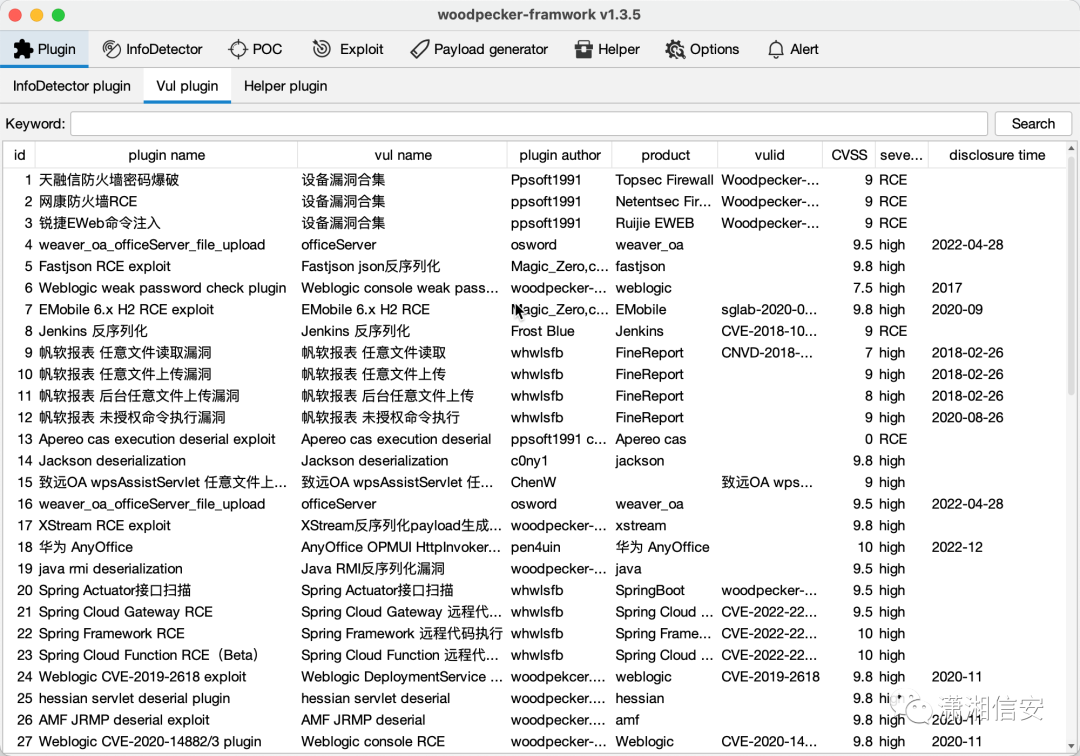
目录
准备工作
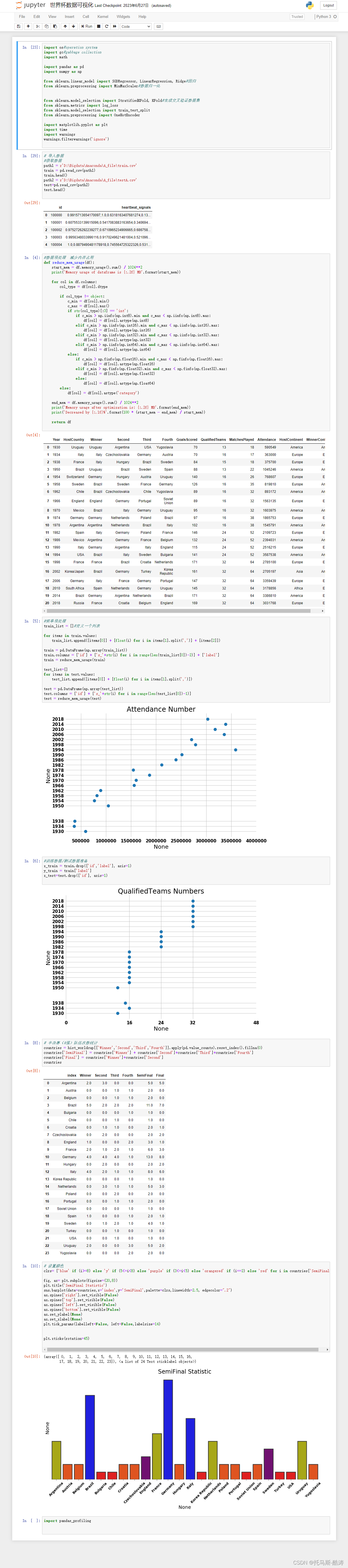
检索图书
本文将讨论如何使用 OpenAI 的 Embedding API 与 Zilliz Cloud 搭建相似性搜索系统。
在本篇中你将看到如何使用 OpenAI 的 Embedding API 和 Zilliz Cloud 完成图书检索。当前,很多的图书检索方案,包括公共图书馆里使用的那些方案,都是使用关键词匹配的方式获取检索结果,并没有真正理解书名的含义。本文搭建的相似性搜索系统实现了基于语义的搜索能力。该方案将使用一个预训练模型来获取输入数据的向量化表示并根据这个表示进行相似性搜索来获取与输入数据在语义层面相似的结果。该方案可用于一系列基于文字的使用场景,包括匿名检测及文档搜索。

准备工作
首先,我们需要从 Open AI 网站获取一个 API 密钥。另外,如果你还没有一个向量数据库,可前往 Zilliz Cloud 创建一个免费的 Serverless Cluster 来完成本文中的示例。
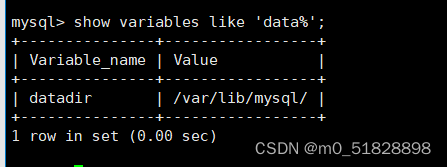
你可以单击此处下载我们将在示例代码中使用的数据集。数据集的格式为 CSV ,我们可以使用如下代码加载该数据集。