作者 | gongyouliu
编辑 | gongyouliu
自2022年11月30日OpenAI发布chatGPT以来,大模型技术掀起了新一轮人工智能浪潮。chatGPT在各个领域(包括对话、摘要、内容生成、问题解答、识图、数学计算与推理、代码编写等)取得了比之前算法好得多的成绩,很多方面都超越了人类专家的水平,特别是对话交流具备了一定的共情能力,这让AI领域的工作者和普通大众相信AGI(Artificial General Intelligence,通用人工智能)时代马上就要来临了。
最近7-8年都没有哪一项科技进步如chatGPT这般吸引全球的目光(上一次引发全球关注的AI大事件是2016年的AlphaGo)。除了媒体的大肆报道,国内外各个科技公司、科研机构、高等院校都在跟进大模型技术,基于大模型的创业公司比比皆是。
国外有Google发布的Bard、meta发布的LLaMA等,不到半年时间,国外就跑出了非常多的大模型应用的创业公司,做得优秀的如midjourney、jasper、runway等,都获得了上亿美元的融资,估值达数十亿美金规模。
国内也不甘落后,各个大厂、创业公司、科研院校都相继发布了大模型产品(如百度的文心一言、华为的盘古大模型、阿里的通义大模型、复旦的MOSS等),也有不少大佬亲自下场做大模型,如李开复、王慧文、王小川等。
以chatGPT为首的大模型相关技术,可以应用于搜索、对话、内容创作等众多领域,推荐系统也不例外,在这方面已经有非常多的学术研究了,已经发表过众多相关论文。我相信不久大模型相关技术会在工业界大量用于推荐系统,大模型相关技术一定会成为推荐系统的核心技术,就像前几年深度学习技术对推荐系统的革新一样。
chatGPT、大模型相关技术不能被任何人、任何行业忽视,它在各行各业的应用一定会出现井喷。作者在过去一段时间一直在跟进大模型相关技术的进展以及在行业上的应用,特别是在推荐系统领域的应用。为此,我们花两章的篇幅来介绍大模型和推荐系统,希望本书能与时俱进,也希望我们提供的素材能让读者尽快了解大模型相关知识及大模型在推荐系统上的应用。在这个每天都有大模型相关重磅突破的时间节点,我们必须要跟上技术发展的步伐。
我们在本章对chatGPT和大模型相关的知识进行介绍,让读者具备相关的背景知识,对大模型非常熟悉的读者可以跳过本章。具体来说,本章我们从语言模型发展史、全球大模型简介、大模型核心技术简介、大模型应用场景等4个方面来讲解。在下一章我们会重点讲解大模型在推荐系统上的应用。
21.1 语言模型发展史
语言是人类表达和交流的一种突出能力,我们在幼儿开始就学会了沟通表达,并且伴随我们一生。在很长一段时间机器无法掌握以人类的方式进行交流、创作的能力。实现让机器能够像人类一样阅读、书写和交流的能力,一直是学术界一个长期的研究课题,充满挑战。直到以chatGPT为标志性事件的大模型技术的出现,这一愿望才变得可能。大模型是语言模型发展的高级阶段,本节我们来梳理一下语言模型(Language Models,LM)的四个发展阶段,让读者可以更好地了解大模型是怎么进化出来的。
从技术上讲,语言模型是提高机器的语言智能的主要方法之一。一般来说,LM旨在对单词序列的生成概率进行建模,从而预测后面(或中间空缺的)单词的概率。LM的研究在学术界和产业界都受到了广泛的关注。
21.1.1 统计语言模型
统计语言模型(Statistical Language Models,SML,想深入了解SLM的读者可以阅读参考文献1-4)是基于上世纪90年代的统计学习方法的基础上发展而来的。其基本思想是基于马尔可夫假设(基于最近的上下文预测下一个单词)建立单词预测模型。具有固定上下文长度n的SLM也称为n-gram语言模型,例如,bigram和trigram语言模型分别是n=2和n=3。SLM已被广泛应用于提升信息检索(IR)和自然语言处理(NLP)任务的效果。
SLM容易受到维数灾难(the curse of dimensionality)的影响,我们无法估计高阶(即上面的n很大)的语言模型,因为我们需要估计指数级(n的指数)的转移概率,当n很大时,这变得不可能,一般是研究n=2或n=3的情况,也就是bigram和trigram语言模型。
21.1.2 神经网络语言模型
神经网络语言模型(NLM,Neural Language Models,见参考文献5-7)通过神经网络(例如递归神经网络)来表征单词序列的概率。参考文献5的重要贡献是引入了单词的分布式表示的概念,并建立了以聚合上下文特征(即分布式单词向量)为条件的单词预测函数。通过扩展学习单词或句子的有效特征的思想,开发了一种通用的神经网络方法来为各种NLP任务构建统一的解决方案(参考文献8)。此外,word2vec(见参考文献9、10)建立了一个用于学习单词的分布式表示的简化浅层神经网络(我们在第9章9.1.1节介绍过),该网络在各种NLP任务中被证明是非常有效的。这些研究开创了将语言模型用于表示学习(而不是单词序列建模)的新范式,对NLP领域产生了重要影响。
21.1.3 预训练语言模型
预训练语言模型(PLM,Pre-trained Language Models)作为早期的尝试,ELMo(见参考文献11)被发明出来用于捕获上下文感知的单词表示,它首先预训练双向LSTM(biLSTM)网络(而不是学习固定的单词表示),然后根据特定的下游任务微调biLSTM网络。此外,基于具有自注意机制的高度并行性的Transformer架构(见参考文献12)提出的BERT模型(见参考文献13),通过在大规模未标记语料库上预训练双向语言模型和专门设计的预训练任务获得单词的表示,这些预先训练的、上下文感知的单词表示作为通用语义特征非常有效,这在很大程度上提高了NLP任务的性能标准。这些研究启发了大量的后续工作,确立了“先预训练再微调”的学习范式。根据这一范式,已经开发出了大量关于PLM的模型,也引入了不同的架构(例如,GPT-2和BART)或改进的预训练策略。在这种学习范式下,通常需要对PLM进行微调,以适应不同的下游任务。
21.1.4 大语言模型
研究人员发现,扩展PLM(例如,扩展模型大小或数据大小)通常会提高下游任务的模型容量(可以理解为模型预测能力的上限)。许多研究已经通过训练越来越大的PLM(例如,175B参数的GPT-3和540B参数的PaLM)来探索性能极限。尽管缩放主要在模型大小上进行(具有类似的架构和预训练任务),但这些大型PLM表现出与较小PLM不同的行为(例如,330M参数的BERT和1.5B参数的GPT-2),并在解决一系列复杂任务时表现出令人惊讶的能力(称为涌现能力,见参考文献14)。例如,GPT-3可以通过上下文学习(in-context learning)解决few-shot任务(上下文学习和few-shot在21.3节会介绍,这里不展开),而GPT-2则不能很好地解决。因此,学术界为这些大型PLM创造了大型语言模型(LLM,Large Language Models,简称大模型)这个新词,来特指这类模型。LLM吸引了越来越多人的关注,LLM的一个最著名的应用是ChatGPT,它将GPT系列的LLM用于对话,展现了惊人的对话能力。
这里提一下,本章所说的大模型是指参数规模达到10B(也就是100亿)以上规模的模型,这也是行业上大家公认的大模型的参数水平。
LLM和PLM之间有三个主要区别。首先,LLM显示出一些令人惊讶的涌现能力,这在以前的较小PLM中可能没有观察到。这些能力是语言模型在复杂任务中表现出的关键能力,这使得人工智能算法空前强大和有效。其次,LLM将彻底改变人类开发和使用人工智能算法的方式。与小型PLM不同,访问LLM的主要方法是通过提示界面(例如,GPT-4 API)。人类必须了解LLM是如何工作的,并以LLM可以理解的方式格式化他们的任务。第三,LLM的发展不再明确区分研究和工程。LLM的训练需要在大规模数据处理和分布式并行训练方面有丰富的实践经验。为了开发有价值的LLM,研究人员必须解决复杂的工程问题,与工程师合作或者自身需要具备很强的工程能力。
如今,LLM正在对人工智能社区产生重大影响,而ChatGPT和GPT-4的出现引发了大家对人工通用智能(AGI)可能性的重新思考。OpenAI发表了一篇题为“AGI及其后的规划”的技术文章,讨论了接近AGI的短期和长期计划,有些学者认为GPT-4可能就是AGI的早期版本。随着LLM的快速发展,人工智能的研究领域正在发生革命性的变化。在NLP领域,LLM(在某种程度上)可以作为通用语言任务求解器,研究范式已经转向LLM。在IR领域,传统的搜索引擎受到了通过AI聊天机器人(即ChatGPT)获取信息的新方式的挑战,而new Bing提出了一种基于LLM增强搜索结果的初步尝试。在CV领域,研究人员试图开发类似ChatGPT的视觉语言模型,该模型可以更好地服务于多模态对话,GPT-4通过整合视觉信息支持多模态输入。这一新的技术浪潮可能会带来一个繁荣的、基于LLM的应用生态系统。例如,微软365被LLM(即Copilot)加持,可以实现自动化办公,而OpenAI支持在ChatGPT中使用插件来实现特定功能。
尽管LLM取得了进展并产生了影响,但LLM的基本原理仍然没有得到很好的探索。首先,为什么涌现能力出现在LLM中,而不是较小的PLM中,这是很神秘的。我们缺乏对LLM卓越能力的关键因素的深入、详细的分析,研究LLM何时以及如何获得这种能力是很重要的。其次,小型研究机构很难训练出高质量的LLM,主要是由于LLM需要大规模数据、硬件、工程能力的支撑,需要大量的资金。目前LLM主要由大公司训练,其中许多重要的训练细节(如数据收集和清洁)没有对外披露。第三,使LLM与人类价值观或偏好保持一致是一项挑战。尽管LLM能力很强,但也可能产生有毒、虚假或有害的内容,我们需要有效的控制方法来消除LLM使用的潜在风险。
21.2 全球大模型简介
21.1.4节已经对大模型相关的概念进行过简要介绍了,本节我们重点讲解一下OpenAI(这也是大模型时代的核心企业)的模型进化史和全球重要的大模型概况,让读者初步了解重要的大模型生态。
21.2.1 OpenAI大模型发展历程
关于OpenAI网上的介绍非常多了,大家应该也比较熟悉了,我这里不过多说明,这一小节重点讲一下GPT系列的发展历程。GPT系列大体经历了如下6个发展阶段(下图上一行),最新的版本是GPT-4,目前一直在迭代优化中。下图第二行是基于GPT-3.5的一系列迭代版本(大家如果购买过openAI的大模型账号并进行过相关开发,应该是知道这些名字的),这个版本被大家熟知是2022年11月30日发布的chatGPT,目前chatGPT一直在优化中,GPT-4中的能力也逐步融入到了chatGPT中,chatGPT是一个不断进化的系统。
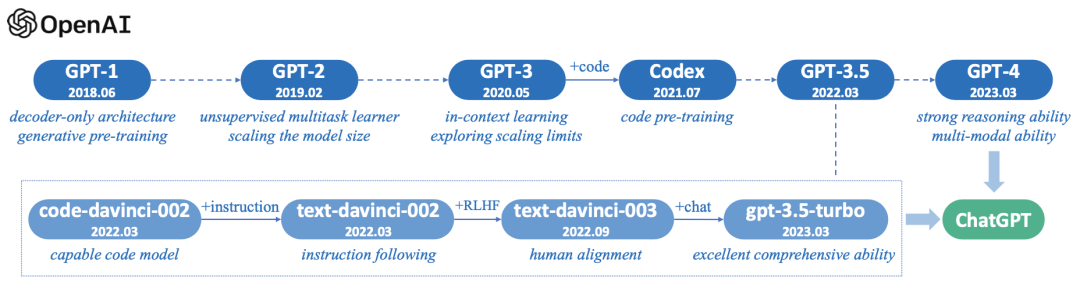
图1:GPT系列模型技术发展的简要说明(图片来源于参考文献19)
21.2.2 全球大模型发展历程
除了OpenAI外,国内外还有非常多的公司参与大模型赛道(国内的报道可以参考晚点发布的「大模型创业潮:狂飙 180 天」,见参考文献15,不过大模型发展太快了,一天一个样,可能等读者看到时,又有新的创业公司加入大模型挑战赛了,或者有更先进、更厉害的模型出现了),下面图2是截止到2023年6月底国内外重要的大模型的发展脉络。
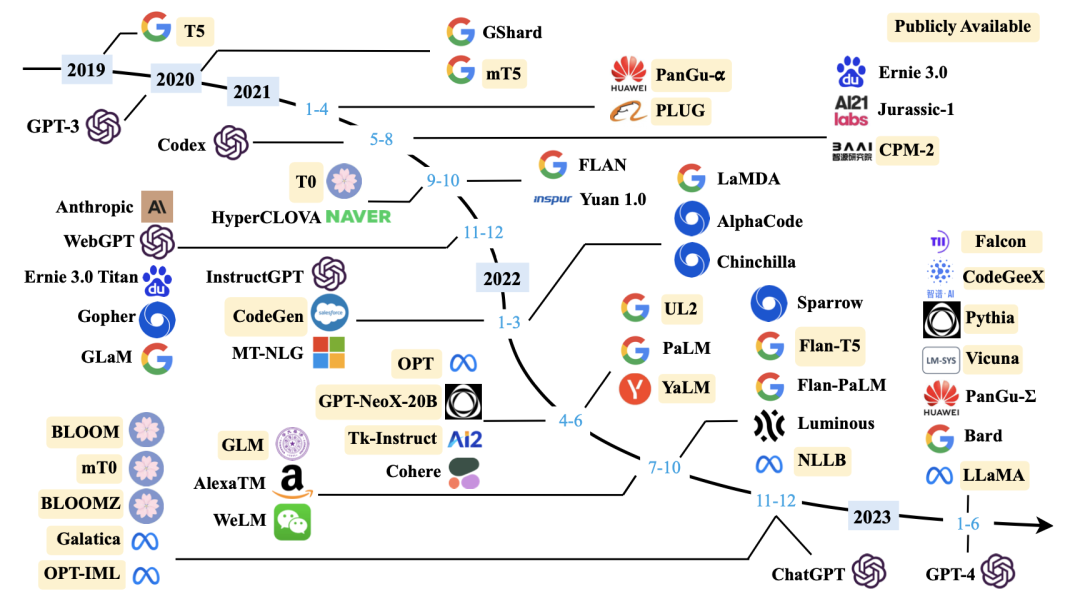
图2:大型语言模型(>=10B)的发布时间线(图片来源于参考文献19)
图2中比较重要的大模型我简单提一下。国外的除了openAI的GPT系列(GPT-1、GPT-2、GPT-3、InstructGPT、chatGPT、GPT-4),还有Google的Bard、Meta(Facebook)的LLaMA,国内有百度的文心一言(Ernie 3.0)、华为的盘古系列(PanGu)等。感兴趣的读者可以基于上图中的模型名称自己去搜索了解,也可以阅读参考文献19,这篇文献是一篇非常全面的介绍大语言模型的发展历史的总结(这篇文章的参考文献多达610篇,也是非常好的学习材料),本章的图片和部分素材来源于这篇论文,强烈建议对大模型感兴趣的读者阅读。
目前所有的大模型架构都是基于Google在2017年发表的一篇著名的Transformer论文(见参考文献31)发展而来的,这篇文章可以说是大模型的祖师爷,有兴趣的读者可以进行阅读。
21.3 大模型核心技术简介
大模型相关技术非常复杂,涉及到算法、工程、软硬件协同、甚至硬件配置、网络布局,想深入学习的读者可以阅读参考文献16-18、32,这4篇文章分别是GPT-1、GPT-2、GPT-3、GPT-4对应的论文,文章对GPT系列大模型相关技术进行了比较详细的介绍。
大模型时代的技术更新太快了,每天跟进都来不及,作者自己最近几个月也是花了非常多的时间跟进最新进展,阅读核心的论文。本节我们简单介绍一下大模型比较特殊的一些技术(相对于之前的小模型),让读者大致知道大模型相关的特点。
21.3.1 预训练技术
给定一个无监督的token语料库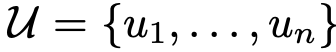 ,我们使用标准语言建模目标函数来最大化以下似然:
,我们使用标准语言建模目标函数来最大化以下似然:
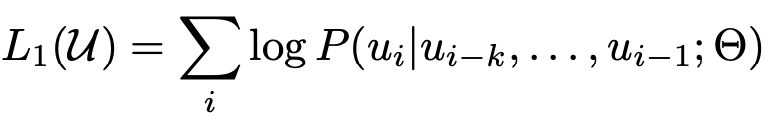
公式1:预训练模型的目标函数
其中k是上下文窗口的大小,条件概率P使用参数为θ的神经网络建模。这些参数使用随机梯度下降法进行训练。一般用多层Transformer解码器(见参考文献20)作为语言模型(即P),它是Transformer的变体。
由于上面的语料库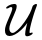 一般是文本文档(比如网页、电子书、论文等),我们用上面的最优化模型是不需要标注数据的,直接用海量的文本训练样本进行训练,这个过程就是预训练。
一般是文本文档(比如网页、电子书、论文等),我们用上面的最优化模型是不需要标注数据的,直接用海量的文本训练样本进行训练,这个过程就是预训练。
预训练为LLM的能力奠定了基础。通过大规模语料库的预训练,LLM可以获得基本的语言理解和生成技能。在这个过程中,预训练语料库的规模和质量对于LLM获得强大的能力至关重要。此外,为了有效地预训练LLM,需要对数据进行各种预处理工作,还需要精心设计模型架构、模型加速方法和优化技术。预训练具体的细节读者可以参考上面提到的几篇论文相关的章节介绍,这里不详细展开。
21.3.2 微调(Adaptation)技术
经过预训练,LLM可以获得解决各种任务的一般能力,但是为了在特定问题或者领域有更好的表现,需要对预训练模型进行微调,微调过程是监督学习任务。
在用公式1中的目标函数训练模型之后,我们再通过监督目标任务对参数进行调整。我们假设有一个标记的数据集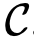 ,其中每个实例由输入token序列
,其中每个实例由输入token序列 ,以及标签y构成。将输入送入我们的预训练模型,以获得最后一个隐藏层的激活函数
,以及标签y构成。将输入送入我们的预训练模型,以获得最后一个隐藏层的激活函数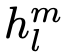 ,然后将其灌入到具有参数
,然后将其灌入到具有参数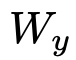 的、增加了一层线性输出层的模型中预测y(是一个多分类问题,所以输出层用了softmax函数):
的、增加了一层线性输出层的模型中预测y(是一个多分类问题,所以输出层用了softmax函数):
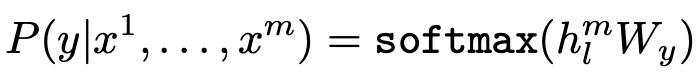
这样我们就获得了如下的求最大值的目标函数:
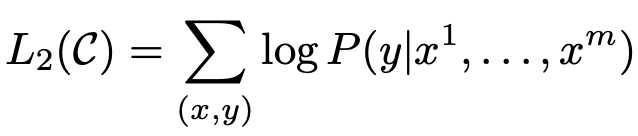
将语言建模作为微调的辅助目标有助于学习,加入辅助目标的模型既可以提高监督模型的泛化能力又可以加速模型的收敛速度。具体而言,就是优化以下目标(权重为λ):
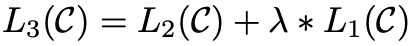
上面讲解的是微调的核心思路,下面我们针对大语言模型,重点说明一下指令微调和对齐微调,这是大语言模型比较有特色的地方。前一种方法旨在增强(或解锁)LLM的能力,而后一种方法旨在调整LLM的行为让模型具有人类价值观或偏好(即跟人类的价值观对齐)。
21.3.2.1 指令微调(Instruction Tuning)
与预训练不同,指令微调通常更有效,因为只有中等数量的样本用于训练。由于指令微调是一个有监督的训练过程,其优化在几个方面与预训练不同,例如训练目标(比如序列到序列的loss)和优化配置参数(比如较小的批大小和学习率)。
本质上,指令微调是在以自然语言表示的格式化样本集合上微调预先训练的LLM的方法。为了执行指令微调,我们首先需要收集或构造满足指令格式的样本。然后,我们使用这些格式化的样本以监督学习的方式对LLM进行微调(例如,使用序列到序列loss进行训练)。在指令微调后,LLM在未知任务上表现出卓越的能力,即使在多语言环境中也是如此(参考下面图3对传统监督学习和指令微调学习的差异)。关于指令微调的详细介绍,读者可以阅读这方面的综述文章(见参考文献21,图3也是来源于这篇文章)。
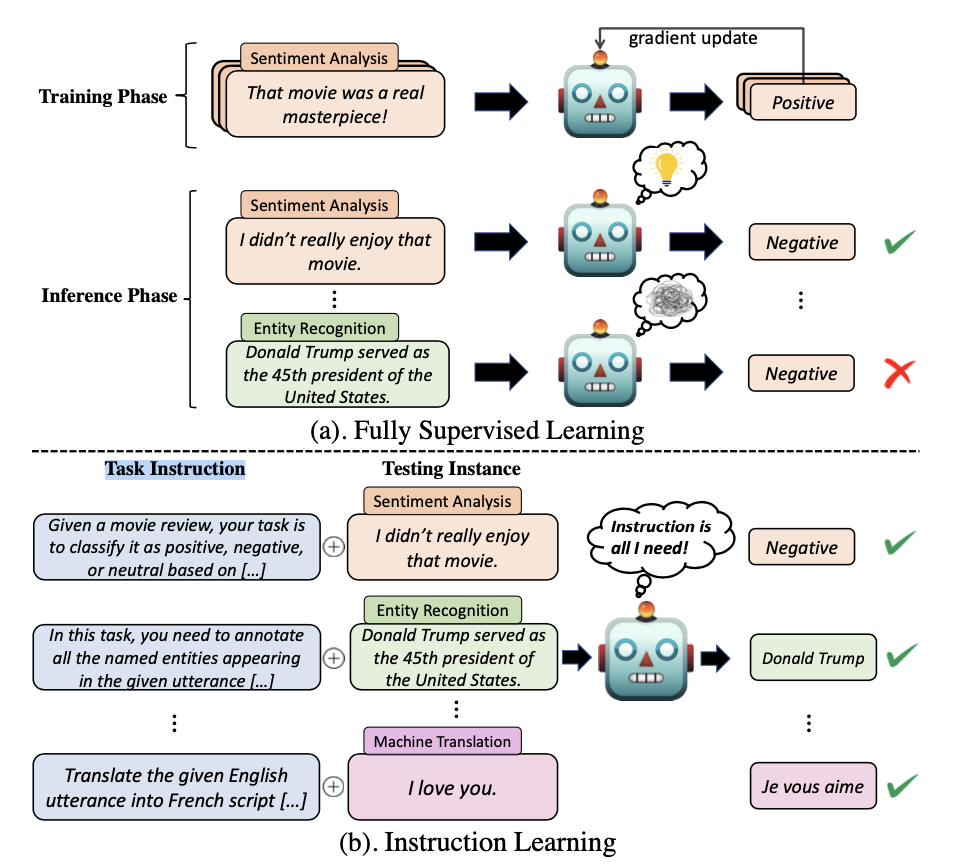
图3:两种机器学习范式:(a)传统的完全监督学习使用广泛的标记示例来表示任务语义,构建过程是昂贵的,由此产生的系统很难推广到新的任务中;(b) 指令学习利用任务指令指导系统快速适应各种新任务。
21.3.2.2 对齐微调(Alignment Tuning)
LLM在广泛的NLP任务中显示出非凡的能力。然而,这些模型有时可能表现出意想不到的行为,例如编造虚假信息、实现不正确的目标以及产生有害、误导和有偏见的言论。LLM模型的目标是通过单词预处理来预训练模型参数,缺乏对人类价值观或偏好的考虑。为了避免这些意想不到的行为,有学者提出了人类对齐(human alignment)的方法,以使LLM的行为符合人类的期望。然而,与最初的预训练和微调(例如,指令微调)不同,这种调整需要考虑非常不同的标准(例如,有用性、诚实性和无害性)。研究表明,人类对齐能在一定程度上损害了LLM的一般能力(即为了实现人类对齐,让LLM在其它任务上的表现变差),相关文献称之为对齐税(alignment tax)。
现在人们越来越关注制定各种标准来规范LLM的行为。在这里,我们以三个具有代表性的对齐标准(即有用、诚实和无害)为例进行讨论,这些标准在现有已被广泛采用。此外,从不同的角度来看,LLM还有其他对齐标准,包括行为、意图、激励和内部特性,这些标准与上述三个标准基本相似(或至少从技术处理上相似)。
为了使LLM与人类价值观保持一致,研究者们已经提出了从人类反馈中强化学习(RLHF,Reinforcement Learning from Human Feedback)(见参考文献23、24),以利用收集的人类反馈数据对LLM进行微调,这有助于改进一致的标准(例如,有用性、诚实性和无害性)。RLHF采用强化学习(RL)算法(例如PPO算法),通过学习奖励模型使LLM适应人类反馈。这种方法将人类纳入训练循环,以开发良好对齐的LLM(如InstructGPT模型就将RLHF作为核心方法,见参考文献22)。
RLHF系统主要包括三个关键组件:预先训练的待对齐的LM、从人类反馈中学习的奖励模型和训练LM的RL算法。具体来说,预先训练的LM通常是一个生成模型,它是用现有的预先训练的LM参数初始化的。例如,OpenAI使用175B GPT-3作为其第一个流行的RLHF模型(即InstructGPT)待对齐的LM,DeepMind使用2800亿参数模型Gopher作为其GopherCite模型的待对齐LM。此外,奖励模型(RM)通常以标量值的形式提供反映人类对LM生成的文本的偏好的监督信号(即通过人类反馈来说明生成文本是否有用、是否诚实、是否无害)。奖励模型可以采取两种形式:微调的LM或使用人类偏好数据从头训练的LM。现有工作通常采用具有不同于对齐LM的参数尺度的奖励模型。例如,OpenAI使用6B GPT-3、DeepMind使用7B Gopher作为奖励模型。最后,为了使用来自奖励模型的信号来优化预训练待对齐的LM,需要设计一种用于大规模模型调整的特定RL算法,具体而言,PPO算法是现有工作中广泛使用的RL算法。下面图4是RLHF的具体工作流,主要有如下3个步骤,下面逐一说明。
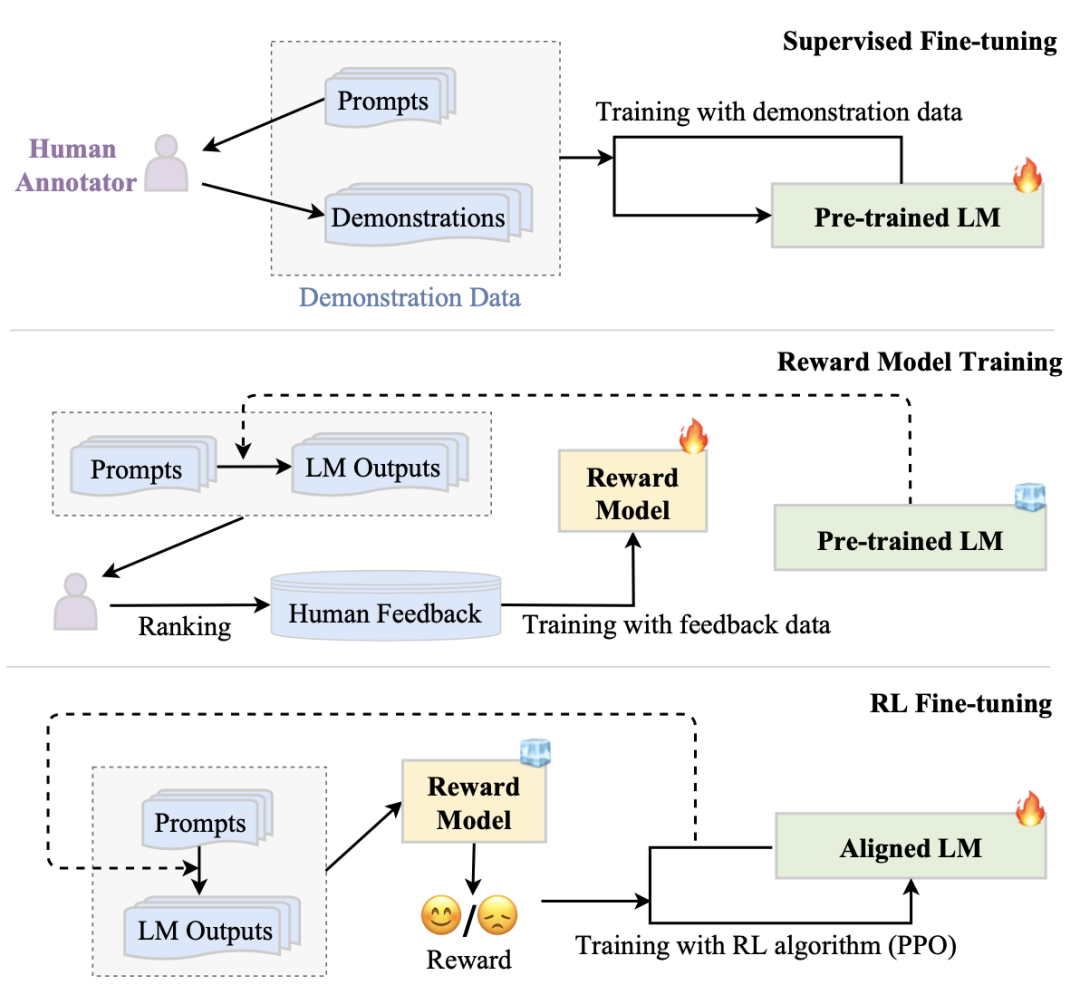
图4:RLHF算法的工作流(图片来源于参考文献19)
第一步:监督微调。为了使LM最初执行所需的行为,它通常需要收集一个监督数据集,该数据集包含用于微调LM的输入提示(指令)和所需输出。这些提示和输出可以由人工标注人员为某些特定任务编写,同时确保任务的多样性(主要目的是提升模型的泛化能力)。例如,InstructionGPT要求人类标注者为一些生成性任务(如开放式QA、头脑风暴、聊天和重写)编写提示(例如,“列出如何重新对我的职业充满热情的五个想法”)和所需输出。
第二步:奖励模型训练。第二步是使用人类反馈数据来训练RM。具体而言,我们利用LM使用抽样的提示(来自监督数据集或人工生成的提示)作为输入来生成一定数量的输出文本。然后,我们邀请人类标注师来评估对这些<输入, 输出>对的质量。标注过程可以以多种形式进行,一种常见的方法是通过对生成的候选文本进行排序来进行标注,这可以减少标注者之间的不一致性。然后,对RM进行训练,以预测人类偏好的输出。在InstructGPT中,标注者将模型生成的输出从最好到最差进行排序,并训练RM(即6B的GPT-3)来预测排序。
第三步:RL微调。在这个步骤中,将LM的对齐(即微调)形式化为RL问题。在这种设置中,预先训练的LM充当策略,该策略将提示作为输入并返回输出文本,其动作空间是词汇表,状态是当前生成的token序列,并且奖励由RM提供。为了避免与初始(调整前)LM显著偏离,惩罚项通常被纳入奖励函数中。例如,InstructGPT使用PPO算法针对RM优化LM。对于每个输入提示,InstructGPT计算当前LM和初始LM的生成结果之间的KL偏差作为惩罚。要注意的是,第二步和最后一步可以多次迭代,以便更好地(基于人类的偏好)对齐LLM。
21.3.3 应用(utilization)学习
在预训练或适应调整之后,使用LLM的一个主要方法是设计合适的提示策略来解决各种任务。一种典型的提示方法是上下文学习(见参考文献25),它以自然语言文本的形式制定任务描述和/或式例(demonstrations)。此外,思维链提示(CoT,见参考文献26)可以通过在提示中插入一系列中间推理步骤来增强上下文学习。此外,还有一种解决复杂任务方法是规划(planning,见参考文献27),该方法首先将任务分解为较小的子任务,然后生成一个行动计划来逐个解决这些子任务。接下来,我们简单介绍这三种技术。
21.3.3.1 上下文学习(ICL,In-Context Learning,也叫情境学习)
ICL使用格式化的自然语言提示(prompts),包括任务描述和/或一些任务示例(demonstrations)。图5左半部分显示了ICL的示意图。首先,从任务描述开始,从任务数据集中选择几个样本作为式例。然后,它们以特定的顺序组合在一起,形成特定模板的自然语言提示。最后,将待测试的查询实例附加到式例中,作为LLM生成输出的输入。基于任务式例,LLM可以在没有显式梯度更新的情况下识别并执行新任务。
设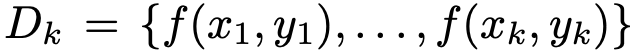 表示一组具有k个示例的样本集,其中
表示一组具有k个示例的样本集,其中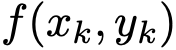 是将第k个任务示例转换为自然语言提示的提示函数。给定任务描述I、式例
是将第k个任务示例转换为自然语言提示的提示函数。给定任务描述I、式例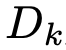 和新的输入查询
和新的输入查询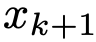 ,从LLM生成的输出
,从LLM生成的输出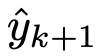 的预测可以公式化如下:
的预测可以公式化如下:
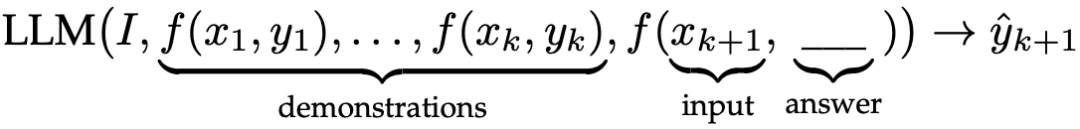
公式2:ICL的形式化说明
其中实际预测结果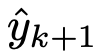 被留白,待LLM预测。由于ICL的性能在很大程度上依赖于式例,因此在提示中正确设计式例非常重要。关于ICL的详细介绍,建议读者阅读参考文献25。
被留白,待LLM预测。由于ICL的性能在很大程度上依赖于式例,因此在提示中正确设计式例非常重要。关于ICL的详细介绍,建议读者阅读参考文献25。
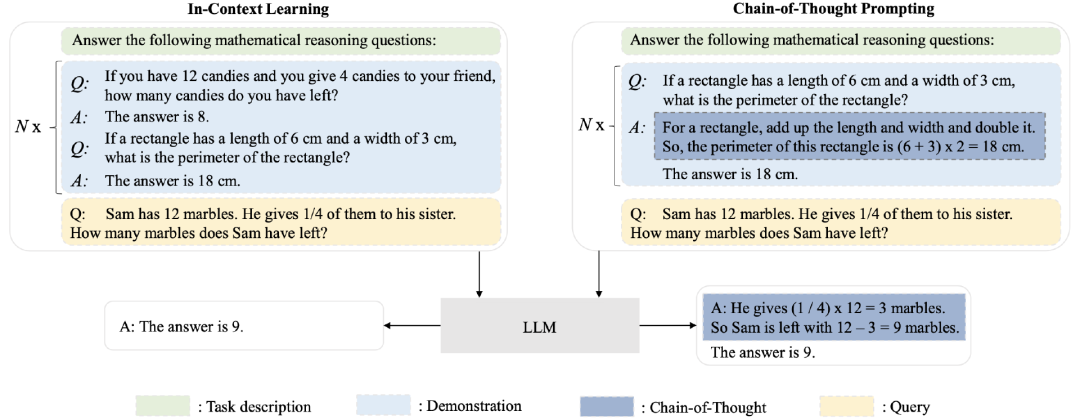
图5:上下文学习(ICL)和思维链(CoT)提示的比较说明。ICL用任务描述、几个演示式例和一个查询提示LLM,而CoT提示涉及提示中的一系列中间推理步骤(图片来源于参考文献19)
21.3.3.2 思维链提示(Chain-of-Throught Prompting)
思维链(CoT)是一种改进的提示策略,用于提高LLM在复杂推理任务上的性能,如算术推理、常识推理和符号推理。CoT没有像ICL中那样简单地用输入输出对构建提示,而是在提示中结合了中间推理步骤,这些步骤可以引导最终输出(过程参见上面的图5右半部分)。
下面我们将详细说明怎么与ICL一起使用CoT,并讨论CoT提示何时以及为什么有效。通常,CoT可以以2种方式与ICL一起使用,即少样本CoT(few-shot CoT)和零样本CoT(zero-shot CoT)。
few-shot CoT是ICL的一种特殊情况,它通过结合CoT推理步骤,将每个式例的<输入, 输出>扩充为<输入, CoT, 输出>。设计适当的CoT提示对于有效地激发LLM的复杂推理能力至关重要。作为一种直接的方法,使用不同的CoT(即每个问题有多个推理路径)可以有效地提高学习性能。另一个直观的想法是,具有更复杂推理路径的提示更有可能激发LLM的推理能力,这可以让生成正确答案的准确性更高。然而,所有这些方法都依赖于带标注的CoT数据集,这限制了它们在实践中的使用。为了克服这一局限性,Auto-CoT建议利用zero-shot CoT通过特定的提示让LLM来生成CoT推理路径,从而消除手动操作。
与few-shot CoT不同,zero-shot CoT提示中不包括人工标注的任务式例。相反,它直接生成推理步骤,然后使用生成的CoT来导出答案。zero-shot CoT是在参考文献28中首次提出的,其中LLM首先由“让我们一步一步思考”提示生成推理步骤,然后由“因此,答案是”提示得出最终答案。当模型大小超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,这表明大模型存在显著的涌现能力。
21.3.3.3 规划(Planning)
使用ICL和CoT提示是概念简单但是能解决各种任务的通用方法。然而,这种方法难以处理复杂的任务,如数学推理和多跳(multi-hop)问答。为了解决这些复杂问题,一种基于提示的计划方法(prompt-based planning)被提出,这个方法将复杂的任务分解为更小的子任务,并生成完成任务的行动计划。具体的步骤读者可以参考下面的图6,下面我们来简单说明具体细节。
在这个技术范式中,通常有三个组成部分:任务规划器(task planner)、计划执行器(plan executor)和环境(environment)。具体来说,由LLM扮演的任务规划器旨在生成解决目标任务的整个计划。计划可以以不同的形式存在,例如,自然语言形式的动作序列或用编程语言编写的可执行程序。然后,计划执行器负责执行计划中的行动。它可以通过文本任务的LLM等模型来实现,也可以通过具体任务的机器人等对象来实现。此外,环境是指计划执行器执行行动的地方,可以根据具体任务进行不同的设置,例如LLM本身或Minecraft等外部虚拟世界。它以自然语言或其他多模态信号的形式向任务规划器提供有关动作执行结果的反馈。
对于解决复杂任务,任务规划器首先需要清楚地理解任务目标,并根据LLM的推理生成合理的计划。然后,计划执行器根据环境中的计划行事,环境会为任务规划器产生反馈。任务规划器可以进一步结合从环境中获得的反馈来完善其初始计划,并迭代执行上述过程,以获得更好的结果作为任务解决方案。
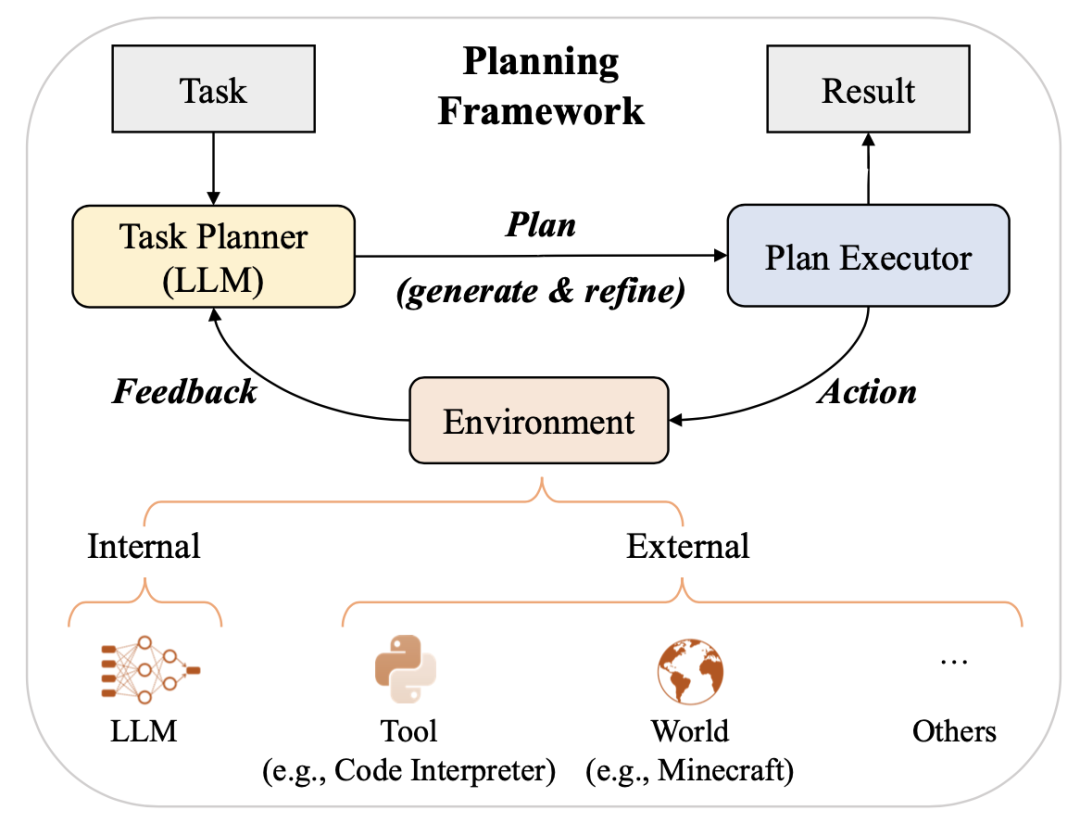
图6:LLM为解决复杂任务而制定的基于提示的计划(图片来源于参考文献19)
21.4 大模型的应用场景
前面我们对大模型的发展历程、国内外的主流大模型及大模型相关的核心技术进行了简单介绍,大家应该对大模型相关知识有了一个初步的了解。大模型被专家、学者一致认为可能是第四次AI革命的“导火索”,极有可能推动AGI时代的到来。
既然大家都这么看好大模型技术,那么大模型的价值体现在什么地方呢?我们可以从大模型能够解决什么问题的角度出发,梳理大模型对个人生活、对企业运营、对社会发展可能带来的影响和革新,因此本节我们重点讲解个5大模型具有颠覆性的应用场景(对于当今最强的GPT-4的能力,大家可以阅读参考文献30)。
21.4.1 内容生成
我们这里的内容生成是广义的,包括文本、图片、视频、音频、代码等,以及对文本内容进行总结、从图片或者视频中提取信息等都属于此范畴。内容生成应该是大模型最直接的应用场景,我们从下面5个场景展开说明。
文本生成
相信chatGPT刚出来的时候,绝大多数人都用过chatGPT生成文本的能力。目前大模型可以基于用户输入的提示生成各种内容,有营销内容、特定领域的文章、各种建议、对某个事情或者问题的观点等,甚至有很多人已经用chatGPT出版了书。
在这个领域,影响最大的是文字工作者,比如自媒体、编辑、文秘、作家等。目前大模型生成的内容还不能直接拿来用,需要人工进行审核、调整,修改不当的地方。大模型是文字工作者最好的帮手,可以给创作者提供思路,创作原型,因此可以极大地提升创作效率。
内容摘要
所谓内容摘要,就是基于一篇已有的内容,让大模型帮你进行总结,提取出核心观点。既可以从文本中提取摘要,也可以对图片、甚至是视频进行总结。
内容摘要的应用场景还是挺多的。对于文本进行摘要可以帮忙读者更快了解文章的主题,从而决定值不值得全部看一遍。另外,对于科研工作者,利用摘要的能力,可以极大提高文献阅读效率(先让大模型提取摘要,这就大致知道这篇文章的重点了)。
图片生成
目前大模型可以基于一段文字描述生成图片,还可以生成相似图片,以及对图片进行风格迁移。这里面比较有名的是midjourney(公司)、stable diffusion(开源项目)等。下面图就是之前走红网络的、midjourney生成的中国情侣的照片(图片来源于midjourney的大模型生成程序),大家可以看到图片细节是非常逼真的。这方面的图非常多,相信读者应该之前都看到过。

大模型生成图片的应用价值非常大,比如文章配图、文内关键段落配图、电影电视剧海报图、广告宣传图、电商的物料图等。大模型对以绘画为职业的人冲击非常大,像游戏公司之前有很多插画师,现在基本都可以用大模型来替代了,之前国内就报道过有家游戏公司裁掉了大量的游戏插画师。
视频生成
大模型的视频生成能力,可以基于一段文本描述生成逼真的视频,目前生成的视频的时长和清晰度还待优化,在视频生成领域比较出名的公司是runway。参考文献29中有一段生成的海底生物的视频看起来比较惊艳,读者可以看看。
视频生成领域的应用价值,相信读者可以感知到,比如创意、宣传、教学、影视、游戏等领域都可以从视频自动生成中获得极大的生产力。
代码生成
大模型基于代码数据训练后,具备了代码纠错、找bug、自动写代码的能力。这对于程序员的生产力提升是不言而喻的,GitHub网站上30%新代码是在AI编程工具Copilot(大模型)帮助下完成的。未来随着大模型代码能力的增强,对初中级程序员是致命打击,很多编程工作可能都被机器替代了。但是资深程序员、架构师不会受影响。
21.4.2 问题解答
大模型的问题解答能力包括知识性问题、科学计算、逻辑推理(比如数学证明、事件推理)等几大块。2023年3月份GPT-4刚发布时,在发布会上就宣称了GPT-4在各类考试(比如SAT)、比赛中的能力能达到top级的水平(见参考文献30),这体现了大模型在问题解答方面的超强能力。
问题解答能力的应用场景也非常多,比如考试、学习、法律咨询、心理咨询、职业咨询、医疗诊断、投资理财等,这些领域相关的问题都可以利用大模型提供的能力来解答。当然,绝大多数应用,需要回答的准确度达到要求,特别是医疗等领域对内容的专业度、准确性有极高的要求,在这些领域目前大模型是不能独立胜任的,需要专家最后把关,这些领域中的大模型相关技术还需要进一步完善和提升。
21.4.3 互动式对话
chatGPT刚发布时是以聊天对话的形式提供服务的,就是大家熟知的聊天机器人(前几年的微软小冰就引爆了聊天机器人领域)。大家惊奇的发现chatGPT的对话能力就像是真人一样,情商非常高,非常聪明。正是大模型这种让人感受到智能的对话能力,让互动式对话应用场景有极大的市场空间。
互动式对话本质上是借助内容生成、问题解答并可能结合一些外部资源(比如借助搜索引擎)以对话的方式跟人(或者机器)交流,是对交互方式的一种革新。基于互动式对话的大模型能力可以赋能非常多的行业和场景。
最直接的应用是智能客服场景,不管是通过拨打电话的方式(如电话销售、电话客服等)、还是对话助手(比如在淘宝APP上跟商家沟通时先是机器人客服互动的,后面解决不了会切换到真人)的方式,都可以利用大模型进行赋能。这类垂直应用行业很多,比如问诊、理财咨询、法律咨询等,都可以利用互动式对话的形式实现,这样体验更好。
还有一种互动方式是借助硬件来实现,这个硬件可能是平板(比如科大讯飞的AI学习机)、也可能是音箱(比如百度的小度音箱、阿里的天猫精灵等)、也可能是(人形)机器人(比如送餐机器人、图书馆的借书服务机器人等)。未来在老人陪伴护理、少儿看护、机器人伴侣等各个细分场景都有极大的市场空间。
另外,在虚拟人/数字人场景中的应用空间也极大。借助人体行为建模、TTS能力,配合大模型的对话互动能力,完全可以打造应用于各类垂直场景的数字人。这方面的应用主要有视频、直播,包括金融、保险等场景的投教视频、直播教学视频等。现在大火的直播带货也可以利用数字人进行直播,很多初创公司已经在做这方面的探索了,很多公司都通过数字人带来了效率的提升、成本的下降。
21.4.4 生产力工具/企业服务
大家常用的工具,比如excel、word、PPT,以及Photoshop、代码编辑器等,都可以利用大模型提供的强大能力进行赋能。代码编辑器利用大模型进行编码、修bug前面已经提到了,这里不展开。生产力工具和企业服务方面的应用我们下面举例说明。
微软于2023年3月16日发布了Microsoft 365 Copilot,该软件集成了GPT-4功能,可以进行文字和图片内容生成、归纳、数据分析和辅助决策等,微软最先将大模型能力引入到了个人和企业服务领域。国内的金山云也不甘示弱,金山办公在2023年7月6日正式推出基于大语言模型的智能办公助手WPS AI,WPS AI是金山办公旗下具备了大语言模型能力的一款生成式人工智能应用,也是中国协同办公赛道首个类ChatGPT式应用。
2023年4月18日,在2023春季钉峰会上,阿里钉钉发了一条斜杠“/”,并现场演示接入千问大模型后,通过输入“/”在钉钉唤起10余项AI能力。目前,钉钉与大模型融合场景正在测试中,将在相关安全评估完成后上线。钉钉总裁叶军现场演示了四个场景:群聊、文档、视频会议及应用开发。可以预见,在不久的将来,基于企业微信、钉钉、飞书生态的各类基于大模型的应用肯定会如雨后春笋一样冒出。
之前阿里CEO张勇在2023年阿里云峰会上说过未来所有云上应用都值得用大模型重做一遍,目前阿里云、百度云、华为云、腾讯云、火山引擎等头部云厂商都陆续发布了基于大模型的云上生产力工具(包括算力支持、模型训练、模型服务、上层应用等整个生态链)。
有了各类云厂商和创业公司的探索,在各类垂直行业(比如金融、医疗、法律、零售、制造业等)构建大模型及相关应用一定是是企业未来智能化转型的方向,这个方向未来至少有10年以上的机会窗口。对大模型在企业服务方面感兴趣的读者可以多关注一下相关新闻动态,我相信不出2年各家云厂商和很多创业公司一定像水电煤一样便捷地供应大模型相关能力供各类行业应用。
21.4.5 搜索推荐
大模型在搜索上的尝试的战火最早是由微软烧起的。大家都知道微软是openAI的最大投资方,因此获得了openAI的大模型系列能力的独家商业使用权。当chatGPT发布不久,微软就宣布将大模型整合到必应(www.bing.com)搜索引擎中,以期能从Google搜索市场份额中分一杯羹。
利用大模型加持的搜索引擎,完全革新了之前搜索引擎的范式(之前是对互联网上已有的知识进行索引,再基于用户输入关键词进行匹配排序),大模型是预先对世界上的知识进行压缩,然后基于用户输入的文本生成最匹配的内容,是对压缩知识的组合式、生成式创造的过程。大模型让搜索的范式从判别式建模过度到了生成式建模。
微软推出大模型版本的bing之后,Google内部非常紧张,不久就发布Bard大模型来迎战chatGPT,并且也将大模型相关的能力逐步应用到了搜索整个生态系统中。国内的百度、360等搜索公司也都推出了自己的大模型产品并且也在尝试整合到自家搜索系统中对搜索引擎进行迭代升级。
大模型在推荐系统上也有极大的用武之地。推荐系统是基于用户过往行为对用户兴趣进行建模,进而预测用户未来的兴趣。用户过往兴趣完全可以作为大模型的输入,通过大模型获得输出反馈(即对用于兴趣的预测),本章我们不展开,这部分内容我们在下一章花一章的篇幅来详细讲解大模型怎么应用于推荐系统。
总结
本章我们对大模型相关的发展历史、openAI技术的发展脉络、当前国内外主流的大语言模型进行了简单的介绍,同时针对大模型区别于之前模型的核心技术原理进行了简单讲解,本章提到的预训练、指令微调、对齐微调、上下文学习、思维链提示、规划等核心技术读者需要了解。相信通过本章的讲解,读者大致了解了大模型相关的知识。
本章我们在最后一节从内容生成、问题解答、互动式对话、生产力工具/企业服务、搜索推荐等5个维度介绍了大模型能够赋能的领域和应用场景。未来大模型一定会革新所有的行业和场景的。读者需要对大模型相关的技术及行业、场景应用保持敏感,在工作中要将大模型相关的技术用起来。作者在本书中增加关于大模型的基础知识和在推荐系统的应用这两章,也是想让读者更加了解和关注大模型。本章的讲解就到这里了,下一章我们会深度讲解大模型在推荐系统中的应用。
参考文献
F. Jelinek, Statistical Methods for Speech Recognition. MIT Press, 1998.
J. Gao and C. Lin, “Introduction to the special issue on statistical language modeling,” ACM Trans. Asian Lang. Inf. Process., vol. 3, no. 2, pp. 87–93, 2004.
R. Rosenfeld, “Two decades of statistical language modeling: Where do we go from here?” Proceedings of the IEEE, vol. 88, no. 8, pp. 1270–1278, 2000.
A. Stolcke, “Srilm-an extensible language modeling toolkit,” in Seventh international conference on spoken language processing, 2002.
Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin, “A neural probabilistic language model,” J. Mach. Learn. Res., vol. 3, pp. 1137–1155, 2003.
T. Mikolov, M. Karafia ́t, L. Burget, J. Cernocky ́, and S. Khudanpur, “Recurrent neural network based language model,” in INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September 26-30, 2010, T. Kobayashi, K. Hirose, and S. Nakamura, Eds. ISCA, 2010, pp. 1045–1048.
S. Kombrink, T. Mikolov, M. Karafia ́t, and L. Burget, “Recurrent neural network based language modeling in meeting recognition,” in INTERSPEECH 2011, 12th Annual Conference of the International Speech Communication Association, Florence, Italy, August 27-31, 2011. ISCA, 2011, pp. 2877–2880.
R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. P. Kuksa, “Natural language processing (almost) from scratch,” J. Mach. Learn. Res., vol. 12, pp. 2493–2537, 2011.
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, C. J. C. Burges, L. Bot- tou, Z. Ghahramani, and K. Q. Weinberger, Eds., 2013, pp. 3111–3119.
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2013.
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACLHLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), M. A. Walker, H. Ji, and A. Stent, Eds. Association for Computational Linguistics, 2018, pp. 2227–2237.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, 2017, pp. 5998–6008.
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Association for Computational Linguistics, 2019, pp. 4171–4186.
J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,” CoRR, vol. abs/2206.07682, 2022.
https://mp.weixin.qq.com/s/yodYn8oXDtHEzyRFZrICuw
Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. Mc- Candlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Ad- vances in Neural Information Processing Systems 33: An- nual Conference on Neural Information Processing Sys- tems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
2023. Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie and Ji-Rong Wen,A Survey of Large Language Models
P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer. Generating wikipedia by summarizing long sequences. ICLR, 2018.
R. Lou, K. Zhang, and W. Yin, “Is prompt all you need? no. A comprehensive and broader view of instruction learning,” CoRR, vol. abs/2303.10475, 2023.
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wain- wright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” CoRR, vol. abs/2203.02155, 2022.
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 4299– 4307.
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Rad- ford, D. Amodei, P. F. Christiano, and G. Irving, “Fine- tuning language models from human preferences,” CoRR, vol. abs/1909.08593, 2019.
Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, L. Li, and Z. Sui, “A survey for in-context learning,” CoRR, vol. abs/2301.00234, 2023.
J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” CoRR, vol. abs/2201.11903, 2022.
D. Zhou, N. Scha ̈rli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, O. Bousquet, Q. Le, and E. H. Chi, “Least-to-most prompting enables complex reasoning in large language models,” CoRR, vol. abs/2205.10625, 2022.
T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwa- sawa, “Large language models are zero-shot reason- ers,” CoRR, vol. abs/2205.11916, 2022.
https://mp.weixin.qq.com/s/9Klm-HK00cKGnlLI39XuMA
https://mp.weixin.qq.com/s/kA7FBZsT6SIvwIkRwFS-xw
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, 2017, pp. 5998–6008.
OpenAI, “Gpt-4 technical report,” OpenAI, 2023.