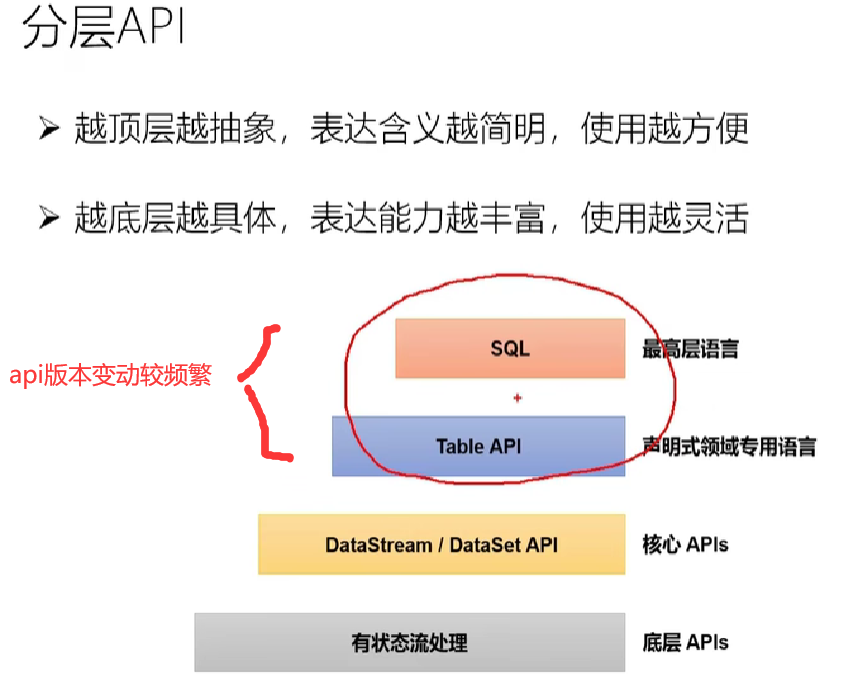
文章目录
- 一.基本概念
- 二.Flink和Spark
- 三. Flink配置文件
- 四. yarn部署flink
- 4.1 session-cluster模式
- 4.2 pre-job-cluster模式
- 五.Flink运行时架构
- 5.1 任务提交流程
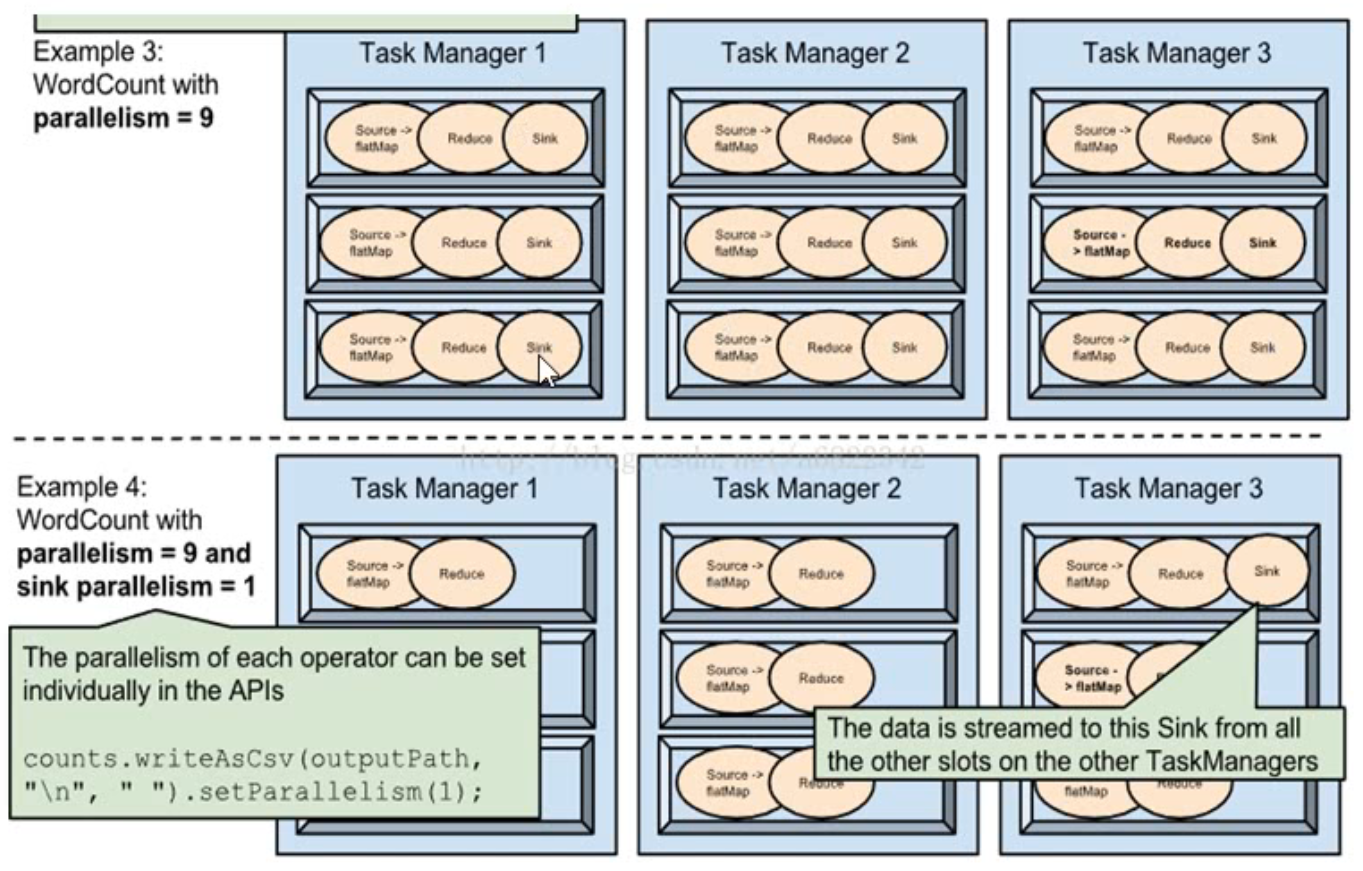
- 5.2 如何实现并行计算
- 5.3 并行任务需要占用多少slot
- 5.4 一个流处理包含多少任务
一.基本概念
官网介绍
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计为在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
1.无限流有一个开始,但没有定义的结束。它们不会在生成数据时终止并提供数据。必须连续处理无限流,即事件必须在摄取后立即处理。不可能等待所有输入数据到达,因为输入是无限的,并且在任何时间点都不会完成。处理无界数据通常需要按特定顺序(例如事件发生的顺序)引入事件,以便能够推断结果完整性。(即实时数据)
2.有界流具有定义的开始和结束。可以通过在执行任何计算之前引入所有数据来处理有界流。处理有界流不需要有序引入,因为始终可以对有界数据集进行排序。有界流的处理也称为批处理。(即存储的数据)
有状态流处-flink处理流程
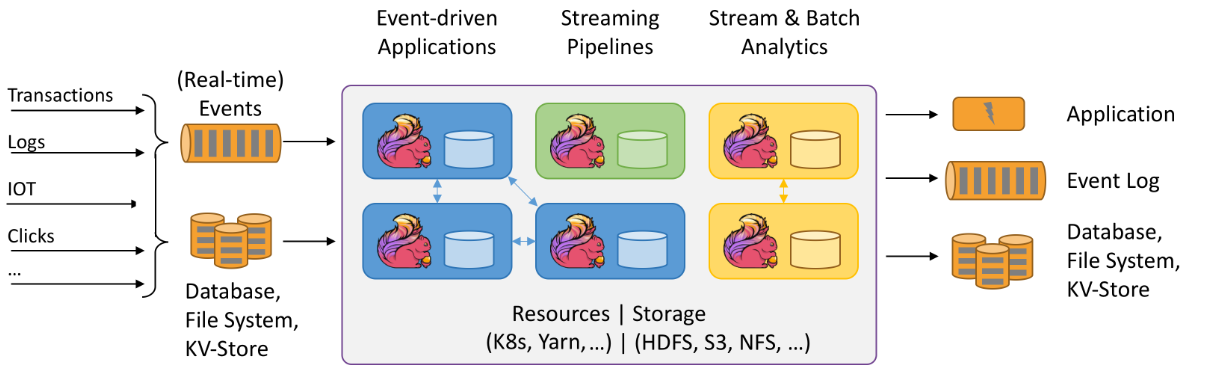
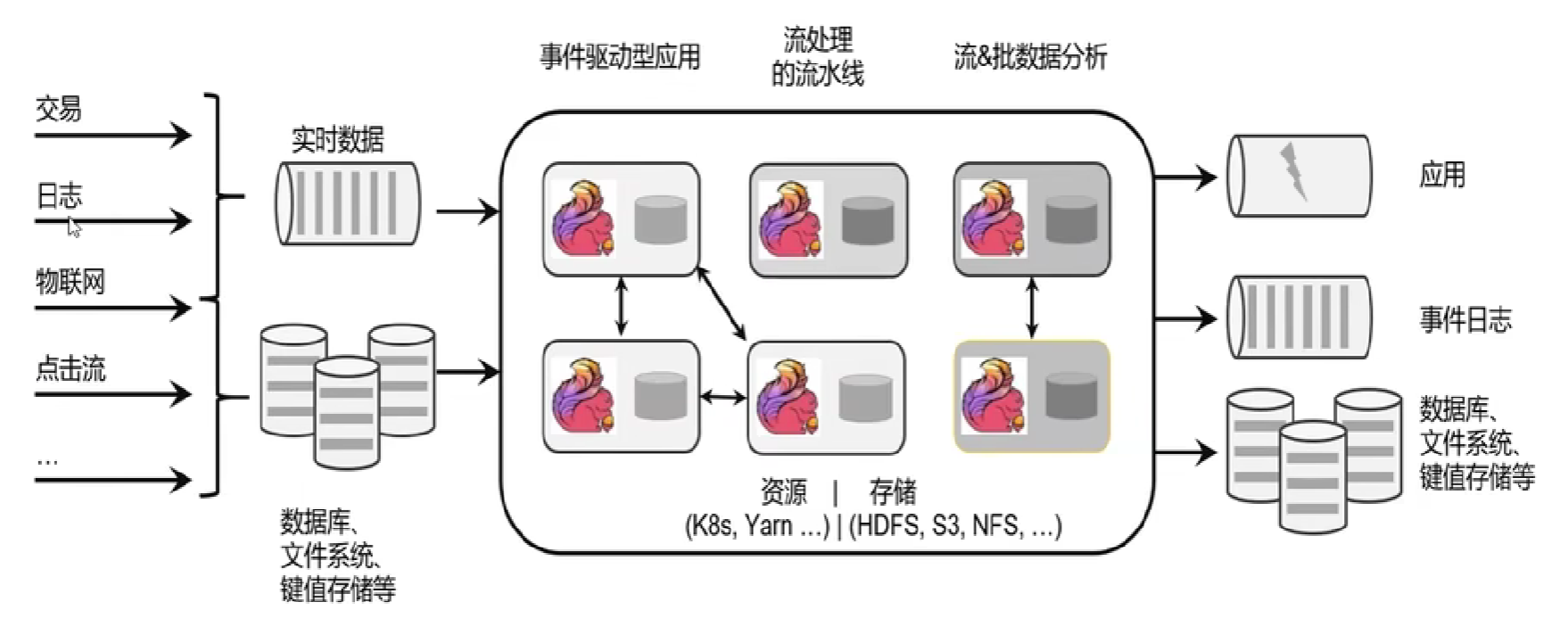
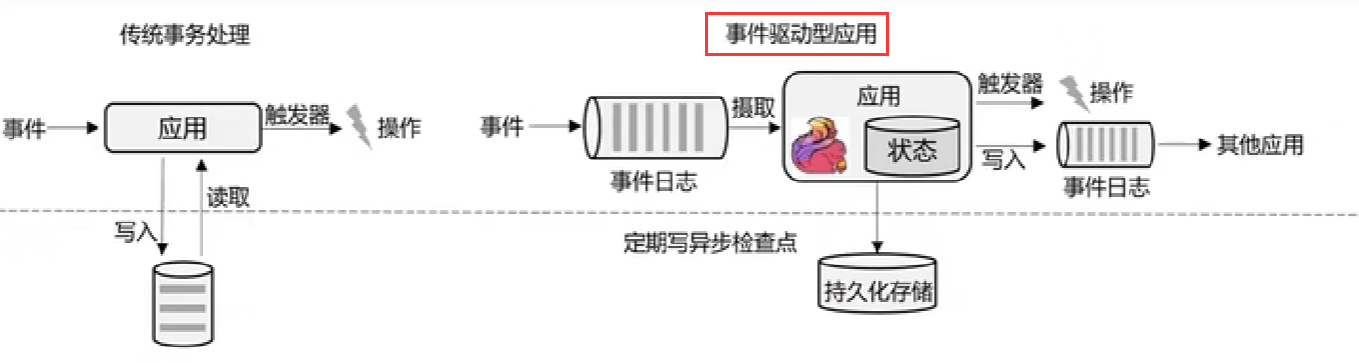
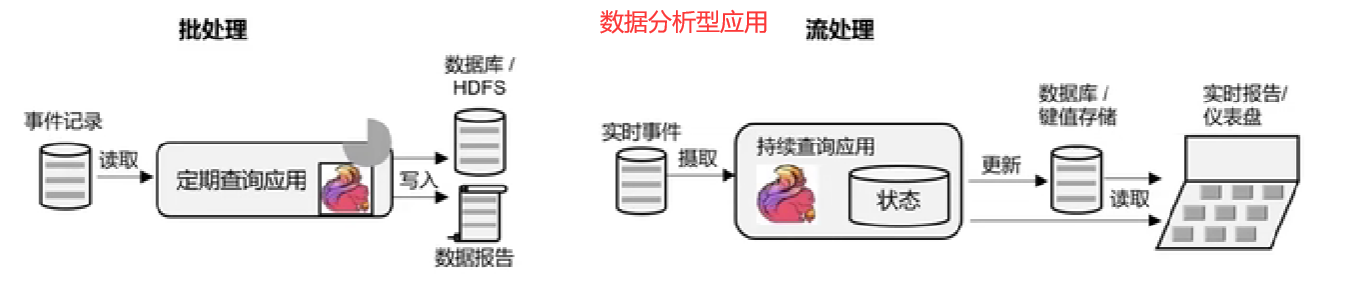
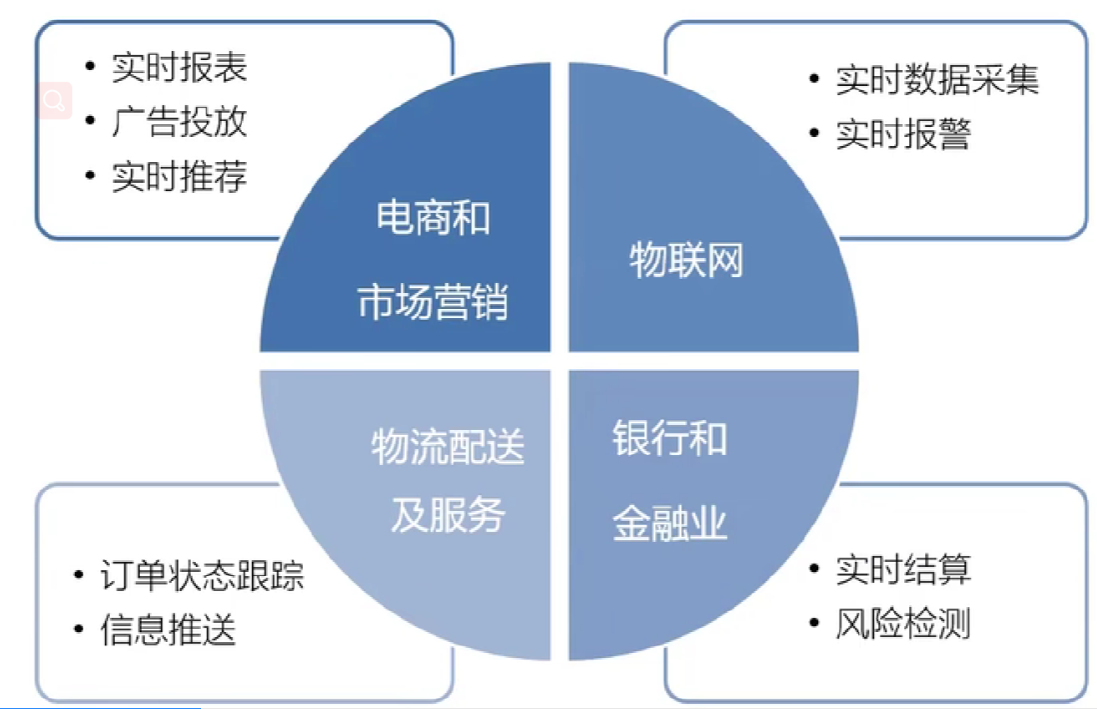
较为合适的应用场景
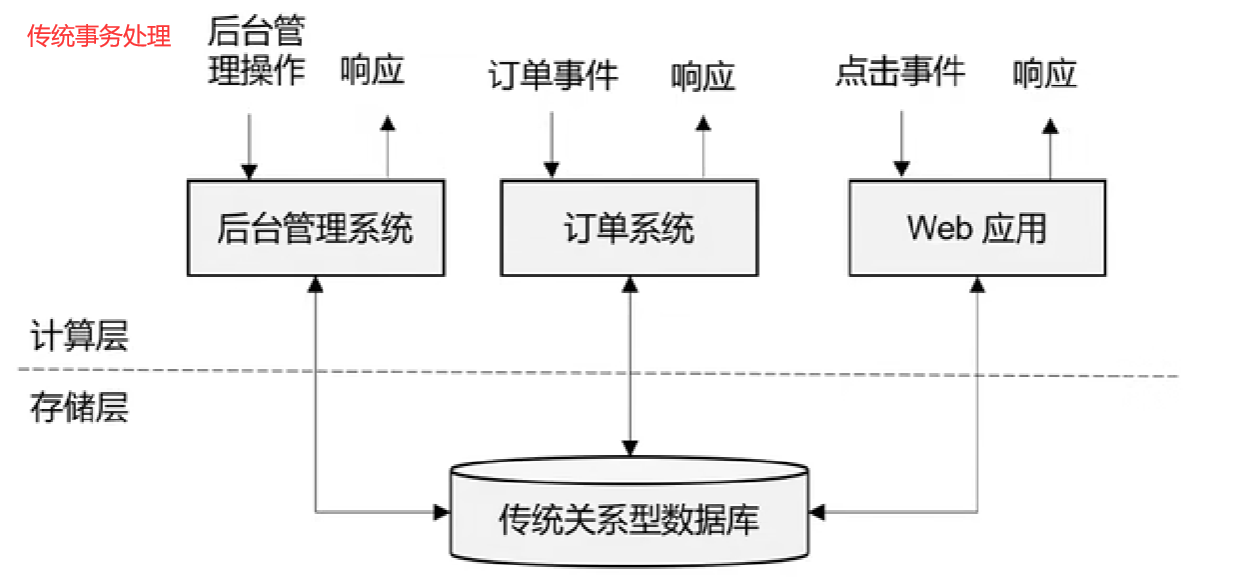
传统事务处理
二.Flink和Spark
-
概念区别
- Spark强劲的分布式大数据处理框架.它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。Spark底层基于批处理.(流是批处理不可切分的特殊情况)
- Flink基于流(批处理是一种有界流)
-
数据模型
- spark采用RDD模型,spark streaming 的 DStream 实际上也就是一组组小批数据RDD的集合
- flink基本数据模型是数据流,以及事件(Event)序列
-
运行时架构
- spark是批计算,将DAG划分为不同的 stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
三. Flink配置文件

jobmanager.sh 资源调度,工作分配脚本
taskmanager.sh 工作任务执行脚本
flink 启动集群后,命令执行器
四. yarn部署flink
4.1 session-cluster模式

# 启动hadhoop集群
# -n(--container) taskManager的数量 不建议指定.动态分配
# -s(--slot) 每个taskManager的slot数量,默认一个slot一个core.默认每个taskmanager的slot个数为1
# -jm: jobManager的内存 mb.
# -tm: 每个taskManager的内存 mb
# -nm: yarn的appName
./yarn-session.sh -s 2 -jm 1024 -tm 1024 -nm test -d
# 提交job
./flink run -c com.vector.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host localhost -port 7777
./flink list -a
# 取消yarn-session
yarn application --kill application_12451231_0001
4.2 pre-job-cluster模式
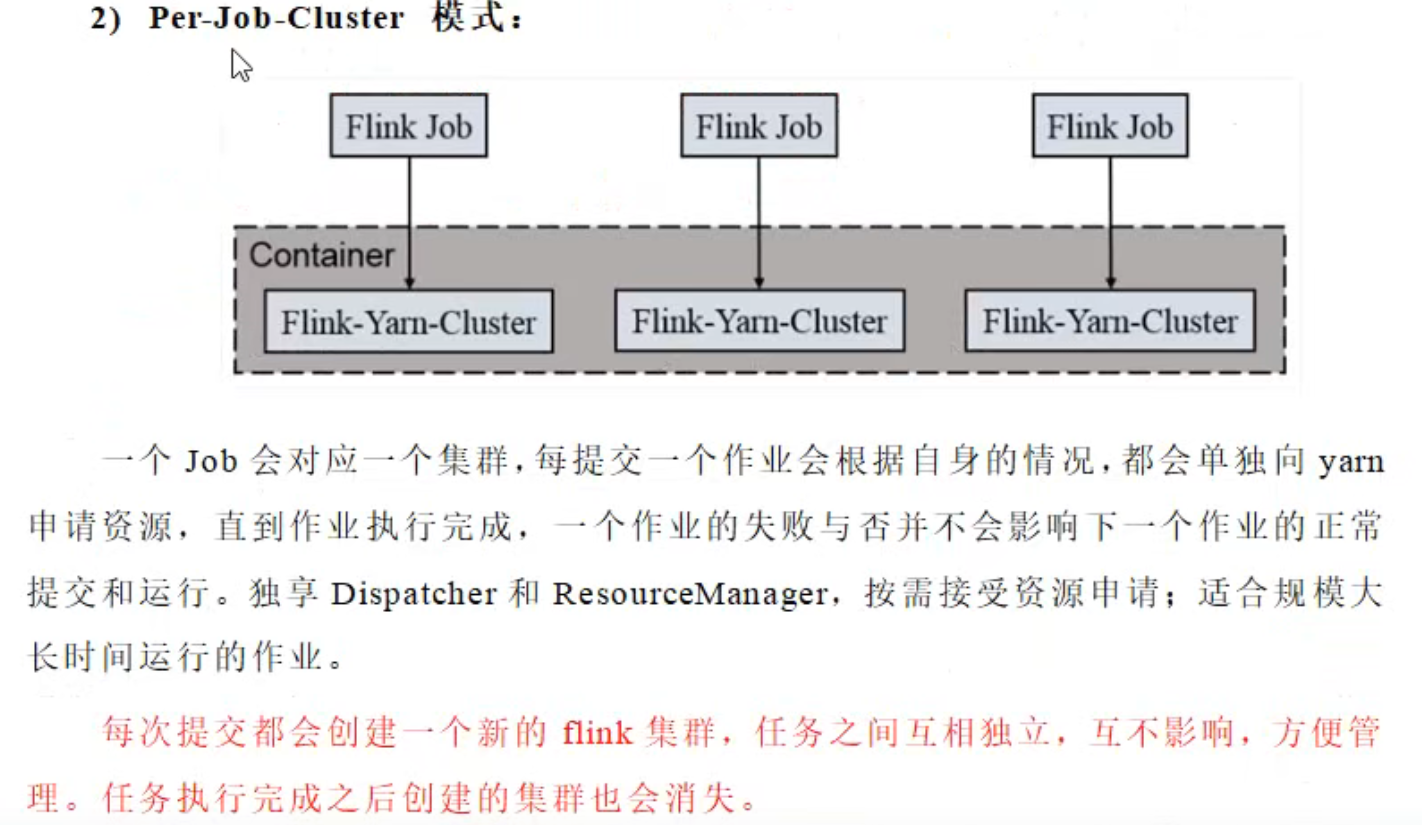
1)启动hadoop集群(略)
2)不启动yarn-session ,直接执行job
./flink run -m yarn-cluster -c com.vector.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host localhost -port 7777
五.Flink运行时架构
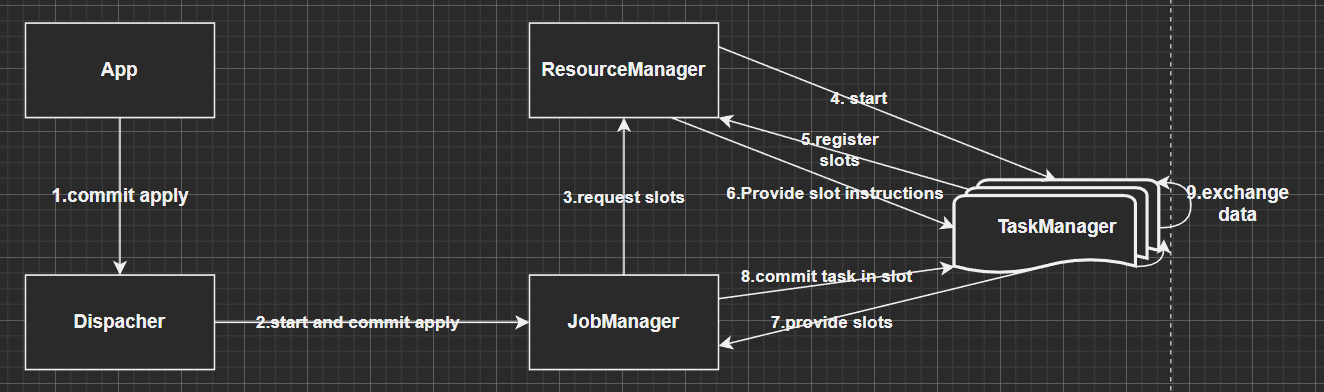
flink运行时组件: jobManager,TaskManager,ResourceManager,Dispacher
JobManager控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager所控制执行。
- JobManager 会先接收到要执行的应用程序,这个应用程序会包括: 作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做"“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
- JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器( TaskManager)上的插槽((slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
TaskManager
- Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
- 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
ResourceManager
- 主要负责管理任务管理器(TaskManager)的插槽(slot) ,TaskManger插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN.Mesos、K8s,以及standalone部署。
- 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
Dispacher
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
- Dispatcher也会启动一个Web Ul,用来方便地展示和监控作业执行的信息。
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
5.1 任务提交流程
5.2 如何实现并行计算
并行度 可以在代码中指定,提交job指定,也可以在集群配置给默认的并行度.
优先级:代码>提交job>集群配置的并行度
- 一个特定算子的子任务 (subtask)的个数被称之为其并行度(parallelism) 。一般情况下,一个stream 的并行度,可以认为就是其所有算子中最大的并行度。
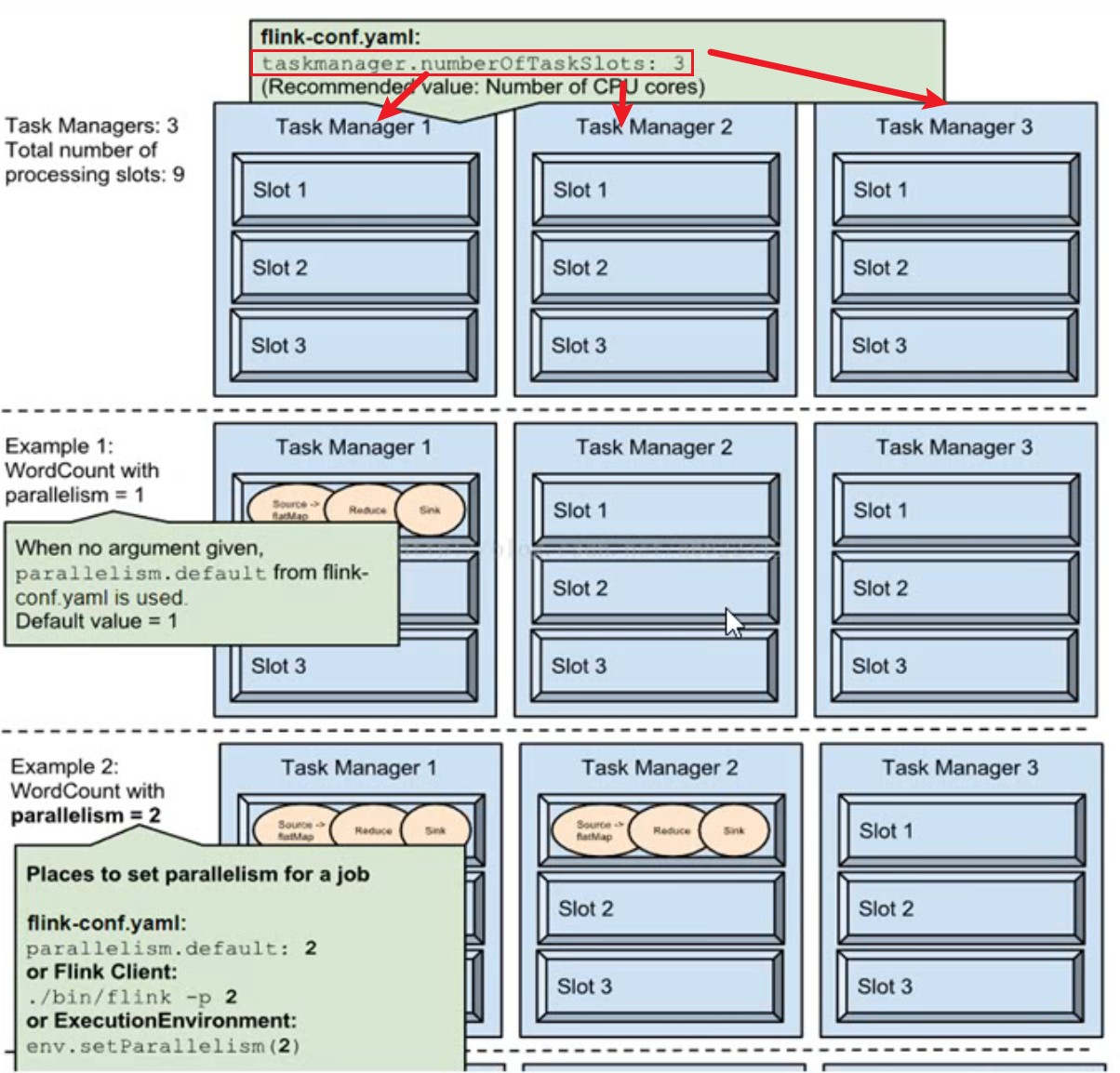
slots
推荐按照cpu核心数设置slot
- Flink 中每一个TaskManager都是一个JVM进程,它可能会在独立的线程上执行一个或多个子任务
- 为了控制一个TaskManager能接收多少个task,taskManager通过task slot来进行控制(一个TaskManager至少有一个slot)
- 默认情况下,Flink允许子任务共享slot,即使它们是不同任务的子任务。这样的结果是,一个slot可以保存作业的整个管道。
- Task Slot是静态的概念,是指TaskManager具有的并发执行能力
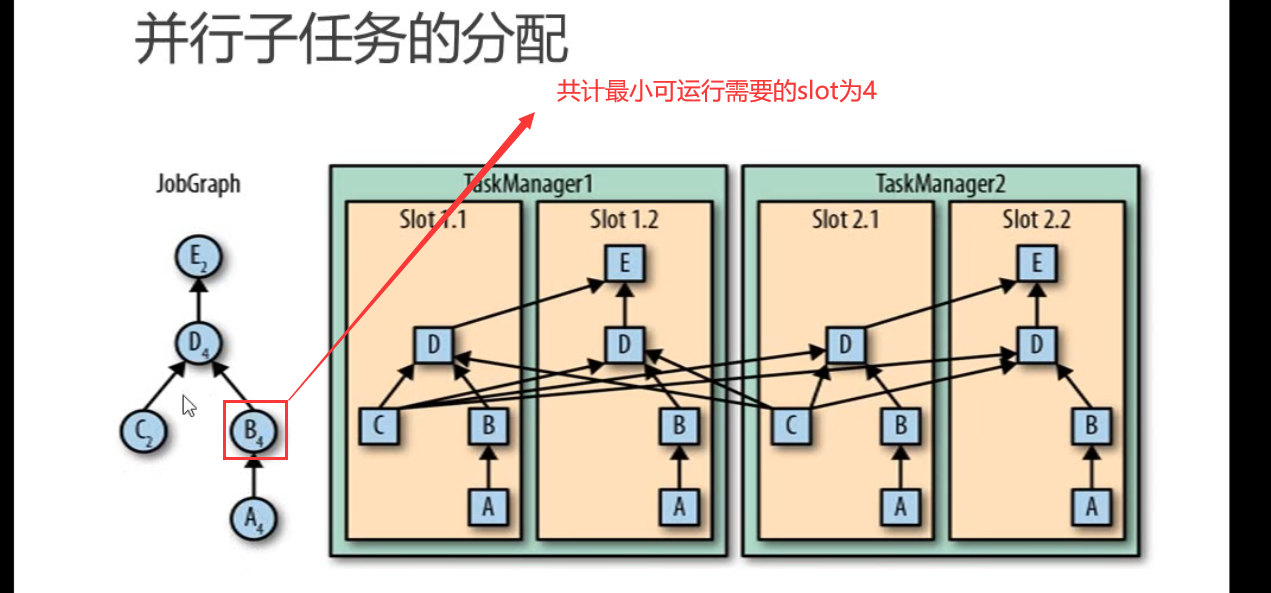
至少需要的slot数 = SUM(MAX(同一个共享组的任务数,同一个共享组的任务数的最大并行度))
情况1
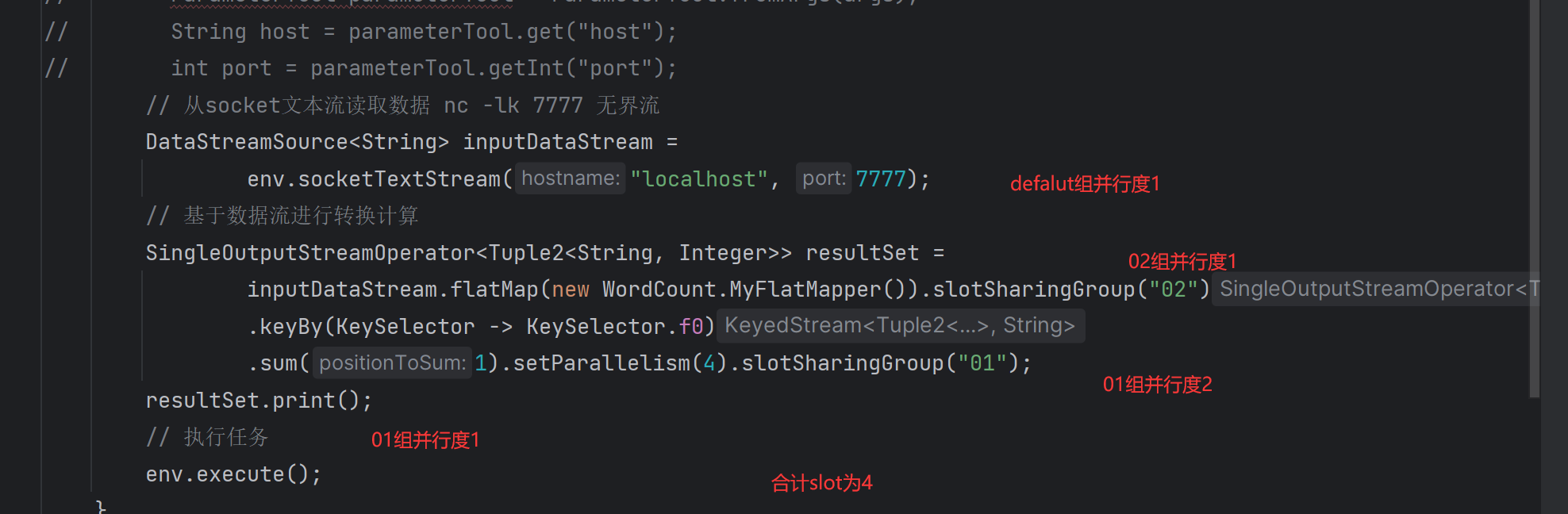
情况2
.setParallelism(4).slotSharingGroup("01"); 设置并行度和共享组 显示设置共享组可以指定不同的slot并行执行.如果有地方没配,则和前一个处于同一个共享组.如果为首部.则为defalut共享组
public class StreamWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(8);
// 从文件中读取数据 有界流
// String inputPath = System.getProperty("user.dir") + "/src/main/resources/text.txt";
// FileSource<String> source = FileSource
// .forRecordStreamFormat(
// new TextLineInputFormat("UTF-8"),
// new Path(inputPath))
// .build();
// DataStream<String> inputDataStream =
// env.fromSource(source, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "text");
// ParameterTool parameterTool = ParameterTool.fromArgs(args);
// String host = parameterTool.get("host");
// int port = parameterTool.getInt("port");
// 从socket文本流读取数据 nc -lk 7777 无界流
DataStreamSource<String> inputDataStream =
env.socketTextStream("localhost", 7777);
// 基于数据流进行转换计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultSet =
inputDataStream.flatMap(new WordCount.MyFlatMapper())
.slotSharingGroup("02")
.keyBy(KeySelector -> KeySelector.f0)
.sum(1).setParallelism(4).slotSharingGroup("01");
resultSet.print();
// 执行任务
env.execute();
}
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按句号分词
String[] words = s.split("");
// 遍历所有word,包成二元组输出
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}








![[禁止登录]登录失败,建议升级最新版本后重试,或通过问题反馈与我们联系。(错误码:45)](https://img-blog.csdnimg.cn/7f7a6d2fbc65435792889918dc14669d.png)


