一、配置中心
官方文档:**https://docs.spring.io/spring-cloud-config/docs/current/reference/html/
经过前面的学习,我们对于一个分布式应用的技术选型和搭建已经了解得比较多了,但是如果我们的微服务项目需要部署很多个实例,那么配置文件我们岂不是得一个一个去改,可能十几个实例还好,要是有几十个上百个呢?那我们一个一个去配置,岂不直接猝死在工位上。
所以,我们需要一种更加高级的集中化地配置文件管理工具,集中地对配置文件进行配置。
Spring Cloud Config 为分布式系统中的外部配置提供服务器端和客户端支持。使用 Config Server,您可以集中管理所有环境中应用程序的外部配置。
实际上Spring Cloud Config就是一个配置中心,所有的服务都可以从配置中心取出配置,而配置中心又可以从GitHub远程仓库中获取云端的配置文件,这样我们只需要修改GitHub中的配置即可对所有的服务进行配置管理了。
1.部署配置中心
这里我们接着创建一个新的项目,并导入依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
启动类:
@SpringBootApplication
@EnableConfigServer
public class ConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigApplication.class, args);
}
}
配置文件:
server:
port: 8700
spring:
application:
name: configserver
eureka:
client:
service-url:
defaultZone: http://localhost:8801/eureka, http://localhost:8802/eureka
这里我们以本地仓库为例(就不用GitHub了,卡到怀疑人生了),首先在项目目录下创建一个本地Git仓库,打开终端,在桌面上创建一个新的本地仓库:


然后我们在文件夹中随便创建一些配置文件,注意名称最好是{服务名称}-{环境}.yml:

然后我们在配置文件中,添加本地仓库的一些信息(远程仓库同理),详细使用教程:https://docs.spring.io/spring-cloud-config/docs/current/reference/html/#_git_backend
spring:
cloud:
config:
server:
git:
# 这里填写的是本地仓库地址,远程仓库直接填写远程仓库地址 http://git...
uri: file://${user.home}/Desktop/config-repo
# 默认分支设定为你自己本地或是远程分支的名称
default-label: main
然后启动我们的配置服务器,通过以下格式进行访问:
- http://localhost:8700/{服务名称}/{环境}/{Git分支}
- http://localhost:8700/{Git分支}/{服务名称}-{环境}.yml

也可以使用 http://localhost:8700/bookservice/dev/master链接,它仅显示配置文件原文:

除了使用Git来保存之外,还支持一些其他的方式,详细情况请查阅官网。
2.客户端配置
服务端配置完成之后,我们接着来配置一下客户端,那么现在我们的服务既然需要从服务器读取配置文件,那么就需要进行一些配置,我们删除原来的application.yml文件(也可以保留,最后无论是远端配置还是本地配置都会被加载),改用bootstrap.yml(在application.yml之前加载,可以实现配置文件远程获取):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
spring:
cloud:
config:
# 名称,其实就是文件名称
name: bookservice
# 配置服务器的地址
uri: http://localhost:8700
# 环境
profile: dev
# 分支
label: master
配置完成之后,启动图书服务:
可以看到已经从远端获取到了配置,并进行启动。
3.微服务CAP原则
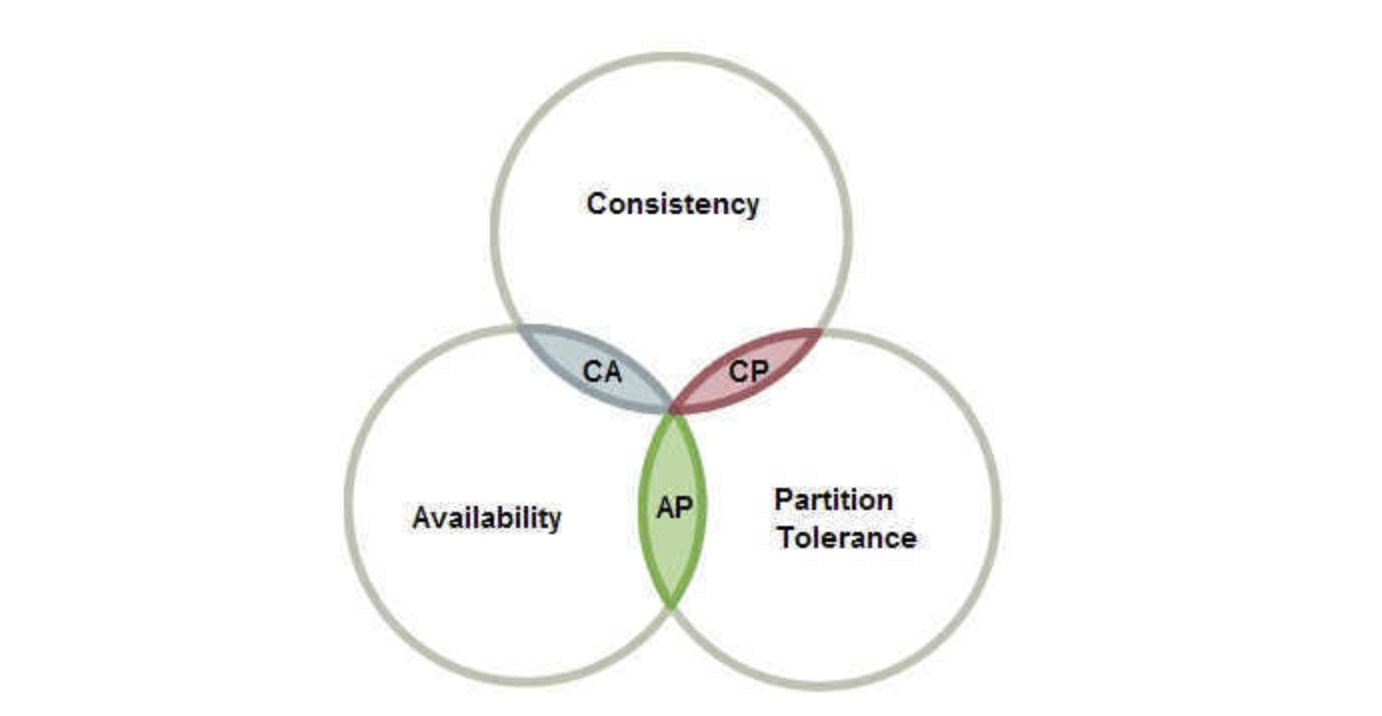
CAP原则又称CAP定理,指的是在一个分布式系统中,存在Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可同时保证,最多只能保证其中的两者。
一致性(C):在分布式系统中的所有数据备份,在同一时刻都是同样的值(所有的节点无论何时访问都能拿到最新的值)
可用性(A):系统中非故障节点收到的每个请求都必须得到响应(比如我们之前使用的服务降级和熔断,其实就是一种维持可用性的措施,虽然服务返回的是没有什么意义的数据,但是不至于用户的请求会被服务器忽略)
分区容错性(P):一个分布式系统里面,节点之间组成的网络本来应该是连通的,然而可能因为一些故障(比如网络丢包等,这是很难避免的),使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中(这样就可能出现某些被分区节点存放的数据访问失败,我们需要来容忍这些不可靠的情况)
总的来说,数据存放的节点数越多,分区容忍性就越高,但是要复制更新的次数就越多,一致性就越难保证。同时为了保证一致性,更新所有节点数据所需要的时间就越长,那么可用性就会降低。
所以说,只能存在以下三种方案:
AC 可用性+一致性
要同时保证可用性和一致性,代表着某个节点数据更新之后,需要立即将结果通知给其他节点,并且要尽可能的快,这样才能及时响应保证可用性,这就对网络的稳定性要求非常高,但是实际情况下,网络很容易出现丢包等情况,并不是一个可靠的传输,如果需要避免这种问题,就只能将节点全部放在一起,但是这显然违背了分布式系统的概念,所以对于我们的分布式系统来说,很难接受。
CP 一致性+分区容错性
为了保证一致性,那么就得将某个节点的最新数据发送给其他节点,并且需要等到所有节点都得到数据才能进行响应,同时有了分区容错性,那么代表我们可以容忍网络的不可靠问题,所以就算网络出现卡顿,那么也必须等待所有节点完成数据同步,才能进行响应,因此就会导致服务在一段时间内完全失效,所以可用性是无法得到保证的。
AP 可用性+分区容错性
既然CP可能会导致一段时间内服务得不到任何响应,那么要保证可用性,就只能放弃节点之间数据的高度统一,也就是说可以在数据不统一的情况下,进行响应,因此就无法保证一致性了。虽然这样会导致拿不到最新的数据,但是只要数据同步操作在后台继续运行,一定能够在某一时刻完成所有节点数据的同步,那么就能实现最终一致性,所以AP实际上是最能接受的一种方案。
比如我们实现的Eureka集群,它使用的就是AP方案,Eureka各个节点都是平等的,少数节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka客户端在向某个Eureka服务端注册时如果发现连接失败,则会自动切换至其他节点。只要有一台Eureka服务器正常运行,那么就能保证服务可用**(A),只不过查询到的信息可能不是最新的(C)**