机器学习笔记之受限玻尔兹曼机——对数似然梯度求解
- 引言
- 回顾:含隐变量能量模型的对数似然梯度
- 受限玻尔兹曼机的对数似然梯度
- 模型参数求解主体思路
- 求解过程
引言
上一节介绍了含隐变量能量模型的对数似然梯度求解。本节针对受限玻尔兹曼机,对模型参数进行求解。
回顾:含隐变量能量模型的对数似然梯度
已知一个随机变量集合
X
\mathcal X
X,随机变量间关系可描述成马尔可夫随机场,并包含观测变量
v
v
v和隐变量
h
h
h两种。
根据能量模型的描述,将联合概率分布
P
(
X
)
\mathcal P(\mathcal X)
P(X)表示为如下形式:
P
(
X
)
=
P
(
h
,
v
)
=
1
Z
exp
{
−
E
[
h
,
v
]
}
\mathcal P(\mathcal X) = \mathcal P(h,v) = \frac{1}{\mathcal Z} \exp\{ - \mathbb E[h,v]\}
P(X)=P(h,v)=Z1exp{−E[h,v]}
其中,
Z
\mathcal Z
Z表示配分函数。如果此时给定样本集合(基于观测变量的集合):
V
=
{
v
(
i
)
}
i
=
1
N
v
(
i
)
∈
R
n
\mathcal V = \{v^{(i)}\}_{i=1}^N \quad v^{(i)} \in \mathbb R^n
V={v(i)}i=1Nv(i)∈Rn
关于样本集合
V
\mathcal V
V的对数似然
L
(
θ
)
\mathcal L(\theta)
L(θ)可表示为:
各样本间依然服从‘独立同分布’。
L
(
θ
)
=
1
N
∑
v
(
i
)
∈
V
log
P
(
v
(
i
)
;
θ
)
\mathcal L(\theta) = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta)
L(θ)=N1v(i)∈V∑logP(v(i);θ)
对于对数似然
L
(
θ
)
\mathcal L(\theta)
L(θ)的梯度
∇
θ
L
(
θ
)
\nabla_{\theta}\mathcal L(\theta)
∇θL(θ)可表示为:
∇
θ
L
(
θ
)
=
∂
∂
θ
[
1
N
∑
v
(
i
)
∈
V
log
P
(
v
(
i
)
;
θ
)
]
=
1
N
∑
v
(
i
)
∈
V
∇
θ
log
P
(
v
(
i
)
;
θ
)
∇
θ
log
P
(
v
(
i
)
;
θ
)
=
∑
h
(
i
)
,
v
(
i
)
{
P
(
h
(
i
)
,
v
(
i
)
)
⋅
∂
∂
θ
[
E
(
h
(
i
)
,
v
(
i
)
)
]
}
−
∑
h
(
i
)
{
P
(
h
(
i
)
∣
v
(
i
)
)
⋅
∂
∂
θ
[
E
(
h
(
i
)
,
v
(
i
)
)
]
}
⇒
{
h
(
i
)
=
(
h
1
(
i
)
,
h
2
(
i
)
,
⋯
,
h
m
(
i
)
)
T
v
(
i
)
=
(
v
1
(
i
)
,
v
2
(
i
)
,
⋯
,
v
n
(
i
)
)
T
m
+
n
=
p
\begin{aligned} \nabla_{\theta}\mathcal L(\theta) & = \frac{\partial}{\partial \theta} \left[\frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \log \mathcal P(v^{(i)};\theta)\right] \\ & = \frac{1}{N} \sum_{v^{(i)} \in \mathcal V} \nabla_{\theta} \log \mathcal P(v^{(i)};\theta) \\ \nabla_{\theta} \log \mathcal P(v^{(i)};\theta) & = \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} - \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)})\cdot \frac{\partial}{\partial \theta} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \\ & \Rightarrow \begin{cases} h^{(i)} = (h_1^{(i)},h_2^{(i)},\cdots,h_m^{(i)})^T \\ v^{(i)} = (v_1^{(i)},v_2^{(i)},\cdots,v_n^{(i)})^T \\ m + n = p \end{cases} \end{aligned}
∇θL(θ)∇θlogP(v(i);θ)=∂θ∂⎣⎡N1v(i)∈V∑logP(v(i);θ)⎦⎤=N1v(i)∈V∑∇θlogP(v(i);θ)=h(i),v(i)∑{P(h(i),v(i))⋅∂θ∂[E(h(i),v(i))]}−h(i)∑{P(h(i)∣v(i))⋅∂θ∂[E(h(i),v(i))]}⇒⎩⎪⎨⎪⎧h(i)=(h1(i),h2(i),⋯,hm(i))Tv(i)=(v1(i),v2(i),⋯,vn(i))Tm+n=p
受限玻尔兹曼机的对数似然梯度
模型参数求解主体思路
基于受限玻尔兹曼机结构的联合概率分布
P
(
X
)
\mathcal P(\mathcal X)
P(X)表示如下:
P
(
X
)
=
P
(
h
,
v
)
=
1
Z
exp
[
v
T
W
h
+
b
T
v
+
c
T
h
]
\mathcal P(\mathcal X) = \mathcal P(h,v) = \frac{1}{\mathcal Z} \exp \left[v^T \mathcal W h + b^Tv + c^Th \right]
P(X)=P(h,v)=Z1exp[vTWh+bTv+cTh]
关于模型参数
θ
\theta
θ的描述,自然是
θ
=
{
W
,
b
,
c
}
\theta = \{\mathcal W,b,c\}
θ={W,b,c}。但本质上只有一种信息表示:结点之间关联关系的表示。其中
b
,
c
b,c
b,c分别表示某观测变量/某隐变量与自身的关联关系,这种关系被视作特殊的节点间关系。在本节中,仅求解一般性的关联关系——存在边的,隐变量与观测变量之间的关联关系,也就是模型参数
W
\mathcal W
W:
W
=
(
w
11
,
w
12
,
⋯
,
w
1
n
w
21
,
w
22
,
⋯
,
w
2
n
⋮
w
m
1
,
w
m
2
,
⋯
,
w
m
n
)
m
×
n
W
(
i
)
=
[
w
k
j
(
i
)
]
m
×
n
\mathcal W = \begin{pmatrix} w_{11},w_{12},\cdots,w_{1n} \\ w_{21},w_{22},\cdots,w_{2n} \\ \vdots \\ w_{m1},w_{m2},\cdots,w_{mn} \\ \end{pmatrix}_{m \times n} \quad \mathcal W^{(i)} = [w_{kj}^{(i)}]_{m \times n}
W=⎝⎜⎜⎜⎛w11,w12,⋯,w1nw21,w22,⋯,w2n⋮wm1,wm2,⋯,wmn⎠⎟⎟⎟⎞m×nW(i)=[wkj(i)]m×n
主体思路:如果能够将
W
\mathcal W
W的梯度求解出来,自然就可以使用极大似然估计,基于梯度上升法,将
W
\mathcal W
W近似出来:
W
(
t
+
1
)
⇐
W
(
t
)
+
η
∇
W
L
(
W
)
\mathcal W^{(t+1)} \Leftarrow \mathcal W^{(t)} + \eta \nabla_{\mathcal W} \mathcal L(\mathcal W)
W(t+1)⇐W(t)+η∇WL(W)
求解过程
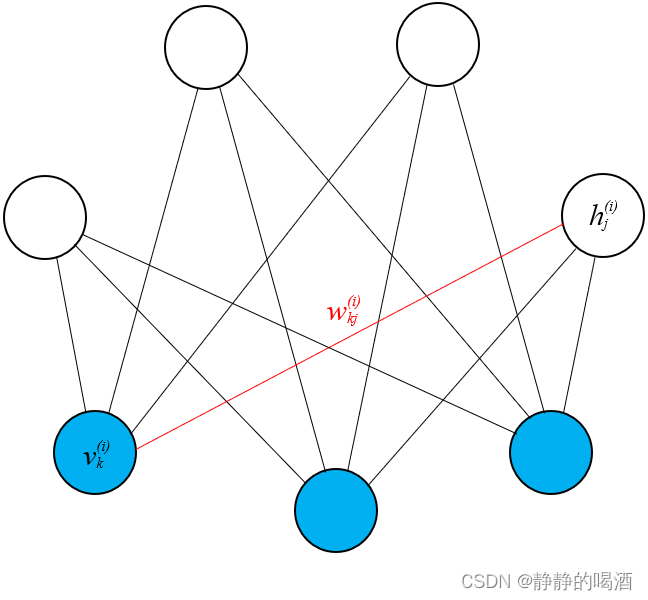
基于能量模型的对数似然梯度,将受限玻尔兹曼机的结构表示代入公式中:
依然仅针对一个观测样本
v
(
i
)
v^{(i)}
v(i),该样本的第
k
k
k个分量(维度)
v
k
(
i
)
v_k^{(i)}
vk(i)和对应隐变量
h
(
i
)
h^{(i)}
h(i)的第
j
j
j个分量
h
j
(
i
)
h_j^{(i)}
hj(i)之间的模型参数
w
k
j
(
i
)
w_{kj}^{(i)}
wkj(i)进行积分。
∇
θ
[
log
P
(
v
(
i
)
;
θ
)
]
=
∂
∂
w
k
j
(
i
)
[
log
P
(
v
(
i
)
;
θ
)
]
=
−
∑
h
(
i
)
{
P
(
h
(
i
)
∣
v
(
i
)
)
⋅
∂
∂
w
k
j
(
i
)
[
E
[
h
(
i
)
,
v
(
i
)
]
]
}
+
∑
h
(
i
)
,
v
(
i
)
{
P
(
h
(
i
)
,
v
(
i
)
)
⋅
∂
∂
w
k
j
(
i
)
[
E
(
h
(
i
)
,
v
(
i
)
)
]
}
\begin{aligned} \nabla_{\theta}\left[\log \mathcal P(v^{(i)};\theta)\right] & = \frac{\partial}{\partial w_{kj}^{(i)}} \left[ \log \mathcal P(v^{(i)};\theta)\right] \\ & = - \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot \frac{\partial}{\partial w_{kj}^{(i)}} \left[ \mathbb E [h^{(i)},v^{(i)}]\right]\right\} + \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot \frac{\partial}{\partial w_{kj}^{(i)}} \left[\mathbb E(h^{(i)},v^{(i)})\right]\right\} \end{aligned}
∇θ[logP(v(i);θ)]=∂wkj(i)∂[logP(v(i);θ)]=−h(i)∑{P(h(i)∣v(i))⋅∂wkj(i)∂[E[h(i),v(i)]]}+h(i),v(i)∑{P(h(i),v(i))⋅∂wkj(i)∂[E(h(i),v(i))]}
由于这里不考虑模型参数
b
,
c
b,c
b,c的影响,使用
Δ
\Delta
Δ进行表示。因而 能量函数
E
[
h
(
i
)
,
v
(
i
)
]
\mathbb E[h^{(i)},v^{(i)}]
E[h(i),v(i)]可表示为如下形式:
E
[
h
(
i
)
,
v
(
i
)
]
=
−
{
[
h
(
i
)
]
T
W
(
i
)
v
(
i
)
+
Δ
(
i
)
}
=
−
(
∑
k
=
1
m
∑
j
=
1
n
h
k
(
i
)
⋅
w
k
j
(
i
)
⋅
v
j
(
i
)
+
Δ
(
i
)
)
\begin{aligned} \mathbb E[h^{(i)},v^{(i)}] & = - \left\{[h^{(i)}]^T \mathcal W^{(i)} v^{(i)} + \Delta^{(i)}\right\} \\ & = - \left(\sum_{k=1}^m \sum_{j=1}^n h_k^{(i)} \cdot w_{kj}^{(i)} \cdot v_j^{(i)} + \Delta^{(i)} \right) \end{aligned}
E[h(i),v(i)]=−{[h(i)]TW(i)v(i)+Δ(i)}=−(k=1∑mj=1∑nhk(i)⋅wkj(i)⋅vj(i)+Δ(i))
将其代入,有:
能量函数
E
[
h
(
i
)
,
v
(
i
)
]
\mathbb E[h^{(i)},v^{(i)}]
E[h(i),v(i)]仅对
w
k
j
(
i
)
w_{kj}^{(i)}
wkj(i)一项进行求导,连加号
∑
≠
k
m
,
∑
≠
j
n
\sum_{\neq k}^m,\sum_{\neq j}^n
∑=km,∑=jn均视作常数:
∂
∂
w
k
j
(
i
)
[
E
[
h
(
i
)
,
v
(
i
)
]
]
=
∂
∂
w
k
j
(
i
)
[
−
(
h
1
(
i
)
⋅
w
11
(
i
)
⋅
v
1
(
i
)
+
⋯
h
k
(
i
)
⋅
w
k
j
(
i
)
⋅
v
j
(
i
)
+
⋯
+
h
m
(
i
)
⋅
w
m
n
(
i
)
⋅
v
n
(
i
)
+
Δ
(
i
)
)
]
=
∂
∂
w
k
j
(
i
)
[
−
(
h
k
(
i
)
⋅
w
k
j
(
i
)
⋅
v
j
(
i
)
)
]
=
−
h
k
(
i
)
v
j
(
i
)
∇
θ
[
log
P
(
v
(
i
)
;
θ
)
]
=
−
∑
h
(
i
)
{
P
(
h
(
i
)
∣
v
(
i
)
)
⋅
(
−
h
k
(
i
)
v
j
(
i
)
)
}
+
∑
h
(
i
)
,
v
(
i
)
{
P
(
h
(
i
)
,
v
(
i
)
)
⋅
(
−
h
k
(
i
)
v
j
(
i
)
)
}
\begin{aligned} \frac{\partial}{\partial w_{kj}^{(i)}} \left[\mathbb E[h^{(i)},v^{(i)}]\right] & = \frac{\partial}{\partial w_{kj}^{(i)}} \left[- \left(h_1^{(i)} \cdot w_{11}^{(i)} \cdot v_1^{(i)} + \cdots h_k^{(i)} \cdot w_{kj}^{(i)} \cdot v_j^{(i)} + \cdots + h_m^{(i)} \cdot w_{mn}^{(i)} \cdot v_{n}^{(i)} + \Delta^{(i)}\right)\right] \\ & = \frac{\partial}{\partial w_{kj}^{(i)}} \left[ -\left(h_k^{(i)} \cdot w_{kj}^{(i)} \cdot v_j^{(i)}\right)\right] \\ & = - h_{k}^{(i)} v_j^{(i)} \\ \nabla_{\theta}\left[\log \mathcal P(v^{(i)};\theta)\right] & = -\sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot (-h_k^{(i)}v_j^{(i)})\right\} + \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot (-h_k^{(i)} v_j^{(i)})\right\} \end{aligned}
∂wkj(i)∂[E[h(i),v(i)]]∇θ[logP(v(i);θ)]=∂wkj(i)∂[−(h1(i)⋅w11(i)⋅v1(i)+⋯hk(i)⋅wkj(i)⋅vj(i)+⋯+hm(i)⋅wmn(i)⋅vn(i)+Δ(i))]=∂wkj(i)∂[−(hk(i)⋅wkj(i)⋅vj(i))]=−hk(i)vj(i)=−h(i)∑{P(h(i)∣v(i))⋅(−hk(i)vj(i))}+h(i),v(i)∑{P(h(i),v(i))⋅(−hk(i)vj(i))}
继续化简,有:
∇
θ
[
log
P
(
v
(
i
)
;
θ
)
]
=
∑
h
(
i
)
{
P
(
h
(
i
)
∣
v
(
i
)
)
⋅
h
k
(
i
)
v
j
(
i
)
}
−
∑
h
(
i
)
,
v
(
i
)
{
P
(
h
(
i
)
,
v
(
i
)
)
⋅
h
k
(
i
)
v
j
(
i
)
}
\begin{aligned} \nabla_{\theta}\left[\log \mathcal P(v^{(i)};\theta)\right] & = \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} - \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot h_k^{(i)} v_j^{(i)}\right\} \end{aligned}
∇θ[logP(v(i);θ)]=h(i)∑{P(h(i)∣v(i))⋅hk(i)vj(i)}−h(i),v(i)∑{P(h(i),v(i))⋅hk(i)vj(i)}
这里依然假设变量信息(隐变量、观测变量)服从伯努利分布(Bernoulli Distribution),因而所有变量均是离散型随机变量,并且仅有两种取值:
0
,
1
0,1
0,1。基于这种假设,可以继续向下化简:
- 先观察等号右侧第一项:
将∑ h ( i ) \sum_{h^{(i)}} ∑h(i)按照随机变量维度展开.
除去∑ h k ( i ) \sum_{h_k^{(i)}} ∑hk(i)项之外的其他项全被积分掉了。例如:
∑ h 1 ( i ) P ( h 1 ( i ) , h 2 ( i ) , ⋯ , h m ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) = h k ( i ) v j ( i ) ⋅ ∑ h 1 ( i ) P ( h 1 ( i ) , h 2 ( i ) , ⋯ , h m ( i ) ∣ v ( i ) ) = h k ( i ) v j ( i ) ⋅ P ( h 2 ( i ) , ⋯ , h m ( i ) ∣ v ( i ) ) \begin{aligned} & \quad \sum_{h_1^{(i)}} \mathcal P(h_1^{(i)},h_2^{(i)},\cdots,h_m^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)} \\ & = h_k^{(i)}v_j^{(i)} \cdot \sum_{h_1^{(i)}} \mathcal P(h_1^{(i)},h_2^{(i)},\cdots,h_m^{(i)} \mid v^{(i)}) \\ & = h_k^{(i)}v_j^{(i)} \cdot \mathcal P(h_2^{(i)},\cdots,h_m^{(i)} \mid v^{(i)}) \end{aligned} \\ h1(i)∑P(h1(i),h2(i),⋯,hm(i)∣v(i))⋅hk(i)vj(i)=hk(i)vj(i)⋅h1(i)∑P(h1(i),h2(i),⋯,hm(i)∣v(i))=hk(i)vj(i)⋅P(h2(i),⋯,hm(i)∣v(i))
剩余的项以此类推~从而有:
∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) } = ∑ h 1 ( i ) , ⋯ , ∑ h k ( i ) , ⋯ , ∑ h m ( i ) { P ( h 1 ( i ) , ⋯ , h k ( i ) , ⋯ , h m ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) } = ∑ h k ( i ) P ( h k ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) \begin{aligned} \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} & = \sum_{h_1^{(i)}},\cdots,\sum_{h_k^{(i)}},\cdots,\sum_{h_m^{(i)}} \left\{\mathcal P(h_1^{(i)},\cdots,h_k^{(i)},\cdots,h_m^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} \\ & = \sum_{h_k^{(i)}} \mathcal P(h_k^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)} \end{aligned} h(i)∑{P(h(i)∣v(i))⋅hk(i)vj(i)}=h1(i)∑,⋯,hk(i)∑,⋯,hm(i)∑{P(h1(i),⋯,hk(i),⋯,hm(i)∣v(i))⋅hk(i)vj(i)}=hk(i)∑P(hk(i)∣v(i))⋅hk(i)vj(i)
将 h k ( i ) = { 0 , 1 } h_k^{(i)} = \{0,1\} hk(i)={0,1}分别代入,有:
P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) + 0 \mathcal P(h_k^{(i)}=1 \mid v^{(i)}) \cdot v_j^{(i)} + 0 P(hk(i)=1∣v(i))⋅vj(i)+0 - 再观察等号右侧第二项:
将P ( h ( i ) , v ( i ) ) \mathcal P(h^{(i)},v^{(i)}) P(h(i),v(i))按照条件概率公式展开.
将仅和v ( i ) v^{(i)} v(i)相关的和仅和h ( i ) h^{(i)} h(i)相关的项分开.
第一项的结果∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) } = P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) \sum_{h^{(i)}}\left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} = \mathcal P(h_k^{(i)}=1 \mid v^{(i)}) \cdot v_j^{(i)} ∑h(i){P(h(i)∣v(i))⋅hk(i)vj(i)}=P(hk(i)=1∣v(i))⋅vj(i)直接拿来用就可以。
∑ h ( i ) , v ( i ) { P ( h ( i ) , v ( i ) ) ⋅ h k ( i ) v j ( i ) } = ∑ h ( i ) , v ( i ) { P ( v ( i ) ) ⋅ P ( h ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) } = ∑ v ( i ) P ( v ( i ) ) ∑ h ( i ) { P ( h ( i ) ∣ v ( i ) ) ⋅ h k ( i ) v j ( i ) } = ∑ v ( i ) P ( v ( i ) ) ⋅ P ( h k ( i ) = 1 ∣ v ( i ) ) ⋅ v j ( i ) \begin{aligned} \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(h^{(i)},v^{(i)}) \cdot h_k^{(i)} v_j^{(i)}\right\} & = \sum_{h^{(i)},v^{(i)}} \left\{\mathcal P(v^{(i)}) \cdot \mathcal P(h^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} \\ & = \sum_{v^{(i)}} \mathcal P(v^{(i)}) \sum_{h^{(i)}} \left\{\mathcal P(h^{(i)} \mid v^{(i)}) \cdot h_k^{(i)}v_j^{(i)}\right\} \\ & = \sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)} \end{aligned} h(i),v(i)∑{P(h(i),v(i))⋅hk(i)vj(i)}=h(i),v(i)∑{P(v(i))⋅P(h(i)∣v(i))⋅hk(i)vj(i)}=v(i)∑P(v(i))h(i)∑{P(h(i)∣v(i))⋅hk(i)vj(i)}=v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)
最终,受限玻尔兹曼机的梯度可表示为:
∇
θ
[
log
P
(
v
(
i
)
;
θ
)
]
=
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
⋅
v
j
(
i
)
−
∑
v
(
i
)
P
(
v
(
i
)
)
⋅
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
⋅
v
j
(
i
)
\nabla_{\theta}\left[\log \mathcal P(v^{(i)};\theta)\right] = \mathcal P(h_k^{(i)}=1 \mid v^{(i)}) \cdot v_j^{(i)} - \sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}
∇θ[logP(v(i);θ)]=P(hk(i)=1∣v(i))⋅vj(i)−v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)
继续观察等号右侧第一项:
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
⋅
v
j
(
i
)
\mathcal P(h_k^{(i)}=1 \mid v^{(i)}) \cdot v_j^{(i)}
P(hk(i)=1∣v(i))⋅vj(i)由于
v
(
i
)
v^{(i)}
v(i)是一个样本,那么
v
j
(
i
)
v_j^{(i)}
vj(i)自然是已知的;而
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
\mathcal P(h_k^{(i)}=1 \mid v^{(i)})
P(hk(i)=1∣v(i))在受限玻尔兹曼机——推断任务(后验概率)可以将其表示为Sigmoid函数的形式:
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
=
Sigmoid
(
∑
l
=
1
n
w
l
k
(
i
)
⋅
v
l
+
c
l
)
\mathcal P(h_k^{(i)}=1 \mid v^{(i)}) = \text{Sigmoid}(\sum_{l=1}^n w_{lk}^{(i)} \cdot v_l + c_l)
P(hk(i)=1∣v(i))=Sigmoid(l=1∑nwlk(i)⋅vl+cl)
因此可以判定:第一项是可求的。
关于等号右侧第二项:
∑
v
(
i
)
P
(
v
(
i
)
)
⋅
P
(
h
k
(
i
)
=
1
∣
v
(
i
)
)
⋅
v
j
(
i
)
\sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}
∑v(i)P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)
这里关于
v
(
i
)
v^{(i)}
v(i)的积分是约不掉的,基于它的伯努利分布,v^{(i)}的
n
n
n维随机变量,其时间复杂度是
O
(
n
)
=
2
n
\mathcal O(n) = 2^n
O(n)=2n。因此不能硬求它的梯度结果。需要使用吉布斯采样/对比散度的方式进行求解。
下一节将继续介绍关于受限玻尔兹曼机使用对比散度的方式求解对数似然梯度。
相关参考:
直面配分函数:6-Log-Likelihood Gradient of RBM