MySQL除了提供一些聚合函数供我们使用,同时还提供了很多的内置扩展函数,这些函数有的是进行日期处理的,有的是进行字符串处理的,有的则是进行数值处理,以及其它的种种函数,这些函数可以帮助我们对数据进行加工,得出我们想要的信息,需要注意的是函数要在查询语句select中使用,不可单独使用
目前为止,我们接触的查询函数,都是针对一张单表,但是很多的数据是彼此关联的,关系模型如此受欢迎,也是因为它较好的解决了多张表互相联系的查询,这篇文章开始,我们就正式开始了复合查询的学习,学习不同表中的数据如何进行关联
子查询是指在一个语句中,出现多个嵌套的select查询语句
在本篇文章中,将会用到4张表,部门表(dept),员工表(emp),信息表(msg),薪水等级表(salgrade),表中具体定义就不给出了,将在例子中体现出来
目录
内置函数
1.日期函数
2.字符串函数
3. 数学函数
4.其它的函数
复合查询
笛卡尔积
自连接
内连接
外连接
子查询
单行子查询
多行子查询
多列子查询
在from子句中使用子查询
合并查询
内置函数
1.日期函数
日期函数能方便对数据库中的日期数据进行处理,具体函数及功能描述如下表
| 函数名称 | 功能描述 |
|---|---|
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp() | 当前时间戳 |
| date_add(date, interval d_value_type) | 在date中添加日期或时间 interval后的数值单位可以是:year,minute,second,day |
| date_sub(date, interval d_value_type) | 在date中减去日期或时间 interval后的数值单位可以是:year,minute,second,day |
| datediff(date1, date2) | 两个日期的差值,单位是天 |
| now() | 当前的日期和时间 |
| date(now()) | 将当前的日期时间进行截断,只取当前日期 |
注意日期和时间并不是一个东西,日期是指年月日,而时间是指时分秒
加下来依次举例这些日期函数的用法,看下图
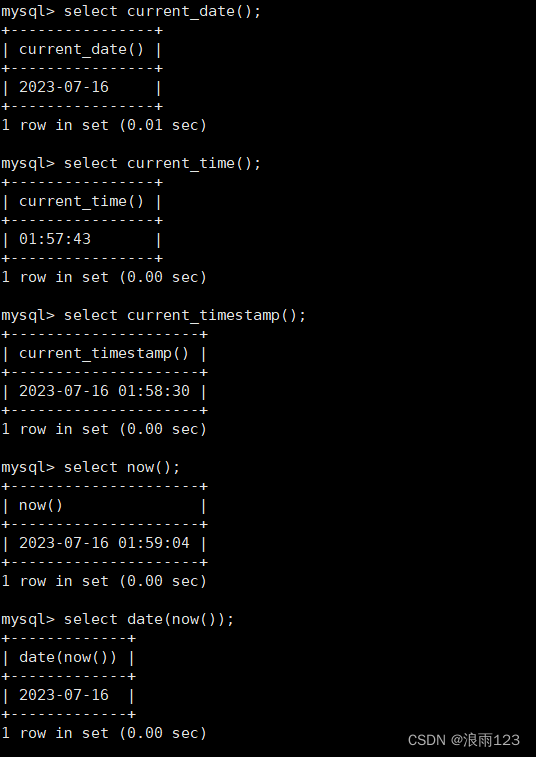
上面这几个函数是比较简单的,看一眼基本就知道该怎么使用了,其中时间戳是指从指 Unix 时间戳,即自从 Unix 纪元(1970 年 1 月 1 日 00:00:00)到当前时间的秒数,这里数据库将其转换成日期和时间的形式显示出来
注意date函数中的参数不一定是now(),你可以参数其他的日期时间,最后都会截取日期部分
接下来我们看一下稍微有些麻烦的函数,它们是如何操作的
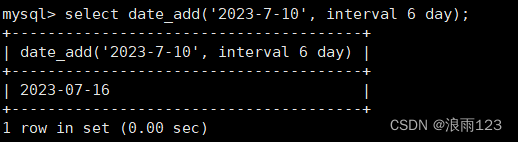
先看看date_add()的用法,这个是往一个给定的日期中增加某个日期单位的数目,然后返回增加后的日期,例如给定一个日期为'2023-7-10',给这个日期加上6天,返回6天后的日期
具体操作语句如下:
select date_add('2023-7-10', interval 6 day);
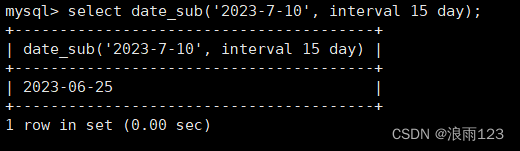
date_sub()的用法,这个是往一个给定的日期中减去某个日期单位的数目,然后返回减去后的日期,例如给定一个日期为'2023-7-10',给这个日期减去15天,返回15天前的日期
具体操作语句如下:
select date_sub('2023-7-10', interval 15 day);
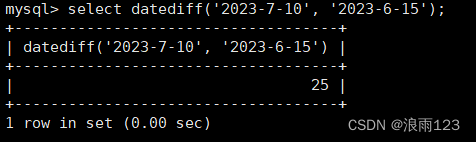
datediff()这个函数需要给定两个日期参数,然后该函数会返回这两个日期之间的天数差值
假设计算'2023-06-25' 与 '2023-7-10'之间相差了多少天,就可以使用datediff()来解决
具体操作如下
select datediff('2023-7-10', '2023-06-25');
2.字符串函数
字符串函数能方便对数据库中的字符串数据进行处理,具体函数及功能描述如下表
| 函数名称 | 功能描述 |
|---|---|
| charset(string) | 返回字符串的字符集 |
| concat(string [,...]) | 连接多个字符串 |
| instr(string, substring) | 返回string在substring中出现的位置,如果没有出现就返回0 |
| ucase(string) | 将字符串string都转换成大写 |
| lcase(string) | 将字符串string都转换成小写 |
| left(string, length) | 返回从string左边起length个字符 |
| length(string) | 返回string的长度 |
| replace(str, search_str, replace_str) | 在str中用replace_str替换search_str |
| strcmp(string1, string2) | 逐字符的比较两个字符串,规则和C语言的一样 |
| substring(str, position, length) | 从str的position开始,取length个字符 |
| ltrim(string) | 去除前空格 |
| rtrim(string) | 去除后空格 |
字符串函数有很多,但是很多函数看看就知道怎么使用了,因此,这样的函数就不再演示了,笔者将稍微有些复杂的挑出来演示
concat()这个函数可以将多个字符串拼接起来,以员工表来演示
显示员工的一些信息,格式为:xxx的职业是xx, 工资为xx
select concat(ename, ',职业是', job, ',工资为', sal) from emp;

replace(str, search_str, replace_str),该函数可以用来替换一个字符串中的某些内容
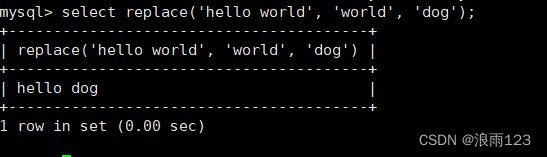
substring()这个函数可以看作是left函数的进阶版,可以从指定位置x处取n个字符
下图程序演示从第3个字符开始取5个字符
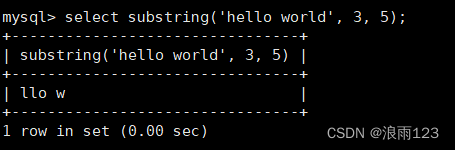
ltrim(),该函数用来删除字符串左侧的空格,rtrim()是删除字符串右侧的空格
下面演示该函数的用法,要注意该函数不会修改原始数据,而是返回一个新的字符串
3. 数学函数
数学函数能方便对数据库中的数值数据进行处理,具体函数及功能描述如下表
| 函数名称 | 功能描述 |
|---|---|
| abs(num) | 求绝对值 |
| bin(decimal_num) | 十进制数转换成二进制数 |
| hex(decimal_num) | 十进制数转换成十六进制数 |
| conv(num, from_base, to_base) | 进制转换 |
| ceiling(num) | 向上取整 |
| floor(num) | 向下取整 |
| format(num, decimal_num) | 格式化,保留小数位数 |
| rand() | 返回随机浮点数,范围[0.0-1.0) |
| mod(num, denominator) | 取模,求余 |
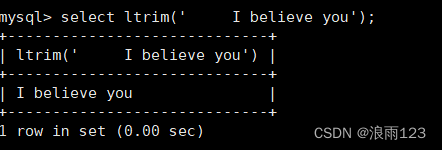
数学函数,abs(), bin(), hex(), conv(),ceiling(), floor()这些是比较简单的函数,我们演示一下如何使用即可,剩下几个我们详细看看如何使用

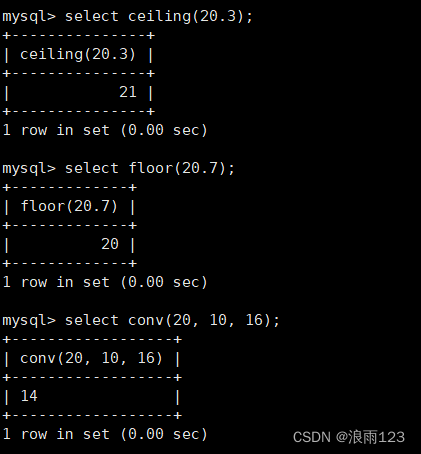
num:要进行转换的数值from_base:原始数值的数制,可以是2到36之间的任意整数to_base:目标数值的数制,可以是2到36之间的任意整数
format()是用来保留小数的位数(会自动进行四舍五入)

rand()产生从0.0到1.0之间的任意一个数,如果想要产生0-100之间的随机数,那么将rand()*100并将结果进行取整即可
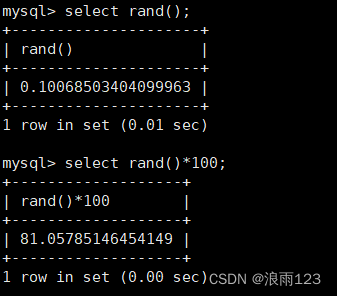
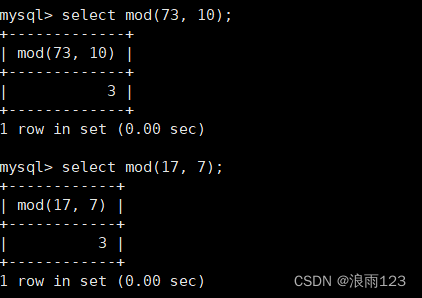
mod()函数,第一个参数是要被取模的数,第二个参数是用哪个数来取模
4.其它的函数
除了对数据进行处理的相关函数,MySQL还提供了一些其他的,查询用户信息的相关函数,这些函数不是很多,也并不常用,大家简单了解一下
| 函数名称 | 功能描述 |
|---|---|
| user() | 显示当前用户 |
| md5(str) | 对一个字符串进行md5摘要,摘要后得到一个32位字符串 |
| database() | 显示当前正在使用的数据库 |
| password() | MySQL使用该函数对用户密码进行加密 |
| ifnull(val1, val2) | 如果val1为NULL,返回val2,否则返回val1 |
user(), database(), ifnull(val1, val2)的使用相对比较简单,这里简单演示一下

md5()以及password()是对密码进行处理的相关函数,我们来详细了解一下这两个函数的用途。数据库在保存数据的时候,难免要存储用户的密码信息,如果用户的密码信息直接就存放到库中,这是很危险的一个举动,如果数据库的信息被别人盗取,或者被一些不法分子利用管理权限窃取,因为密码是明文存放的,所以在数据中找到某个用户就能直接得出他的密码。为了杜绝这样的事情发生,在存储密码数据的时候,数据库通常不会明文存放密码,而是将用户的密码通过某种规则,进行加密,将加密之后形成的字符串存储到数据库中,这样即使不法分子窃取了数据库数据,也不知道用户的真实密码是什么
而md5()就是对用户密码进行加密的一个函数,把用户的密码作为参数传进去,会返回一个32位字符串,就是加密过后的密码
我们建立一个简单的用户表来演示md5()的使用,表的定义如下
create table user(
user_name varchar(30),
password varchar(32)
);

如果直接插入,那么就会造成密码明文显示,密码就有很大的风险

通过md5()的使用,就可以对密码进行加密,那么如何将密码进行匹配呢?

通过查找实例可知,想要进行密码匹配就要再次使用md5()函数,并且提供正确的密码,然后才能查找到该用户,password()的用法是类似的,区别是password的加密更加复杂,需要更多的空间来存储,这里就不演示了
复合查询
笛卡尔积
首先我们得明白为什么会用到复合查询,然后明白复合查询是基于什么原理实现的,最后了解复合查询如何使用,接下来我们用职工表来说明

上图是部门表和员工表的所有信息,就拿员工表和部门表来说,在员工表中可以查到该员工所属部门的部门号,但是并没有部门的名称,现在要求查询员工的所有信息以及该员工所属部门的部门名称,这该怎么办,部门名称在部门表中,如果我们想要做到既有员工信息又有部门信息,那么就要将两张表统合在一起
那么如何将两张表统合在一起呢,计算机不想我们人那么灵活,可以直接分析,手动将两张表汇成一张表,那么计算机中采用的方法就是将两张表做笛卡尔积
什么是做笛卡尔积,简单来说就是将表A中的每一行与表B中的所有行都进行一个连接组成一系列新的信息,如下图
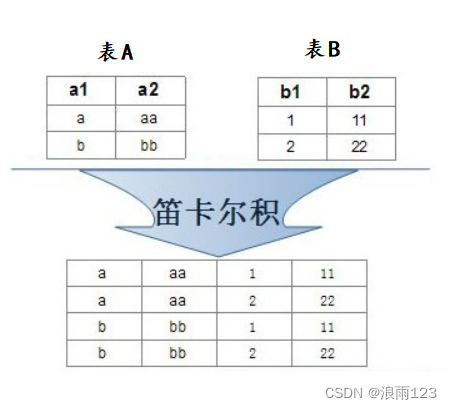
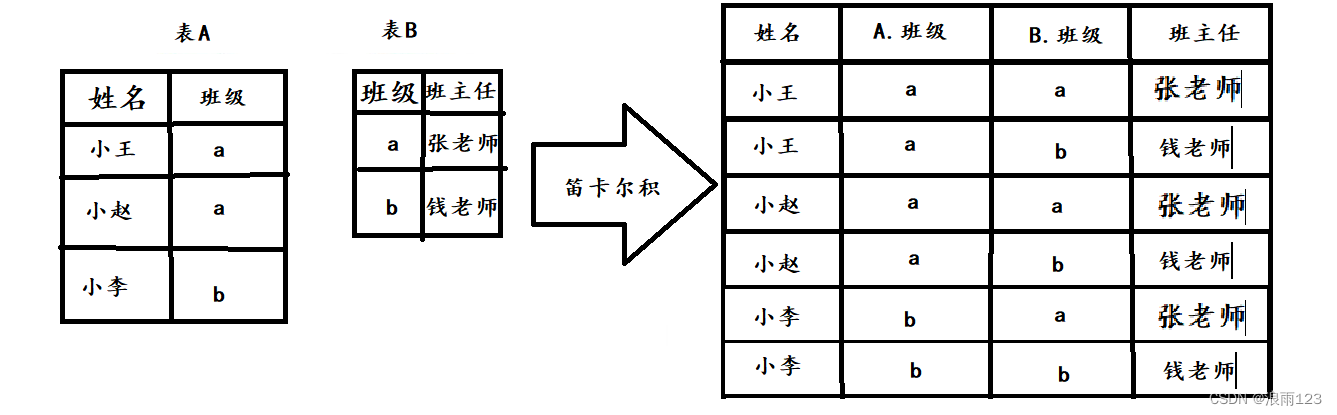
如上表,查找每位同学的班主任是谁,可以将表A与表B做笛卡尔积,但是可以明显发现,笛卡尔的结果虽然做到了将两张表的信息统合在一起,但是有很多的信息我们是不需要的,比如上表,小王的班级是a,和表B中的班级b的连接就显得没有意义,所以我们往往会对笛卡尔的结果进行一次筛选,而这个筛选的媒介就是两张表中的共同属性,也就是外键,如果两张表中的共同属性的值相同,则这个信息就保留,否则都剔除,也就是A.班级 = B.班级,班级符合,可以找到自己的班主任,如果A.班级 != B.班级,班级都不匹配,那么B.班级的班主任就不是该同学的班主任,这样的信息应该剔除掉,筛选后我们就能得到自己想要的信息了,这里举例是两张表,笛卡尔积可以多张表同时进行
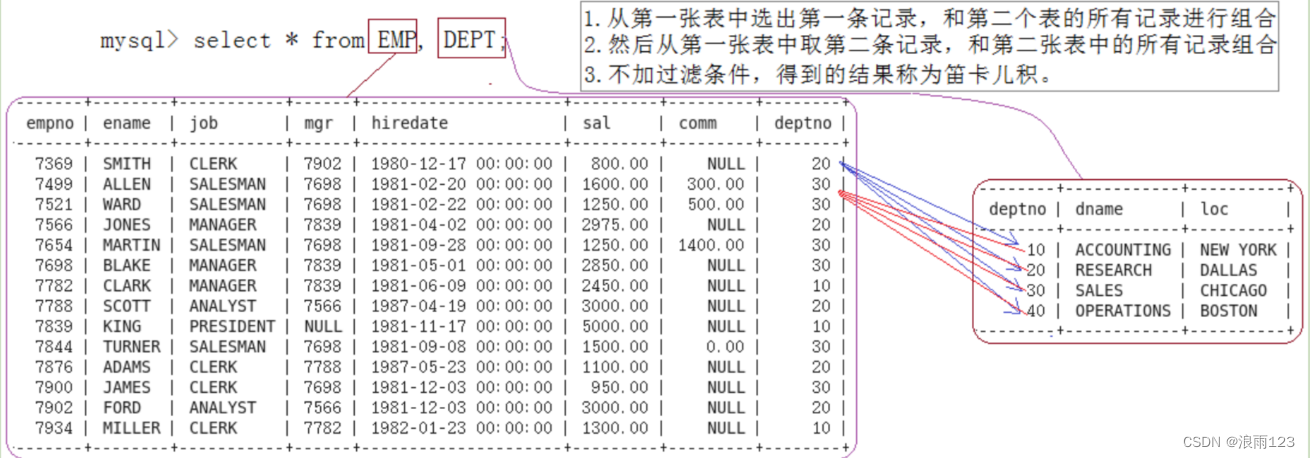
根据上述笛卡尔积的原理,我们接下来实现在数据库中查找员工所有的信息以及所在的部门名,MySQL中要进行多表连接(即做笛卡尔积),只需要在select的from子句中把要用到的表列出来即可,如下图,将员工表和部门表进行连接(数据太多,未显示完全)
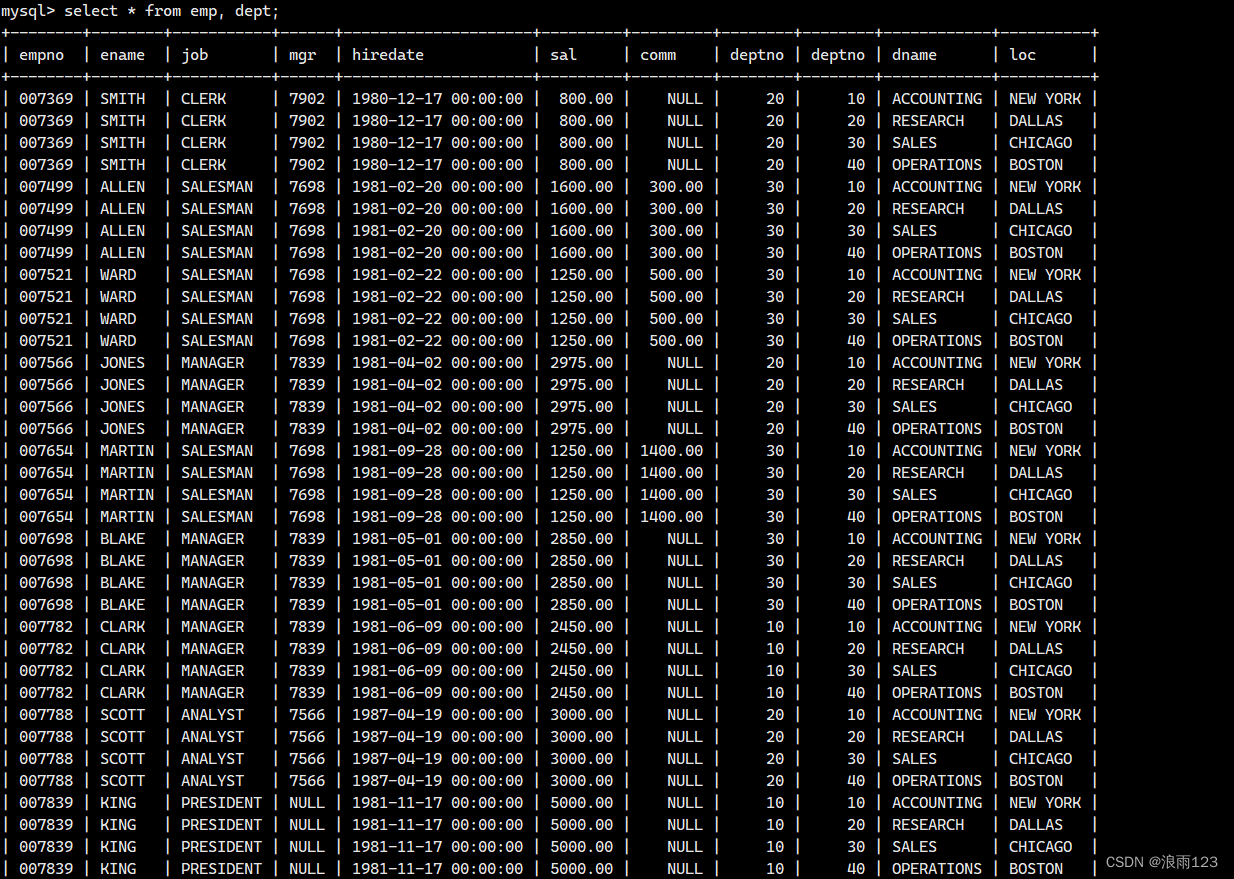
同样,这样做有很多的信息都是没用的,所以我们要进行一次筛选,也就是用部门号筛选
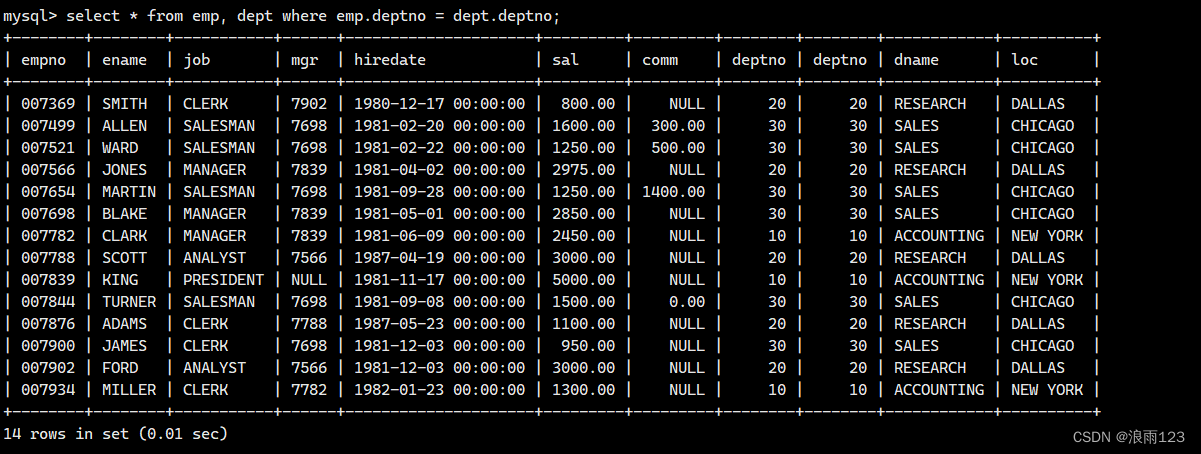
select * from emp, dept where emp.deptno = dept.deptno;
查询结果如下
自连接
进行复合查询的时候,如果一张表自己和自己连接,那么这样的连接过程称为自连接,因为自连接的表名都是一样的,因此要给参与连接的表取个新的不重复的名字,这样能够标明出不同的表,方便条件筛选
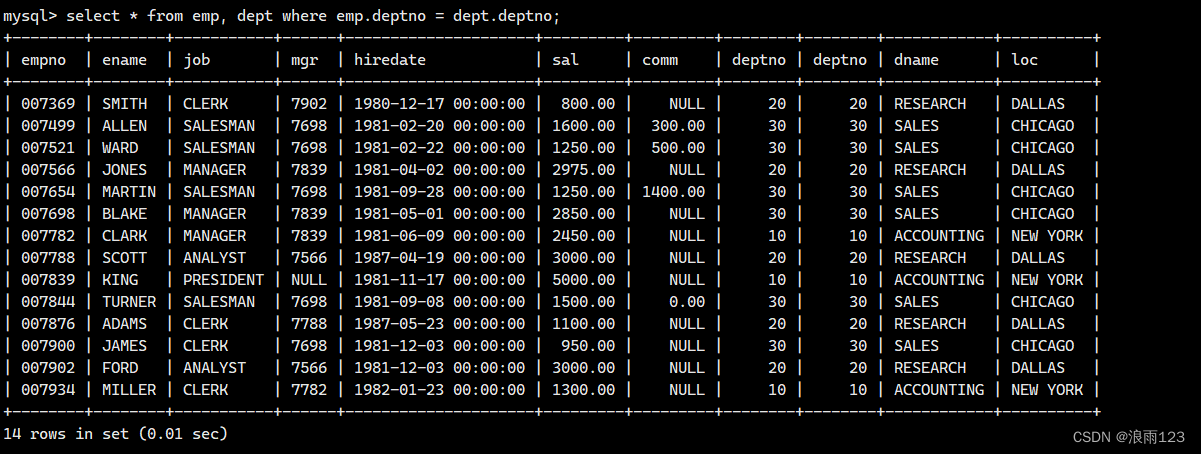
例如:将部门表与部门表进行自连接
select * from dept as A, dept as B where A.deptno = B.deptno;
什么情况下会用到自连接呢,举个例子,我们需要查找WARD这个人的上级领导,因为他的上级领导也是员工,也在员工表中,想要查找他的上级领导是哪个人,就要在mgr这一列得到WARD这个人的上级领导的员工号,从而找到这个领导
select leader.empno,leader.ename from emp leader, emp worker where leader.empno = worker.mgr and worker.ename='WARD';
内连接
内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,笔者前面所述的查询都是内连接,也是在开发过程中使用的最多的连接查询
前面我们在进行内连接的时候,直接在from子句中写出要连接的表,当然内连接还有一种比较标准的写法,接下来看看这个比较标准的写法select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
-- 用前面的写法
select ename, dname from emp, dept where emp.deptno=dept.deptno and
ename='SMITH';
-- 用标准的内连接写法
select ename, dname from emp inner join dept on emp.deptno=dept.deptno and
ename='SMITH';
外连接
左外连接:如果联合查询,左侧的表完全显示我们就说是左外连接
语法形式:select 字段 from 表名1 right join 表名2 on 连接条件;
右外连接:如果联合查询,右侧的表完全显示我们就说是右外连接
语法形式:select 字段 from 表名1 right join 表名2 on 连接条件;
接下来建立两张表来演示这个过程create table stu (id int, name varchar(30)); -- 学生表
insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
create table exam (id int, grade int); -- 成绩表
insert into exam values(1, 56),(2,76),(11, 8);要求:查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
按照连接的标准写法,也就是用join 和 on这种形式,如果两个表中在on的条件下没有匹配项,那么就不会显示出来,这和题目要求的学生没有成绩,也要将学生的信息显示出来相违背,因此需要使用左外连接,使用左外连接后,在左边的表中的信息即使没有与右表相匹配的项,也能够显示出来,这就保证了左表数据的完整性
我们用内连接和左外连接的形式分别求一下,对比结果是否如此
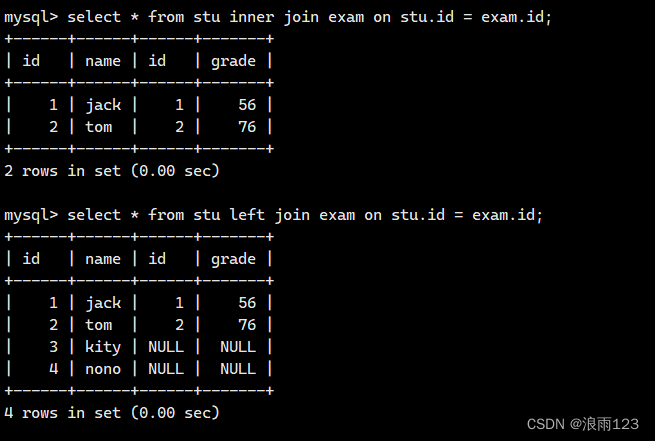
因为右外连接就是与左外连接相反,这里就不再演示了,用法都是类似的
子查询
有些需要查询的内容,仅用一个查询语句是无法完成任务的,需要多层嵌套查询才能完成任务,像这样嵌入在其他sql语句中的select语句,就称为子查询,也叫嵌套查询
单行子查询
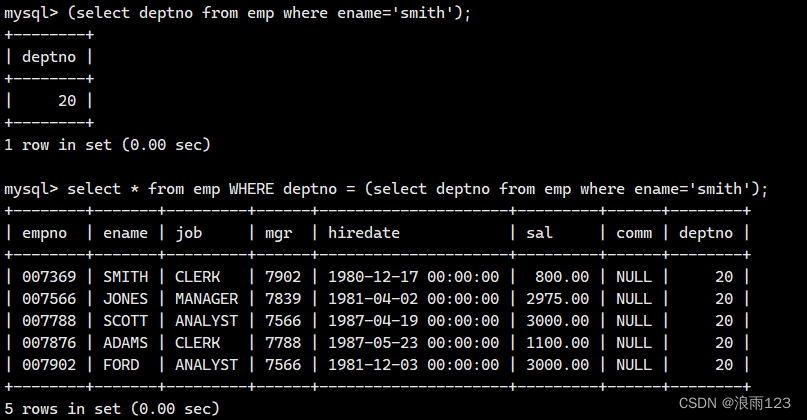
子查询的结果只返回一行的,我们称之为单行子查询,怎么理解呢?我们举个例子,查找和WARD处于同一个部门的所有员工的信息,查询语句如下
select * from emp where deptno = (select deptno from emp where ename='WARD');
在这个查询语句中,括号里的这个子查询,指明了查询WARD,所以查询结果只有一行,也就是提供给主查询语句的数据只有一行
多行子查询
子查询的结果返回多行的,我们称之为多行子查询,大家想想看,既然子查询提供给主查询的结果有多条,那么是满足其中的一个,还是都要满足呢?不同的情况我们要用不同的关键词来表示
in:只要满足in里的任意一个条件结果即为真
all:满足all中的所有条件,结果才为真
any:满足any条件里的任意一个,结果即为真
in关键字;查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
select ename,job,sal,deptno from emp where job in (select distinct job from
emp where deptno=10) and deptno<>10;all关键字;显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
select ename, sal, deptno from EMP where sal > all(select sal from EMP where
deptno=30);any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
select ename, sal, deptno from EMP where sal > any(select sal from EMP where
deptno=30);any是用于子查询,in是用于表达式列表,in也可以用于子查询,因为多行子查询的返回结果有多个,就组成一个表达式列表
多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句
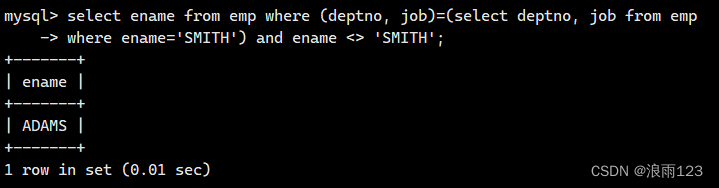
例如:查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
select ename from emp where (deptno, job)=(select deptno, job from emp
where ename='SMITH') and ename <> 'SMITH';
在from子句中使用子查询
我们都知道from表示查询的属于来源于哪些表,如果在from中使用子查询,意味着把子查询的结果作为一张表,给主查询提供数据来源
例如:显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
select ename, deptno, sal, format(asal,2) from emp, (select avg(sal) as asal, deptno as dt from emp group by deptno) as tmp where emp.sal > tmp.asal and emp.deptno=tmp.dt;

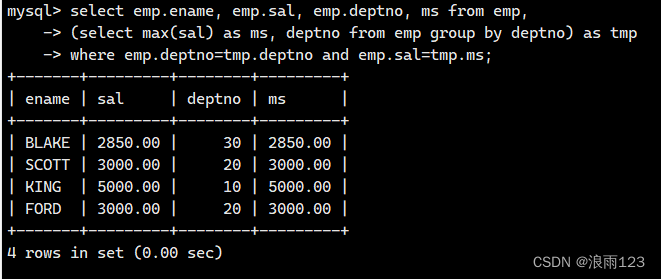
要求:查找每个部门工资最高的人的姓名、工资、部门、最高工资,代码如下
select emp.ename, emp.sal, emp.deptno, ms from emp, (select max(sal) as ms, deptno from emp group by deptno) as tmp where emp.deptno=tmp.deptno and emp.sal=tmp.ms;
合并查询
联合查询就比较容易理解了,联合查询就是通过union, union all 关键词将多个select的执行结果合并
union:该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
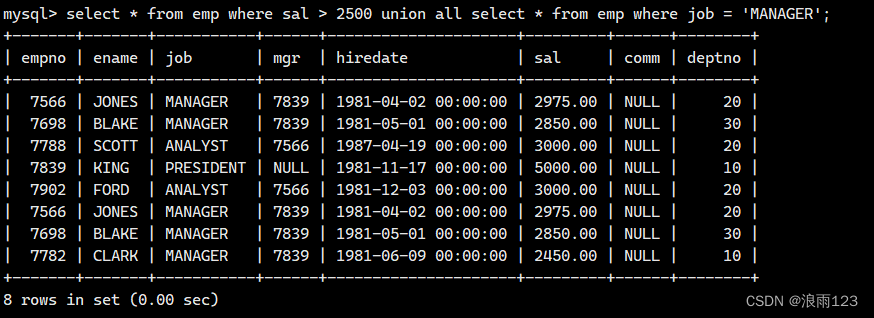
例如:将工资大于2500或职位是MANAGER的人找出来emp
select * from emp where sal > 2500 union select * from emp where job = 'MANAGER';

union all: 该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
这个简单来说就是不去重,使用和上述同样的例子,大家感受一下