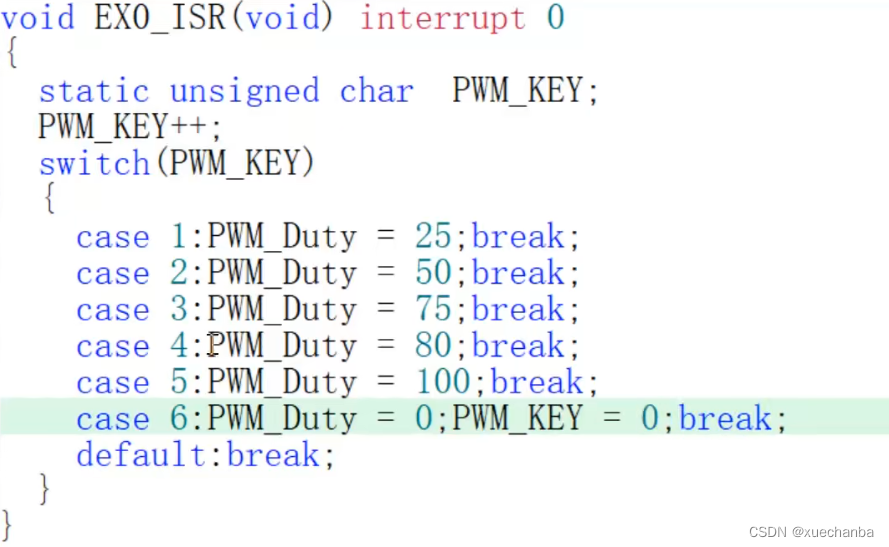
目录
1. Motivation
2. BYTE
3. ByteTrack
4.完整代码实现
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
沿着多目标跟踪(MOT)中tracking-by-detection的范式,我们提出了一种简单高效的数据关联方法BYTE。 利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的物体(遮挡、模糊等困难样本),从而降低漏检并提高轨迹的连贯性。BYTE能轻松应用到9种state-of-the-art的MOT方法中,并取得1-10个点不等的IDF1指标的提升。基于BYTE我们提出了一个跟踪方法ByteTrack,首次以30 FPS的运行速度在MOT17上取得80.3 MOTA,77.3 IDF1和63.1 HOTA,目前位居MOTChallenge榜单第一。我们还在开源代码中加入了将BYTE应用到不同MOT方法中的教程以及ByteTrack的部署代码。
Paper: http://arxiv.org/abs/2110.06864
Code: https://github.com/ifzhang/ByteTrack
Leaderboard: https://motchallenge.net/results/MOT17/?det=Private
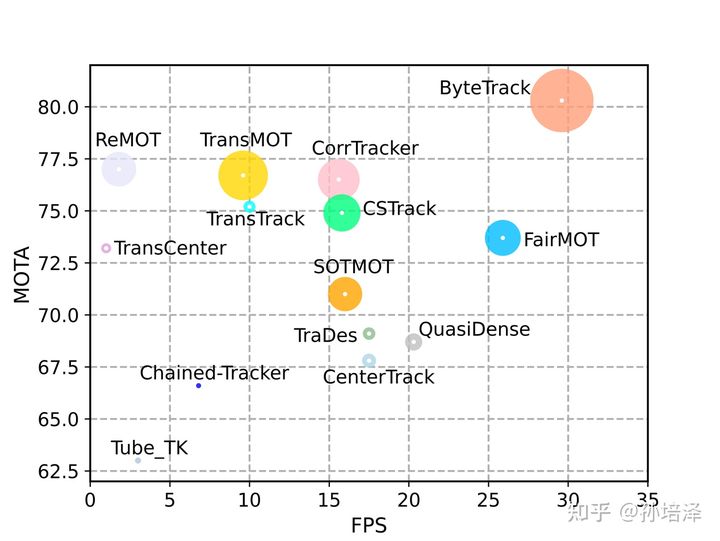
纵轴是MOTA,横轴是FPS,圆的半径代表IDF1的相对大小
1. Motivation
Tracking-by-detection是MOT中的一个经典高效的流派,通过相似度(位置、外观、运动等信息)来关联检测框得到跟踪轨迹。由于视频中场景的复杂性,检测器无法得到完美的检测结果。为了处理true positive/false positive的trade-off,目前大部分MOT方法会选择一个阈值,只保留高于这个阈值的检测结果来做关联得到跟踪结果,低于这个阈值的检测结果直接丢弃。但是这样做合理吗?答案是否定的。黑格尔说过:“存在即合理。”低分检测框往往预示着物体的存在(例如遮挡严重的物体)。简单地把这些物体丢弃会给MOT带来不可逆转的错误,包括大量的漏检和轨迹中断,降低整体跟踪性能。
2. BYTE
为了解决之前方法丢弃低分检测框的不合理性,我们提出了一种简单、高效、通用的数据关联方法BYTE (each detection box is a basic unit of the tracklet, as byte in computer program)。直接地将低分框和高分框放在一起与轨迹关联显然是不可取的,会带来很多的背景(false positive)。BYTE将高分框和低分框分开处理,利用低分检测框和跟踪轨迹之间的相似性,从低分框中挖掘出真正的物体,过滤掉背景。整个流程如下图所示:
(1)BYTE会将每个检测框根据得分分成两类,高分框和低分框,总共进行两次匹配。
(2)第一次使用高分框和之前的跟踪轨迹进行匹配。
(3)第二次使用低分框和第一次没有匹配上高分框的跟踪轨迹(例如在当前帧受到严重遮挡导致得分下降的物体)进行匹配。
(4)对于没有匹配上跟踪轨迹,得分又足够高的检测框,我们对其新建一个跟踪轨迹。对于没有匹配上检测框的跟踪轨迹,我们会保留30帧,在其再次出现时再进行匹配。
我们认为,BYTE能work的原因是遮挡往往伴随着检测得分由高到低的缓慢降低:被遮挡物体在被遮挡之前是可视物体,检测分数较高,建立轨迹;当物体被遮挡时,通过检测框与轨迹的位置重合度就能把遮挡的物体从低分框中挖掘出来,保持轨迹的连贯性。

3. ByteTrack
ByteTrack使用当前性能非常优秀的检测器YOLOX得到检测结果。在数据关联的过程中,和SORT一样,只使用卡尔曼滤波来预测当前帧的跟踪轨迹在下一帧的位置,预测的框和实际的检测框之间的IoU作为两次匹配时的相似度,通过匈牙利算法完成匹配。这里值得注意的是我们没有使用ReID特征来计算外观相似度:
(1)第一点是为了尽可能做到简单高速,第二点是我们发现在检测结果足够好的情况下,卡尔曼滤波的预测准确性非常高,能够代替ReID进行物体间的长时刻关联。实验中也发现加入ReID对跟踪结果没有提升。
(2)如果需要引入ReID特征来计算外观相似度,可以参考我们开源代码中将BYTE应用到JDE,FairMOT等joint-detection-and-embedding方法中的教程。
(3)ByteTrack只使用运动模型没有使用外观相似度能在MOT17,20取得高性能的本质原因是MOT数据集的运动模式比较单一
4.完整代码实现
视频,笔记和代码,以及注释都放到网盘了,放在主页置顶文章,避免初学者踩坑少走弯路,节省更多时间学习,研究