前面学习了一下论文:Improved Field-Based Soybean Seed Counting and Localization with Feature Level Considered
论文链接:https://spj.science.org/doi/10.34133/plantphenomics.0026
解读链接:论文阅读--考虑特征水平的改进的基于田间的大豆种子计数和定位_追忆苔上雪的博客-CSDN博客
下面开始着手复现p2p大豆计数模型
(一)p2p人群计数源码以及复现
由于p2p大豆计数模型建立在p2p人群计数,这里提供一下p2p人群计数代码
<1>p2p人群计数源码:https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet
<2>p2p人群计数源码复现过程:
crowdcountingp2p代码复现_追忆苔上雪的博客-CSDN博客
crowdcountingp2p代码复现(续)_追忆苔上雪的博客-CSDN博客
(二)p2p大豆计数代码复现
<1>p2p大豆计数源码
源码地址:https://github.com/UTokyo-FieldPhenomics-Lab/P2PNet-Soy
由于该开源代码是用jupyter写的,不能利用pycharm和pytorch直接进行复现,下面开始介绍利用自己pycharm复现的方法
<2>植物计数方法的拓展
在复现代码之前,先介绍一下植物计数过程需要使用到的方法,大家按需自取,链接附上:
作物计数方法汇总_追忆苔上雪的博客-CSDN博客
作物计数方法之合并信息生成json标签的方法_追忆苔上雪的博客-CSDN博客
这里再拓展一个将标签中提到搭配点的列表完整存入txt文本的方法,方便将p2p大豆计数方法拓展至其他植物
import scipy.io as sio
import numpy as np
import os
mat_filename_list = os.listdir(r"D:\P2P_plant_counting\P2P_watermelon\watermelon_dataset\data_root\test_data\label_mat")
mat_filename_list2 = os.listdir(r"D:\P2P_plant_counting\P2P_watermelon\watermelon_dataset\data_root\train_data\label_mat")
# print(mat_filename_list)
# 批量转化 mat 文件为 txt 文件并保存在 txt_file 文件夹中
for mat_filename in mat_filename_list:
# print(mat_filename)
matdata = sio.loadmat("D:/P2P_plant_counting/P2P_watermelon/watermelon_dataset/data_root/test_data/label_mat/" + mat_filename)
# print(matdata)
data = matdata["image_info"]
array1 = data[0][0][0][0][0]
# print(array1)
for i in array1:
# print(i)
a1 = i[0]
b1 = i[1]
# print(list1)
txt_filename = mat_filename.split('.')[0]
# print(txt_filename)
with open(r'D:\P2P_plant_counting\P2P_watermelon\watermelon_dataset\data_root\test_data\label\{}.txt'.format(txt_filename), 'a') as fp: # a 防止覆盖循环写入
fp.write('['+str(a1)+','+str(b1)+']'+'\n')
fp.close()
for mat_filename2 in mat_filename_list2:
matdata2 = sio.loadmat("D:/P2P_plant_counting/P2P_watermelon/watermelon_dataset/data_root/train_data/label_mat/" + mat_filename2)
# print(matdata)
data2 = matdata2["image_info"]
array2 = data2[0][0][0][0][0]
# print(array1)
for j in array1:
# print(i)
a2 = j[0]
b2 = j[1]
# print(list1)
txt_filename2 = mat_filename2.split('.')[0]
# print(txt_filename)
with open(r'D:\P2P_plant_counting\P2P_watermelon\watermelon_dataset\data_root\train_data\label\{}.txt'.format(txt_filename2), 'a') as fp: # a 防止覆盖循环写入
fp.write('['+str(a2)+','+str(b2)+']'+'\n')
fp.close()则可以将mat标签中提取到点的信息存到txt文本中方便后续训练所需
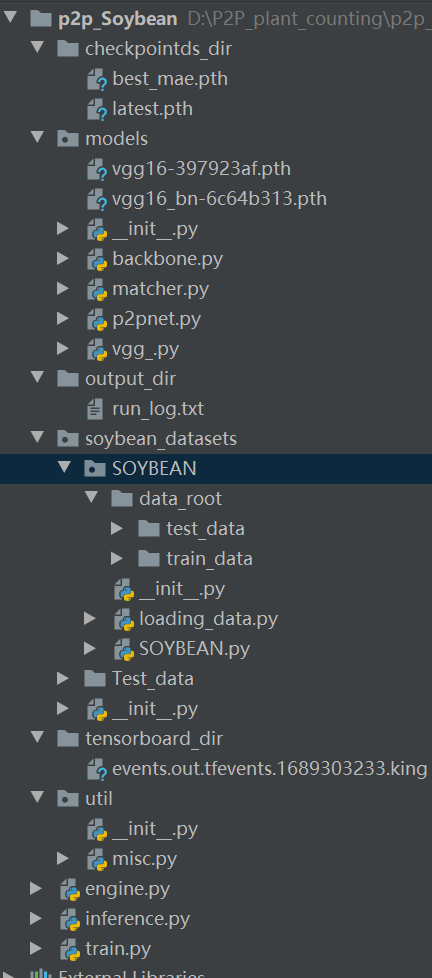
<3>p2p大豆计数框架
p2p大豆计数框架如下图所示,其中数据集在源码中的链接中有下载链接,这里不多做介绍
若是需要自己将p2p计数框架用于其作物,数据制作可以参考上文链接中所介绍的方法
vgg16的权重文件也可自己下载:这里提供链接:
https://download.pytorch.org/models/vgg16_bn-6c64b313.pth
https://download.pytorch.org/models/vgg16-397923af.pth
<4>关键代码介绍
其中数据处理代码相比源码,这里做了一点改变,详见下图
训练代码参数解释
parser.add_argument('--point_loss_coef', default=0.0002, type=float) # default = 0.0002 # 0.5
# the final classification loss = -(the sum of positive confidence score + eos_coef * the sum of negative confidence score)/M, M is total proposed points
parser.add_argument('--eos_coef', default=0.05, type=float, # 0.05
help="Relative classification weight of the no-object class") # default = 0.5
# a threshold during evaluation for counting and visualization
parser.add_argument('--threshold', default=0.5, type=float,
help="threshold in evalluation: evaluate_crowd_no_overlap")
parser.add_argument('--row', default=2, type=int,
help="row number of anchor points")
parser.add_argument('--line', default=2, type=int,
help="line number of anchor points")
# dataset parameters
parser.add_argument('--dataset_file', default='SOYBEAN')
parser.add_argument('--data_root', default='/home/king/Projects/LiuHuaiyang/p2p_plant_counting/p2p_Soybean/soybean_datasets/SOYBEAN/data_root',
help='path where the dataset is')
parser.add_argument('--output_dir', default='output_dir', # 存放输出日志
help='path where to save, empty for no saving')
parser.add_argument('--checkpoints_dir',
default='checkpointds_dir', # 存放权重路径
help='path where to save checkpoints, empty for no saving') # ckpt_5n was not bad, default 2 X 2
parser.add_argument('--tensorboard_dir',
default='tensorboard_dir', # 存放训练阶段和评估阶段loss值
help='path where to save, empty for no saving')parser.add_argument('--data_root用于存放数据集路径
parser.add_argument('--output_dir用于存放 输出日志
parser.add_argument('--checkpoints_dir',用于存放训练的权重路径
parser.add_argument('--tensorboard_dir',用于存放训练阶段和评估阶段loss值
推理代码参数解释
parser = argparse.ArgumentParser(description="Object Counting Framework")
# * Backbone
parser.add_argument('--backbone', default='vgg16', type=str,
help="Name of the convolutional backbone to use")
#vgg16_bn
# a threshold during evaluation for counting and visualization
parser.add_argument('--threshold', default=0.5, type=float,
help="threshold in evalluation: evaluate_crowd_no_overlap")
parser.add_argument('--row', default=2, type=int,
help="row number of anchor points")
parser.add_argument('--line', default=2, type=int,
help="line number of anchor points")
parser.add_argument('--data_root', default='/home/king/Projects/LiuHuaiyang/p2p_plant_counting/p2p_Soybean/soybean_datasets/SOYBEAN/data_root/',
help='path where the dataset is')
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--resume', default="/home/king/Projects/LiuHuaiyang/p2p_plant_counting/p2p_Soybean/checkpointds_dir/best_mae.pth", help='resume from checkpoint') # 训练好的权重位置
parser.add_argument('--vis_dir', default='/media/king/DATA/LiuHuaiyang/p2p_plant_counting/p2p_Soybean/vis_p2pnetSoy_out') # 预测输出路径
parser.add_argument('--eval', action='store_true')
parser.add_argument('--num_workers', default=1, type=int)
parser.add_argument('--gpu_id', default=0, type=int, help='the gpu used for training')
parser.add_argument('--half', default=True, type=bool)parser.add_argument('--resume'用于存放训练好的权重位置
parser.add_argument('--vis_dir'为预测输出路径
<5>p2p大豆计数框架训练与推理
按照上述框架和参数设置好以后,就可以开始训练了,温馨提示,epoch很大的时候不要用自己的电脑训练,最好用服务器训练
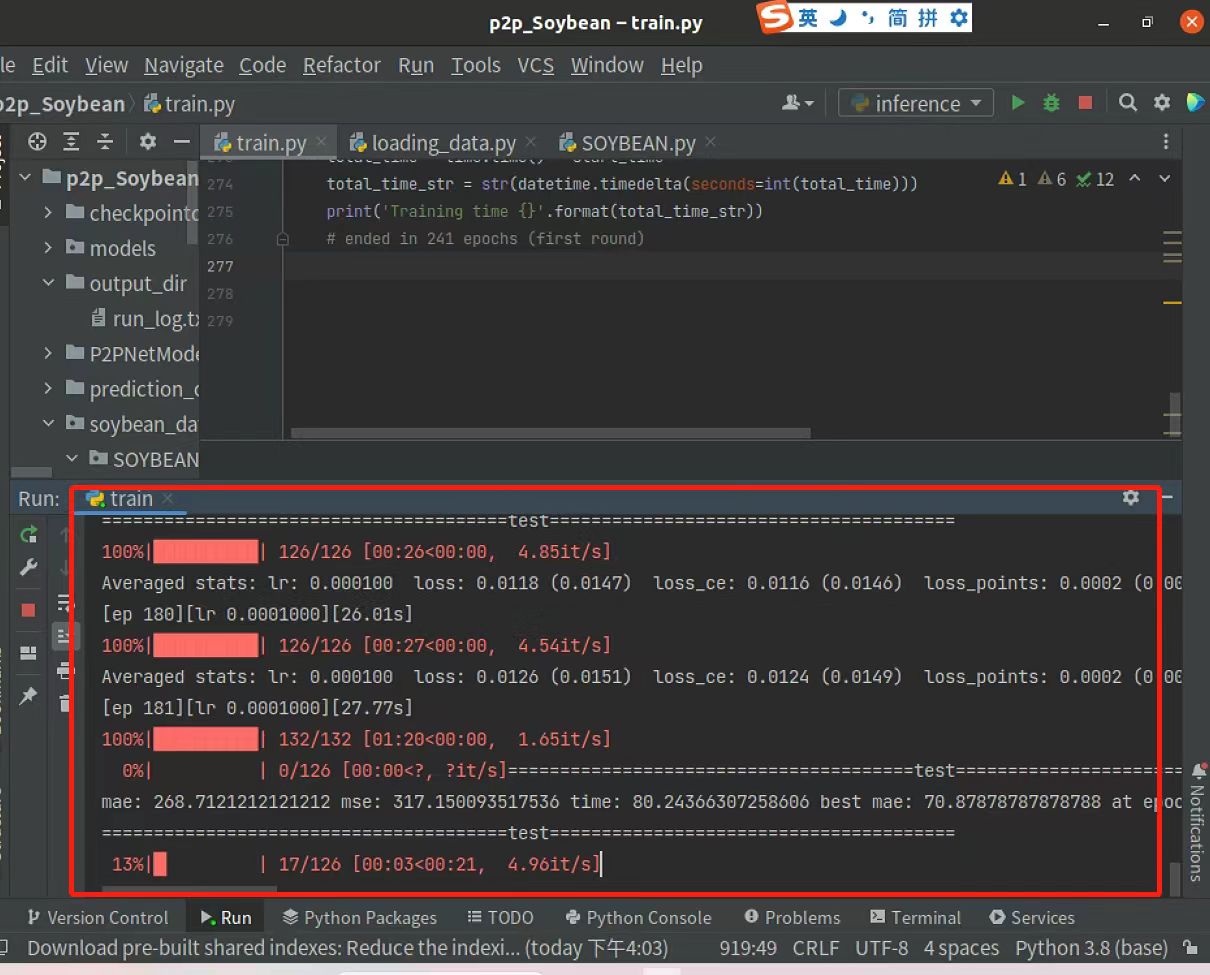
推理效果如图所示,下图是使用训练200epoch的权重预测的图,可以看到有部分豆荚是没有预测到,可以加大训练epoch达到自己想要的效果

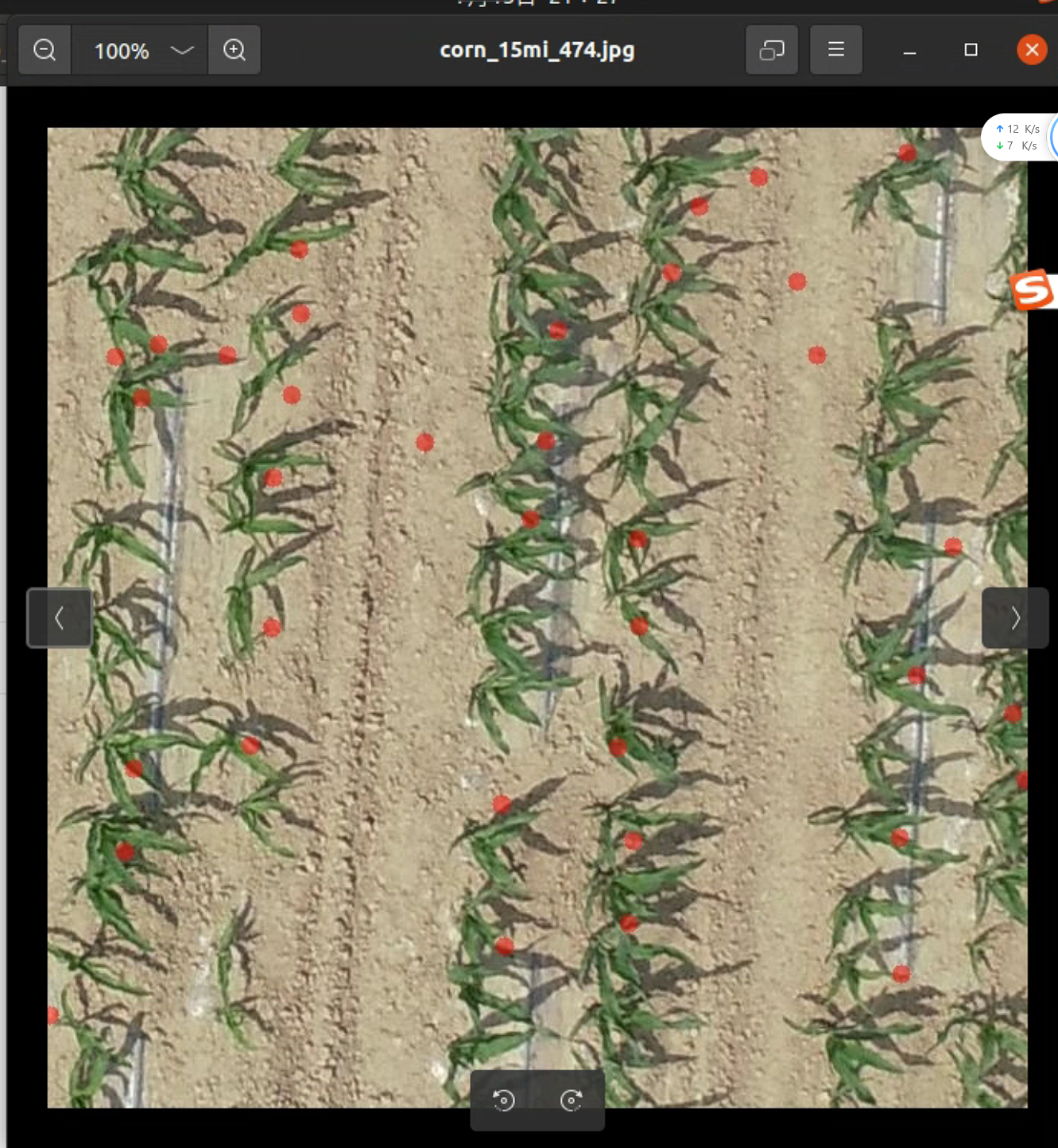
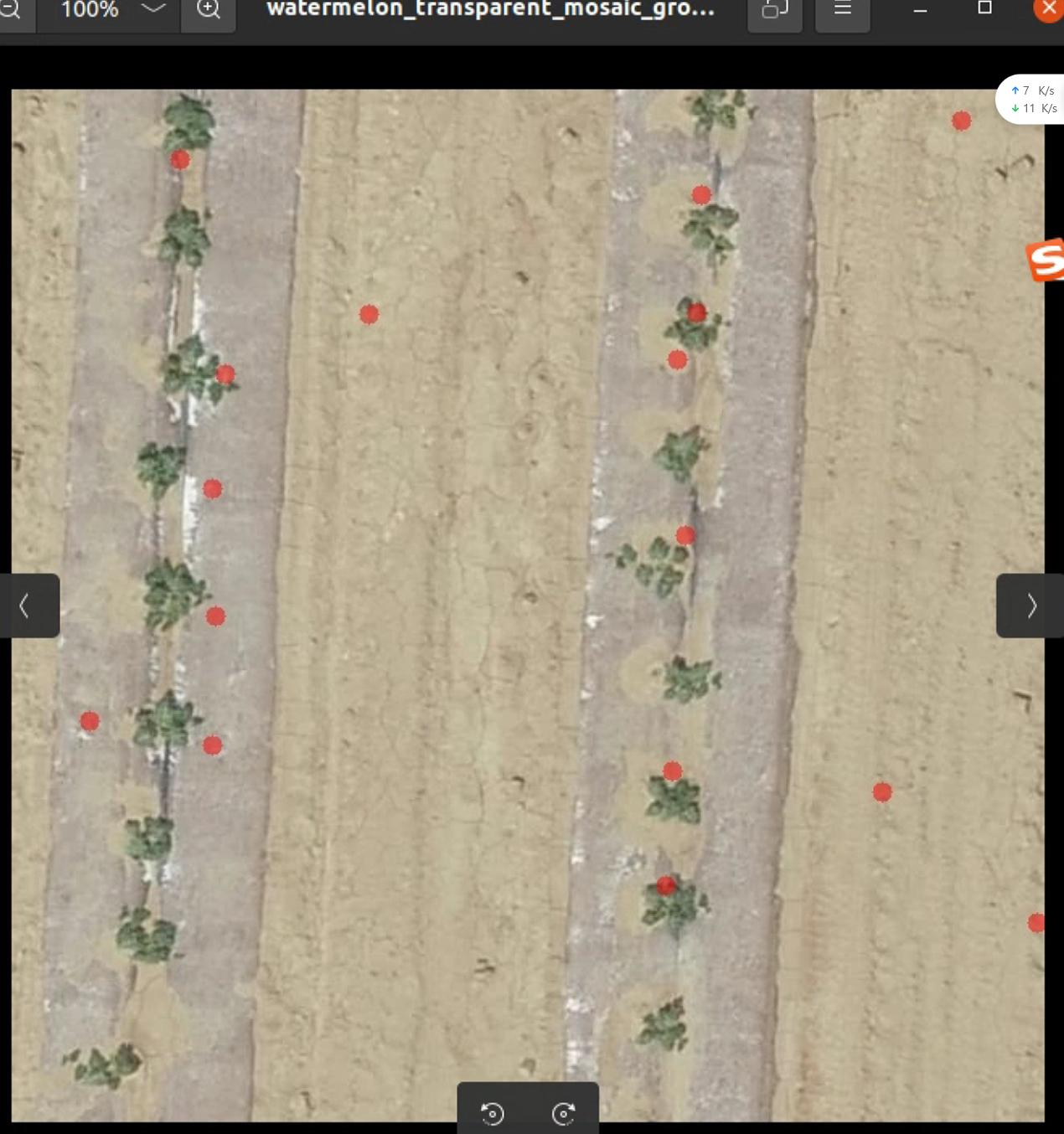
同样的方法预测西瓜苗和玉米苗,会发现预测不准,这个后续再想办法改进模型解决
p2p大豆计数模型pycharm源码已经上传
https://download.csdn.net/download/m0_73832962/88058077?spm=1001.2014.3001.5503
声明:未经本人允许不得转载,搬运或用于其他用途