文章目录
- 【LeetCode热题100】打卡第38天:课程表&实现前缀树
- ⛅前言
- 课程表
- 🔒题目
- 🔑题解
- 实现前缀树
- 🔒题目
- 🔑题解
【LeetCode热题100】打卡第38天:课程表&实现前缀树
⛅前言
大家好,我是知识汲取者,欢迎来到我的LeetCode热题100刷题专栏!
精选 100 道力扣(LeetCode)上最热门的题目,适合初识算法与数据结构的新手和想要在短时间内高效提升的人,熟练掌握这 100 道题,你就已经具备了在代码世界通行的基本能力。在此专栏中,我们将会涵盖各种类型的算法题目,包括但不限于数组、链表、树、字典树、图、排序、搜索、动态规划等等,并会提供详细的解题思路以及Java代码实现。如果你也想刷题,不断提升自己,就请加入我们吧!QQ群号:827302436。我们共同监督打卡,一起学习,一起进步。
LeetCode热题100专栏🚀:LeetCode热题100
Gitee地址📁:知识汲取者 (aghp) - Gitee.com
题目来源📢:LeetCode 热题 100 - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
PS:作者水平有限,如有错误或描述不当的地方,恳请及时告诉作者,作者将不胜感激
课程表
🔒题目
原题链接:207.课程表

🔑题解
-
解法一:DFS(超时了,50个示例数据,过了42个,还有6个超时)
感觉最容易想到的还剩带有邻接矩阵的DFS,但是这种空间占用比较大,然后利用一个 vis 数组对遍历的节点进行标记,遍历过的节点标记为true,未遍历的节点标记为 false,如果深度遍历的过程中遇到了已遍历的节点,则说明当前图存在环,思路比较简单
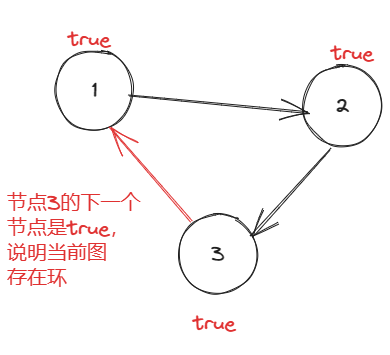
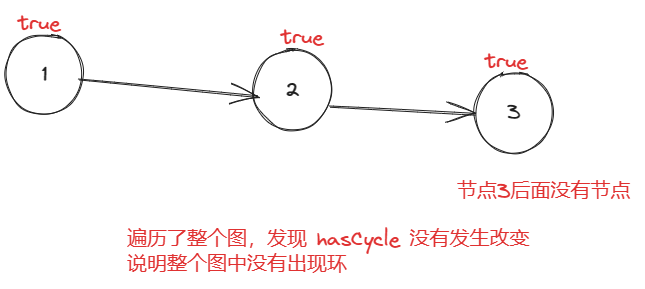
/** * @author ghp * @title * @description */ public class Solution { // 用于标记是否存在环 private boolean hasCycle = false; public boolean canFinish(int numCourses, int[][] prerequisites) { boolean[][] vis = new boolean[numCourses][numCourses]; // 初始化图 int[][] graph = new int[numCourses][numCourses]; for (int i = 0; i < prerequisites.length; i++) { int row = prerequisites[i][0]; int col = prerequisites[i][1]; graph[row][col] = 1; } // 判断图中是否有环 for (int i = 0; i < numCourses; i++) { for (int j = 0; j < numCourses; j++) { // 当前节点有下一个节点时,才开始DFS遍历 dfs(graph, vis, i, j); if (hasCycle) { // 如果已经发现了环,则直接返回 return false; } } } return true; } private void dfs(int[][] graph, boolean[][] vis, int i, int j) { if (hasCycle) { // 已发现环,直接结束搜索 return; } if (vis[i][j]) { // 当前节点已经走过了,说明有环,更新标记,结束搜索 hasCycle = true; return; } for (int k = 0; k < graph.length; k++) { if (graph[i][j] == 1) { // 当前节点有下一个节点,可以往下搜索 vis[i][j] = true; dfs(graph, vis, j, k); vis[i][j] = false; } } } }复杂度分析:
- 时间复杂度: O ( n 3 ) O(n^3) O(n3),遍历每一个节点时间复杂度是 n 2 n^2 n2,DFS搜索耗时是 n n n,两者是嵌套,所以这里的总的时间复杂度是 n 3 n^3 n3
- 空间复杂度: O ( n 2 ) O(n^2) O(n2),graph占用空间 n 2 n^2 n2,vis占用空间 n 2 n^2 n2
其中 n n n 为课程的数量
代码优化:空间和时间优化(超时了,50个示例数据,过了46个,还有4个超时)
- 空间优化:我们发现每次 vis 我们每次的DFS只需要用到一层的,所以我们可以将二维的vis压缩成一维的vis
- 时间优化:前面我们是遍历了图的每一个节点,但是发现并没有这个必要,我们只需一层一层的遍历即可,DFS只需传当前层的节点,从而降低一个指数级的时间复杂度
public class Solution { // 用于标记是否存在环 private boolean hasCycle = false; public boolean canFinish(int numCourses, int[][] prerequisites) { // 初始化图 int[][] graph = new int[numCourses][numCourses]; for (int i = 0; i < prerequisites.length; i++) { int row = prerequisites[i][0]; int col = prerequisites[i][1]; graph[row][col] = 1; } // 判断图中是否有环 for (int i = 0; i < numCourses; i++) { boolean[] vis = new boolean[numCourses]; // DFS判断当前节点出发是否存在环 dfs(graph, vis, i); if (hasCycle) { // 如果已经发现了环,则直接返回 return false; } } return true; } private void dfs(int[][] graph, boolean[] vis, int i) { if (hasCycle) { // 已发现环,直接结束搜索 return; } if (vis[i]) { // 当前节点已经走过了,说明有环,更新标记,结束搜索 hasCycle = true; return; } for (int j = 0; j < graph[i].length; j++) { if (graph[i][j] == 1) { // 当前节点有下一个节点,则遍历下一个节点 vis[i] = true; dfs(graph, vis, j); vis[i] = false; } } } }复杂度分析:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2),遍历一层的节点时间复杂度是 n n n,DFS搜索时间复杂度是 n n n,两者嵌套,所以总的时间复杂度是 n 2 n^2 n2
- 空间复杂度: O ( n 2 ) O(n^2) O(n2),vis占用空间 n n n,graph占用空间 n 2 n^2 n2
其中 n n n 为课程的数量
代码优化:时间和空间优化
使用vis数组对每一个节点进行标记,用于整体判断节点是否已被遍历,使用path数组标记当前节点是否已被遍历,并且用于回溯。
这样可以直接利用vis数组进行剪枝,只要遍历过的节点,可以直接不用重新遍历了
不想画图了…………┭┮﹏┭┮大家自信参考代码理解,如果有任何不理解的地方,欢迎在评论区提问,随时在线解答
注意:并不是说使用邻接表一定要比使用邻接矩阵的DFS的时间复杂度和空间复杂度要更加优秀,这个需要看具体情况,如果图的边比较多,优先推荐使用邻接矩阵,如果图的节点比较多,优先推荐使用邻接表。总的来讲稀疏图使用邻接表,稠密图使用邻接矩阵
import java.util.List; /** * @author ghp * @title * @description */ public class Solution { // 用于标记是否存在环 private boolean hasCycle = false; public boolean canFinish(int numCourses, int[][] prerequisites) { // 构建邻接表 List<List<Integer>> graph = buildGraph(numCourses, prerequisites); boolean[] vis = new boolean[numCourses]; for (int i = 0; i < numCourses; i++) { if (!vis[i] && hasCycle) { // 当前课程没有被遍历 并且 当前还没有发现环,则说明可以继续遍历 dfs(graph, i, vis, new boolean[numCourses]); } } return hasCycle; } private void dfs(List<List<Integer>> graph, int course, boolean[] vis, boolean[] path) { vis[course] = true; path[course] = true; for (int preCourse : graph.get(course)) { if (path[preCourse]) { // 当前课的先行课已经被访问过了,说明出现了环 hasCycle = true; return; } if (!vis[preCourse]) { // 当前层并没有被访问过 dfs(graph, preCourse, vis, path); } } path[course] = false; } private List<List<Integer>> buildGraph(int numCourses, int[][] prerequisites) { List<List<Integer>> graph = new ArrayList<>(); for (int i = 0; i < numCourses; i++) { graph.add(new ArrayList<>()); } for (int[] prerequisite : prerequisites) { int course = prerequisite[0]; int preCourse = prerequisite[1]; graph.get(course).add(preCourse); } return graph; } }复杂度分析:
- 时间复杂度: O ( n + m ) O(n+m) O(n+m)
- 空间复杂度: O ( n + m ) O(n+m) O(n+m)
其中 n n n 为课程的数量, m m m是课程的关系(说白了就是图的边)
另一种写法,参考自这位大佬Krahets。感觉这种方法更加优雅😄
import java.util.ArrayList; import java.util.List; /** * @author ghp * @title * @description */ public class Solution { // 用于标记是否存在环 private boolean hasCycle = false; public boolean canFinish(int numCourses, int[][] prerequisites) { // 构建邻接表 List<List<Integer>> graph = buildGraph(numCourses, prerequisites); // 用于标记当前节点是否遍历 0:未遍历 1:已遍历发现环 -1:已遍历未发现环 int[] vis = new int[numCourses]; for (int i = 0; i < numCourses; i++) { if (vis[i] == 0 && !hasCycle) { // 当前课程没有被遍历 并且 当前还没有发现环,则说明可以继续遍历 dfs(graph, i, vis); } } return !hasCycle; } private void dfs(List<List<Integer>> graph, int i, int[] vis) { if (vis[i] == 1) { // 已遍历发现环 return; } if (vis[i] == -1) { // 已遍历未发现环 return; } vis[i] = 1; for (int j : graph.get(i)) { if (vis[j] == 1) { // 当前课程的先行课已被遍历,说明当前出现了环 hasCycle = true; return; } // 当前先行课未被遍历,可以继续放下遍历 dfs(graph, j, vis); } vis[i] = -1; } private List<List<Integer>> buildGraph(int numCourses, int[][] prerequisites) { List<List<Integer>> graph = new ArrayList<>(); for (int i = 0; i < numCourses; i++) { graph.add(new ArrayList<>()); } for (int[] prerequisite : prerequisites) { int course = prerequisite[0]; int preCourse = prerequisite[1]; graph.get(course).add(preCourse); } return graph; } } -
解法二:BFS(拓扑排序)
这里思想很巧妙,由于我之前没有接触过拓扑排序,所以一开始看到这个题解是十分懵逼的(心想我是谁?我在哪?我要干啥?)
在补充了拓扑排序相关知识后,再来看这题解,发现并没有之前那么懵逼了,反而觉得比前面的DFS还要简单O(∩_∩)O
首先我们来了解一下什么是拓扑排序:拓扑排序(Topological sort)是对有向无环图(DAG,Directed Acyclic Graph)进行排序的一种算法。在拓扑排序中,图中的节点表示任务或事件,有向边表示任务间的依赖关系。
一上来看到这个定义我是一脸懵逼的,这里我就画一个图来快速理解一下拓扑排序吧(一图胜千言):
无环的情况,能够遍历所有的节点:
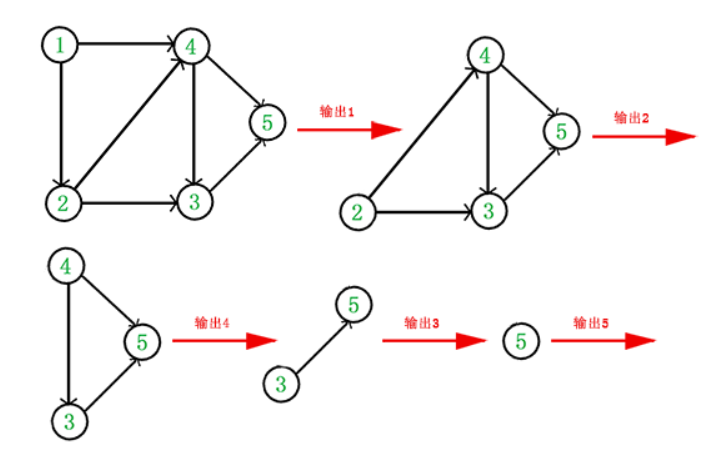
有环的情况,不能够遍历完所有的节点:
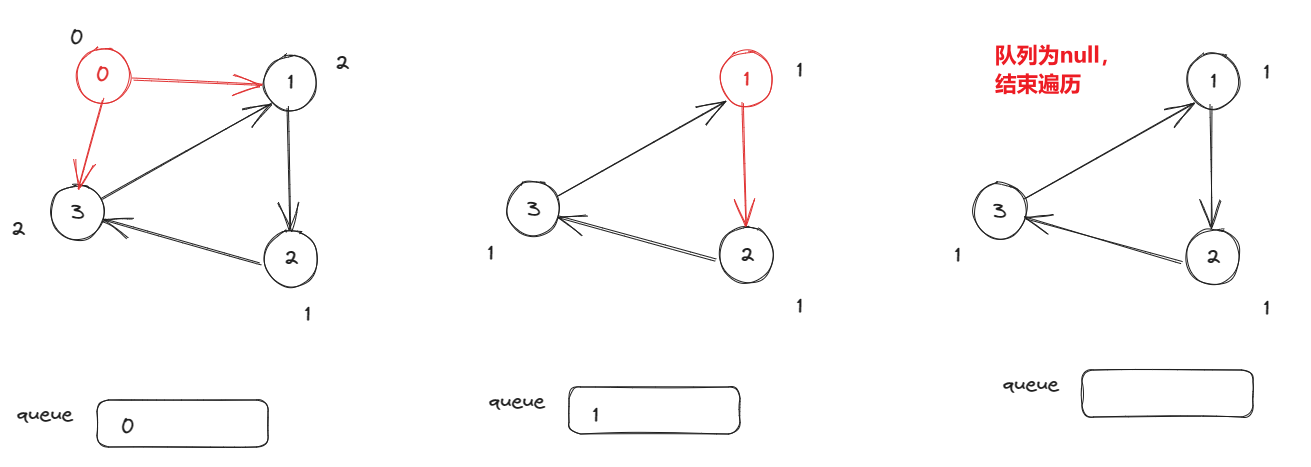
拓扑排序的目标是将图中的节点按照依赖关系进行排序,即满足所有的先决条件。如果存在依赖关系循环(即存在环),则无法进行拓扑排
同样的这个题解也是参考 K神 的(●ˇ∀ˇ●)
import java.util.ArrayList; import java.util.LinkedList; import java.util.List; import java.util.Queue; /** * @author ghp * @title * @description */ public class Solution { public boolean canFinish(int numCourses, int[][] prerequisites) { // 记录节点的入读 int[] indegree = new int[numCourses]; // 构建邻接表 List<List<Integer>> graph = buildGraph(numCourses, prerequisites, indegree); // 初始化队列,将所有入度为0的节点加入队列 Queue<Integer> queue = new LinkedList<>(); for (int i = 0; i < numCourses; i++) { if (indegree[i] == 0){ queue.add(i); } } // BFS遍历所有节点 while (!queue.isEmpty()){ int pre = queue.poll(); // 移除前一个节点 numCourses--; for (Integer cur : graph.get(pre)) { if (--indegree[cur] == 0){ // 当前节点前一个节点被移除后,当前节点的入读变为了0,则入读 queue.add(cur); } } } // 判断是否遍历完了所有节点,如果遍历完了所有节点则说明不存在环,反之则说明存在环 return numCourses == 0; } private List<List<Integer>> buildGraph(int numCourses, int[][] prerequisites, int[] indegree) { List<List<Integer>> graph = new ArrayList<>(); for (int i = 0; i < numCourses; i++) { graph.add(new ArrayList<>()); } for (int[] prerequisite : prerequisites) { int course = prerequisite[0]; int preCourse = prerequisite[1]; graph.get(course).add(preCourse); indegree[preCourse]++; } return graph; } }复杂度分析:
- 时间复杂度: O ( ) O() O()
- 空间复杂度: O ( ) O() O()
其中 n n n 为数组中元素的个数
实现前缀树
🔒题目
原题链接:208.实现前缀树

🔑题解
-
解法一:前缀树
首先我们来了解一下什么是前缀树:前缀树(Trie)是一种多叉树的数据结构,用于高效地存储和检索字符串集合。它也被称为字典树、单词查找树或键树。前缀树的特点是每个节点代表一个字符,从根节点到叶子节点的路径表示一个完整的字符串。通过不同的路径可以区分不同的字符串。根节点不包含字符,每个非根节点都有一个与之对应的字符值。在前缀树中,具有相同前缀的字符串会共享相同的前缀路径。
说白了这个前缀树就是一颗26叉树,每一个节点下都有26个子节点
/** * @author ghp * @title * @description */ public class Solution { } class Trie { // 是否存在以某一个单词结尾的树 private boolean isExit; // 节点的分支 private Trie[] children; public Trie() { this.isExit = false; this.children = new Trie[26]; } /** * 新增单词 * @param word */ public void insert(String word) { Trie root = this; // 构建前缀树,将字符串中的字符 for (int i = 0; i < word.length(); i++) { char ch = word.charAt(i); int index = ch - 'a'; if (root.children[index] == null) { // 后面为null, root.children[index] = new Trie(); } // 将指针移动到子节点,构建下一层节点 root = root.children[index]; } // 将当前字符的最后一个单词结的isExit属性标记为true root.isExit = true; } /** * 查询单词 * @param word * @return */ public boolean search(String word) { Trie root = searchPrefix(word); // 当前节点存在,并且是以当前单词最后一个字母结尾的 return root != null && root.isExit; } /** * 查询前缀 * @param prefix * @return */ public boolean startsWith(String prefix) { return searchPrefix(prefix) != null; } private Trie searchPrefix(String prefix) { Trie root = this; for (int i = 0; i < prefix.length(); i++) { char ch = prefix.charAt(i); int index = ch - 'a'; if (root.children[index] == null) { // 当前字符不存在,直接返回null return null; } // 遍历下一层节点 root = root.children[index]; } return root; } }复杂度分析:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2)
- 空间复杂度: O ( 1 ) O(1) O(1)
其中 n n n 为数组中元素的个数
参考资料:
- 【图解算法】模板+变式——带你彻底搞懂字典树(Trie树)_






![[Linux笔记]vim基础](https://img-blog.csdnimg.cn/e1712ad3abc640539a0a5820b0e6beca.png#pic_center)