模型导出
修改Image的Input动态维度
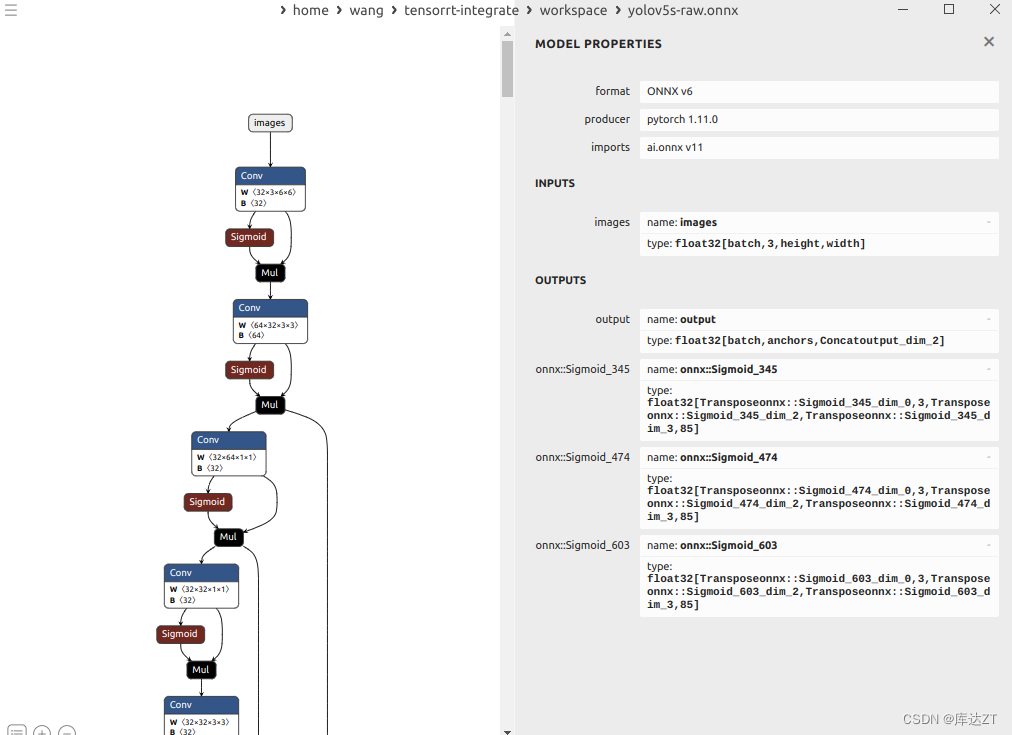
首先可以看到这个模型导出的时候Input有三个维度都是动态,而我们之前说过只需要一个batch维度是动态,所以要在export的export onnx 进行修改,将
torch.onnx.export(model, im, f, verbose=False, opset_version=opset, training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL, do_constant_folding=not train, input_names=['images'], output_names=['output'], dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640) 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85) } if dynamic else None)改为:
torch.onnx.export(model, im, f, verbose=False, opset_version=opset, training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL, do_constant_folding=not train, input_names=['images'], output_names=['output'], dynamic_axes={'images': {0: 'batch'}, # shape(1,3,640,640) 'output': {0: 'batch'} # shape(1,25200,85) } if dynamic else None)
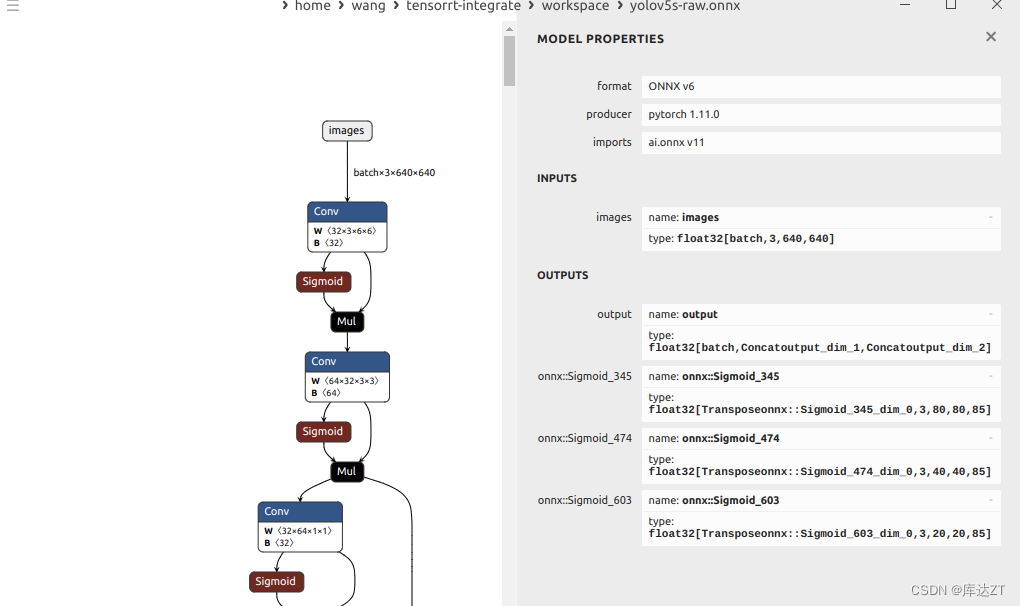
修改完的已经变成了只有batch是动态维度 。
修改output
而且也可以看到,这里的output输出有四个tensor,其中三个都是fpn结构,80*80 , 40*40 , 20*20,这些我们在这里去掉,仅保留拼接后的结果。
将yolov5-6.0/models/yolo.py中的Class detect修改:
return x if self.training else (torch.cat(z, 1), x)
-->
return x if self.training else torch.cat(z, 1)
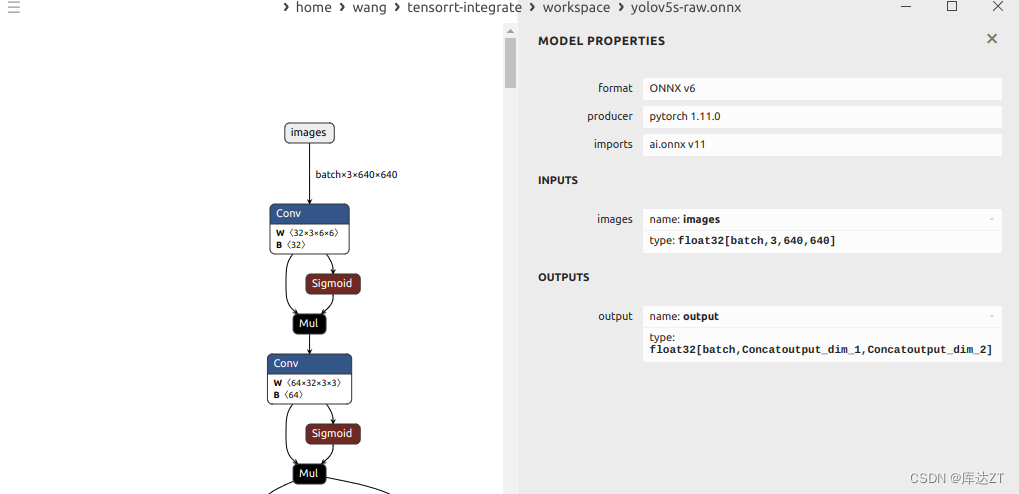
修改完毕的output仅保留拼接后的结果。
剪去多余节点:
之后发现这个onnx还是很丑啊
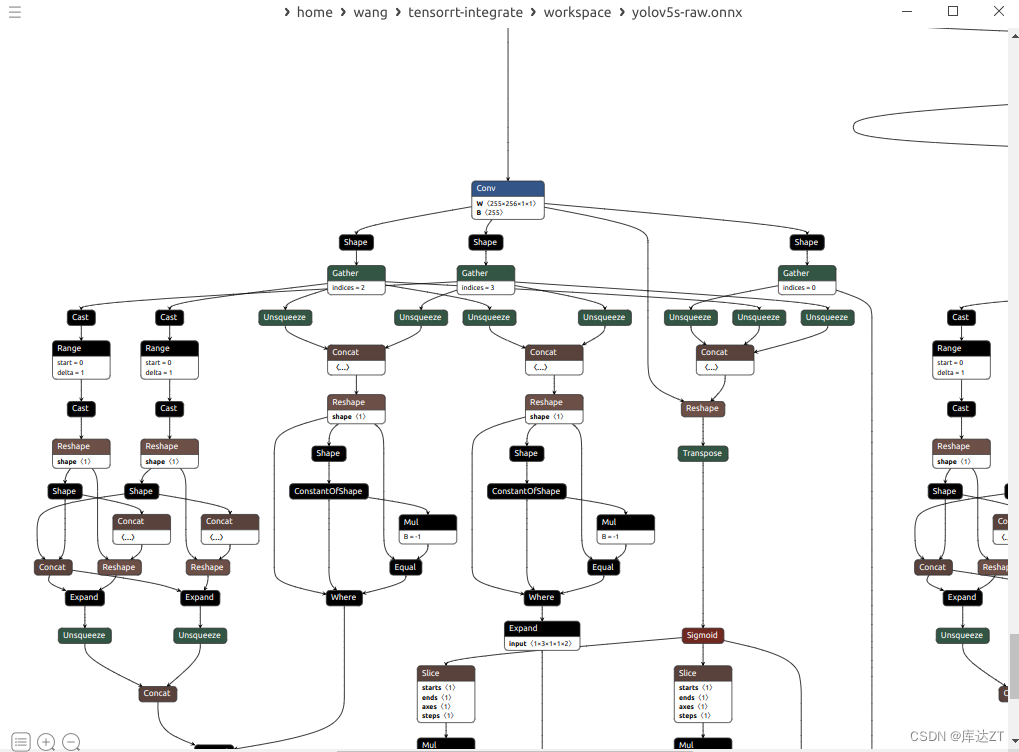
发现真正导致变丑的原因在于这些节点 比如Gather。所以下一步就是要干掉他。
这一步就是将:
for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()改为:
x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = map(int,x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
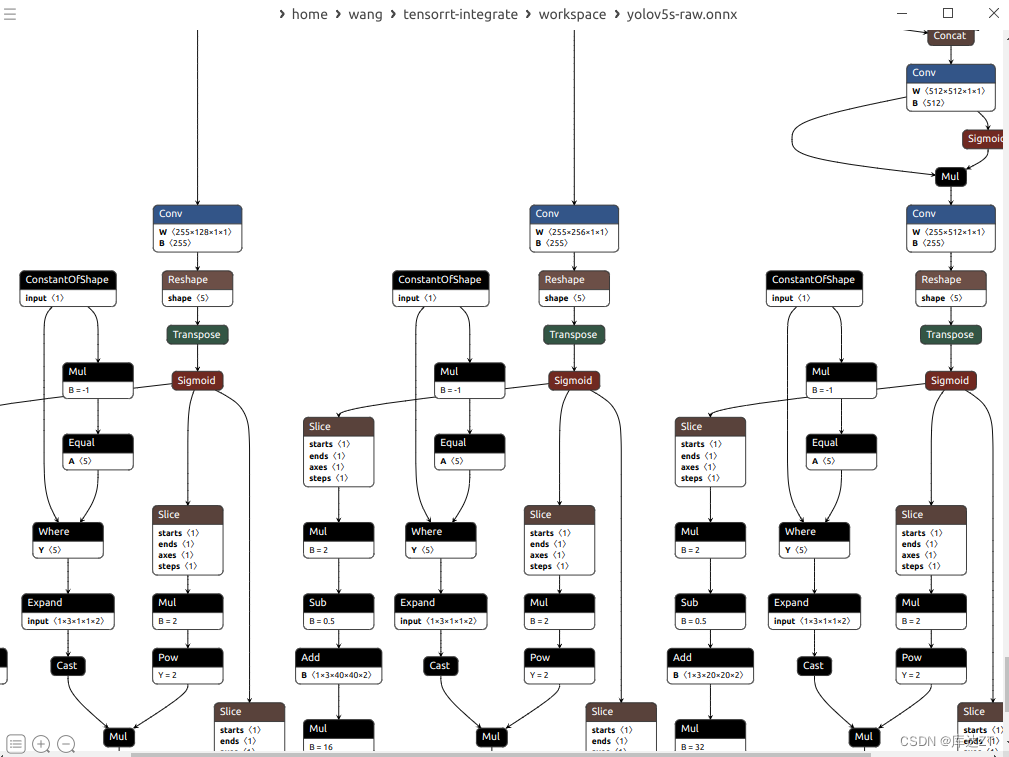 可以看到明显改善了不少。
可以看到明显改善了不少。
调整reshape
但是在reshape中可以看到中间维度是-1,而我们要的是batch是-1
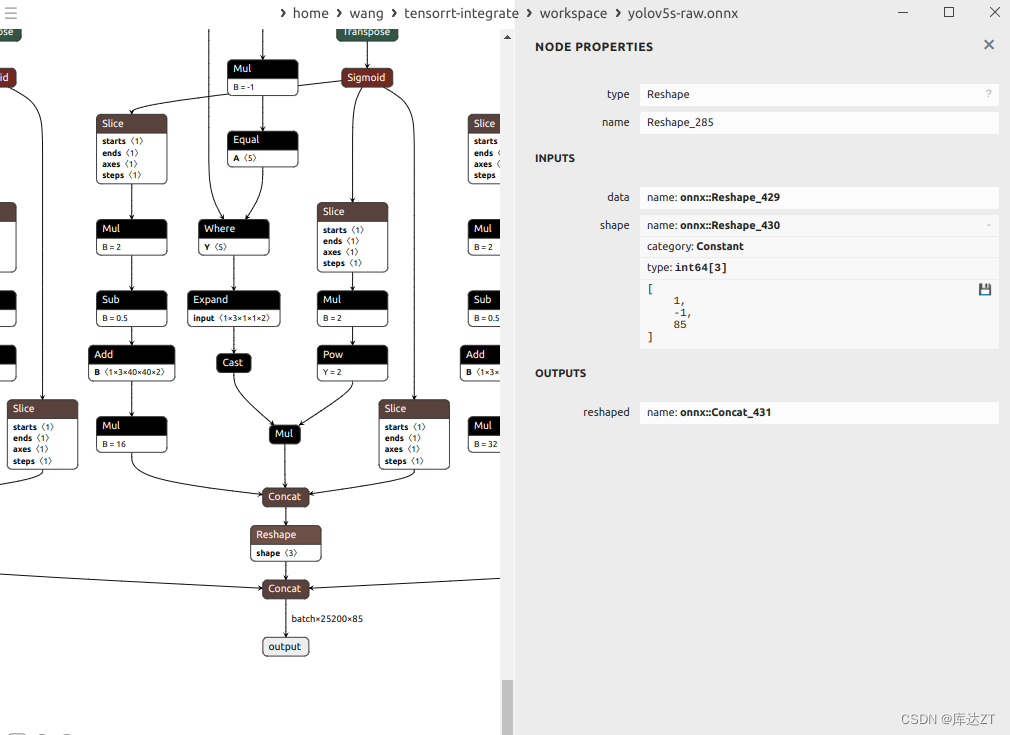
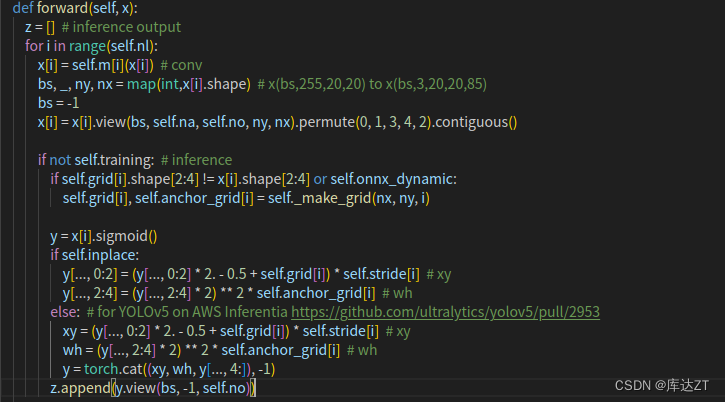
而bs是-1 , y.view还有个-1,这肯定是不行的,那么我们就要手动把这个计算出来,首先y的shape和x的shape一样,x的shape是bs*self.na*self.no*ny*nx,那么这里就是y.view(bs , self.na*nx*ny,self,no)
之后保存再次导出,可以看到已经变成batch的-1了

修改多余节点:
但是发现还有比如expand这种节点,推断可能是由于数据跟踪引起的
def _make_grid(self, nx=20, ny=20, i=0): d = self.anchors[i].device yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)]) grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float() anchor_grid = (self.anchors[i].clone() * self.stride[i]) \ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()所以在这里就没必要每个都保存起来,直接给一个常量值就可以。
anchor_grid = (self.anchors[i].clone() * self.stride[i]).view(1,-1,1,1,2)然后将所有用到self.anchor_grid的部分都替换为anchor_grid。
这样看起来就变成很平整的样子了
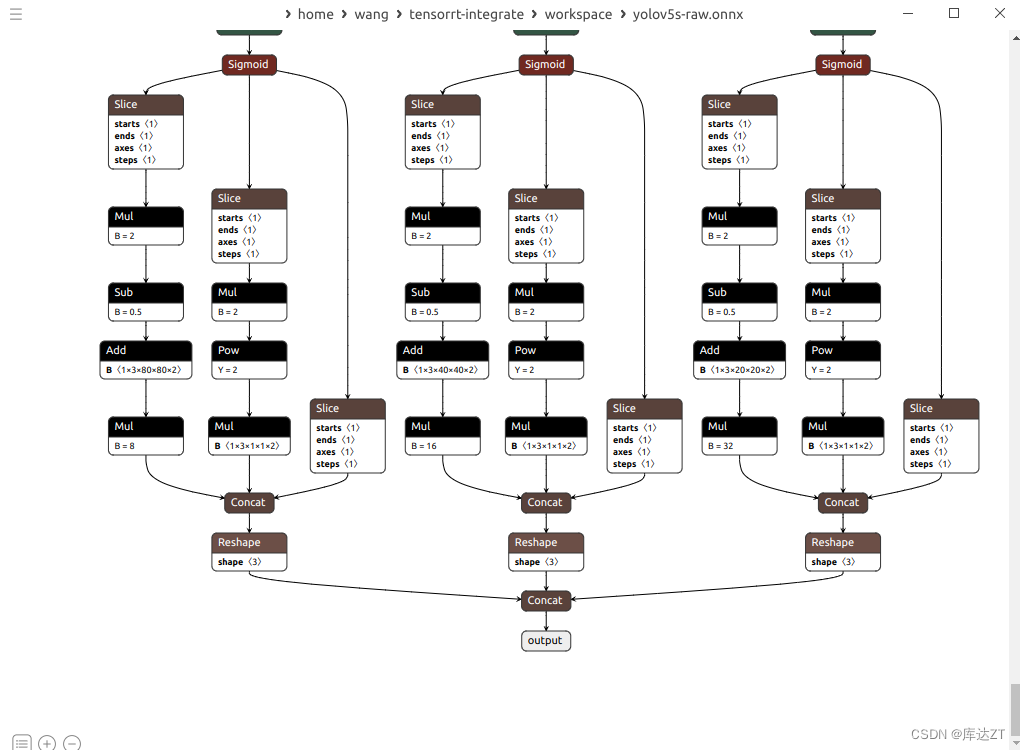
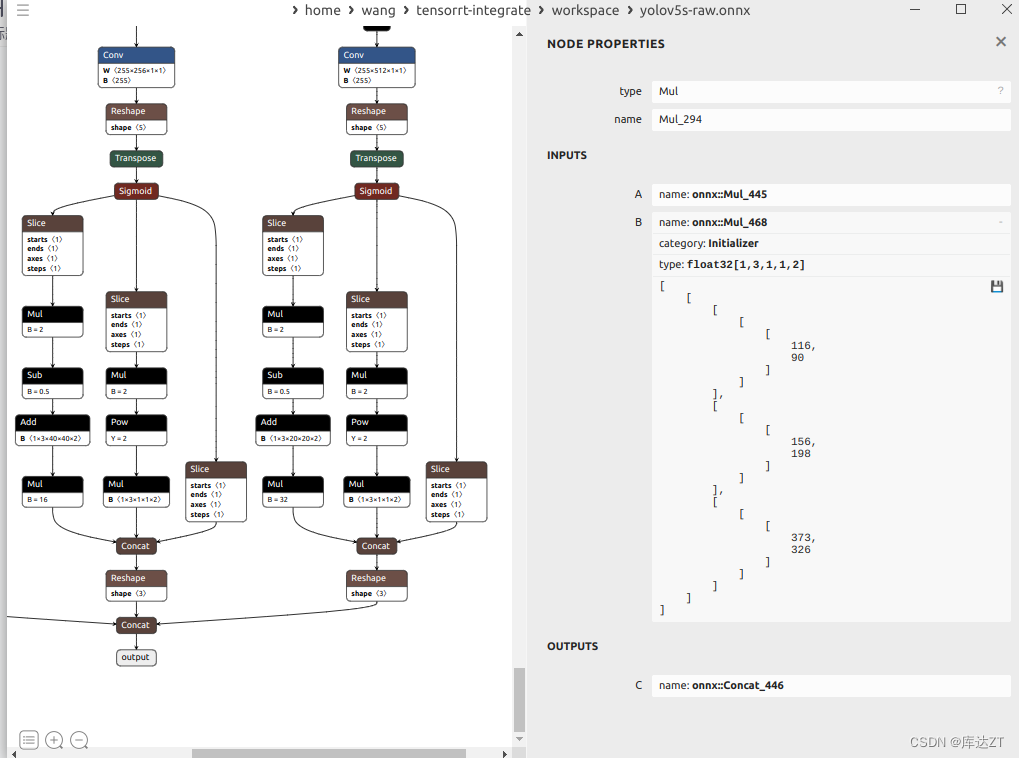
刚刚的那一大堆就变成了1*3*1*1*2这样子的常量值,这个kind是Initializer,就是常量的这个意思。
CPP推理过程:
TRT:

YOLO:

可以看到置信度稍微有一些区别。
输入input作warpaffine:
因为我们的输入是一个确认了的输入:是640*640。所以要对图像做一个类似warpaffine。就是等比缩放剧中填充

///
// letter box
auto image = cv::imread("car.jpg");
// 通过双线性插值对图像进行resize
float scale_x = input_width / (float)image.cols;
float scale_y = input_height / (float)image.rows;
float scale = std::min(scale_x, scale_y);
float i2d[6], d2i[6];
// resize图像,源图像和目标图像几何中心的对齐
i2d[0] = scale; i2d[1] = 0; i2d[2] = (-scale * image.cols + input_width + scale - 1) * 0.5;
i2d[3] = 0; i2d[4] = scale; i2d[5] = (-scale * image.rows + input_height + scale - 1) * 0.5;
cv::Mat m2x3_i2d(2, 3, CV_32F, i2d); // image to dst(network), 2x3 matrix
cv::Mat m2x3_d2i(2, 3, CV_32F, d2i); // dst to image, 2x3 matrix
cv::invertAffineTransform(m2x3_i2d, m2x3_d2i); // 计算一个反仿射变换
//为什么要计算逆矩阵:因为正矩阵是图像变成warpaffine的过程,逆变换是把框变回到图像尺度的过程
cv::Mat input_image(input_height, input_width, CV_8UC3);
cv::warpAffine(image, input_image, m2x3_i2d, input_image.size(), cv::INTER_LINEAR, cv::BORDER_CONSTANT, cv::Scalar::all(114)); // 对图像做平移缩放旋转变换,可逆,填充全是常量值,114
cv::imwrite("input-image.jpg", input_image);
//存储一下warpaffine效果
int image_area = input_image.cols * input_image.rows;
unsigned char* pimage = input_image.data;
float* phost_b = input_data_host + image_area * 0;
float* phost_g = input_data_host + image_area * 1;
float* phost_r = input_data_host + image_area * 2;
for(int i = 0; i < image_area; ++i, pimage += 3){
// 注意这里的顺序rgb调换了
*phost_r++ = pimage[0] / 255.0f;
*phost_g++ = pimage[1] / 255.0f;
*phost_b++ = pimage[2] / 255.0f;
}
///
checkRuntime(cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream));
存储一下warpaffine效果

之后就是作推理:
// 3x3输入,对应3x3输出
auto output_dims = engine->getBindingDimensions(1);
int output_numbox = output_dims.d[1];
int output_numprob = output_dims.d[2];
int num_classes = output_numprob - 5;//类别数
int output_numel = input_batch * output_numbox * output_numprob;
float* output_data_host = nullptr;
float* output_data_device = nullptr;
checkRuntime(cudaMallocHost(&output_data_host, sizeof(float) * output_numel));
checkRuntime(cudaMalloc(&output_data_device, sizeof(float) * output_numel));
// 明确当前推理时,使用的数据输入大小
auto input_dims = engine->getBindingDimensions(0);
input_dims.d[0] = input_batch;
execution_context->setBindingDimensions(0, input_dims);
float* bindings[] = {input_data_device, output_data_device};
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
checkRuntime(cudaMemcpyAsync(output_data_host, output_data_device, sizeof(float) * output_numel, cudaMemcpyDeviceToHost, stream));
checkRuntime(cudaStreamSynchronize(stream));
这个结果就是我们之前YOLOV5的predict(https://blog.csdn.net/zhuangtu1999/article/details/131499750?spm=1001.2014.3001.5501)
但在这里根之前不太一样了:
vector<vector<float>> bboxes;
float confidence_threshold = 0.25;
float nms_threshold = 0.5;
for(int i = 0; i < output_numbox; ++i){
float* ptr = output_data_host + i * output_numprob;
float objness = ptr[4];
if(objness < confidence_threshold)
continue;
float* pclass = ptr + 5;
int label = std::max_element(pclass, pclass + num_classes) - pclass;
float prob = pclass[label];
float confidence = prob * objness;
if(confidence < confidence_threshold)
continue;
// 中心点、宽、高
float cx = ptr[0];
float cy = ptr[1];
float width = ptr[2];
float height = ptr[3];
// 预测框
float left = cx - width * 0.5;
float top = cy - height * 0.5;
float right = cx + width * 0.5;
float bottom = cy + height * 0.5;
// 对应图上的位置
float image_base_left = d2i[0] * left + d2i[2];
float image_base_right = d2i[0] * right + d2i[2];
float image_base_top = d2i[0] * top + d2i[5];
float image_base_bottom = d2i[0] * bottom + d2i[5];
bboxes.push_back({image_base_left, image_base_top, image_base_right, image_base_bottom, (float)label, confidence});
}
printf("decoded bboxes.size = %d\n", bboxes.size());
这里的预测框,left,top等等对应的是warpaffine之后的图片,但我们要做的是把他在原来的图片上加入回来,所以还要做一个反变换的过程。
这里也是我们值前提到过,咱们只有缩放和平移的时候,有效的参数只有三个:scale , dx , dy,这里对应的就是d2i[0] , d2i[2] , d2i[5]。
在之后就是nms:
// nms非极大抑制
std::sort(bboxes.begin(), bboxes.end(), [](vector<float>& a, vector<float>& b){return a[5] > b[5];});
std::vector<bool> remove_flags(bboxes.size());
std::vector<vector<float>> box_result;
box_result.reserve(bboxes.size());
auto iou = [](const vector<float>& a, const vector<float>& b){
float cross_left = std::max(a[0], b[0]);
float cross_top = std::max(a[1], b[1]);
float cross_right = std::min(a[2], b[2]);
float cross_bottom = std::min(a[3], b[3]);
float cross_area = std::max(0.0f, cross_right - cross_left) * std::max(0.0f, cross_bottom - cross_top);
float union_area = std::max(0.0f, a[2] - a[0]) * std::max(0.0f, a[3] - a[1])
+ std::max(0.0f, b[2] - b[0]) * std::max(0.0f, b[3] - b[1]) - cross_area;
if(cross_area == 0 || union_area == 0) return 0.0f;
return cross_area / union_area;
};
for(int i = 0; i < bboxes.size(); ++i){
if(remove_flags[i]) continue;
auto& ibox = bboxes[i];
box_result.emplace_back(ibox);
for(int j = i + 1; j < bboxes.size(); ++j){
if(remove_flags[j]) continue;
auto& jbox = bboxes[j];
if(ibox[4] == jbox[4]){
// class matched
if(iou(ibox, jbox) >= nms_threshold)
remove_flags[j] = true;
}
}
}
printf("box_result.size = %d\n", box_result.size());
通过cv::rectangle画框:
for(int i = 0; i < box_result.size(); ++i){
auto& ibox = box_result[i];
float left = ibox[0];
float top = ibox[1];
float right = ibox[2];
float bottom = ibox[3];
int class_label = ibox[4];
float confidence = ibox[5];
cv::Scalar color;
tie(color[0], color[1], color[2]) = random_color(class_label);//通过标签随机选择颜色
cv::rectangle(image, cv::Point(left, top), cv::Point(right, bottom), color, 3);
auto name = cocolabels[class_label];
auto caption = cv::format("%s %.2f", name, confidence);
int text_width = cv::getTextSize(caption, 0, 1, 2, nullptr).width + 10;
cv::rectangle(image, cv::Point(left-3, top-33), cv::Point(left + text_width, top), color, -1);
cv::putText(image, caption, cv::Point(left, top-5), 0, 1, cv::Scalar::all(0), 2, 16);
}
cv::imwrite("image-draw.jpg", image);
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFreeHost(input_data_host));
checkRuntime(cudaFreeHost(output_data_host));
checkRuntime(cudaFree(input_data_device));
checkRuntime(cudaFree(output_data_device));
}
总结:
在这次过程中,warpaffine(预处理)和后处理过程都可以使用我们之前的核函数去处理,这一部分打包到GPU上的话性能会变得更高。