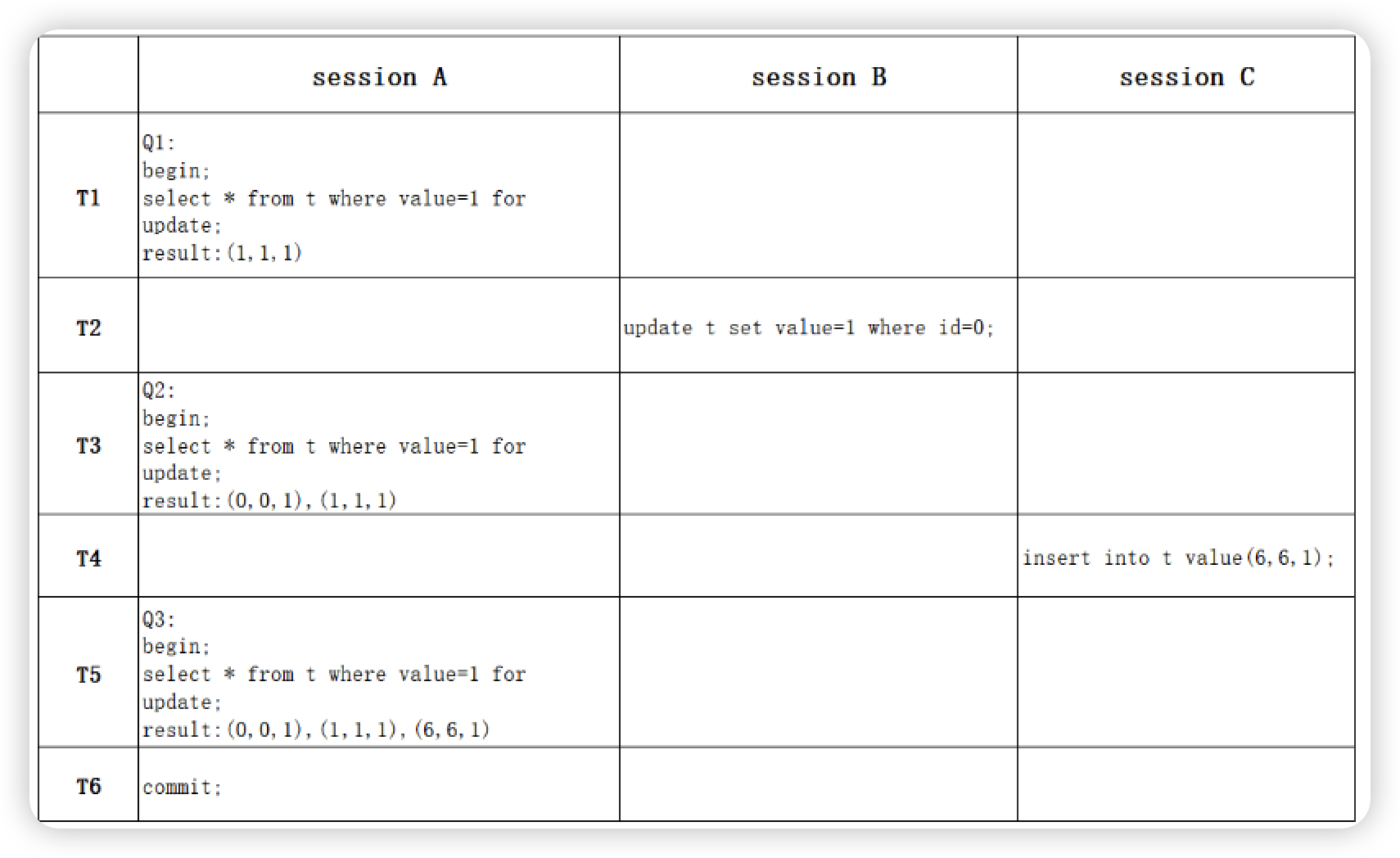
Uber的请求流程非常复杂,如上图所示,他们使用Spanner来存储大量数据。Spanner是一个全面托管的、关键的关系型数据库服务,可以在全球范围内提供事务一致性和高可用性的自动同步复制。
但是,当扩展到数百万并发请求时,使用Cassandra很难保证低延迟的写入。另一个问题是工程团队开始注意到复杂的存储交互,这些交互需要进行多行和多表的写入操作(具体意义不明)。但无论如何,本地Cassandra数据库变得非常具有挑战性。
对于Uber来说,数据不一致可能导致两个司机接同一个乘客。
解决方案是构建一个应用层框架,使用Saga模式来协调数据库操作。
Saga设计模式

Saga设计模式是一种用于在分布式事务场景下管理微服务间数据一致性的方式。Saga是一系列事务,每个事务更新每个服务并发布消息或事件以触发下一个事务步骤。如果某个步骤失败,Saga将执行一系列补偿事务来撤销之前事务所做的更改。
简单来说,如果在事务期间出现问题(事务是逻辑或工作的单个单元,有时由多个操作组成),则应撤销之前的更改。
事务是什么?
事务是一个逻辑或工作的单个单元,有时由多个操作组成。在事务内部,事件是对实体状态的更改,命令封装了执行操作或触发后续事件所需的所有信息。
事务必须具备原子性、一致性、隔离性和持久性(ACID)。单个服务内的事务是ACID的,但跨服务的数据一致性需要跨服务事务管理策略。
在多服务架构中:
•原子性:事务是不可分割的操作集合,要么全部执行,要么全部不执行。•一致性:事务将数据从一个有效状态转换为另一个有效状态。•隔离性:保证并发事务产生的数据状态与按顺序执行的事务产生的数据状态相同。•持久性:确保已提交的事务即使在系统故障或断电的情况下仍然保持提交状态。
解决方案
Saga模式通过一系列本地事务提供事务管理。本地事务是Saga中参与者执行的原子工作任务。每个本地事务都会更新数据库并发布消息或事件以触发Saga中的下一个本地事务。如果本地事务失败,Saga将执行一系列补偿事务来撤销之前的本地事务所做的更改。
有两种常见的Saga实现方法:协作和编排。每种方法都有一套用于协调工作流的挑战和技术。
协作是一种无需集中控制点的Saga协调方式。在协作中,每个本地事务都会发布领域事件,从而触发其他服务中的本地事务。

编排是一种通过集中式控制器协调Saga的方式。编排器告知Saga参与者要执行的本地事务。编排器处理所有事务,告知参与者根据事件执行哪些操作。编排器执行Saga请求,存储和解释每个任务的状态,并使用补偿事务进行故障恢复。