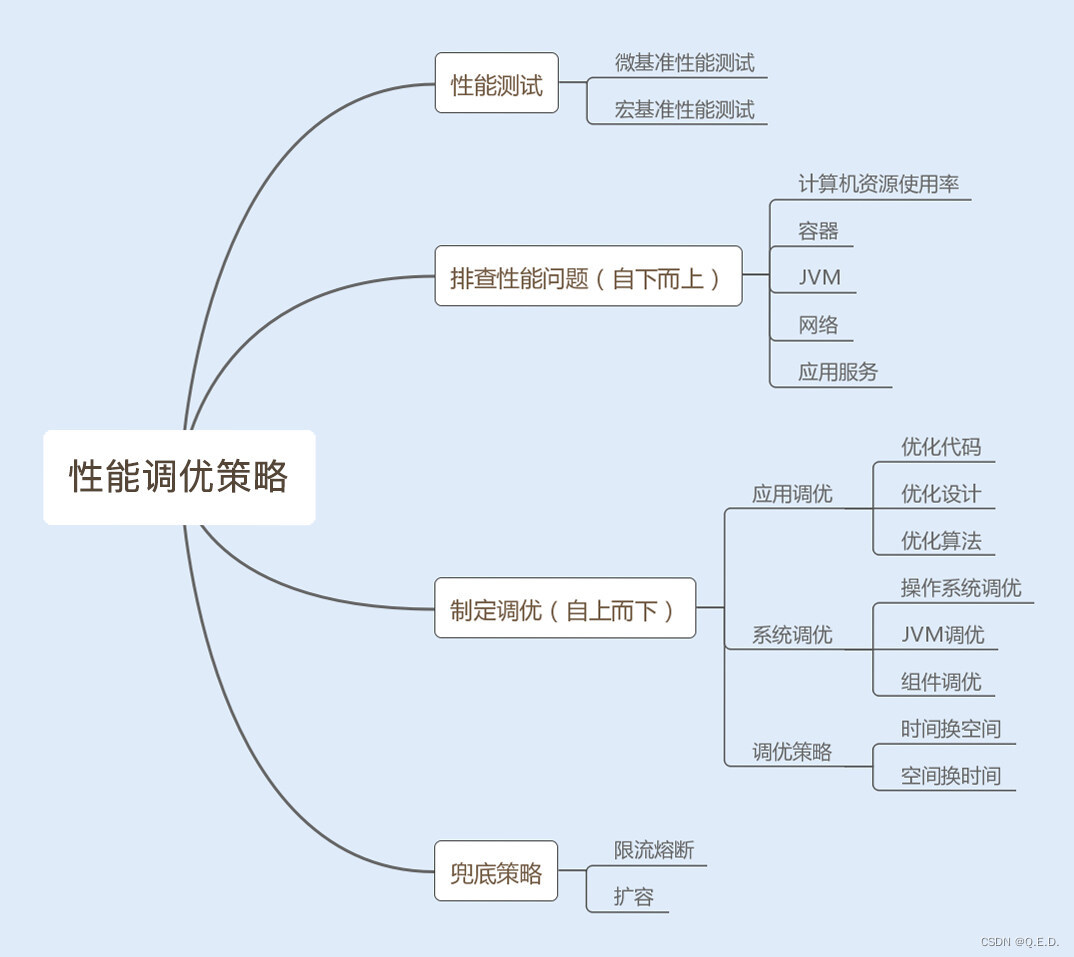
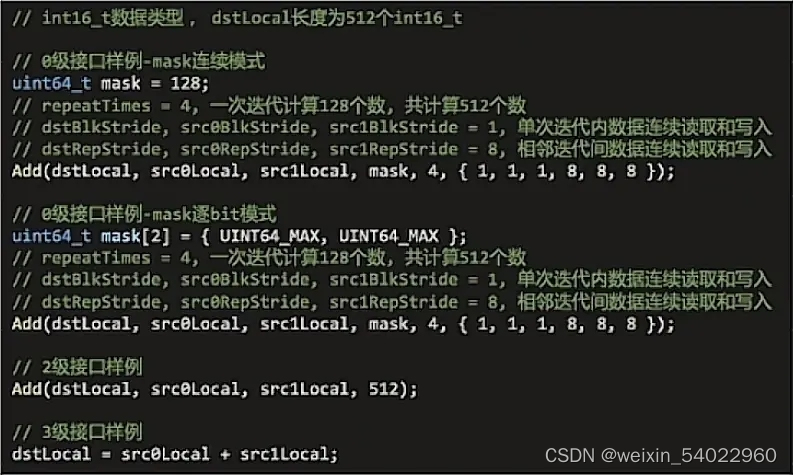
概述
本文研究背景是法律专业人员常用的演绎推理方法,即法律演绎,用于案例分析。
过去的方法主要是通过学习、微调或示例来教授大型语言模型(LLM)进行法律判决预测。这些方法存在的问题是学习样本有限,解释性差。因此,本文提出了面向法律判决预测的简单提示方法——法律演绎提示(LoT),使模型能够根据法律大前提、事实小前提以及结论进行演绎推理并给出判决,无需学习、微调或示例。
本文提出的研究方法是使用法律演绎提示教授LLMs进行法律判决预测。该方法使模型能够集中于与判决相关的关键信息,并正确理解行为的法律含义。
本文在中国刑事案例数据集CAIL2018上对GPT-3模型进行了零-shot判决预测实验。实验结果表明,使用法律演绎提示的LLMs相比于基准方法和思维链提示(目前的最先进提示方法)在多样化的推理任务上实现了更好的性能。法律演绎提示使模型能够预测判决,同时附带法律条文和解释,显著提高了模型的可解释性。


重要问题探讨
1. 为什么当前的法律判决预测模型缺乏可解释性?
○ 当前的法律判决预测模型仅提供最终的判决结果,但缺乏提供法律推理过程的中间步骤。
○ 这限制了模型的可解释性,因为判断的依据无法被理解或验证。
2. 如何提高法律判决预测模型的可解释性?
○ 使用大型语言模型(LLMs)和思维链(chain-of-thought)技术来实现法律判决预测模型。
○ LLMs能够通过思维链生成中间的推理步骤,从而提供可解释性。
○ 这种方法能够让模型生成与法律推理过程相关的解释步骤,使判决过程更加透明。
3. 怎样的数据注释成本限制了法律判决预测模型在实际法律场景中的应用?
○ 当前的法律判决预测模型需要大量由法律专家标注的数据来进行训练。
○ 这种数据注释成本非常高,并且在实际法律场景中很难得到足够标注的数据。
4. LLMs是否能够降低法律判决预测模型的数据注释成本?
○ LLMs具有零样本学习(zero-shot learning)的能力,无需任务特定的示例即可进行推理。
○ 这意味着相较于传统的监督学习或微调方法,LLMs在数据注释方面具有更低的成本。
5. 怎样将思维链技术应用到法律判决预测模型中?
○ 使用思维链引导LLMs来生成中间推理步骤,从而实现法律判决预测模型的解释性。
○ 这种方法通过教导LLMs以少量示例来生成中间推理步骤,使得模型的推理过程具有高度可解释性。
以上问题与文本内容相关,并基于文本内容给出了相应的回答。
论文:2307.08321.pdf