首先,建表
创建student表,SQL代码如下
create table student (
id int(10) not null unique primary key,
name varchar(20) not null,
sex varchar (4),
brith year,
department varchar(20),
address varchar(50)
);
创建score表。SQL代码如下:
create table score (
id int(10) not null unique primary key auto_increment,
stu_id int(10) not null,
c_name varchar (20),
grade int(10)
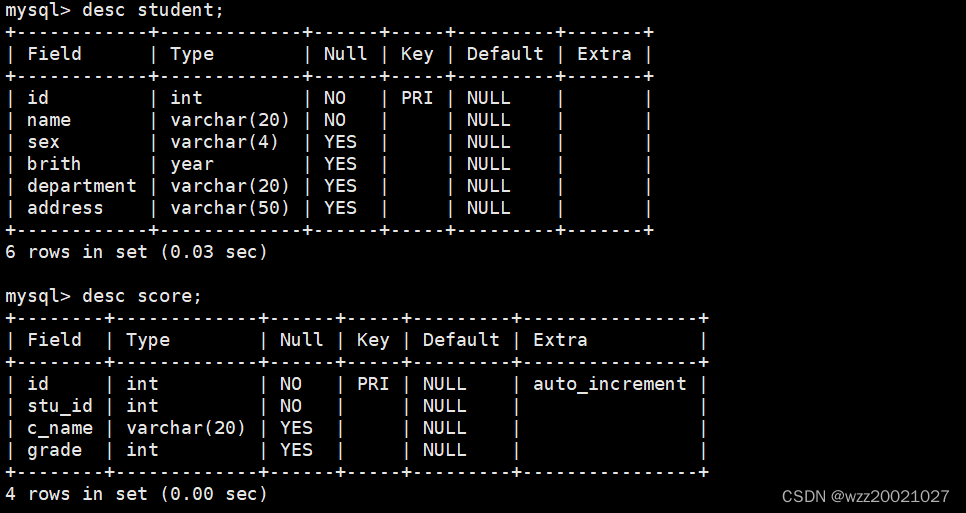
);查看表的结构(查验是否创建完成)
2.为student表和score表增加记录
向student表插入记录的INSERT语句如下:
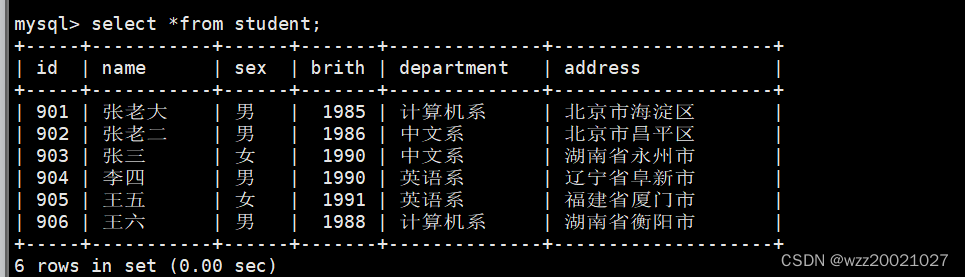
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);1.查询student表的所有记录
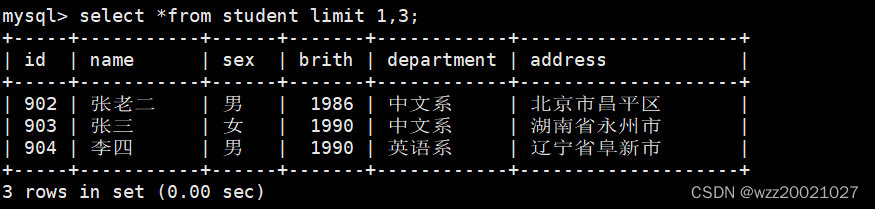
2.查询student表的第2条到4条记录
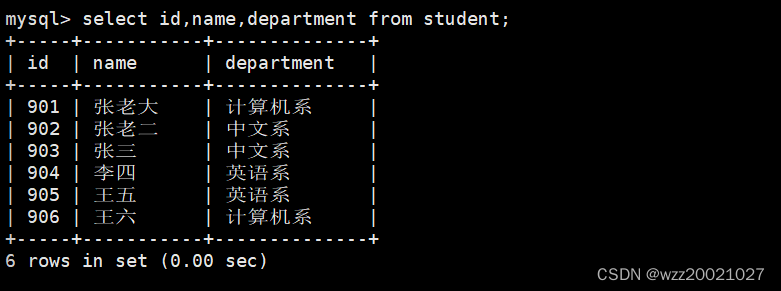
3.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
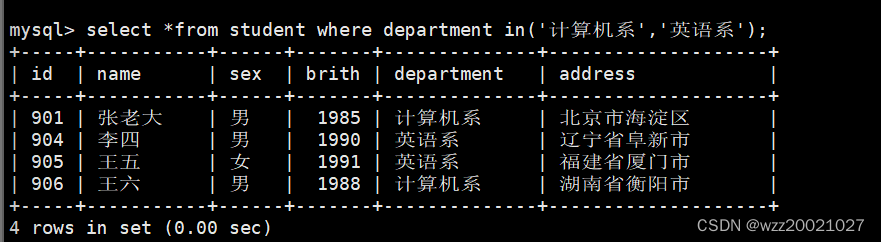
4.从student表中查询计算机系和英语系的学生的信息
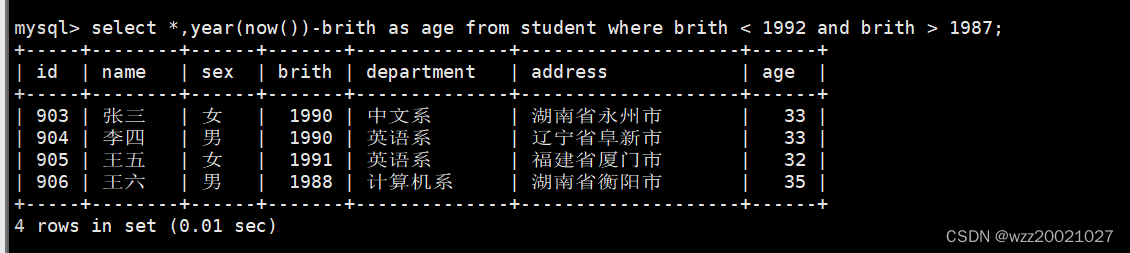
5.从student表中查询年龄18~22岁的学生信息
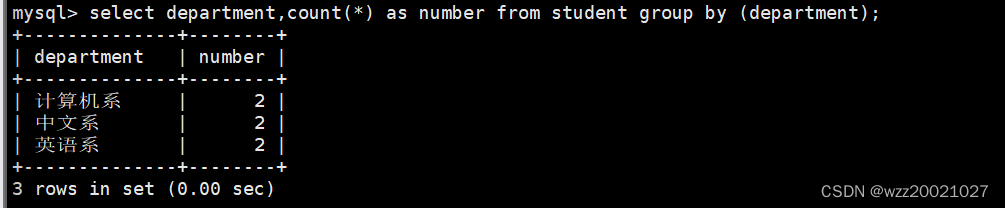
6.从student表中查询每个院系有多少人
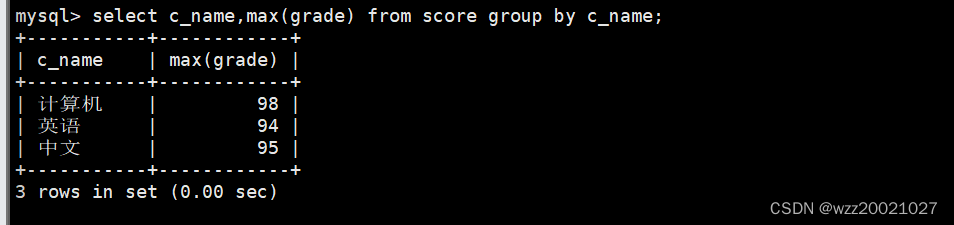
7.从score表中查询每个科目的最高分
8.查询李四的考试科目(c_name)和考试成绩(grade)

9.用连接的方式查询所有学生的信息和考试信息

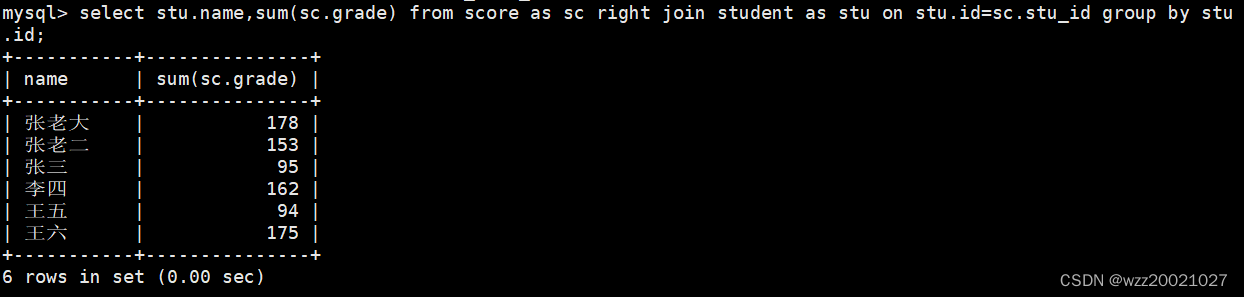
10.计算每个学生的总成绩
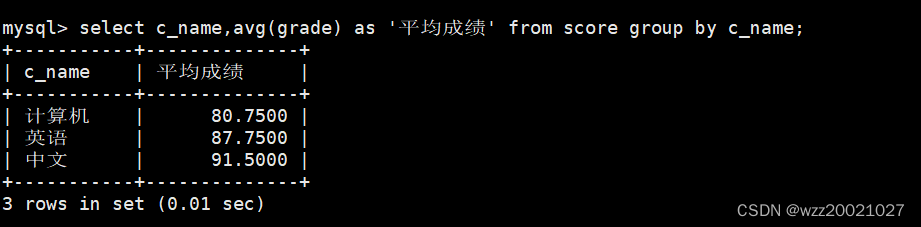
11.计算每个考试科目的平均成绩
12.查询计算机成绩低于95的学生信息

13.查询同时参加计算机和英语考试的学生的信息

14.将计算机考试成绩按从高到低进行排序
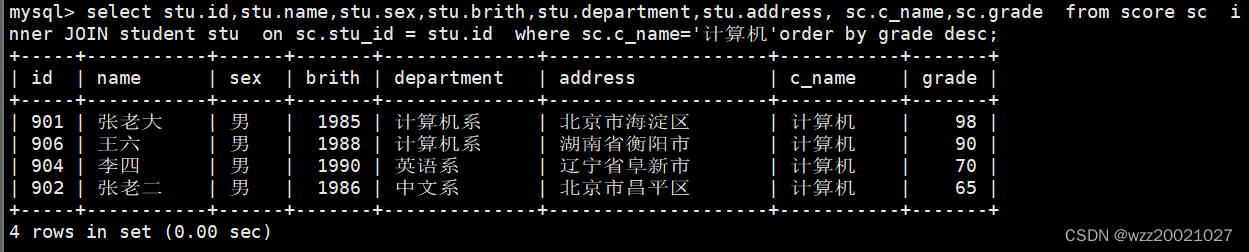
15.从student表和score表中查询出学生的学号,然后合并查询结果
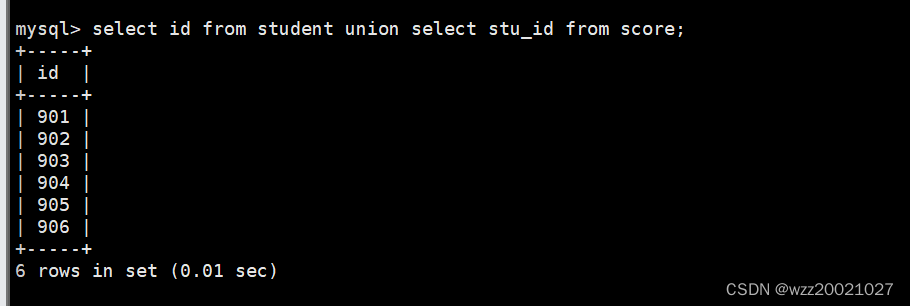
16.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
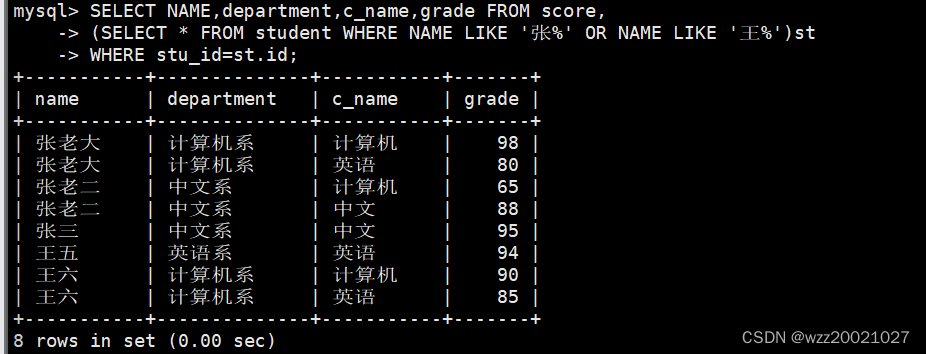
17.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩