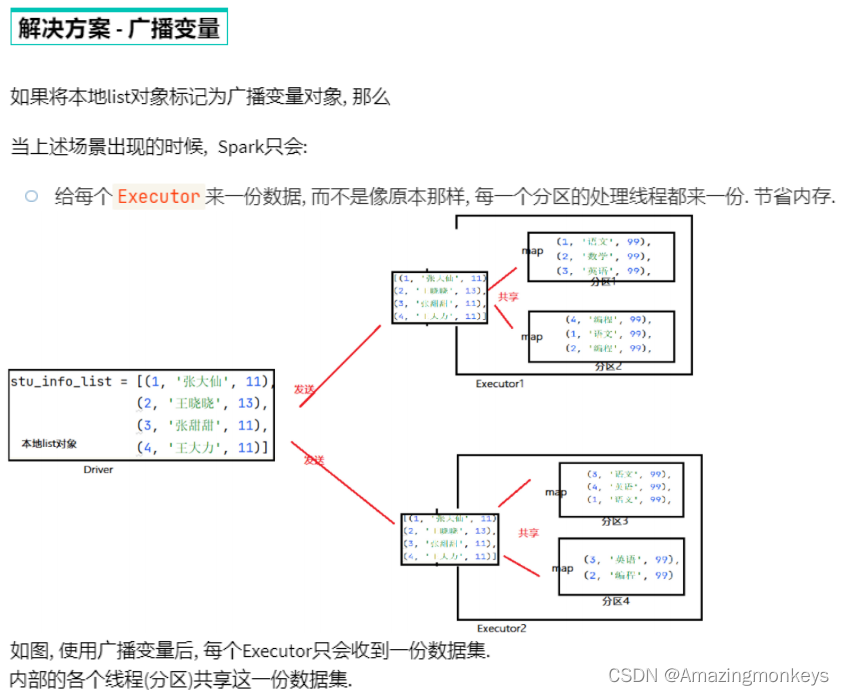
广播变量



# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
stu_info_list = [(1, '张大仙', 11),
(2, '王晓晓', 13),
(3, '张甜甜', 11),
(4, '王大力', 11)]
# 1. 将本地Python List对象标记为广播变量
broadcast = sc.broadcast(stu_info_list)
score_info_rdd = sc.parallelize([
(1, '语文', 99),
(2, '数学', 99),
(3, '英语', 99),
(4, '编程', 99),
(1, '语文', 99),
(2, '编程', 99),
(3, '语文', 99),
(4, '英语', 99),
(1, '语文', 99),
(3, '英语', 99),
(2, '编程', 99)
])
def map_func(data):
id = data[0]
name = ""
# 匹配本地list和分布式rdd中的学生ID 匹配成功后 即可获得当前学生的姓名
# 2. 在使用到本地集合对象的地方, 从广播变量中取出来用即可
for stu_info in broadcast.value:
stu_id = stu_info[0]
if id == stu_id:
name = stu_info[1]
return (name, data[1], data[2])
print(score_info_rdd.map(map_func).collect())
"""
场景: 本地集合对象 和 分布式集合对象(RDD) 进行关联的时候
需要将本地集合对象 封装为广播变量
可以节省:
1. 网络IO的次数
2. Executor的内存占用
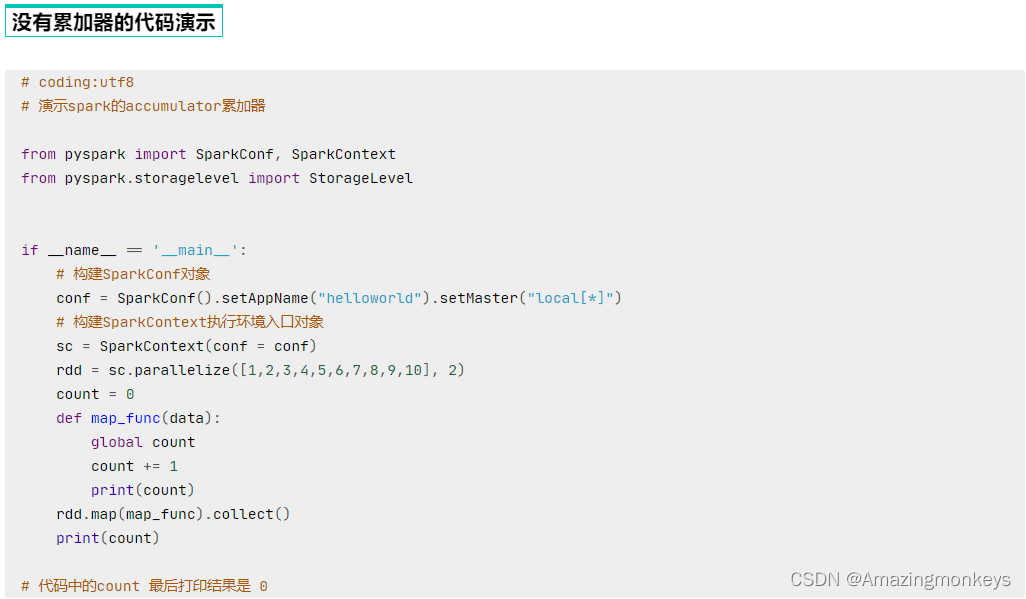
"""累加器


![]()
# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
# Spark提供的累加器变量, 参数是初始值
acmlt = sc.accumulator(0)
def map_func(data):
global acmlt
acmlt += 1
# print(acmlt)
rdd2 = rdd.map(map_func)
rdd2.cache()
rdd2.collect()
rdd3 = rdd2.map(lambda x:x)
rdd3.collect()
print(acmlt)


综合案例
# coding:utf8
import time
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
import re
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
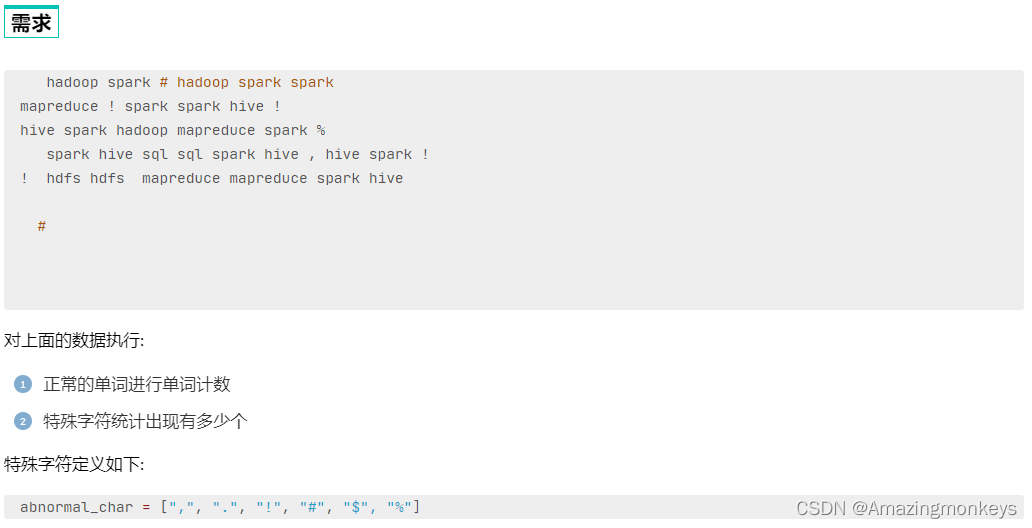
# 1. 读取数据文件
file_rdd = sc.textFile("../data/input/accumulator_broadcast_data.txt")
# 特殊字符的list定义
abnormal_char = [",", ".", "!", "#", "$", "%"]
# 2. 将特殊字符list 包装成广播变量
broadcast = sc.broadcast(abnormal_char)
# 3. 对特殊字符出现次数做累加, 累加使用累加器最好
acmlt = sc.accumulator(0)
# 4. 数据处理, 先处理数据的空行, 在Python中有内容就是True None就是False
lines_rdd = file_rdd.filter(lambda line: line.strip())
# 5. 去除前后的空格
data_rdd = lines_rdd.map(lambda line: line.strip())
# 6. 对数据进行切分, 按照正则表达式切分, 因为空格分隔符某些单词之间是两个或多个空格
# 正则表达式 \s+ 表示 不确定多少个空格, 最少一个空格
words_rdd = data_rdd.flatMap(lambda line: re.split("\s+", line))
# 7. 当前words_rdd中有正常单词 也有特殊符号.
# 现在需要过滤数据, 保留正常单词用于做单词计数, 在过滤 的过程中 对特殊符号做计数
def filter_func(data):
"""过滤数据, 保留正常单词用于做单词计数, 在过滤 的过程中 对特殊符号做计数"""
global acmlt
# 取出广播变量中存储的特殊符号list
abnormal_chars = broadcast.value
if data in abnormal_chars:
# 表示这个是 特殊字符
acmlt += 1
return False
else:
return True
normal_words_rdd = words_rdd.filter(filter_func)
# 8. 正常单词的单词计数逻辑
result_rdd = normal_words_rdd.map(lambda x: (x, 1)).\
reduceByKey(lambda a, b: a + b)
print("正常单词计数结果: ", result_rdd.collect())
print("特殊字符数量: ", acmlt)
广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO传输,提高性能。
累加器解决了什么问题?
分布式代码执行中,进行全局累加。