求(短摘要vs长摘要)表明,所提出方法在生成信息丰富、连贯和流畅的摘要方面优于竞争模型,以捕获意见共识。
2
本文提出了第一个基于抽取式摘要的协同过滤模型ES-COFILT。所提出的模型专门为每个项目和用户产生提取性摘要。
与其他类型的解释不同,摘要级解释与现实生活中的解释非常相似。
优势:统一了表示和解释。抽取式摘要同时表示项目和用户。
模型:集成了BERT、K均值嵌入custthng和多层感知机,分别学习句子嵌入、表示解释和用户-项目交互。
提高:评分预测的准确性和用户/1tem的扩展性。实验结果表明,该模型的预测精度优于其他主流推荐模型。
此外,我们提出了一个全面的集合。评估解释在现实生活中的可解释性的标准。可解释性研究表明,与其他解释类型相比,摘要级解释具有优势和偏好。
Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes 面向面对面对话的无监督抽象式对话摘要
Unsupervised Summarization for Chat Logs with Topic-Oriented Ranking and Context-Aware Auto-Encoders 基于主题排序和上下文感知自动编码器的聊天日志无监督摘要
Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes 面向面对面对话的无监督抽象式对话摘要
其他
判断抽取式和生成式摘要
抽取式:Extractive Summarization
生成式:Abstractive Summary
主要方法
无监督的抽取式摘要。
抽取式摘要旨在通过识别和提取少量重要句子来浓缩一段文本(Allahyari等人,2017;Liu和 Lapata, 2019;El-Kassas etal.,2021),保留了文本的原意。
无监督抽取摘要中最流行的方法:
利用基于图的方法来计算句子在摘要中包含的显著性(Mi-halcea和Tarau,2004;郑和拉帕塔,2019)。这些方法将文档中的句子表示为无向图中的节点,这些节点的边使用句子相似度进行加权。使用节点cen-对图中的句子进行评分和排序真实性,使用PageRank递归计算(Page et al.,1999)。
评估
评估信息量:一元分词和二元分词重叠(ROUGE-1 和胭脂-2)
度量流畅性:最长公共子序列(ROUGE-L)