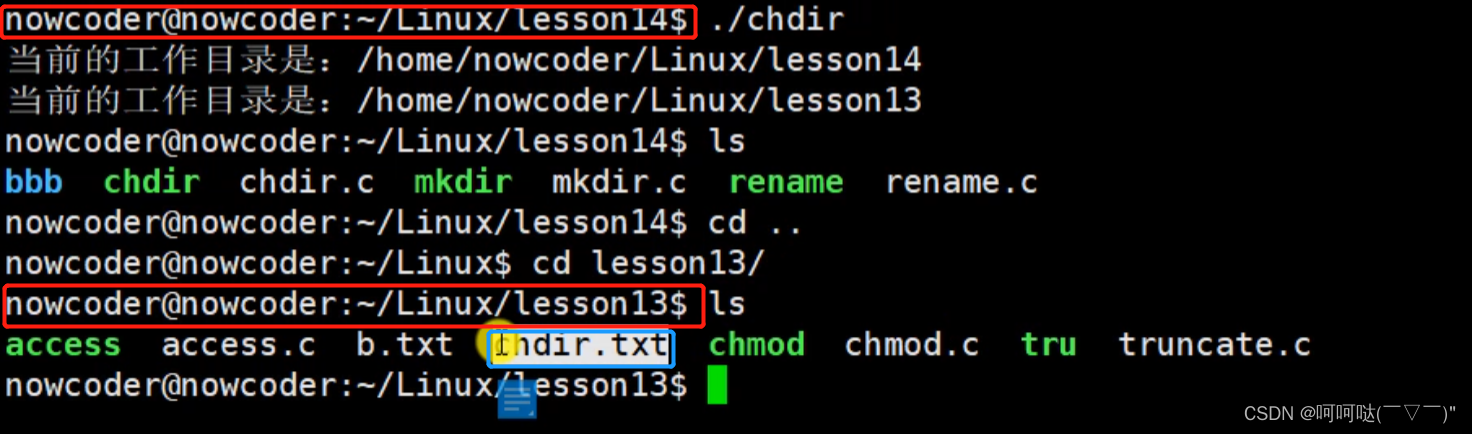
前面我们用过了cifar10,这里因为我们模型的体量更大,他能够理解更加复杂的数据集,所以这里我们就使用更加复杂的数据集叫做cifar100,顾名思义就是它是一个100分类的图像数据集,分类数据更多,复杂度更多。
定义数据集
import torchvision
import torch
#定义数据集
class Dataset(torch.utils.data.Dataset):
def __init__(self, train):
#在线加载数据集
#更多数据集:https://pytorch.org/vision/stable/datasets.html
self.data = torchvision.datasets.CIFAR100(root='data',
train=train,
download=True)
#更多数据增强:https://pytorch.org/vision/stable/transforms.html
self.compose = torchvision.transforms.Compose([
#原本是32*32的,缩放到300*300,这是为了适应预训练模型的习惯,便于它抽取图像特征
torchvision.transforms.Resize(300),
#随机左右翻转,这是一种图像增强,很显然,左右翻转不影响图像的分类结果
torchvision.transforms.RandomHorizontalFlip(p=0.5),
#图像转矩阵数据,值域是0-1之间
torchvision.transforms.ToTensor(),
#让图像的3个通道的数据分别服从3个正态分布,这3分数据是从一个大的数据集上统计得出的
#投影也是为了适应预训练模型的习惯
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
def __len__(self):
return len(self.data)
def __getitem__(self, i):
#取数据
x, y = self.data[i]
#应用compose,图像转数据
x = self.compose(x)
return x, y
dataset = Dataset(train=True)
x, y = dataset[0]
print(len(dataset), x.shape, y)这里我们使用了torchvision的加载数据集的方式,它能够在线的加载数据集,那么更多的数据集可以通过上面注释中的连接获得。root='data',是指将下载的数据集保存到本地磁盘的路径,也就是数据缓存的位置,下面这个参数train它的取值是一个布尔值,指的是要下载的数据集的训练的部分还是测试的部分,这里用到是一个变量因为两部分训练集我们都需要。
compose这个变量是torchvision提供的另外一个功能,就是图像的数据增强,具体的方法也可以通过注释当中的链接查到,下面演示的是常用的几个,第一个是resize也就是图像的缩放,原本是32x32,这里统一缩放到300x300,这是为了适应预训练模型的习惯,便于预训练模型抽取图像的特征,因为我们的预训练模型它训练的时候都是使用300x300的图像来训练的。第二个应用的图像增强就是随机的左右翻转,翻转的概率设置为0.5,但对于cifar100这个数据集来说,左右翻转是不影响图像的分类结果,加上这个数据增强是让我们的数据集更加的丰富。使用ToTensor这个工具类将图像转为矩阵,值域在0到1之间。最后我们对数据进行一个normalize,也就是让我们的图像数据的三个通道分别的服从三个正态分布,三个正态分布它的均值和标准差都写在上面了。
然后就是len和getitem,getitem这个函数每次取一批数据后,然后对这个图像应用我们的compose,这样对我们的图像增强,然后把图像转换为了数据。
定义loader
#每次从loader获取一批数据时回回调,可以在这里做一些数据整理的工作
#这里写的只是个例子,事实上这个回调函数什么也没干..
def collate_fn(data):
#取数据
x = [i[0] for i in data]
y = [i[1] for i in data]
#比如可以手动转换数据格式
x = torch.stack(x)
y = torch.LongTensor(y)
return x, y
#数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=8,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
x, y = next(iter(loader))
print(len(loader), x.shape, y)loader的代码没有什么可讲的,要提到的只有collate_fn,这个函数是每次从loader取一批数据的时候都会回调的,所以可以在这一个函数里面做一些数据整理的工作。
(6250, torch.Size([8, 3, 300, 300]), tensor([50, 54, 98, 51, 77, 96, 72, 81]))
很显然,x就是8张图像,y就是8个整数,取值是在0到100之间。
迁移学习
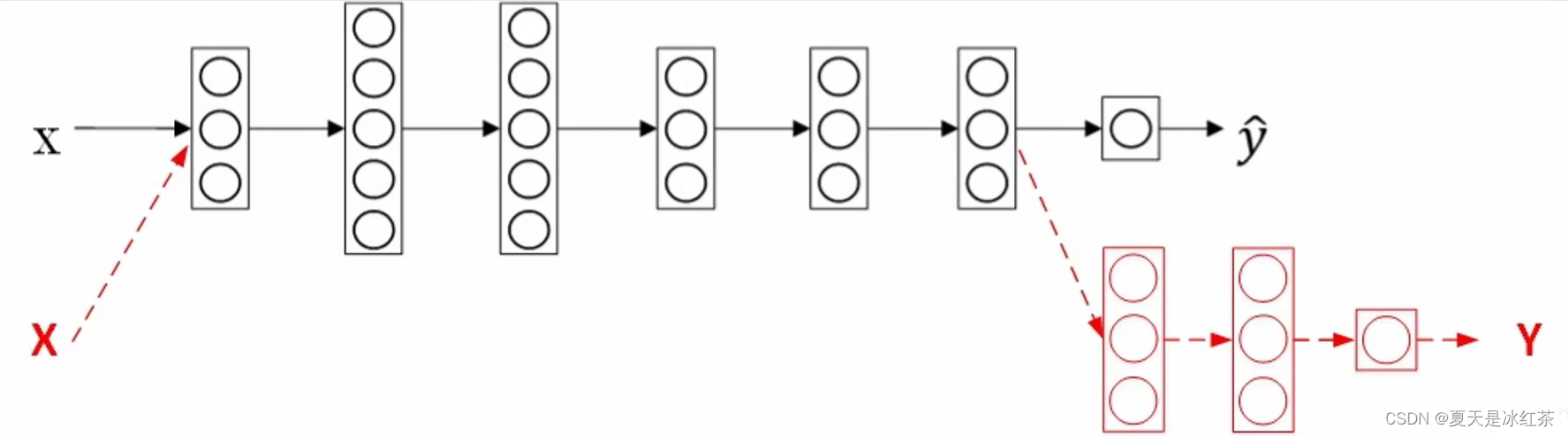
一般模型的第一部都是将数据读进去,然后一层层的抽取特征,最后把数据抽取成一个向量后,放到一个全连接的神经网络当中取进行分类,那么对于一个训练好的神经网络模型来说,其中的很多层其实是可以复用的。比方这里的一个模型它是一个回归的结果,然后我又不想要回归了怎么办。很简单,我将最后一层剪掉,然后重新接上三层新的,然后在这三层当中想做分类还是回归就有我自己决定了。也就是说前面的这些层我是不对它进行训练的,或者说这些层基本上训练好了,即使我对它进行重新的训练,难度也会想对的较小。
这种就是迁移学习,它的核心思想就是复用以前训练好的模型,它其中的一些层的参数,尤其是浅层的,因为这些层它是负责图像数据的特征抽取的,在我新的模型当中是可以复用的,因为数据特征抽取这个工作我一样是要做的。
定义模型
按照之前所说的,我们需要一个预训练好的模型,使用torchvision来完成这项工作,在这里面它提供了很多的预训练模型,更多的选择可以去链接中查找,这样通过torchvision加载后, 重新组装模型,而我们也只需要这里面的feature部分,后面给它接一个全连接的输出层,那么我要做的是分类还是回归就可以自己决定了。
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#加载预训练模型
#更多模型:https://pytorch.org/vision/stable/models.html#table-of-all-available-classification-weights
pretrained = torchvision.models.efficientnet_v2_s(
weights=torchvision.models.EfficientNet_V2_S_Weights.IMAGENET1K_V1)
#重新组装模型,只要特征抽取部分
pretrained = torch.nn.Sequential(
pretrained.features,
pretrained.avgpool,
torch.nn.Flatten(start_dim=1),
)
#锁定参数,不训练
for param in pretrained.parameters():
param.requires_grad_(False)
pretrained.eval()
self.pretrained = pretrained
#线性输出层,这部分是要重新训练的
self.fc = torch.nn.Sequential(
torch.nn.Linear(1280, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 100),
)
def forward(self, x):
#调用预训练模型抽取参数,因为预训练模型是不训练的,所以这里不需要计算梯度
with torch.no_grad():
#[8, 3, 300, 300] -> [8, 1280]
x = self.pretrained(x)
#计算线性输出
#[8, 1280] -> [8, 100]
return self.fc(x)
model = Model()
x = torch.randn(8, 3, 300, 300)
print(model.pretrained(x).shape, model(x).shape)模型训练
#训练
def train():
#注意这里的参数列表,只包括要训练的参数即可
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3)
loss_fun = torch.nn.CrossEntropyLoss()
model.fc.train()
#定义计算设备,优先使用gpu
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
print('device=', device)
for i, (x, y) in enumerate(loader):
#如果使用gpu,数据要搬运到显存里
x = x.to(device)
y = y.to(device)
out = model(x)
loss = loss_fun(out, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 500 == 0:
acc = (out.argmax(dim=1) == y).sum().item() / len(y)
print(i, loss.item(), acc)
#保存模型,只保存训练的部分即可
torch.save(model.fc.to('cpu'), 'model/8.model')定义设备是我们普遍会写的,如果有GPU那么就使用GPU进行运算
测试
@torch.no_grad()
def test():
#加载保存的模型
model.fc = torch.load('model/8.model')
model.fc.eval()
#加载测试数据集,共10000条数据
loader_test = torch.utils.data.DataLoader(dataset=Dataset(train=False),
batch_size=8,
shuffle=True,
drop_last=True)
correct = 0
total = 0
for i in range(100):
x, y = next(iter(loader_test))
#这里因为数据量不大,使用cpu计算就可以了
out = model(x).argmax(dim=1)
correct += (out == y).sum().item()
total += len(y)
print(correct / total)这里加载的是测试数据集,注意这里的train是False,最后得出的正确率为70%,还是比较的高的。