目录
赛制官方链接
活动背景
活动时间:即日起-12月31日17点
数据说明
世界杯成绩信息表:WorldCupsSummary
世界杯比赛比分汇总表:WorldCupMatches.csv
世界杯球员信息表:WorldCupPlayers.csv
代码实现

赛制官方链接
世界杯数据可视化分析_学习赛_天池大赛-阿里云天池
活动背景
2022世界杯在卡塔尔正如火如荼的进行,作为全球最受欢迎的体育运动,自然会吸引全世界无数球迷的目光,这也是历史上首次在冬季举办的世界杯。让我们一起来分析世界杯历史数据,看看能得出哪些有意思的结论吧。
本次数据分析项目包括3张来自FIFA官方数据整理的基础数据表,期待看到各位数据分析探索能手发挥想象力,开展各种分析。
活动时间:即日起-12月31日17点
数据说明
世界杯成绩信息表:WorldCupsSummary
包含了所有21届世界杯赛事(1930-2018)的比赛主办国、前四名队伍、总参赛队伍、总进球数、现场观众人数等汇总信息,包括如下字段:
- Year: 举办年份
- HostCountry: 举办国家
- Winner: 冠军队伍
- Second: 亚军队伍
- Third: 季军队伍
- Fourth: 第四名队伍
- GoalsScored: 总进球数
- QualifiedTeams: 总参赛队伍数
- MatchesPlayed: 总比赛场数
- Attendance: 现场观众总人数
- HostContinent: 举办国所在洲
- WinnerContinent: 冠军国家队所在洲
世界杯比赛比分汇总表:WorldCupMatches.csv
包含了所有21届世界杯赛事(1930-2014)单场比赛的信息,包括比赛时间、比赛主客队、比赛进球数、比赛裁判等信息。包括如下字段:
- Year: 比赛(所属世界杯)举办年份
- Datetime: 比赛具体日期
- Stage: 比赛所属阶段,包括 小组赛(GroupX)、16进8(Quarter-Final)、半决赛(Semi-Final)、决赛(Final)等
- Stadium: 比赛体育场
- City: 比赛举办城市
- Home Team Name: 主队名
- Away Team Name: 客队名
- Home Team Goals: 主队进球数
- Away Team Goals: 客队进球数
- Attendance: 现场观众数
- Half-time Home Goals: 上半场主队进球数
- Half-time Away Goals: 上半场客队进球数
- Referee: 主裁
- Assistant 1: 助理裁判1
- Assistant 2: 助理裁判2
- RoundID: 比赛所处阶段ID,和Stage字段对应
- MatchID: 比赛ID
- Home Team Initials: 主队名字缩写
- Away Team Initials: 客队名字缩写
世界杯球员信息表:WorldCupPlayers.csv
- RoundID: 比赛所处阶段ID,同比赛信息表的RoundID字段
- MatchID: 比赛ID
- Team Initials: 队伍名
- Coach Name: 教练名
- Line-up: 首发/替补
- Shirt Number: 球衣号码
- Player Name: 队员名
- Position: 比赛角色,包括:C=Captain, GK=Goalkeeper
- Event: 比赛事件,包括进球、红/黄牌等
数据的话可以在比赛官网获得,以下提供思路代码实现,使用Jupyter notbook工具
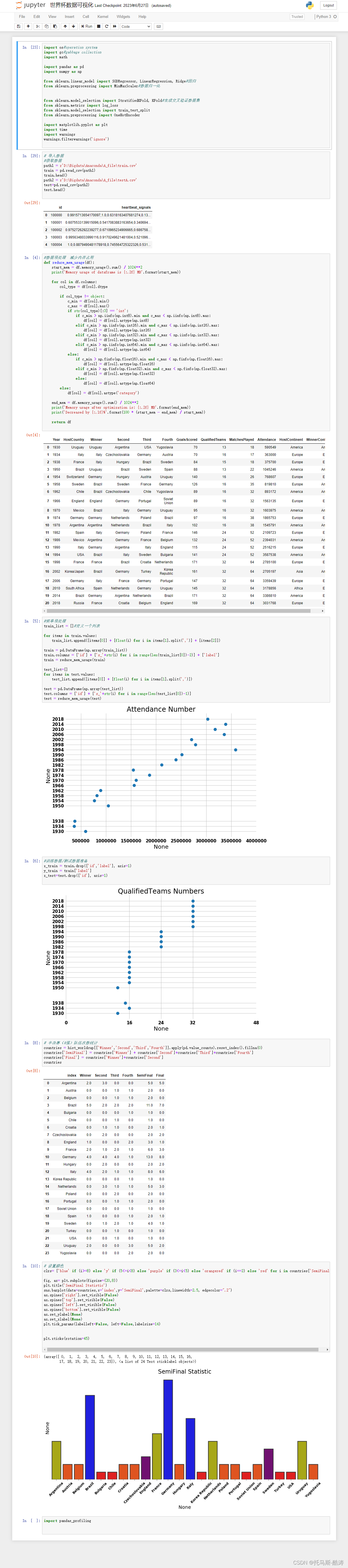
代码实现
import os#operation system
import gc#gabbage collection
import math
import pandas as pd
import numpy as np
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge#回归
from sklearn.preprocessing import MinMaxScaler#数据归一化
from sklearn.model_selection import StratifiedKFold, KFold#生成交叉验证数据集
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
# 导入数据
#获取数据
path1 = r'D:\Bigdata\Anaconda\A_file\train.csv'
train = pd.read_csv(path1)
train.head()
path2 = r'D:\Bigdata\Anaconda\A_file\testA.csv'
test=pd.read_csv(path2)
test.head()
#数据预处理 减少内存占用
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
#简单预处理
train_list = []#定义一个列表
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
train = pd.DataFrame(np.array(train_list))
train.columns = ['id'] + ['s_'+str(i) for i in range(len(train_list[0])-2)] + ['label']
train = reduce_mem_usage(train)
test_list=[]
for items in test.values:
test_list.append([items[0]] + [float(i) for i in items[1].split(',')])
test = pd.DataFrame(np.array(test_list))
test.columns = ['id'] + ['s_'+str(i) for i in range(len(test_list[0])-1)]
test = reduce_mem_usage(test)
#训练数据/测试数据准备
x_train = train.drop(['id','label'], axis=1)
y_train = train['label']
x_test=test.drop(['id'], axis=1)
# 半决赛(4强)队伍次数统计
countries = hist_worldcup[['Winner','Second','Third','Fourth']].apply(pd.value_counts).reset_index().fillna(0)
countries['SemiFinal'] = countries['Winner'] + countries['Second']+countries['Third']+countries['Fourth']
countries['Final'] = countries['Winner']+countries['Second']
countries
# 设置颜色
clrs= ['blue' if (i>=8) else 'y' if (5<=i<8) else 'purple' if (3<=i<5) else 'orangered' if (i==2) else 'red' for i in countries['SemiFinal']]
fig, ax= plt.subplots(figsize=(20,8))
plt.title('SemiFinal Statistic')
sns.barplot(data=countries,x='index',y='SemiFinal',palette=clrs,linewidth=2.5, edgecolor=".2")
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.set_ylabel(None)
ax.set_xlabel(None)
plt.tick_params(labelleft=False, left=False,labelsize=14)
plt.xticks(rotation=45)