Rapid Latex OCR
![]()
![]()

![]()
rapid_latex_ocr是一个将公式图像转为latex格式的工具。- 仓库中的推理代码来自修改自LaTeX-OCR,模型已经全部转为ONNX格式,并对推理代码做了精简,推理速度更快,更容易部署。
- 仓库只有基于
ONNXRuntime或者OpenVINO推理onnx格式的代码,不包含训练模型代码。如果想要训练自己的模型,请移步LaTeX-OCR。 - 如果有帮助到您的话,请给个小星星⭐或者赞助一杯咖啡(点击页面最上面的Sponsor中链接)
- 欢迎各位小伙伴积极贡献,让这个工具更好。
使用
-
安装
-
pip安装
rapid_latext_ocr库。因将模型打包到whl包中超出pypi限制(100M),因此需要单独下载模型。pip install rapid_latex_ocr -
下载模型(Google Drive | 百度网盘),初始化时,指定模型路径即可,详细参见下一部分。
模型名称 大小 image_resizer.onnx37.1M encoder.onnx84.8M decoder.onnx48.5M
-
-
使用
- 脚本使用:
from rapid_latex_ocr import LatexOCR image_resizer_path = 'models/image_resizer.onnx' encoder_path = 'models/encoder.onnx' decoder_path = 'models/decoder.onnx' tokenizer_json = 'models/tokenizer.json' model = LatexOCR(image_resizer_path=image_resizer_path, encoder_path=encoder_path, decoder_path=decoder_path, tokenizer_json=tokenizer_json) img_path = "tests/test_files/6.png" with open(img_path, "rb") as f: data = f.read() result, elapse = model(data) print(result) # {\frac{x^{2}}{a^{2}}}-{\frac{y^{2}}{b^{2}}}=1 print(elapse) # 0.4131628000000003 - 命令行使用
$ rapid_latex_ocr -h usage: rapid_latex_ocr [-h] [-img_resizer IMAGE_RESIZER_PATH] [-encdoer ENCODER_PATH] [-decoder DECODER_PATH] [-tokenizer TOKENIZER_JSON] img_path positional arguments: img_path Only img path of the formula. optional arguments: -h, --help show this help message and exit -img_resizer IMAGE_RESIZER_PATH, --image_resizer_path IMAGE_RESIZER_PATH -encdoer ENCODER_PATH, --encoder_path ENCODER_PATH -decoder DECODER_PATH, --decoder_path DECODER_PATH -tokenizer TOKENIZER_JSON, --tokenizer_json TOKENIZER_JSON $ rapid_latex_ocr tests/test_files/6.png \ -img_resizer models/image_resizer.onnx \ -encoder models/encoder.onnx \ -dedocer models/decoder.onnx \ -tokenizer models/tokenizer.json # ('{\\frac{x^{2}}{a^{2}}}-{\\frac{y^{2}}{b^{2}}}=1', 0.47902780000000034)
- 脚本使用:
-
输入输出说明
- 输入(
Union[str, Path, bytes]):只含有公式的图像。 - 输出(
Tuple[str, float]):(识别结果, 耗时), 具体参见下例:( '{\\frac{x^{2}}{a^{2}}}-{\\frac{y^{2}}{b^{2}}}=1', 0.47902780000000034 )
- 输入(





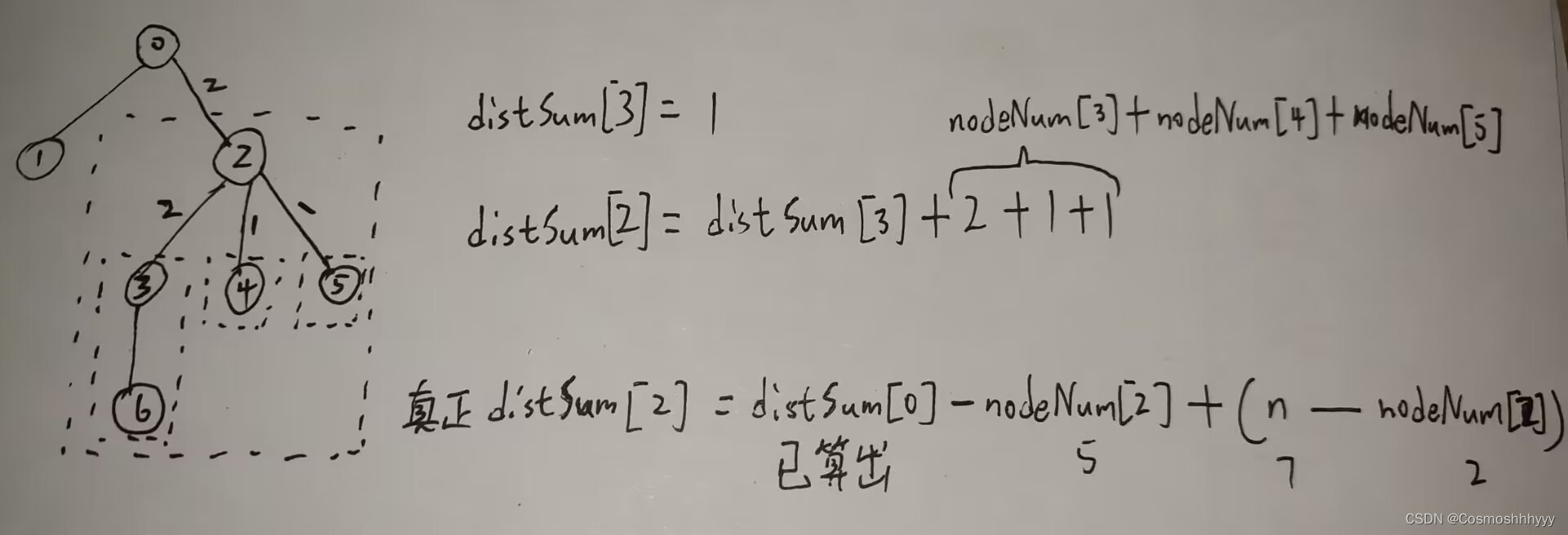



![[Linux] 网络编程 - 初见TCP套接字编程: 实现简单的单进程、多进程、多线程、线程池tcp服务器](https://img-blog.csdnimg.cn/img_convert/58937ec14d936d3059d3428a3f94a890.gif)