1.创建表格插入数据
DROP TABLE IF EXISTS 学生;
create table 学生
(
student_id INT PRIMARY KEY,
gender TEXT,
city TEXT,
a_score FLOAT(2),
b_score FLOAT(2),
weight FLOAT(2)
)engine=innodb;
INSERT INTO 学生 VALUES
(001,'female','xiameng',90.6,110.87,50.34),
(002,'male','guangzhou',93.6,116.87,48.6),
(003,NULL,'guangzhou',90.64,107.06,60.34),
(004,'female','guangzhou',80.6,103.87,45.0),
(005,NULL,'xiameng',NULL,98.8,50.34),
(006,'female','guangzhou',90.6,113.87,50.34),
(007,'female','xiameng',NULL,110.02,50.34),
(008,'male','wuhan',90.6,90.87,50.34),
(010,'male','guangzhou',90.6,98.87,48.6),
(011,'female','xiameng',90.6,96.87,48.6),
(012,'male','xiameng',90.6,87.17,50.34),
(013,NULL,'xiameng',90.6,80.87,48.6),
(014,'female','guangzhou',90.6,103.87,50.34),
(015,NULL,'xiameng',90.6,98.87,50.34),
(016,'female','wuhan',NULL,110.87,50.34),
(017,'female','guangzhou',90.6,98.87,50.34),
(018,'female','xiameng',90.6,96.87,50.34),
(019,'female','guangzhou',90.6,110.95,48.6),
(020,'female','wuhan',90.6,110.87,50.34),
(021,NULL,'guangzhou',NULL,110.87,50.34),
(022,'female','guangzhou',90.6,110.87,50.34),
(023,NULL,'wuhan',90.6,110.87,50.34),
(024,'female','guangzhou',90.6,110.87,50.34),
(025,'female','guangzhou',90.6,110.87,48.6),
(026,'male','guangzhou',NULL,110.87,50.34),
(027,'female','wuhan',90.6,110.87,50.34),
(028,'female','guangzhou',90.6,110.87,48.6),
(029,'female','xiameng',90.6,110.87,48.6),
(030,'male','guangzhou',90.6,110.87,45.0),
(031,'female','xiameng',NULL,110.87,50.34),
(032,'female','guangzhou',90.6,110.87,50.34),
(033,NULL,'guangzhou',NULL,96.5,50.34),
(034,'female','wuhan',90.6,96.5,45.0),
(035,'male','guangzhou',90.6,110.87,50.34),
(036,'female','wuhan',90.6,96.5,50.34),
(037,'female','guangzhou',90.6,110.87,50.34),
(038,'male','wuhan',90.6,110.87,50.34),
(039,'female','guangzhou',90.6,110.87,50.34),
(040,'male','xiameng',NULL,110.87,50.34),
(041,'female','wuhan',90.6,107.06,50.34),
(042,NULL,'guangzhou',NULL,110.87,50.34),
(043,'female','guangzhou',90.6,110.87,45.0),
(044,'male','wuhan',90.6,110.87,50.34),
(045,'female','xiameng',90.6,110.87,50.34),
(046,'female','guangzhou',90.6,107.06,50.34),
(047,'male','guangzhou',90.6,110.87,50.34),
(048,'female','guangzhou',90.6,96.5,45.0),
(049,NULL,'wuhan',NULL,107.06,50.34),
(050,NULL,'wuhan',90.6,110.87,50.34),
(051,NULL,'wuhan',NULL,110.87,50.34),
(052,NULL,'guangzhou',90.6,96.5,50.34),
(053,'female','guangzhou',90.6,110.87,50.34),
(054,NULL,'wuhan',90.6,110.87,48.6),
(055,'female','xiameng',90.6,110.87,50.34),
(056,NULL,'xiameng',90.6,107.06,45.0),
(057,'male','guangzhou',90.6,96.5,50.34),
(058,NULL,'guangzhou',90.6,110.87,50.34),
(059,NULL,'wuhan',NULL,110.87,48.6),
(060,'female','wuhan',NULL,110.87,48.6);2. 常见聚合函数
| 函数 | 解释 |
| COUNT(columnX) | 计算columnX中包含非空值的行数 |
| COUNT(*) | 计算输出表中的行数 |
| MIN(columnX) | 返回columnX中的最小值。对于文本类,返回按字母顺序排序出现在最前面的值 |
| MAX(columnX) | 返回columnX中的最大值 |
| SUM(columnX) | 返回columnX中所有值的总和 |
| AVG(columnX) | 返回columnX中所有值的平均值 |
| STDDEV(columnX) | 返回columnX中所有值的样本标准差 |
| VAR(columnX) | 返回columnX中所有值的样本方差 |
| REGR_SLOPE(columnX,columnY) | 返回columnX作为因变量、columnY作为自变量时线性回归的斜率。 |
| REGR_INTERCEPT(columnX,columnY) | 返回columnX作为因变量、columnY作为自变量时线性回归的截距。 |
| CORR(columnX,columnY) | 返回数据中columnX和columnY之间的皮尔逊相关系数 |
SELECT COUNT(DISTINCT city) FROM 学生;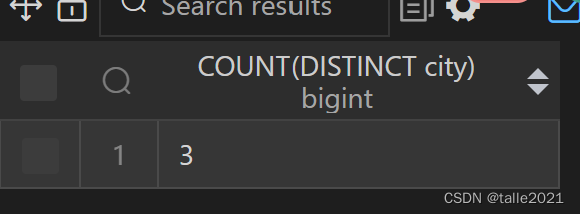
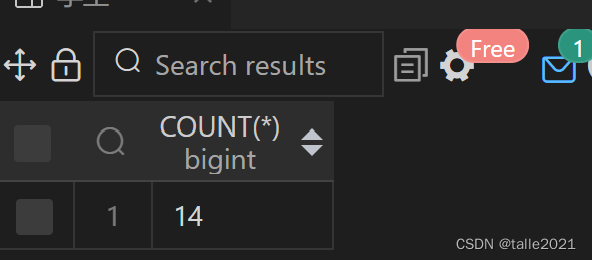
SELECT COUNT(*) FROM 学生 WHERE city='xiameng';
SELECT COUNT(*)/2 FROM 学生 WHERE city='xiameng'; 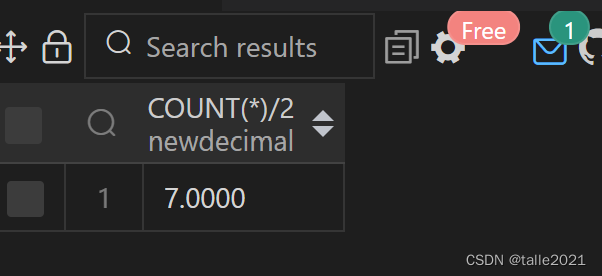
SELECT MIN(b_score),MAX(b_score),AVG(b_score),STDDEV(b_score) FROM 学生;
3. GROUP BY聚合函数
3.1 GROUP BY子句
GROUP BY是一个子句,它可以根据GROUP BY子句中指定的某种键将数据集的行分成多个组,然后将聚合函数应用于单个组中的所有以生成单个数字。
使用GROUP BY查询每个城市有多少个学生
SELECT city,COUNT(*) FROM 学生 GROUP BY city ORDER BY city;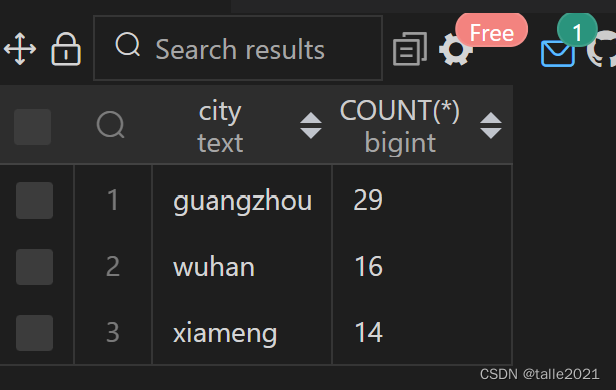
SELECT city,COUNT(*) FROM 学生 WHERE gender='female' GROUP BY city ORDER BY COUNT(*)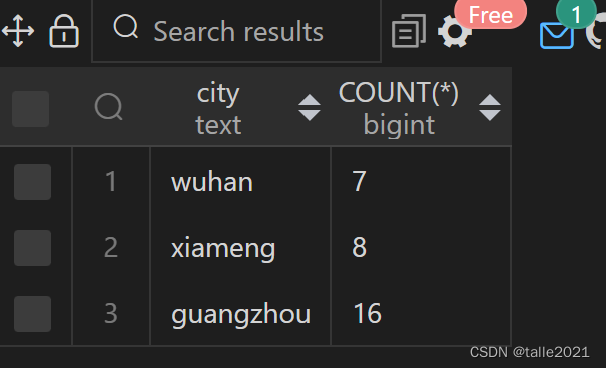
3.2 多列GROUP BY
使用GROUP BY查询每个城市有多少个男、女学生
SELECT city,gender,count(*) FROM 学生 GROUP BY city,gender ORDER BY city,gender;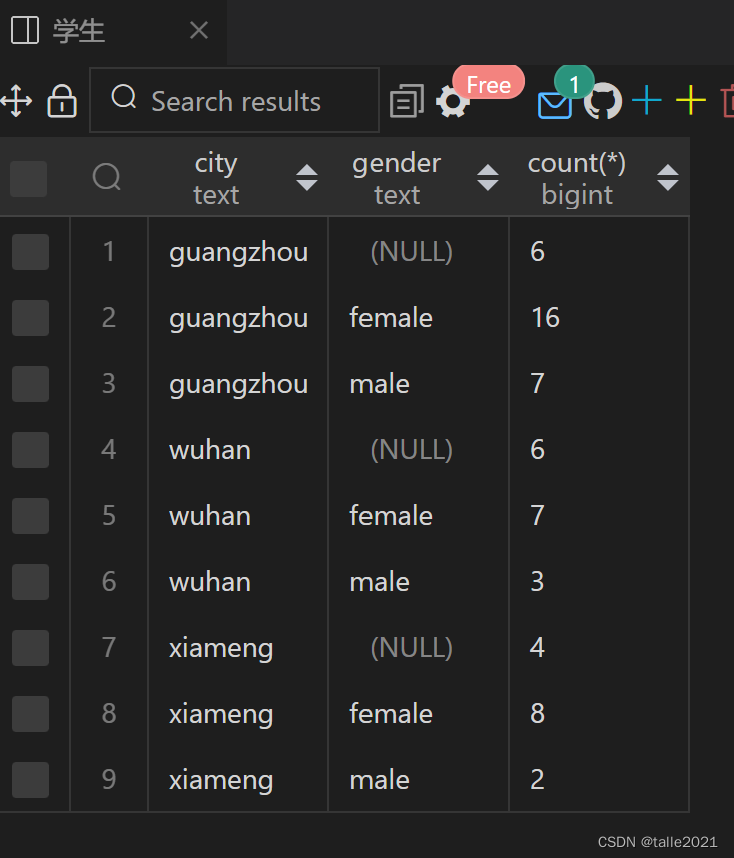
3.3 HAVING子句
HAVING子句类似于WHERE子句,只不过它专门为GROUP BY查询设计的。
SELECT city,gender,count(*) FROM 学生 GROUP BY city,gender HAVING gender IS NOT NULL ORDER BY city,gender;
3.4 使用GROUP BY函数查找缺失值
要确定列是否有缺失值,可以使用SUM和COUNT函数修改后的CASE WHEN语句来确定缺失数据的百分比。
根据查询结果,如果数据的缺失比例非常小(<1%),则可以考虑从分析中过滤或删除缺失的数据。如果有一定比例的数据缺失(<20%),则可以考虑使用典型值(均值、众数等)填充缺失的数据。如果数据缺失的比例超过20%,则可以考虑删除该列,因为没有足够的准确数据来根据该列中的值得出准确的结论。
查询a_score列的缺失值比例:
SELECT SUM(CASE
WHEN a_score is NULL
THEN 1
ELSE 0
END)/COUNT(*) AS missing_score FROM 学生;
3.5 使用GROUP BY函数衡量数据质量
如果想确定列中的每个值是否都是唯一的。虽然在大多数情况下,可以通过设置primary key约束的列来解决,但这并不总是可行。
如验证学生表中的student_id列包含的值是否唯一:
SELECT COUNT(DISTINCT student_id)=COUNT(*) AS equal_id FROM 学生;
SELECT COUNT(DISTINCT city)=COUNT(*) AS equal_city FROM 学生; 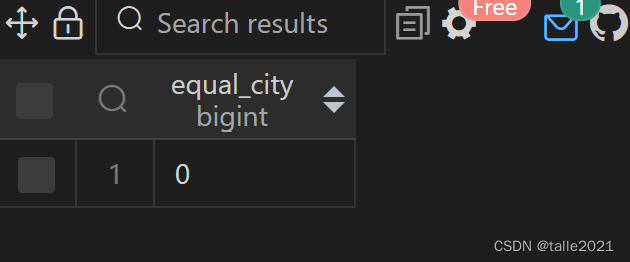

如果查询结果返回1,则该列的每一行都有唯一值;否则,至少有一个重复的值。