目录
1. 基本原理
2. Spark集群搭建
2.1 Spark Standalone 集群搭建
2.2 Spark On Yarn 配置
3. Doris配置Spark与Yarn
3.1 Doris配置Spark
3.2 Doris配置Yarn
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
宝子们订阅、点赞、收藏不迷路!抓紧订阅专题!
Spark load 通过外部的 Spark 资源实现对导入数据的预处理,提高 Doris 大数据量的导入性能并且节省 Doris 集群的计算资源。Spark Load 最适合的场景就是原始数据在文件系统(HDFS)中,数据量在 几十 GB 到 TB 级别,主要用于初次迁移,大数据量导入 Doris 的场景。
Spark load 是利用了 spark 集群的资源对要导入的数据的进行了排序,Doris be 直接写文件,这样能大大降低 Doris 集群的资源使用,对于历史海量数据迁移降低 Doris 集群资源使用及负载有很好的效果。
小数据量还是建议使用 Stream Load 或者 Broker Load。如果大数据量导入Doris,用户在没有 Spark 集群这种资源的情况下,又想方便、快速的完成外部存储历史数据的迁移,可以使用 Broker load ,因为 Doris 表里的数据是有序的,所以 Broker load 在导入数据的时是要利用doris 集群资源对数据进行排序,对 Doris 的集群资源占用要比较大。如果有 Spark 计算资源建议使用 Spark load。
1. 基本原理
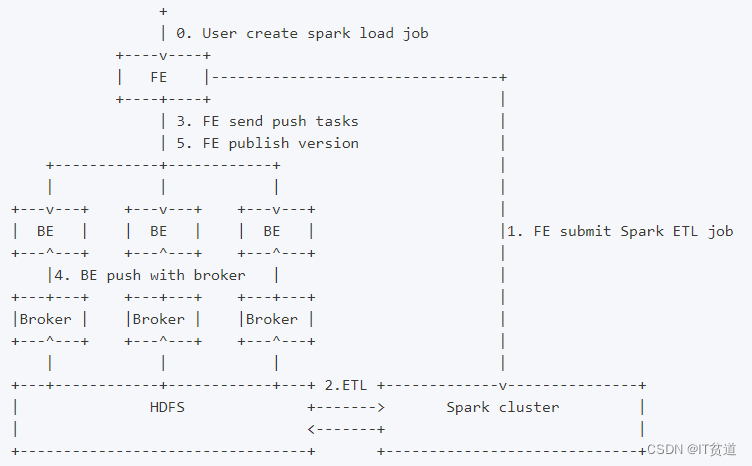
Spark load 是一种异步导入方式,用户需要通过 MySQL 协议创建 Spark 类型导入任务,并通过 SHOW LOAD 查看导入结果。当用户通过 MySQL 客户端提交 Spark 类型导入任务,FE记录元数据并返回用户提交成功,Spark load 任务的执行主要分为以下5个阶段:
- FE 调度提交 ETL 任务到 Spark 集群执行。
- Spark 集群执行 ETL 完成对导入数据的预处理。包括全局字典构建( BITMAP 类型)、分区、排序、聚合等。
- ETL 任务完成后,FE 获取预处理过的每个分片的数据路径,并调度相关的 BE 执行 Push 任务。
- BE 通过 Broker 读取数据,转化为 Doris 底层存储格式。
- FE 调度生效版本,完成导入任务。
2. Spark集群搭建
Doris 中Spark Load 需要借助Spark进行数据ETL,Spark任务可以基于Standalone提交运行也可以基于Yarn提交运行,两种不同资源调度框架配置不同,下面分别进行搭建配置。Spark版本建议使用 2.4.5 或以上的 Spark2 官方版本。经过测试不能使用Spark3.x以上版本,与目前doris版本不兼容。
2.1 Spark Standalone 集群搭建
这里我们选择Spark2.3.1版本进行搭建Spark Standalone集群,Standalone集群中有Master和Worker,Standalone集群搭建节点划分如下:
| 节点IP | 节点名称 | Master | Worker | 客户端 |
| 192.168.179.4 | node1 | ★ | ★ | |
| 192.168.179.5 | node2 | ★ | ★ | |
| 192.168.179.6 | node3 | ★ | ★ |
以上node2,node3计算节点,建议给内存多一些,否则在后续执行Spark Load任务时executor内存可能不足。详细的搭建步骤如下:
1) 下载Spark安装包
这里在Spark官网中现在Spark安装包,安装包下载地址:https://archive.apache.org/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
2) 上传、解压、修改名称
这里将下载好的安装包上传至node1节点的“/software”路径,进行解压,修改名称:
#解压
[root@node1 ~]# tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /software/
#修改名称
[root@node1 software]# mv spark-2.3.1-bin-hadoop2.7 spark-2.3.13) 配置conf文件
#进入conf路径
[root@node1 ~]# cd /software/spark-2.3.1/conf/
#改名
[root@node1 conf]# cp spark-env.sh.template spark-env.sh
[root@node1 conf]# cp workers.template workers
#配置spark-env.sh,在改文件中写入如下配置内容
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=3
export SPARK_WORKER_MEMORY=3g
#配置workers,在workers文件中写入worker节点信息
node2
node3将以上配置好Spark解压包发送到node2、node3节点上:
[root@node1 ~]# cd /software/
[root@node1 software]# scp -r ./spark-2.3.1 node2:/software/
[root@node1 software]# scp -r ./spark-2.3.1 node3:/software/4) 启动集群
在node1节点上进入“$SPARK_HOME/sbin”目录中执行如下命令启动集群:
#启动集群
[root@node1 ~]# cd /software/spark-2.3.1/sbin/
[root@node1 sbin]# ./start-all.sh5) 访问webui
Spark集群启动完成之后,可以在浏览器中输入“http://node1:8080”来查看Spark WebUI:
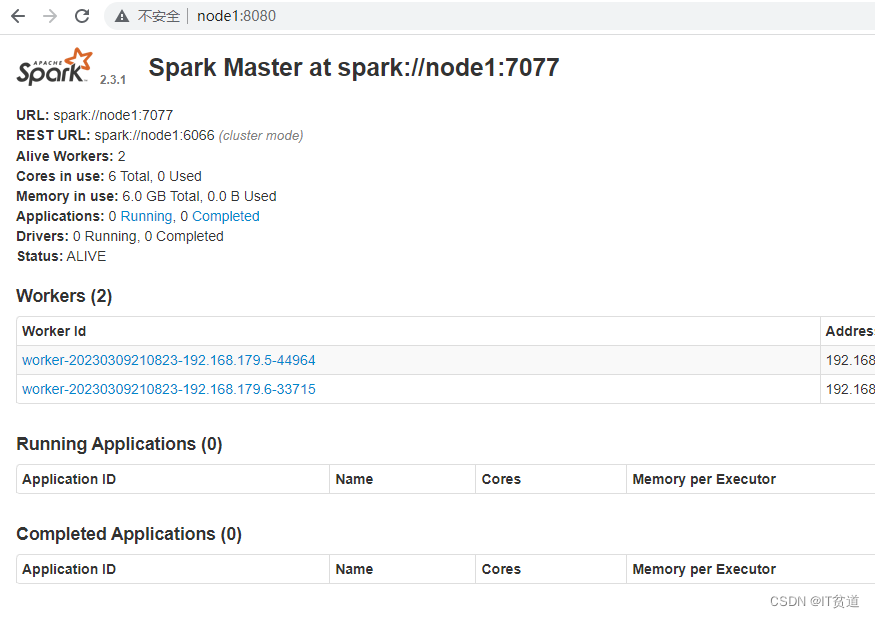
在浏览器中输入地址出现以上页面,并且对应的worker状态为Alive,说明Spark Standalone集群搭建成功。
6) Spark Pi任务提交测试
这里在客户端提交Spark PI任务来进行任务测试,node1-node3任意一台节点都可以当做是客户端,这里选择node3节点为客户端进行Spark任务提交,操作如下:
#提交Spark Pi任务
[root@node3 ~]# cd /software/spark-2.3.1/bin/
[root@node3 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar
...
Pi is roughly 3.1410557052785264
...2.2 Spark On Yarn 配置
Spark On Yarn 配置只需要在提交Spark任务的客户端$SPARK_HOME/conf/spark-env.sh中配置“export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop”,然后再启动Yarn,基于各个客户端提交Spark即可。
1) 配置spark-env.sh文件
在node1-node3 各个节点都配置$SPARK_HOME/conf/spark-env.sh:
...
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
...2) 启动HDFS及Yarn
Doris中8030端口为FE与FE之间、客户端与FE之间通信的端口,该端口与Yarn中ResourceManager调度端口冲突。Doris中8040端口为BE和BE之间的通信端口,该端口与Yarn中NodeManager调度端口冲突,所以启动HDFS Yarn之前需要修改HDFS集群中yarn-site.xml文件,配置ResourceManager和NodeManager调度端口,这里将默认的8030改为18030,8040改为18040。
#node1-node5 节点配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
...
<-- 配置 ResourceManager 对应的节点和端口 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>node1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>node2:18030</value>
</property>
<!-- 配置 NodeManager 对应的端口,DataNode同节点即为NodeManager -->
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:18040</value>
</property>
...以上配置完成后,重新执行start-all.sh命令启动HDFS及Yarn:
#启动zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#启动HDFS和Yarn
[root@node1 ~]# start-all.shnode1-node3任意一台节点提交任务测试:
[root@node1 ~]# cd /software/spark-2.3.1/bin/
[root@node1 bin]# ./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar
...
Pi is roughly 3.146835734178671
...3. Doris配置Spark与Yarn
3.1 Doris配置Spark
FE底层通过执行spark-submit的命令去提交 Spark 任务,因此需要为 FE 配置 Spark 客户端。
- 配置 SPARK_HOME 环境变量
将spark客户端放在FE(FE节点为node1-node3)同一台机器上的目录下,并在FE的配置文件配置 spark_home_default_dir 项指向此目录,此配置项默认为FE根目录下的lib/spark2x路径,此项不可为空。
#node1-node3 FE 节点上 ,配置 fe.conf
vim /software/doris-1.2.1/apache-doris-fe/conf/fe.conf
...
enable_spark_load = ture
spark_home_default_dir = /software/spark-2.3.1
...- 配置 SPARK 依赖包
将spark客户端下的jars文件夹内所有jar包归档打包成一个zip文件,并在FE的配置文件配置 spark_resource_path 项指向此 zip 文件,若此配置项为空,则FE会尝试寻找FE根目录下的 lib/spark2x/jars/spark-2x.zip 文件,若没有找到则会报文件不存在的错误。操作如下:
#node1-node3 各个节点安装 zip
yum -y install zip
#node1 - node3 各个节点上将$SPARK_HOME/jars/下所有jar包打成zip包
cd /software/spark-2.3.1/jars && zip spark-2x.zip ./*
#配置node1-node3节点fe.conf
vim /software/doris-1.2.1/apache-doris-fe/conf/fe.conf
...
spark_resource_path = /software/spark-2.3.1/jars/spark-2x.zip
...- 修改spark-dpp包名
当提交 spark load 任务时,除了以上spark-2x.zip依赖上传到指定的远端仓库,FE 还会上传 DPP 的依赖包至远端仓库,Spark进行数据预处理时需要依赖DPP此包,该包位于FE节点的/software/doris-1.2.1/apache-doris-fe/spark-dpp路径下,默认名称为spark-dpp-1.0-SNAPSHOT-jar-with-dependencies.jar,在提交Spark Load任务后,Doris默认在/software/doris-1.2.1/apache-doris-fe/spark-dpp路径下找名称为“spark-dpp-1.0.0-jar-with-dependencies.jar”的依赖包,所以这里需要在所有FE节点上进行改名,操作如下:
#在所有的FE节点中修改spark-dpp-1.0-SNAPSHOT-jar-with-dependencies.jar名称为spark-dpp-1.0.0-jar-with-dependencies.jar
cd /software/doris-1.2.1/apache-doris-fe/spark-dpp/
mv spark-dpp-1.0-SNAPSHOT-jar-with-dependencies.jar spark-dpp-1.0.0-jar-with-dependencies.jar3.2 Doris配置Yarn
Spark Load 底层的Spark任务可以基于Yarn运行,FE 底层通过执行 yarn 命令去获取正在运行的 application 的状态以及杀死 application,因此需要为 FE 配置 yarn 客户端,建议使用2.5.2 或以上的 hadoop2 官方版本。经测试使用hadoop3问题也不大。
将下载好的 yarn 客户端放在 FE 同一台机器的目录下,并在FE配置文件配置 yarn_client_path 项指向 yarn 的二进制可执行文件,默认为FE根目录下的 lib/yarn-client/hadoop/bin/yarn 路径。
#在node1-node3各个节点配置fe.conf
vim /software/doris-1.2.1/apache-doris-fe/conf/fe.conf
...
yarn_client_path = /software/hadoop-3.3.3/bin/yarn
...当 FE 通过 yarn 客户端去获取 application 的状态或者杀死 application 时,默认会在 FE 根目录下的 lib/yarn-config 路径下生成执行yarn命令所需的配置文件,此路径可通过在FE配置文件配置 yarn_config_dir 项修改,目前生成的配置文件包括 core-site.xml 和yarn-site.xml。
#在node1-node3各个节点配置fe.conf
vim /software/doris-1.2.1/apache-doris-fe/conf/fe.conf
...
yarn_config_dir = /software/hadoop-3.3.3/etc/hadoop
...此外还需要在Hadoop 各个节点中的/software/hadoop-3.3.3/libexec/hadoop-config.sh文件中配置JAVA_HOME,否则基于Yarn 运行Spark Load任务时报错。
#在node1~node5节点上配置
vim /software/hadoop-3.3.3/libexec/hadoop-config.sh
...
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
...