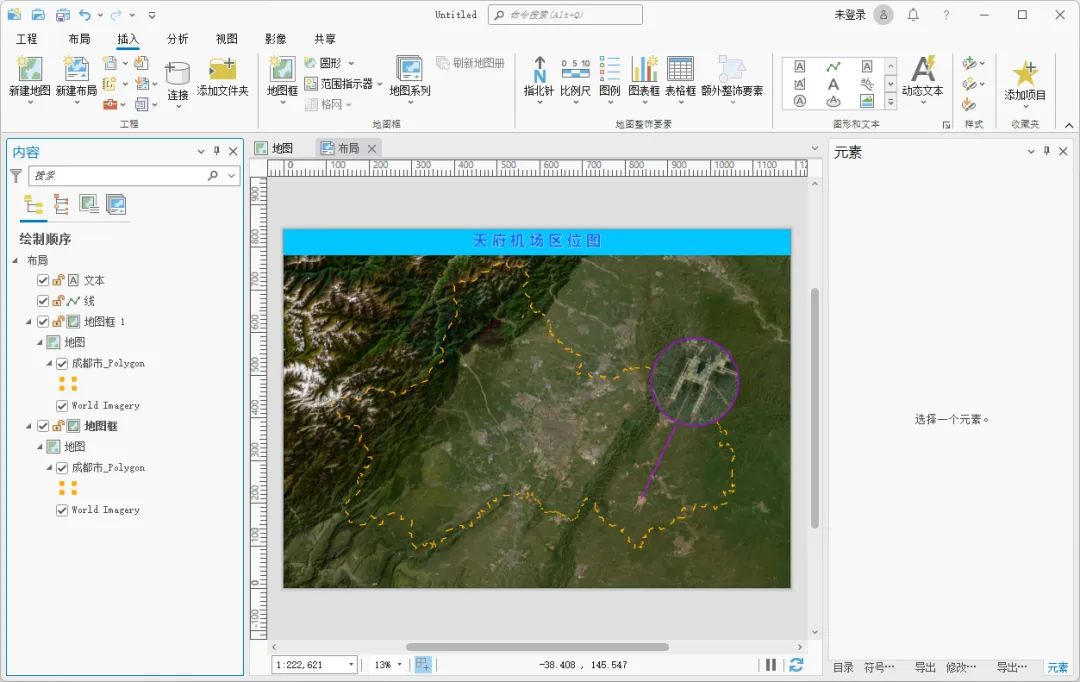
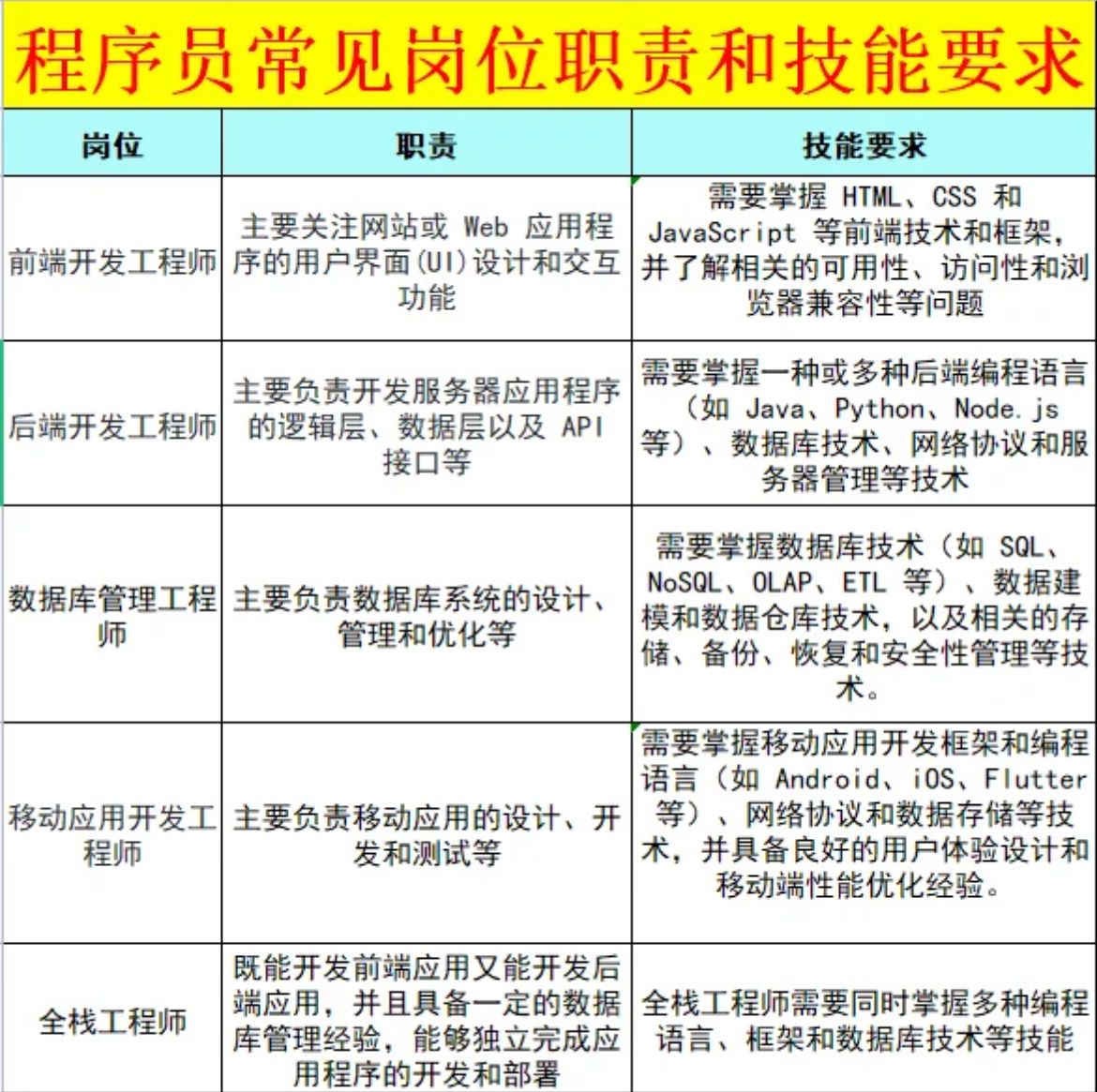
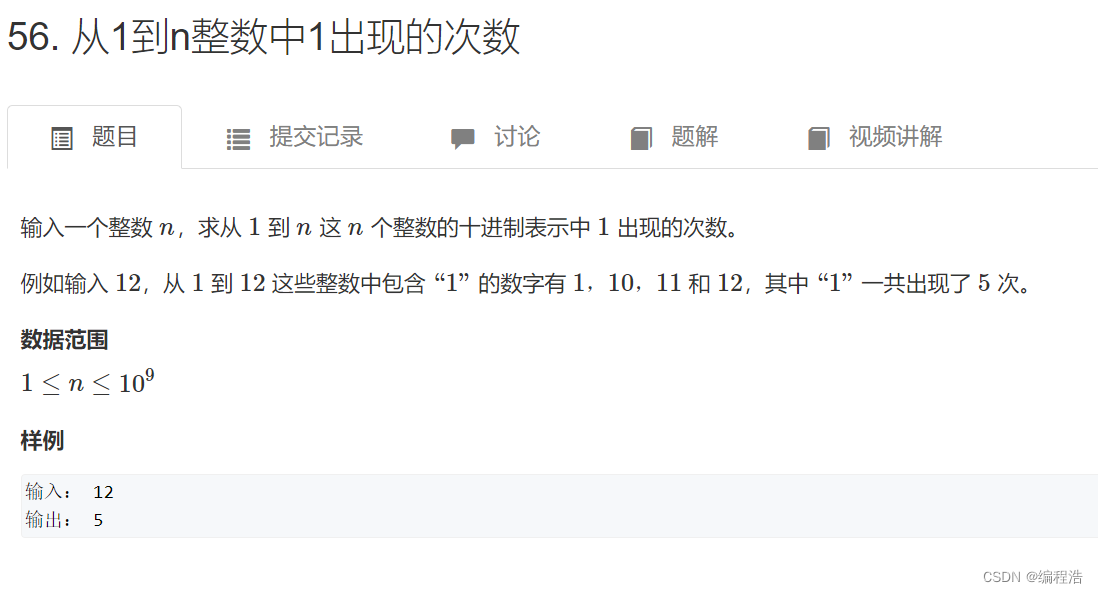
python数据类型
https://draw.io/ 画图
str
序列操作
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引、下标)访问它们。
s= "hello moluo"
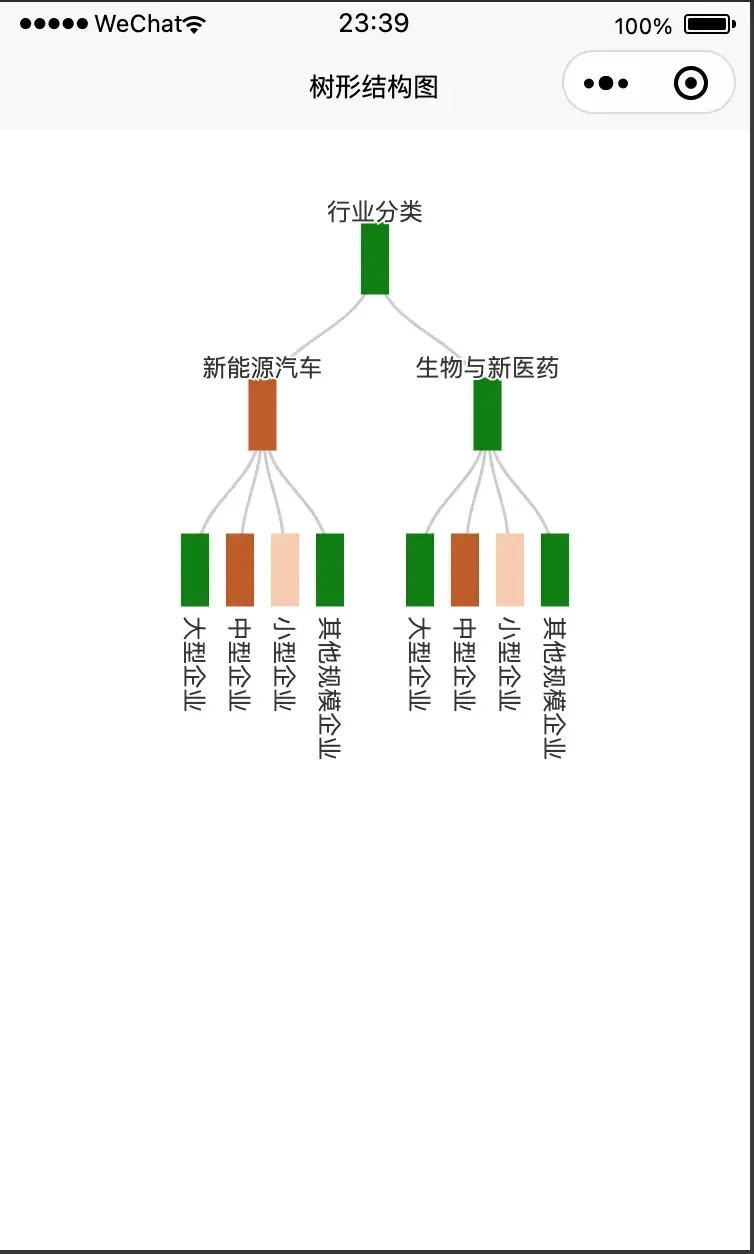
下标从0开始,从左往右,逐一递增。如图 所示。
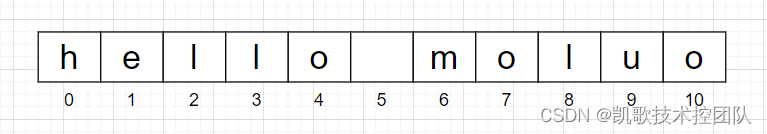
Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,从右往左,逐一递减。如图 所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HIKNfgr8-1689668955828)(assets/image-20220316174543839.png)]](https://img-blog.csdnimg.cn/820759ae980446d19d244059e687702a.png)
索引取值
格式:序列类型数据[下标]
s = "hello moluo"
print(s[6]) # m
print(s[-10]) # e
切片操作
格式:序列类型数据[start : end : step]
s = "hello moluo"
print(s[1:4]) # ell => 取索引1到索引3(左闭又开)
print(s[:4]) # hell => start缺省,默认从0取
print(s[1:]) # ello moluo => end缺省,默认取到最后
print(s[1:-1]) # ello molu
print(s[6:9]) # mol
print(s[-4:-1]) # olu
print(s[-1:-4]) # 空
print(s[-1:-4:-1]) #oul step为1:从左向右一个一个取。为-1 ,从右向左一个取
判断成员是否存在
判断存在:Python 中,可以使用 in 关键字检查某元素是否为序列的成员。
s = "hello moluo"
print("moluo" in s) # True
相加拼接与乘法叠加
支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。
使用数字 n 乘以一个序列会生成新的序列,其内容为原来序列被重复 n 次的结果
s = "hello"+" moluo"
print(s) # hello moluo
s= "*"*10
print(s) # **********
解包
# 解包,也叫解构
# 表示把一个序列的数据,按成员数量拆分成对应数量的变量进行保存
# s = "hu"
# a1, a2 = s
# print(a1)
# print(a2) # a1.print tab键
# 如果成员的数量与等号左边的变量数量不等,则报错!!
# s = "www"
# a1, a2, a3, a4 = s
# print(a1, a2, a3)
# 值类型错误:没有足够的成员值来进行解包(等号左边希望是4个,结果等号右边只提供了3个)
# ValueError: not enough values to unpack (expected 4, got 3)
s = "www"
a1, a2 = s
print(a1, a2)
# 值类型错误:太多的成员值需要解包了(等号左边希望是2个)
# ValueError: too many values to unpack (expected 2)
如果我要保存咱们班上所有同学的名字制作一个花名册,如果使用之前学习的基本数据类型,只能依靠字符串来记录,
但是字符串一次记录一个学生名字,我们想几十个变量来记录。
所以此时可以采用复合数据类型来保存,复合数据类型可以让我们使用一个变量就可以把几十个,甚至上万个数据保存在一个变量中。
List 列表
tuple 元组
dict 字典
set 集合
list
list,列表,在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的一个数据结构。
列表会将所有元素(成员,数据)都放在一对中括号[ ]里面,相邻元素之间用逗号(,)分隔,如下所示:
变量 = [element1, element2, element3, ..., elementn]
注意:不同于C,java等语言的数组(Array),python的列表可以存放不同的,任意的数据类型对象。
列表声明
data = []
print(data, type(data))
data = [123,"moluo",True]
print(data,type(data))
序列操作
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(成员,得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wj8wZyIz-1689668955830)(assets/image-20210413163948909.png)]](https://img-blog.csdnimg.cn/694cc3253df8479cb9272a5a1b34d41a.png)
列表的索引与字符串一样,支持正数索引,从0开始,从左往右,逐一递增。也支持负数索引,从-1开始,从右往左,逐一递减。
索引取值
# 修改列表指定索引的值
data = ["xiaoming", "xiaohong"]
data[1] = "小红"
print(data)
# 取值
l = [10,11,12,13,14]
print(l[2]) # 12
print(l[-1]) # 14
切片操作
"""
列表的切片操作与字符串一样,左闭右开原则,也有3个选项:
变量[开始下标:结束下标:步进值]
列表的步进值默认是1,所以切片操作的方向默认从左往右的。
结果是一个列表,如果有适用范围,则结果包含范围内的指定成员,如果超出范围,则返回一个没有成员的空列表
"""
l = [10, 11, 12, 13, 14]
print(l[2:5]) # [12, 13, 14]
print(l[-3:-1]) # [12,13]
print(l[:3]) # [10,11,12]
print(l[1:]) # [11, 12, 13, 14]
print(l[:]) # [10, 11, 12, 13, 14]
print(l[-1:-3]) # []
print(l[-1:-3:-1]) # [14, 13]
print(l[::2]) # [10, 12, 14 ]
1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[-1]获取;3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step步进值为正,从左向右切,为负从右向左切。
判断成员是否存在
in 关键字检查某元素是否为序列的成员
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True
相加拼接与乘法叠加
l1 = [1,2,3]
l2 = [4,5,6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]
print(l2*3) # [4, 5, 6, 4, 5, 6, 4, 5, 6]
解包
a,b = [1,2]
print(a) # 1
print(b) # 2
tuple
tuple,元组
元组声明
Python的元组与列表类似,不同之处在于元组的元素只能读,不能修改。通常情况下,元组用于保存无需修改的内容。
元组使用小括号表示,声明一个元组:
(element1, element2, element3, ..., elementn)
注意:当创建的元组中只有一个字符串类型的元素时,该元素后面必须要加一个逗号(,)。否则 Python 解释器会将它视为字符串。
data = (1,2,3)
print(data,type(data)) # (1, 2, 3) <class 'tuple'>
# 当元组声明时,可以省略小括号
data = 1,
print(data, type(data)) # (1,) <class 'tuple'>
data = 1, 2
print(data, type(data)) # (1, 2) <class 'tuple'>
常用操作
和列表一样,元组也是一种序列类型,因此也支持索引取值和切片操作、判断成员是否存在,解包。
l = (1,2,3,4,5)
# 索引取值
print(l[2]) # 3
print(l[-2]) # 4
# 切片操作
print(l[2:4]) # (3, 4)
print(l[:4]) # (1, 2, 3, 4)
# 判断成员是否存在
print(2 in l) # True
# 加法拼接
a = (1,2)
b = (4,5)
print(a+b) # (1, 2, 4, 5)
# 乘法叠加
print(b*3) # (4, 5, 4, 5, 4, 5)
# 解包
x, y = (10, 20)
print(x) # 10
print(y) # 20
# 组包
x = 1
y = 2
data = x,y
print(data) # (1, 2)
# 交换2个变量的值
x = 10
y = 20
# y, x = (x, y)
x,y = y,x
print(x,y) # 20 10
set
Python 中的集合(set),和数学中的集合概念一样。由不同的可hash的不重复的元素组成的集合。
声明集合
Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
{element1,element2,...}
其中,elementn 表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则 Python 解释器会抛出 TypeError 错误。
由于集合中的元素是无序的,因此无法向列表那样使用下标访问元素。Python 中,访问集合元素最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
dict
dictionary,字典
声明字典
python使用 { } 创建字典,由于字典中每个元素都包含键(key)和值(value)两部分,因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
dictname = {'key':'value1', 'key2':'value2', ...}
1、同一字典中的各个键必须唯一,不能重复。重复就覆盖了
2、低版本python解释器中,字典的键值对是无序的,但在3.6版本后字典的键值对默认有序的了,这是新的版本特征。
常用操作
book = {
"price": 9.9,
"title": "西游记后传",
"publish": "人民出版社",
"authors": ["吴承恩", "小明"]
}
# (1) 查键值
print(book["title"]) # 返回字符串 西游记后传
print(book["authors"]) # 返回列表 ["吴承恩", "小明"]
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
book["price"] = 299 # 修改键的值
book["publish"] = "北京商务出版社" # 添加键值对
# (3) 删除键值对 del 删除命令
print(book)
del book["publish"]
print(book)
del book
print(book)
# (4) 判断键是否存在某字典中
print("price" in book)
可变与不可变类型
# 可以使用del关键字删除字典的成员(键值对)
# book = {
# "price": 9.9,
# "title": "西游记后传",
# "publish": "人民出版社",
# "authors": ["吴承恩", "小明"],
# }
#
# del book["authors"]
#
# print(book) # {'price': 9.9, 'title': '西游记后传', 'publish': '人民出版社'}
# 字符串就是一种只读类型的数据,不能修改/删除成员,很明显不能使用del
# s = "hello"
# del s[1]
# print(s)
# 列表可以删除/修改一个成员的值,但是基本不适用del来完成这个操作
# l = [1,2,3]
# del l[-1]
# print(l)
# 元组是只读类型的数据,所以不能删除/修改成员
# t = (1,2,3)
# del t[-1]
# print(t)
# 集合,可以删除/添加成员,但是没有下标,自然也就谈不上del删除成员了
s = {1, 2, 3, 4}
ret = s.pop() # 删除第一个成员
print(ret, s)
# 从上面的操作的结果可以按成员是否可以修改,把数据类型进行分类了:
# 可变类型:list, dict, set
# 不可变类型:int, float, bool, str, tuple
关于数据类型的一些术语
基本类型
int
float
bool
str
容器类型,也叫复合类型
list
tuple
set
dict
序列类型
str
list
tuple
变量缓存机制
缓存,就是暂时保存数据的一种技术,一般我们可以把数据临时保存在内存中。缓存的数据会在特定时间后,或者特定条件后被删除。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tQj6qaPF-1689668955831)(assets/image-20220317154226641.png)]](https://img-blog.csdnimg.cn/9d66a68e88c24e3fb624ee9f8dfe7473.png)
在计算机的硬件当中,内存是最重要的配置之一,直接关系到程序的运行速度和流畅度。而python代码的运行,肯定也是放在内存中运行的,所以官方实现了一套变量缓存机制,以达到节省内存的目的。在这个变量缓存机制中,python把一些相同值的变量在内存中指向同一块内存空间,而不再重新开辟新的空间。当然,变量缓存机制,也叫内存驻留机制。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bI501gBQ-1689668955835)(assets/image-20220317154437179.png)]](https://img-blog.csdnimg.cn/7eb87a40d898430cbe395b942c998dab.png)
python中使用id()函数查看数据的内存地址。
a = 10
b = 10
print(id(a)) # 140724467271616
print(id(b)) # 140724467271616
# 数值类型(int, float, bool)
1.对于整型而言,-5~正无穷范围内的相同值 id一致
2.对于浮点数而言,正数范围内的相同值 id一致
3.布尔值而言,值相同情况下,id一致
4.字符串值相同,id一致
# 容器类型(list, set, dict, tuple)
5.空元组 相同的情况下,地址相同
6.列表,元组,字典,集合无论什么情况 id标识都不同
特别说明:简单元组,超出范围的整型,浮点型,在pycharm中因为是基于文本模式,所以会被当成一个整体在python解释器中被缓存,但是在黑窗口下因为是基于交互模式,因此一行代码就是一个整体,因此不会被缓存。
小数据池
不同的python文件(模块)中的代码里面的相同数据的本应该是不在同一个内存地址当中的, 而是应该全新的开辟一个新空间,但是这样也会占用了更多的内存,所以python定义了小数据池的概念,默认允许小部分数据即使在不同的文件当中,只要数据相同就可以使用同一个内存空间,以达到节省内存的目的。
小数据池只针对:int、bool、None关键字 ,这些数据类型有效。(int有争议,在部分系统下没有被缓存到小数据池中)
None属于python里面一个关键字,表示什么都没有,一般在程序中,用于表示没有结果。
A.py,代码:
a = 5
print(a, id(a))
B.py,代码:
# 在其他语言中,如果不同文件/不同窗口下,创建的变量的数据即便一样,也是保存不同的内存空间中的。
# 但是,python为了达到优化的目的,会把简单的小数据(整型,浮点型,None, bool)固话在一个相同内存中,所以python不同文件的小数据,内存地址是一样的。
a = 5
print(a, id(a))
is运算符
# 在python中如果要比较两个变量是否同一个值,一般是使用 == 判断。
# 但是,如果在判断的基础上,还要判断两个变量的内存地址是否一样的话,则需要使用is来判断
# 在python单纯依靠 == 判断两个数据,只能判断值是否一致
# 如果要判断数据是否是同一个,那么还要判断内存地址是否一样
a = -10
b = -10
print( id(a) == id(b)) # 文本模式下True,交互模式下False
# 除了上面直接使用id函数提取内存地址判断以外,可以使用is运算符来判断值是否一样,内存地址是否一样。
a = -10
b = -10
print( a is b) # True
a = [1,2]
b = [1,2]
print(a is b) # False
1. 基于is可以直接判断两个数据的值是否一样,内存地址同一个
2. 基于== 只能判断两个数据的值是否一样
数据类型转换
因为在工作中有时候数据的本身来源有可能是文件,内存,或者用户输入,所以不可避免的出现一些数据的类型与我们期望的不一样。
num = input("请输入您要购买的数量:")
unit = input("请输入商品的单价:")
print(num, type(num)) # 10 <class 'str'>
print(unit, type(unit)) # 5 <class 'str'>
# 此时,就需要把用户录入的数据进行字符串类型转换成数值类型
num = int(num)
unit = float(unit)
total = num * unit
print(total)
类型自动转换
自动转换,也叫隐式转换,是属于动态编程语言里面的一种特性。
动态编程语言:python,php,javascript
静态编程语言:java,go,C/C++
所谓的自动转换,实际上就是python解释器在遇到运算符需要进行运算符的,因为当前运算符的运行规则要求,则自动把参与运算的数据进行类型转换。
# data = bool + int
data = True + 2
print(data)
# data = bool + float
data = True + 3.14
print(data)
# data = int + float
data = 3 + 3.5
print(data)
类型强制转换
# 纯数字组成的字符串才能转成整型
i = int("3")
print(i,type(i)) # 3 <class 'int'>
# 小数转换成字符串
s = str(3.14)
print(s,type(s)) # 3.14 <class 'str'>
# 布尔值转换成整型
x = int(True)
print(x, type(x)) # 1 <class 'int'>
y = bool(0)
print(y, type(y)) # False <class 'bool'>
a = float(True)
print(a, type(a)) # 1.0 <class 'float'>
a = float("3.15")
print(a, type(a)) # 3.15 <class 'float'>
# # 以下错误示例:
# a = float("3.15元")
# print(a, type(a)) # ValueError: could not convert string to float: '3.15元'
容器类型数据强制类型转换
# 列表可以通过转换数据类型为集合,可以去除重复的成员
data = [1,3,4, 5, 3, 2, 1]
print(data, type(data)) # [1, 3, 4, 5, 3, 2, 1] <class 'list'>
ret = set(data)
print(ret, type(ret)) # {1, 2, 3, 4, 5} <class 'set'>
data = list(ret)
print(data, type(data)) # [1, 2, 3, 4, 5] <class 'list'>
# 字典转列表,可以直接提取字典的所有key出来
data = {"A":1, "B":2}
ret = list(data)
print(ret) # ['A', 'B']
# 元组可以通过转换数据成列表,修改成员的排列位置
old_data = (1, 2, 3, 4)
data = list(old_data)
data[1], data[2] = data[2], data[1]
new_data = tuple(data)
print(new_data) # (1, 3, 2, 4)
总结
重点
1. 序列类型中的str所有操作
下标取值
切片的范围操作
in
字符串相加
2. 序列类型中的list所有操作
下标取值
修改值
切片的范围操作+ [::-1]
in
列表相加
3. 序列类型中的tuple所有操作
一个成员的元组的写法 (1,)
下标取值
切片的范围操作
in
解包和组包!!!
4. set的所有操作
有成员的声明方式
集合的成员唯一性(去重)
5. dict的所有操作
列表成员时字典的情况
字典的key唯一性
字典的key必须是不可变类型
键值对的写法
字典按key取值
5. 可变与不可变
可变类型:dict, list, set
不可变类型:int, float, bool, tuple, str
6. 类型强制转换的情况
理解
1. 字符串的解包
2. 列表的解包
3. 变量缓存机制[面试时才是重点]
小数据池
4. 类型转换
自动转换
容器转换
了解
1. 字符串的切片的步进值