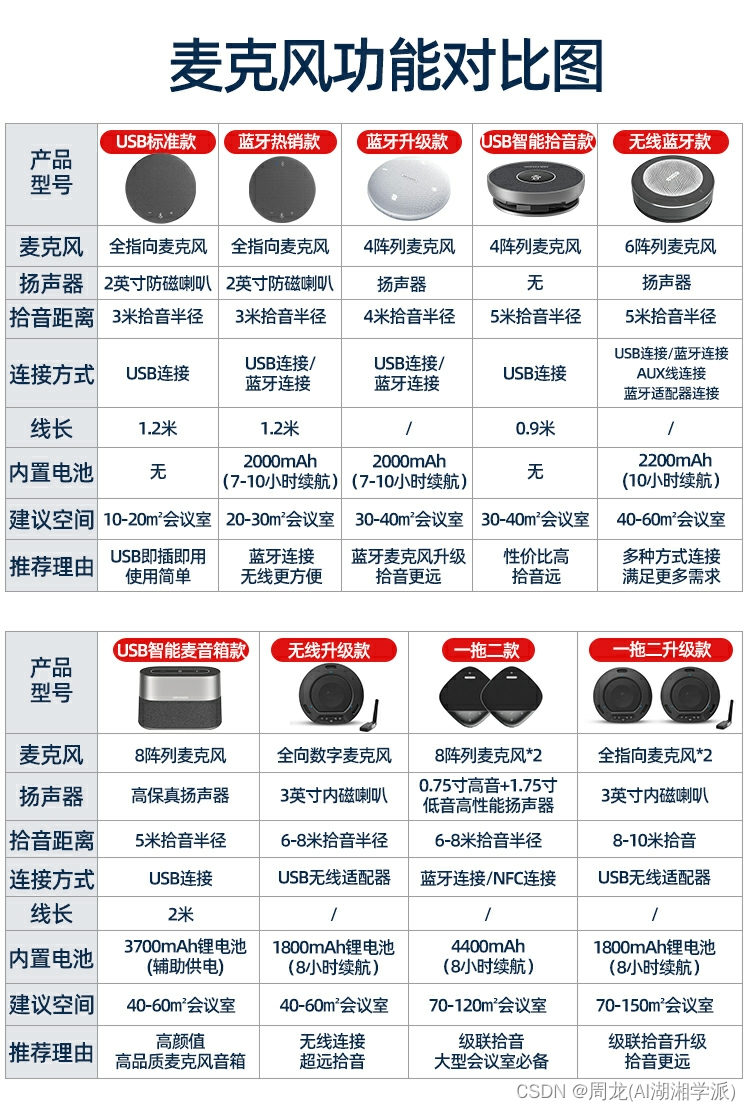
废话不多说,上题:

1.Hadoop中两个⼤表实现join的操作,简单描述。
(1)Hive中可以通过分区来减少数据量;(2)还可以通过优化HQL语句,⽐如只查询需要的字段,尽量避免全表、全字段查询;
2.Hive中存放是什么?
表。存的是和hdfs的映射关系,hive是逻辑上的数据仓库,实际操作的都是hdfs上的⽂ 件,HQL就是⽤sql语法来写的mr程序。
3.Hive与关系型数据库的关系?
没有关系,hive是数据仓库,不能和数据库⼀样进⾏实时的CURD操作。是⼀次写⼊多次读取的操作,可以看成是ETL⼯具。
4.Hive中的排序关键字有哪些?
sort by ,order by ,cluster by ,distribute by (1)sort by :不是全局排序,其在数据进⼊reducer前完成排序
(2)order by :会对输⼊做全局排序,因此只有⼀个reducer(多个reducer⽆法保证全局有序).只有⼀个reducer,会导致当输⼊规模较⼤时,需要较⻓的计算时间。
(3)cluster by :当distribute by 和sort by的字