文章目录
- 1. 服务器安装scrapyd
- 1.1 scrapyd安装
- 1.2 scrapyd配置允许外网访问
- 1.3 服务器安全组开启端口
- 1.4 服务器防火墙开启端口
- 1.5 scrapyd测试
- 2. Gerapy 环境搭建
- 2.1 gerapy安装
- 2.2 gerapy测试
- 2.3 项目部署
- 2.4 定时任务
- 2.5 线上代码修改
Gerapy是一个Python的分布式爬虫部署框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,用于方便地管理和部署爬虫项目。它提供了一套完整的工具和接口,帮助用户管理爬虫的配置、调度、监控和部署。
以下是Gerapy爬虫部署框架的主要特点和功能:
-
分布式架构:Gerapy基于Scrapy框架,并引入了分布式的概念。它支持将爬虫任务分配给多台机器并行执行,提高爬取效率和速度。
-
Web界面管理:Gerapy提供了一个基于Web的管理界面,可以方便地创建、编辑和管理爬虫项目。用户可以通过浏览器访问管理界面,对爬虫进行配置和监控。
-
项目管理:Gerapy允许用户创建多个爬虫项目,并提供了项目管理功能。用户可以在管理界面中创建、导入和删除爬虫项目,以及管理项目的配置文件和依赖。
-
调度管理:Gerapy提供了灵活的调度管理功能。用户可以设置爬虫的运行时间、优先级和并发数等参数,以及配置定时任务,自动执行爬虫。
-
日志和监控:Gerapy提供了实时的日志和监控功能,用户可以通过管理界面查看爬虫的运行状态、日志输出和错误信息,便于调试和监控爬取过程。
-
部署和扩展:Gerapy支持将爬虫项目部署到多台机器上,并提供了方便的部署工具。它还支持分布式扩展,用户可以根据需要增加爬虫节点,实现高并发的爬取任务。
-
API接口:Gerapy提供了丰富的API接口,用户可以通过编程方式管理和控制爬虫项目,例如启动、停止和修改爬虫任务等操作。
总的来说,Gerapy是一个功能强大的爬虫部署框架,它简化了爬虫项目的管理和部署过程,提高了爬取效率和可扩展性,使用户可以更加方便地开发和运行分布式爬虫项目。
1. 服务器安装scrapyd
1.1 scrapyd安装
pip3 install scrapyd
1.2 scrapyd配置允许外网访问
mkdir /etc/scrapyd
vim /etc/scrapyd/scrapyd.conf
写入
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
#bind_address = 127.0.0.1
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
主要是将bind_address = 127.0.0.1 改成 bind_address = 0.0.0.0
端口号默认6800 想要换端口好的话就改http_port
除了以上方法,此外也可以定位scrapyd.conf文件在你的python环境l修改
lib/python3.7/site-packages/scrapyd/scrapyd.conf(default_scrapyd.conf)
1.3 服务器安全组开启端口
比如我的scrapyd 默认端口是6800,那就在服务器后台开启安全组6800 端口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ywB1Cqd2-1689753408599)(爬虫平台搭建.assets/image-20230719140608743.png)]](https://img-blog.csdnimg.cn/4e32eb34980b49afa43df051439b46ab.png)
1.4 服务器防火墙开启端口
# 查看防火墙已经开启的端口号
firewall-cmd --list-port
# 指定开启6800端口
firewall-cmd --zone=public --add-port=6800/tcp --permanent
# 防火墙重载配置
firewall-cmd --reload
经过以上步骤,scrapyd基本算配置完成了
1.5 scrapyd测试
启动命令输入scrapyd就行了

然后在本地浏览器访问 http://ip:6800/ (ip是你自己服务器的ip)
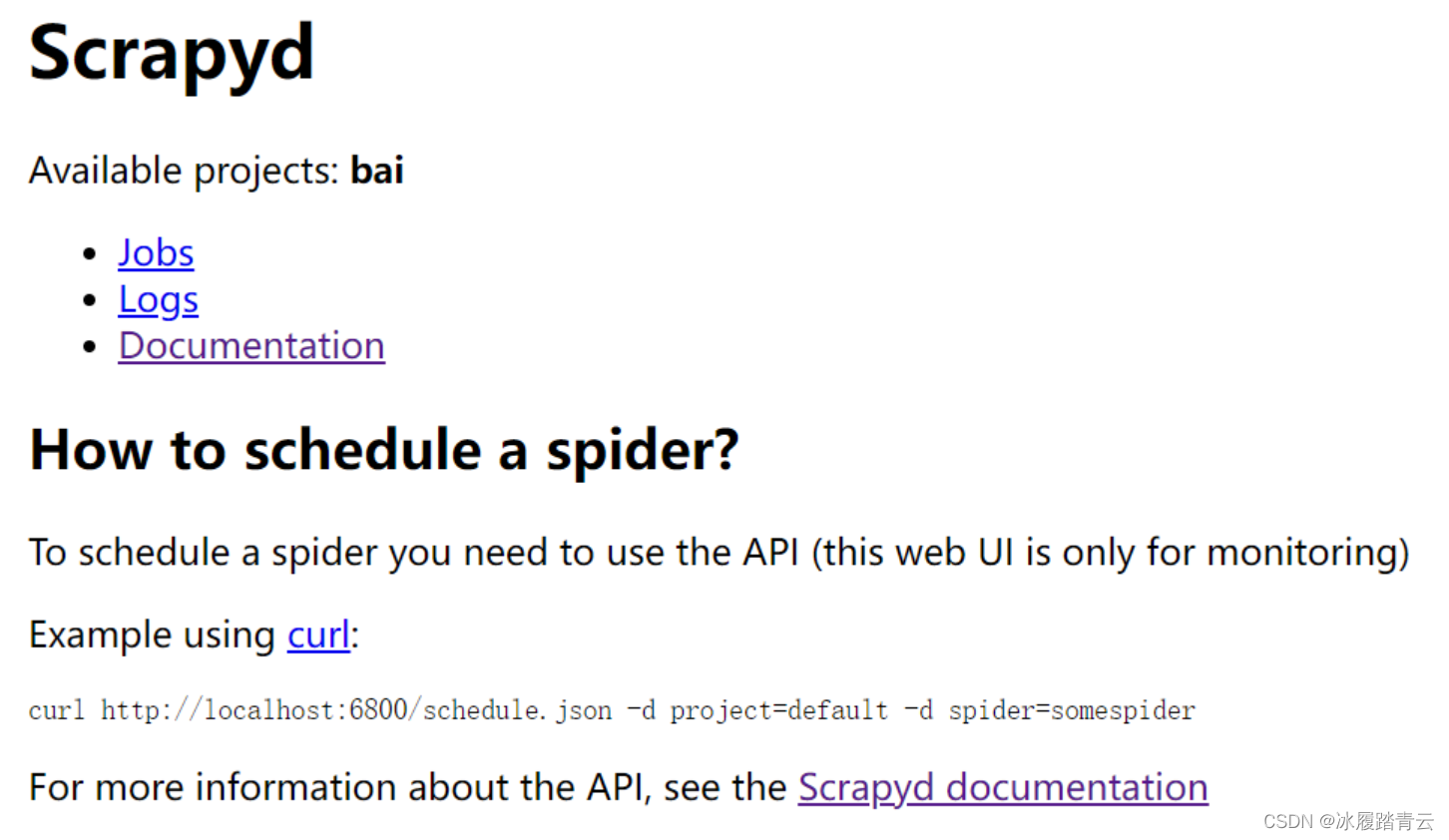
这样就算成功,那个bai是我测试百度的爬虫,不用理会。
后面确定没问题了可以直接用nohup让它在后台运行:
nohup scrapyd > /dev/null 2>&1 &
scrapyd 环境搭好之后,就可以开始搭gerapy了
2. Gerapy 环境搭建
2.1 gerapy安装
pip3 install gerapy
2.2 gerapy测试
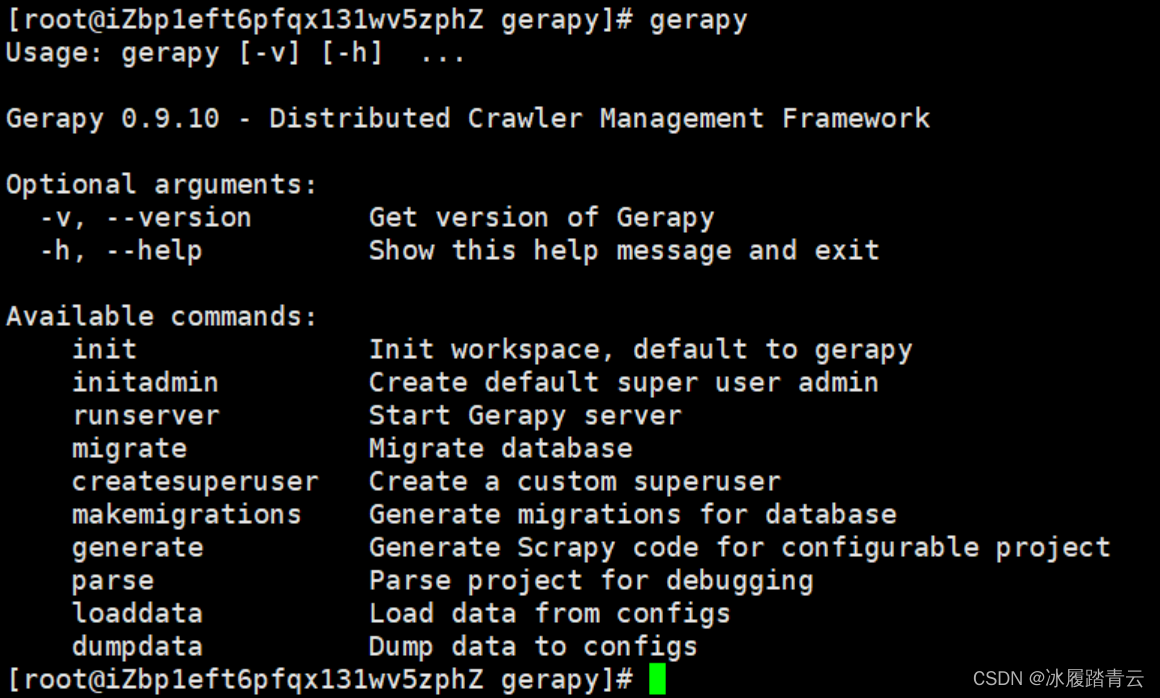
服务器控制台输入gerapy,会看到以下几个帮助参数
第一步我们可以先创建一个文件夹,用于存放我们的gerapy项目,我这里命名gerapy_pro
mkdir gerapy_pro
第二步执行
gerapy init
第三步执行
gerapy migrate
此时我们的文件夹就已经有这些东西了
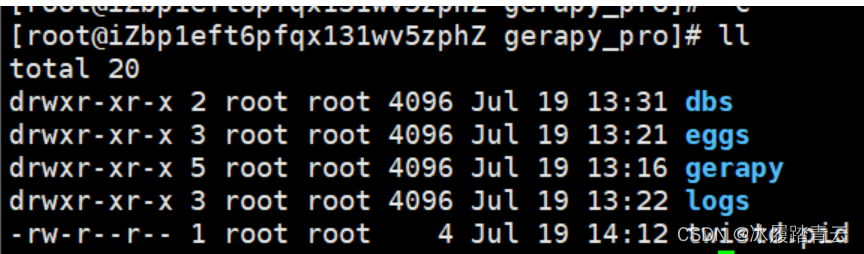
cd gerapy 看看
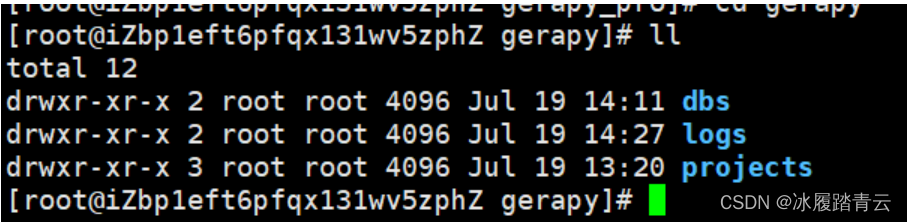
projects里就是我们要放scrapy 项目的地方
第四步 创建超级管理员用于登录
执行
gerapy createsuperuser
输入用户名 邮箱 密码两次 就可以了
在最后一步启动之前,我们也要像scrapyd一样给gerapy 安全组开放端口 ,默认端口8000
然后开启防火墙端口
最后一步启动
gerapy runserver 0.0.0.0:8000
端口号在启动时可以改按上面的命名改

启动成功,然后在本地浏览器访问 http://ip:6800 (ip是你自己服务器的ip) 就可以看到以下界面

后面部署项目测试没问题了就可以让gerapy 后台运行了
nohup gerapy runserver 0.0.0.0:8000 > /dev/null 2>&1 &
2.3 项目部署
输入用户名 密码 点击登录 进入
第一步创建scrapyd主机:
点击主机管理 再点击右上角创建 即进入以下界面
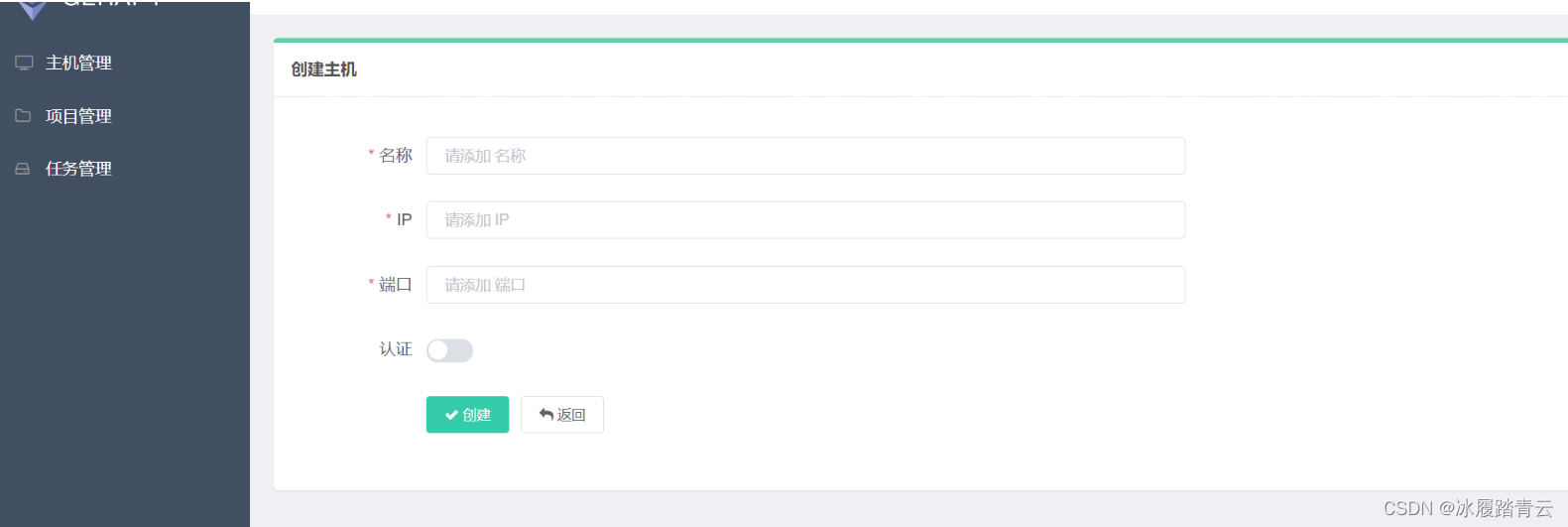
名称随便起,ip就写部署scrapyd的服务器的ip 端口号就写scrapyd服务的端口号 scrapyd服务不设置端口就默认6800
然后点击创建就可成功创建主机(注意服务器scrapyd服务要开着才会成功)
以后爬虫项目都依赖此scrapyd主机运行
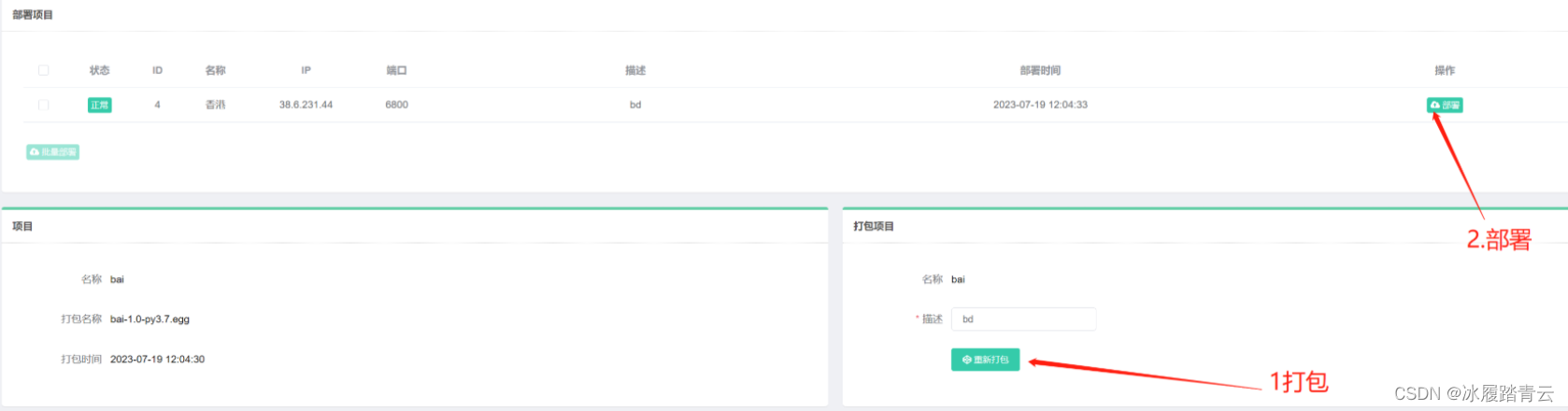
第二步上传项目打包与部署:
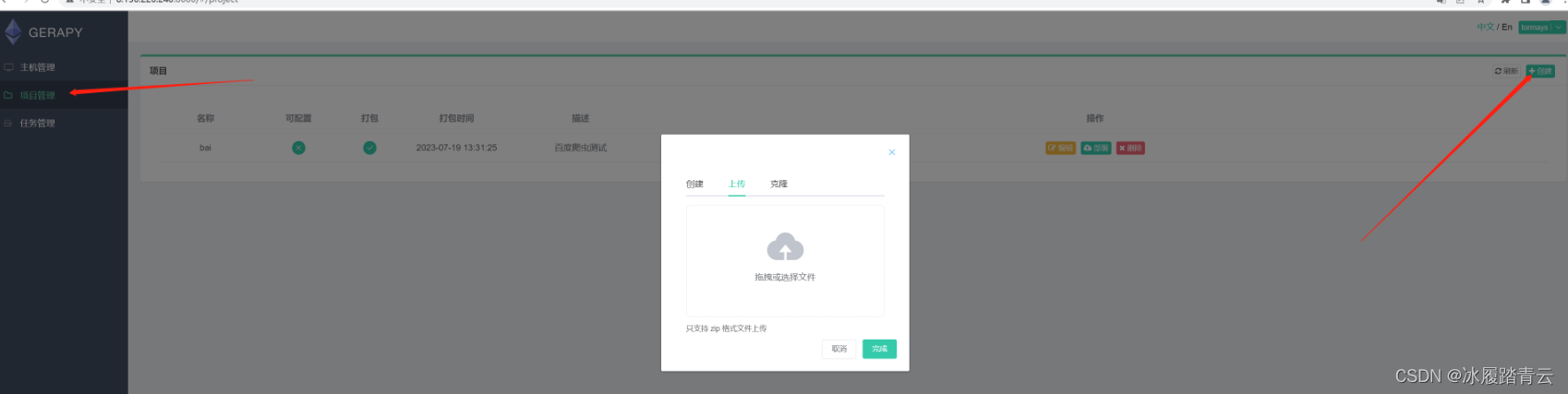
点击左侧的项目管理 再点击右上角的 创建 就可以上传scrapy项目了 ,这里支持zip和克隆形式
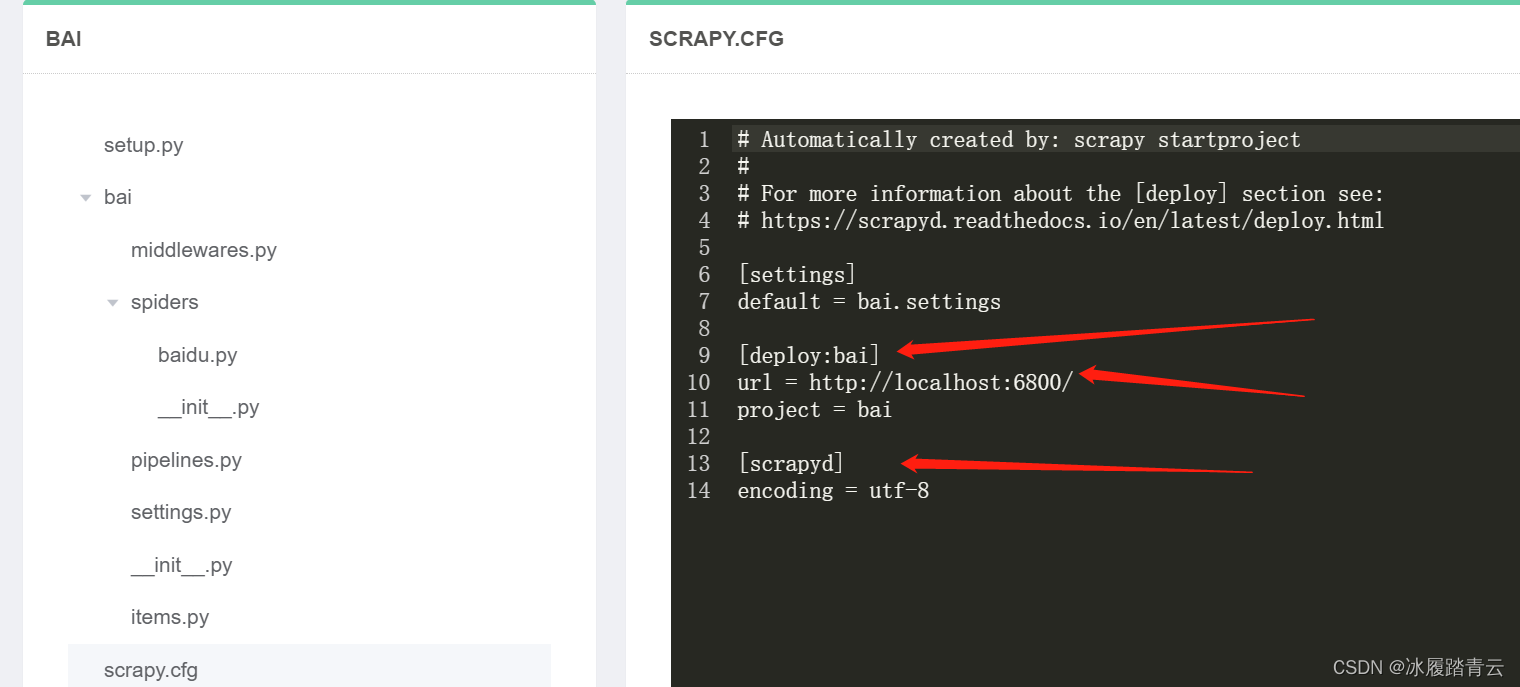
注意scrapy 项目需要改一下scrapy.cfg配置,如下:
我这里演示上传zip格式的文件,上传之后,在项目管理那里就会出现上传的项目

然后点击部署就会出现类型下面的界面,先点击打包(我这里打包过了所以显示重新打包),再点击部署,出现打包成功 部署成功 就算成功了
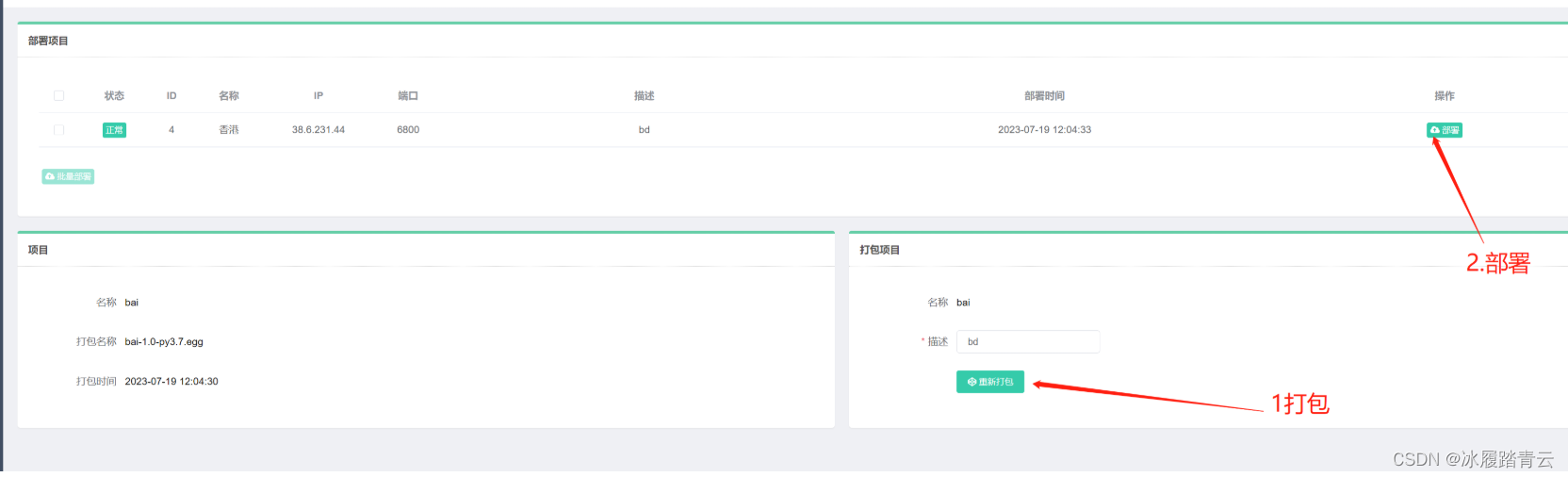
然后点击左侧的主机管理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bhM3cEMw-1689753408604)(爬虫平台搭建.assets/image-20230719150639341.png)]](https://img-blog.csdnimg.cn/c3c3ef23e2eb40c493fa90703984e4ce.png)
点击调度就可以看到我们的scrapy 里写的几个spider 成功部署上去了
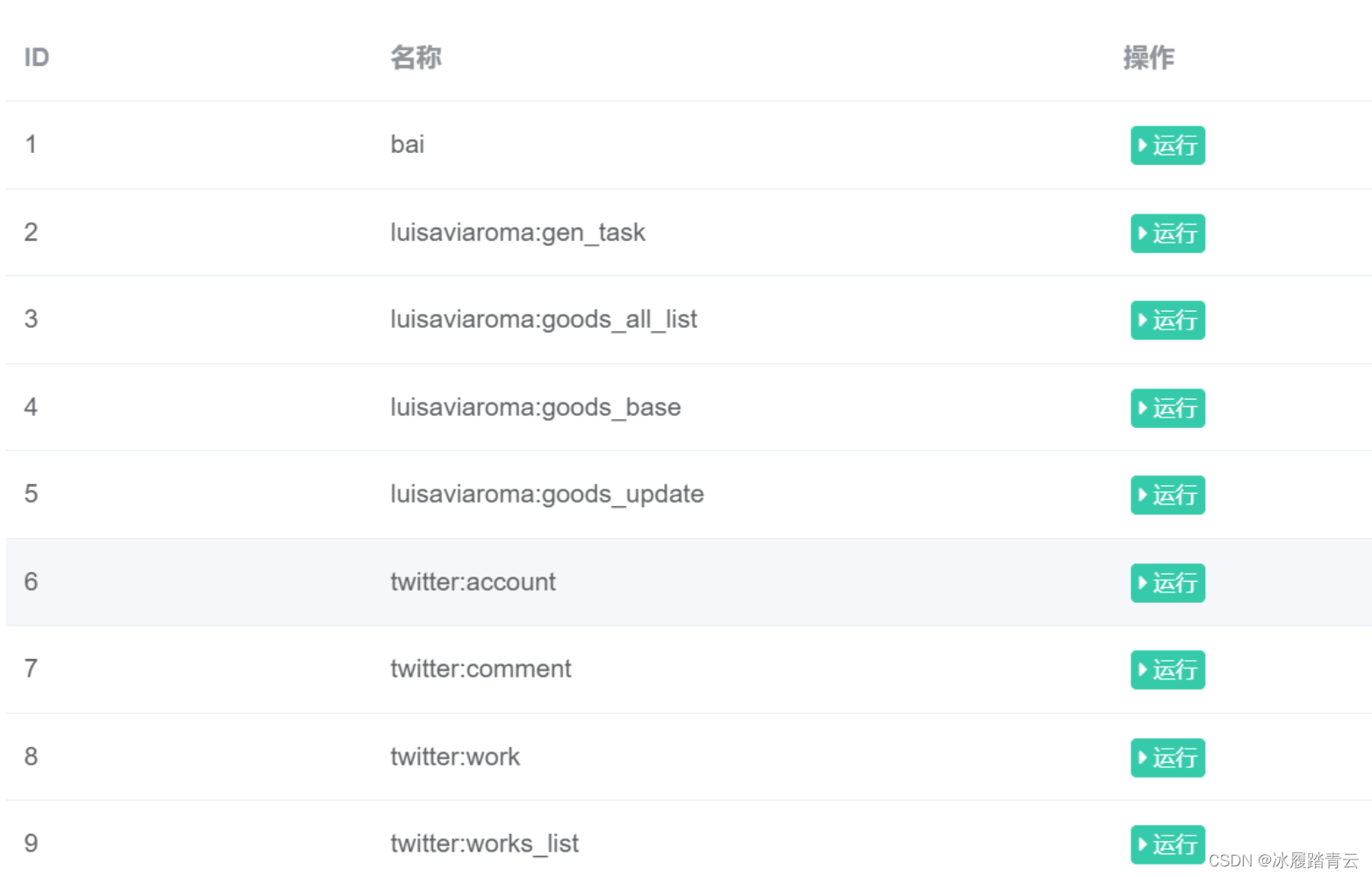
点击运行即可启动爬虫
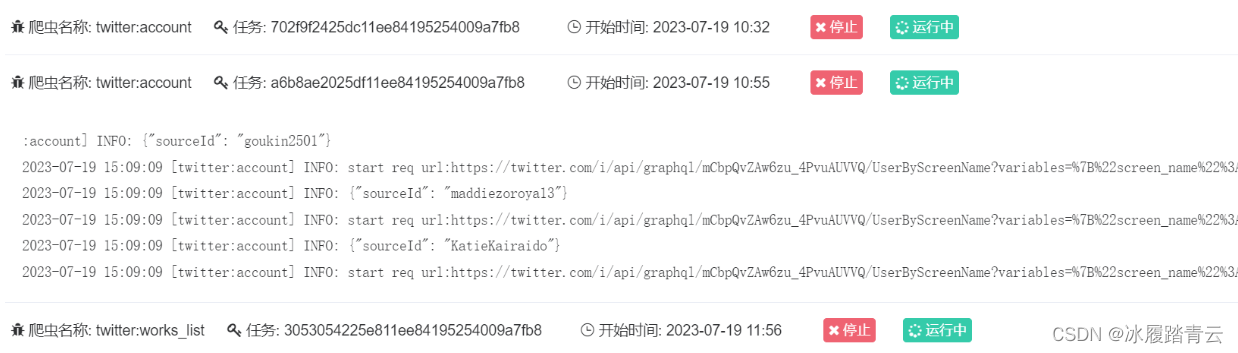
点击停止即会停止爬虫
2.4 定时任务
当然gerapy也支持定时任务,点击左侧任务管理,右上角创建
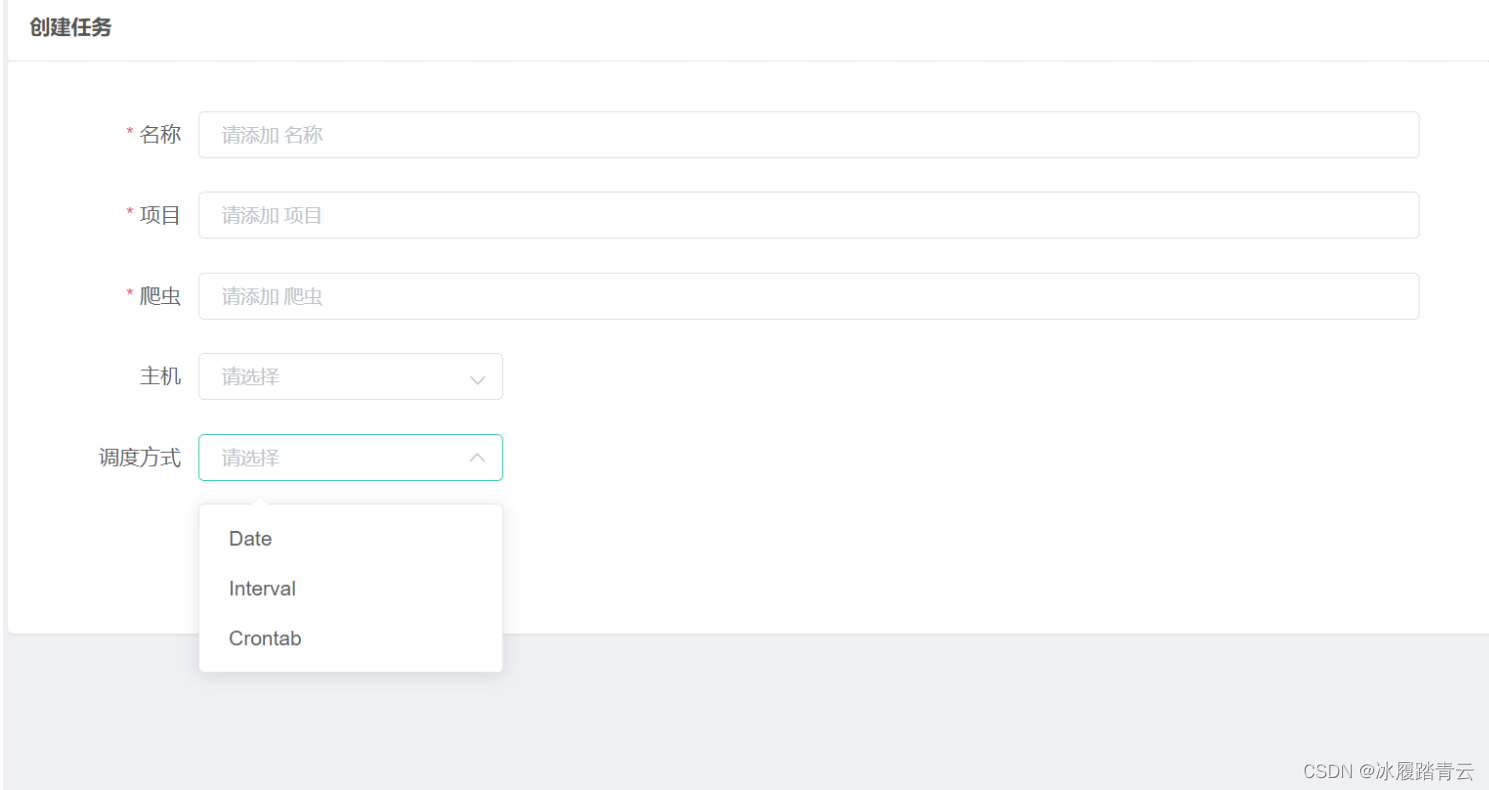
起好名字,主机就是scrapyd主机,比如我下面选择Crontab调度方式:
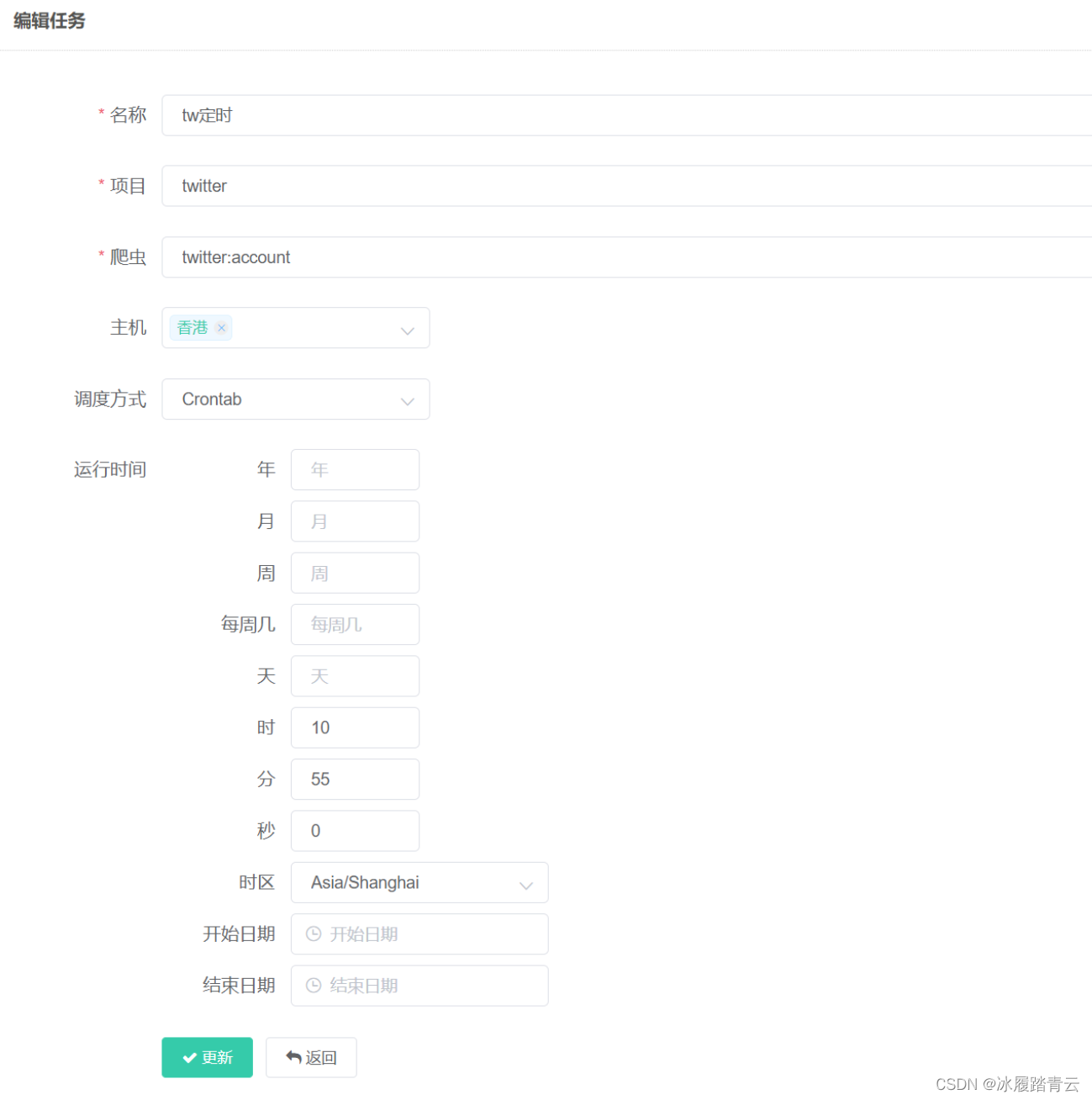
然后点击更新就可以了,之后到时间了就会在主机管理 调度那里自动调度运行。
状态查看:

2.5 线上代码修改
在项目管理里选择要修改的项目,点击编辑
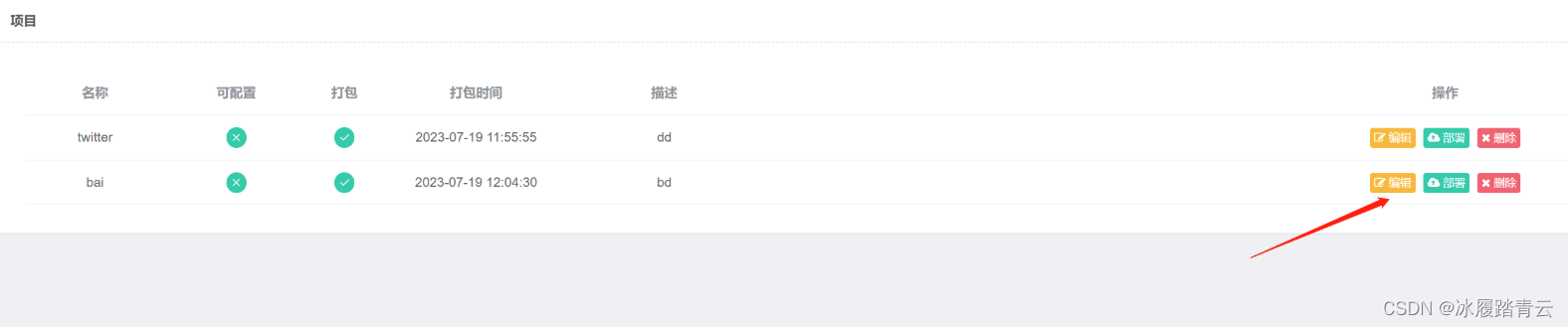
即可进入整个项目
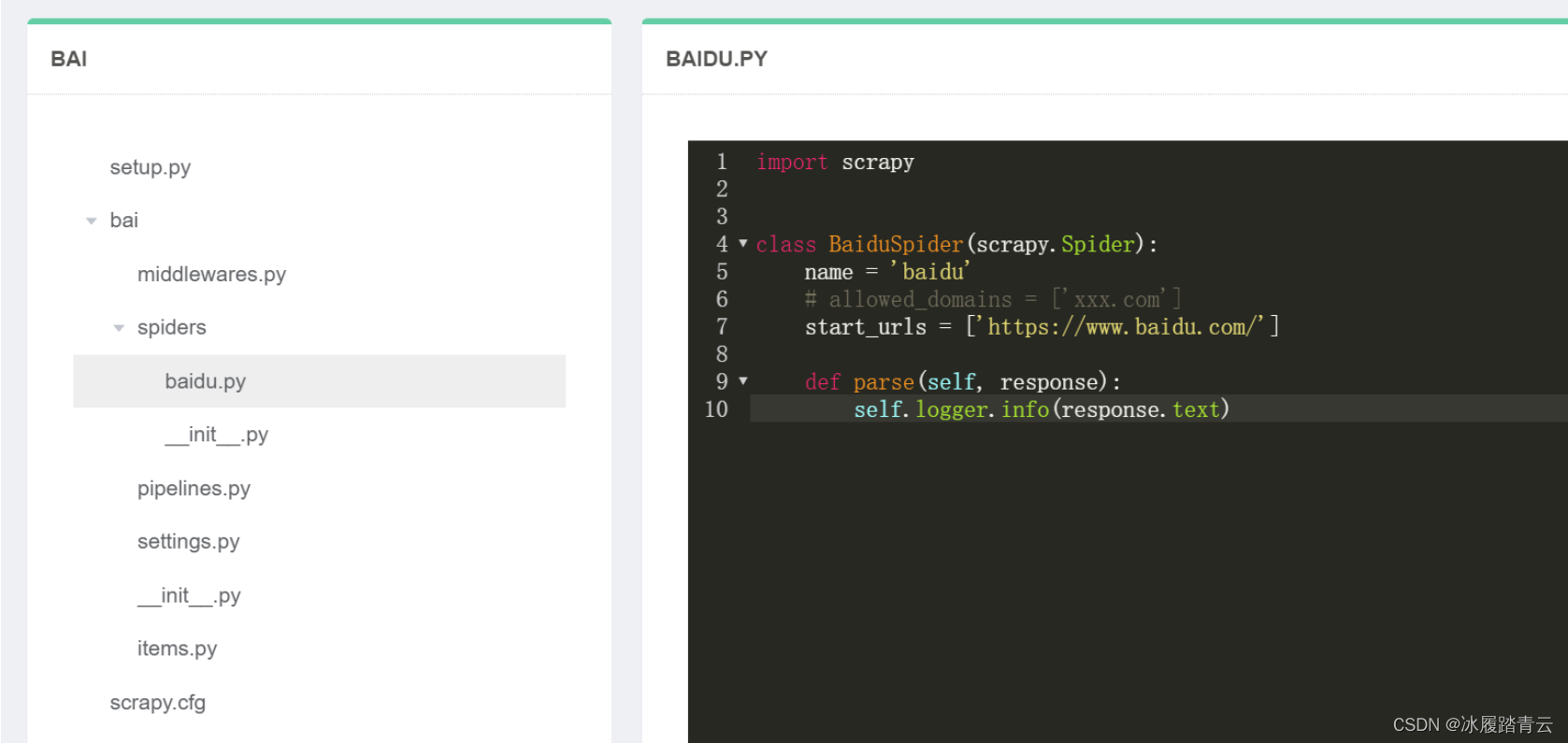
修改完成后会自动保存,然后再重新打包、部署
这样修改即生效,可以到调度那里再运行测试。