原文链接
引言
本篇我们要讲解的模型是大名鼎鼎的支持向量机 SVM,这是曾经在机器学习界有着近乎「垄断」地位的模型,影响力持续了好多年。直至今日,即使深度学习神经网络的影响力逐渐增强,但 SVM 在中小型数据集上依旧有着可以和神经网络抗衡的极好效果和模型鲁棒性。

支持向量机学习方法,针对不同的情况,有由简至繁的不同模型:
-
线性可分支持向量机(linear support vector machine in linearly separable case):训练数据线性可分的情况下,通过硬间隔最大化(hard margin maximization),学习一个线性的分类器,即线性可分支持向量机(亦称作硬间隔支持向量机)。
-
线性支持向量机(linear support vector machine):训练数据近似线性可分的情况下,通过软间隔最大化(soft margin maximization),学习一个线性的分类器,称作线性支持向量机(又叫软间隔支持向量机)。
-
非线性支持向量机(non-linear support vector machine):训练数据线性不可分的情况下,通过使用核技巧(kernel trick)及软间隔最大化,学习非线性分类器,称作非线性支持向量机。
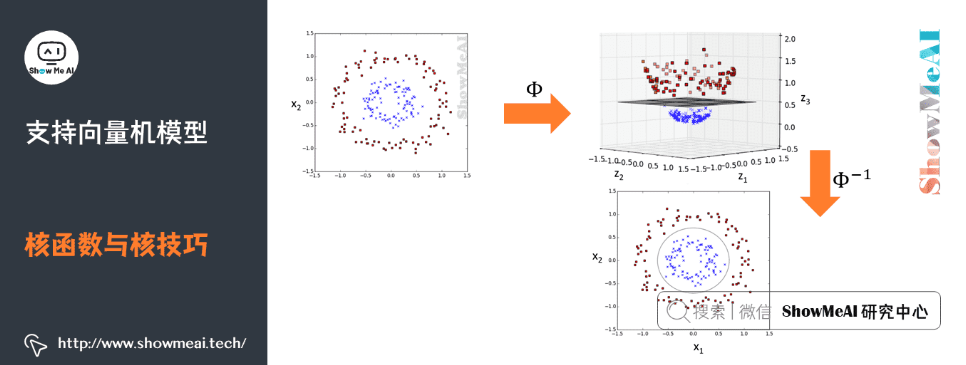
支持向量机可以借助核技巧完成复杂场景下的非线性分类,当输入空间为欧式空间或离散集合、特征空间为希尔贝特空间时,核函数(kernel function)表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。
通过使用核函数可以学习非线性支持向量机,等价于隐式地在高维的特征空间中学习线性支持向量机。这样的方法称为核技巧。
1.最大间隔分类器
1)分类问题与线性模型
分类问题是监督学习的一个核心问题。在监督学习中,当输出变量取有限个离散值时,预测问题便成为分类问题。

实际生活中,有很多问题的本质都是分类,如识别某种模式:文本分类、分词、词性标注、图像内容识别和目标检测等。
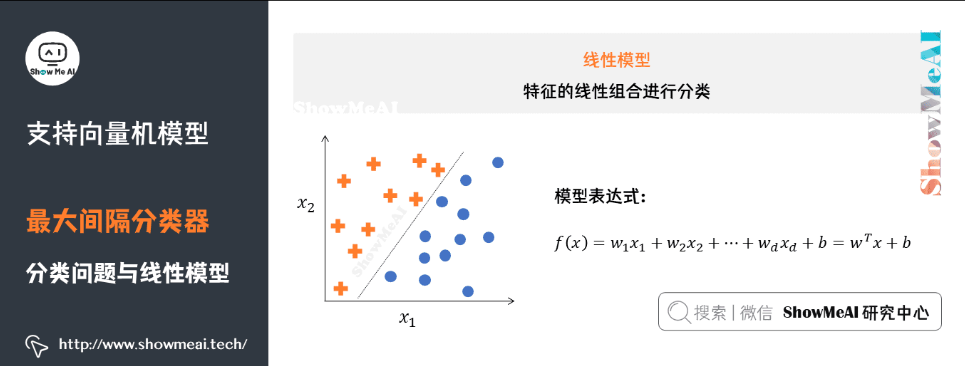
分类问题的数学理解是空间划分(或者寻找不同类别的决策边界),如图所示是一个简单的线性分类器(这部分更详细的讲解参考ShowMeAI文章 图解机器学习 | 机器学习基础知识 和 图解机器学习 | 逻辑回归算法详解)。
2)最大间隔分类器
不同的模型在解决分类问题时,会有不同的处理方式,直观上看,我们会使用不同的决策边界对样本进行划分。
如图中「冰墩墩」与「雪容融」两类样本点,我们对其进行分类,可以完成该分类任务的决策边界有无数个。而我们这里介绍到的 SVM 模型,要求更高一些,它不仅仅希望把两类样本点区分开,还希望找到鲁棒性最高、稳定性最好的决策边界(对应图中的黑色直线)。

这个决策边界与两侧「最近」的数据点有着「最大」的距离,这意味着决策边界具有最强的容错性,不容易受到噪声数据的干扰。直观的理解就是,如果决策边界抖动,最不容易「撞上」样本点或者进而导致误判。