基于PMC知识框架文本挖掘的新能源汽车政策动态评价
- 2. 研究设计
- 2.1 研究技术路线
- 2.2 数据采集
- 2.3 动态分相
- 3. 基于PMC知识框架的策略动态挖掘
- 3.1 PMC知识框架的建立
- 3.2 基于PMC知识框架的策略挖掘字典
- 3.2.1 字典建立步骤
- 3.2.2 建立经验证据的词典
- 3.3 策略动态挖掘分析
- 3.3.1 发行主题(issuing subjects)的动态挖掘
- 3.3.2 政策措施(policy measure)的动态挖掘
- 4. 基于策略挖掘的动态评估
- 4.1 基于PMC知识框架的多输入-输出表
- 4.2 基于策略挖掘的PMC指标计算
- 5. 结论和政策含义
- 5.1 结论
2. 研究设计
2.1 研究技术路线
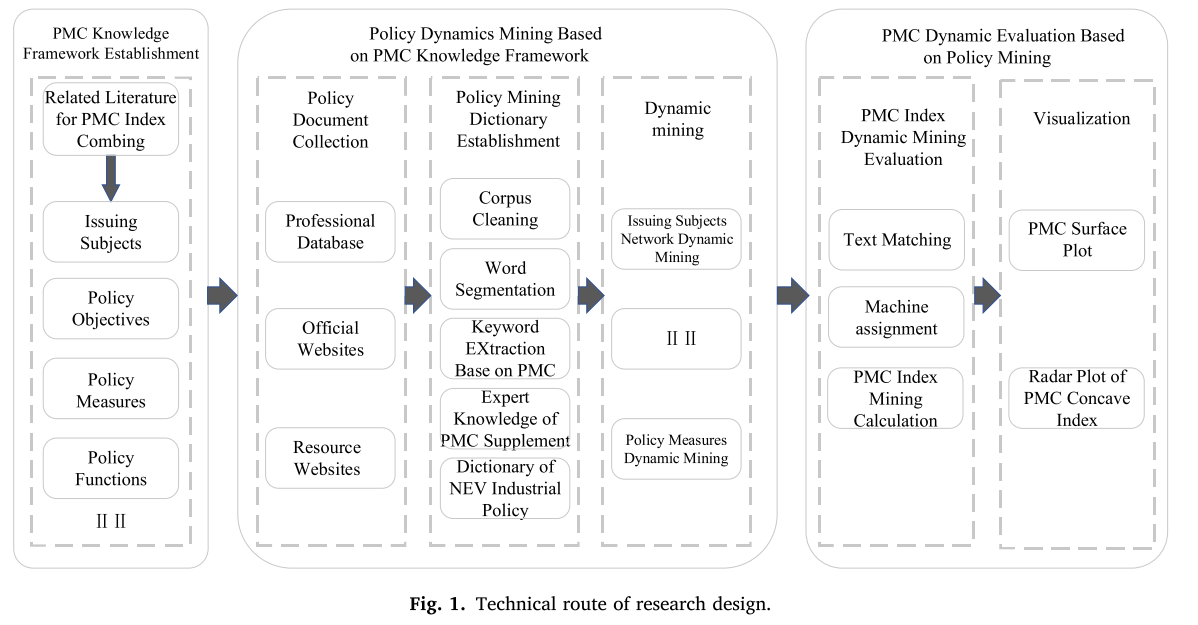
本研究路线如图1所示,分为以下几个步骤:
首先,在梳理PMC指标相关文献的基础上,结合新能源汽车产业发展的应用场景,建立了定量分析新能源汽车政策的PMC知识框架。
然后,基于上述PMC知识框架建立策略挖掘字典。新能源汽车政策文献从官方网站、专业数据库和资源网站收集,参考新能源汽车政策研究的相关文献进行补充;对策略文本语料库进行清理,去除空值和停止词,建立新能源汽车策略挖掘字典,提高分词准确性;基于PMC知识框架提取关键词,并结合专家知识进行补充和分类,完成PMC知识框架各维度的策略挖掘字典。
其次,基于策略字典对策略文档进行动态挖掘,对PMC知识框架各维度中策略文本的外部属性和内部属性进行动态挖掘分析。
最后,基于PMC知识框架挖掘对策略进行动态评价。采用文本匹配技术,将策略文本与PMC知识框架各维度的字典进行匹配,通过机器赋值计算出各策略的PMC指标得分,并将各阶段PMC指标的平均值可视化,实现基于PMC指标知识挖掘的动态评价。
2.2 数据采集
考虑到地方政策主要是中央政策的具体回应和延续,本文主要选取中央部委发布的国家政策文件作为政策数据样本。首先从国务院、工信部等官方网站收集,以“新能源汽车”为标题关键词进行搜索;然后,我们通过专业数据库如中国知网的政府文献数据库和资源网站如北京大学的法宝进行了进一步的搜索。最后,我们补充了现有文献中提出的政策,以确保政策样本的全面性。选定的政策从2001年1月1日至2021年12月31日发布,最终筛选确定了265个政策。
2.3 动态分相
新能源汽车政策的挖掘与评价需要在产业发展阶段的背景下进行动态分析。根据现有文献研究(Zhang and Fang, 2022;庞等,2022),新能源汽车产业的发展阶段可分为以下几个阶段:
(1) 启动阶段(2001—2008)
(2) 试点示范阶段(2009—2013年)
(3) 推广阶段(2014—2016年)
(4) 过渡阶段(2017—2019年)
(5) 高质量发展阶段(2020—至今)
第五阶段,我国新能源汽车进入高质量发展阶段。逐步取消购货补贴,进一步修订完善相关政策。此外,产业“十四五”规划提出,到2025年,将形成包括技术创新和产业生态在内的多维度新能源汽车产业体系。发展新能源汽车规模,重点支持产业发展,提高技术创新和产品质量。
3. 基于PMC知识框架的策略动态挖掘
3.1 PMC知识框架的建立
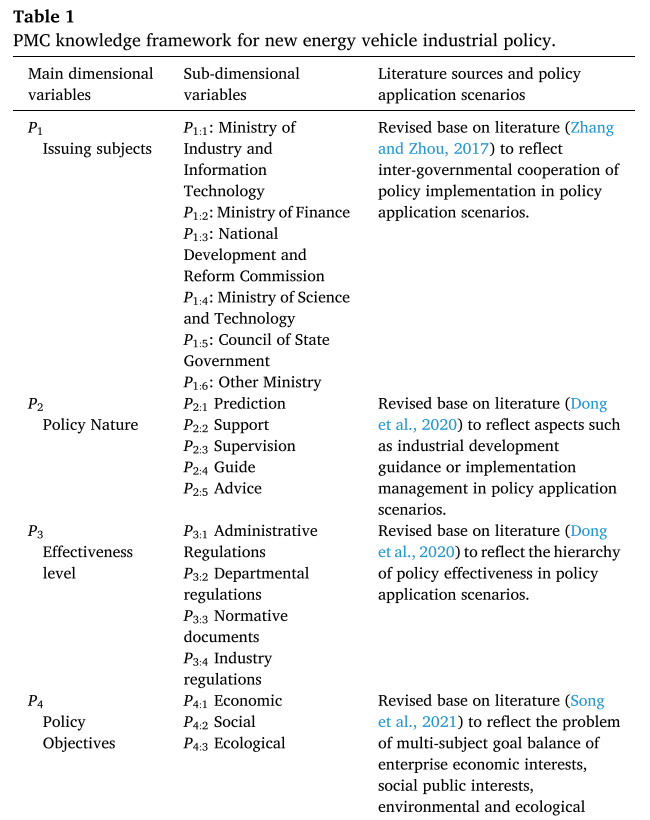
基于相关研究文献和新能源汽车政策应用场景中的实际问题,建立了新能源汽车政策的PMC知识框架。
政策的外部属性包括:政策的性质(P1)、签发主体(P2)、有效性水平(P3)和政策的时限(P4)。
政策的内部属性包括:政策目标(P5)、政策功能(P6)、政策措施(P7)、政策工具(P8)和政策受体(P9)。
如**表1(部分)**所示,一共有9个主要维度变量和42个子维度变量。
3.2 基于PMC知识框架的策略挖掘字典
3.2.1 字典建立步骤
基于PMC知识框架建立策略挖掘字典的主要步骤如下:
(1)将收集到的策略样本语料库导入python中进行数据清理,包括去除空值、去除不激活词等。
(2)将文本挖掘机器识别与本体语义相结合,创建新能源汽车策略词典。
首先,对新能源汽车产业政策相关文献进行梳理,将学者分析新能源汽车产业政策内容的关键词进行归纳,形成初步的政策词汇。然后利用文本挖掘技术识别关键字,通过高频词挖掘等方法提取并输出策略语料库中的高频词,从而更新初步的策略词汇。最后,基于专家知识对政策内容进行理解和分析,厘清政策内容维度,并对各内部维度的关键词进行改进。
(3)基于上述过程,迭代优化新能源汽车政策词汇。最后,根据PMC知识框架对字典中的关键词进行分类,并对各个次级变量的关键词进行专家知识补充,最终建立基于PMC知识框架的更完整的新能源汽车策略字典(如表2所示)。

3.2.2 建立经验证据的词典
首先,对现有文献中关于新能源汽车政策挖掘的关键词进行整理,包括热点话题关键词,如基础设施建设中的“基础设施”、“建设”。利用供给侧政策工具的“研发补贴”、“经营补贴”和“财政支持”三种类型的政策工具的关键词建立政策字典。
然后,将收集到的新能源汽车政策语料库导入python文本挖掘中,并将TF-IDF (Wang and Stewart, 2015;采用KIM D et al., 2019)算法提取分词后的高频关键词,并进行人工筛选和过滤,剔除“新能源”、“汽车”等通用词。剔除对政策特征分析无明显影响的词,并整理出政策各维度中需要分析的有效高频词。
最后,专家根据PMC知识框架对关键词进行分类。专家对各子维的关键词进行补充,如“充电成本”、“利息补贴”等,最终完成基于PMC知识框架的新能源汽车政策挖掘字典。如表2所示的dic - tionary摘录。由于篇幅限制,附录A是完整的字典。
3.3 策略动态挖掘分析
3.3.1 发行主题(issuing subjects)的动态挖掘
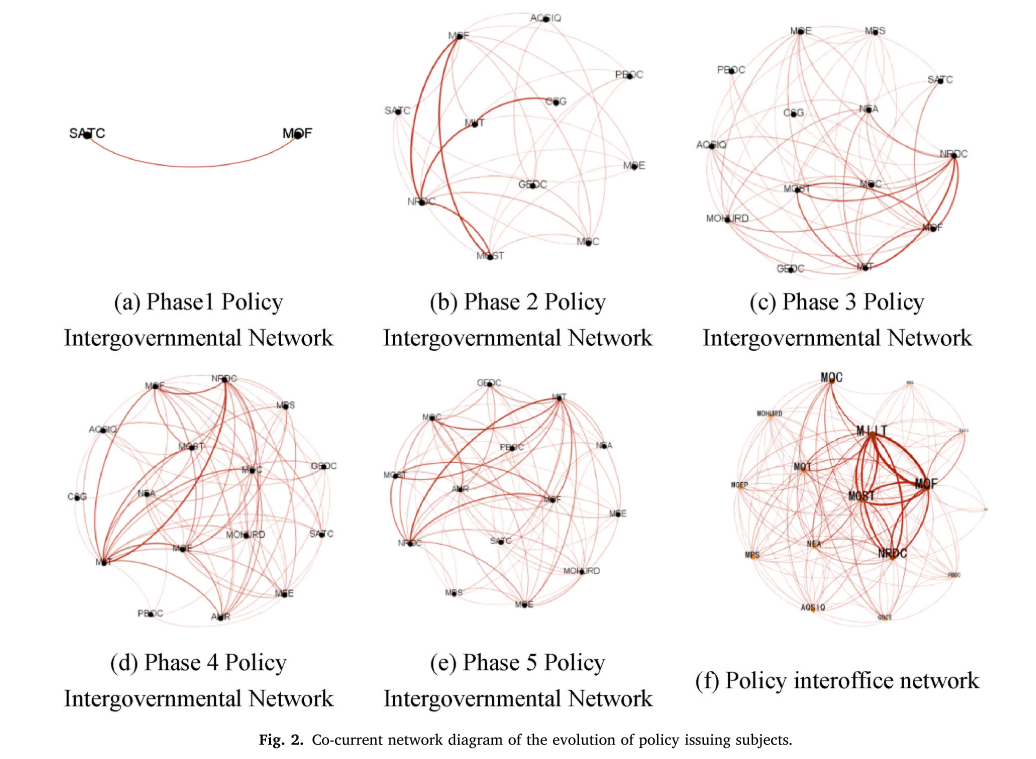
政策发布主体的维度反映了政策的外部属性,挖掘分析主要采用Ucinet、Gephi等社会网络分析方法和软件对政策发布主体的政府间合作网络指标进行分析。各演化阶段政策发布主体共现网络的可视化分析如图2所示。
通过计算网络平均度、网络图密度等指标,量化新能源汽车政策发布主体各阶段共现网络,网络指标统计如表3所示。
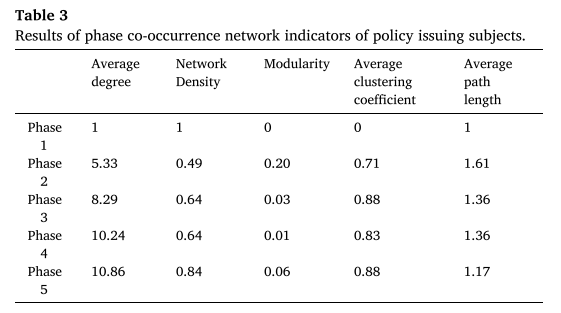
由图2和表3可以看出发行主体多元化的趋势。网络的平均度数和密度呈逐渐增加的趋势。新能源汽车政策发放主体数量的增长表明,发放主体之间的联系日益紧密。模块化指数呈现出由下降到上升的趋势,说明发行主体之间的合作范围呈现先扩大后缩小的趋势。平均聚类系数呈波动上升趋势,平均路径长度指标整体呈下降趋势,说明新能源汽车发行主体间合作不断深化。在现阶段的发展中,以财政部、工信部、科技部、发改委为核心节点的网络基本形成,四部委之间的合作比较密切,但四部委与其他部门之间的合作网络相对松散。
3.3.2 政策措施(policy measure)的动态挖掘
基于PMC知识框架的策略挖掘字典,对策略度量维度的样本策略语料库进行动态挖掘。将样本政策语料库按新能源汽车产业发展阶段进行时间切片,分阶段进行政策措施的LDA主题建模,包括单词、主题和文档三层结构(Tazibt and Aoughlis, 2019)。首先,根据主题一致性算法确定LDA主题的最优数量;然后,对建模的主题进行专家过滤,以删除那些不重要和与研究相关性较小的主题。最后,基于PMC知识框架的子维度对主题进行命名。各阶段的LDA挖掘结果如表4所示。由于篇幅限制,完整的开采结果见附录B。
4. 基于策略挖掘的动态评估
首先,基于PMC政策分析知识框架(表1),建立多投入产出表,对政策进行多维量化。然后,基于PMC知识框架的字典(表2),对PMC指标进行机器赋值,完成客观定量评分。最后,通过PMC曲面和凹指数图对政策动态评价结果进行可视化分析。
4.1 基于PMC知识框架的多输入-输出表
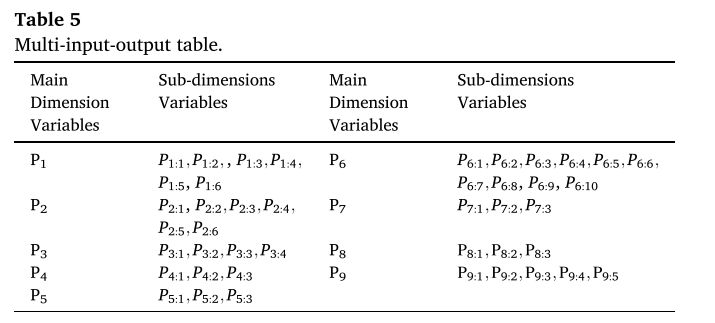
为了更好地量化政策各维度的价值,基于新能源汽车产业政策PMC知识框架(表2),构建多投入产出表(表5),其中9个主维度变量权重相等,共42个子维度变量,通过这一定量分析框架,从多个维度对政策进行了评价。每个个体变量都可以通过存储大量的数据来度量,从而实现从不同维度对政策的评价,反映一定的政策维度的演变。
4.2 基于策略挖掘的PMC指标计算
5. 结论和政策含义
5.1 结论
考虑新能源汽车产业政策面临的复杂应用场景,从政策的外部属性和内部属性多维度出发,建立了基于PMC知识边缘框架的政策挖掘知识字典,采用文本挖掘技术,通过机器赋值完成265个新能源汽车政策PMC评价分数的计算。通过动态挖掘和评价分析,多维度探索新能源汽车产业政策中存在的问题,并提出相应的优化对策。具体研究结论如下:
结论1:由于各阶段政策的逐步分化和发展,政策内部一致性水平不够,呈现下降趋势。PMC指标评分结果(表5)和分数泡图(图4)显示出完美评分时pol - ies不足,PMC有阶段性下降的趋势。反映了新能源汽车政策从粗略的总体布局到亚维度政策的细化和完善的逐步发展,新能源汽车政策的出台力度逐步增强,但目前实现全面深化发展仍有差距。因此,子维度政策需要进一步完善,增加优级政策数量,深化新能源汽车产业高质量发展。
结论2:政策平衡差距明显,政策内外属性之间的良性协同效应较弱,政策各维度之间的组合效应较低。通过对PMC曲面的凹度分析(图5),可以发现PMC曲面的最高点和最低点之间存在明显的空隙。其中,谷点政策维度包括政策发布机构和政策有效性水平,峰值点政策维度包括政策工具和政策措施。因此,需要平衡政策的外部属性和内部属性,完善和优化政策设计,加强政策发布部门和政策措施的协调,提高政策的有效性,促进政策更有效的实施。
**结论3:**政策凹度加剧,政策创新程度与政策可持续性之间存在一定的不平衡。通过计算各阶段政策的PMC凹度指数(图6)可以发现,凹度显著恶化的主要维度主要是目前的政策函数、政策目标和政策措施。因此,政策功能维度侧重于市场链和产业链,而创新链存在结构性缺陷;政策目标层面侧重于社会目标,但缺乏经济目标和生态目标;政策工具供给层面不足,对企业的资源支持相对不足。要强化创新链、经济目标、生态目标和供给维度的隐性政策,不断完善政策规则和标准,推动新能源汽车产业高质量发展。