[介绍]
前面介绍了两个典型的调度模型,如果调度没有问题,剩下的问题就是正面刚算法了。那个不是我这里要介绍的主题的。
但,Not Really。其实除了算法在消耗CPU,CPU还是有很多余力可以挖掘的,这一篇我们专门讨论一下CPU的执行模型,看看我们在算法本身以外,还可以怎么优化我们程序的执行模型。
[流水线]
在不少软件人员的想象中,似乎只要保证CPU的占用率是100%,CPU应该是很忙的,应该在执行完一条指令,然后执行下一条指令,没有空干别的事情。
但如果我们深入进去看,实际上CPU里面也不是只有一个执行部件。假设有一个CPU上有4个执行部件,这些执行部件在CPU时钟的驱动下,一跳一跳地完成每一个动作,并完成一个指令一个指令的执行,这个执行流程就会是这样的:

看见了把,如果CPU真的这样执行,“取指”这个部件在一条指令的执行中,有三跳(CPU称为时钟周期)其实是“闲”着的。
所以,合理的模型应该是这样的:
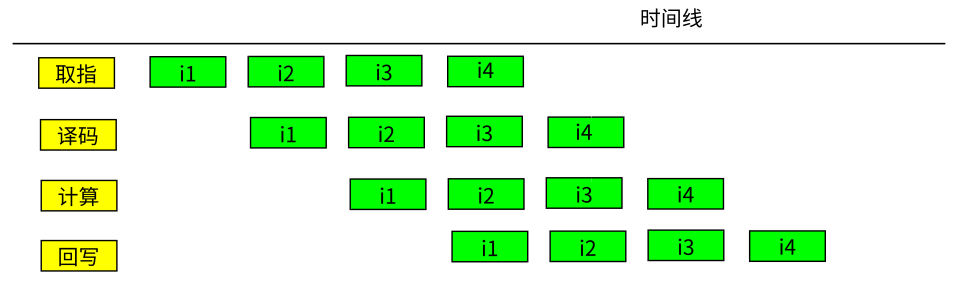
也就是说,i1(被取指这个部件)执行后,取指部件反正闲着也是闲着,不如就直接执行下一条指令的取指就好了。这样算起来,其实不是4个时钟周期执行一条指令的,实际上是一个时钟周期执行一条指令的。这个执行模型,我们就称为“流水线”。它和工厂中的生产流水线的调度原理几乎是一样的。每个执行部件在一条指令中执行占用的那个时间,称为一个Stage,一条指令包含多个Stage,但第二条指令并不需要等待上一条指令的所有Stage都完成了才开始自己的stage。每条指令包含的Stage数目,我们称为流水线的长度。流水线的长度决定了一条指令要多长时间才能完成,但如果流水线一切正常,平均起来,我们只需要一个stage的时间,就可以执行一条指令。
现代CPU的流水线是很长的,比如ARM的A57,流水线长度超过15。所以,看起来一条指令需要15个时钟周期,实际上你只需要1个时钟周期就可以执行一条指令。
[流水线的破坏1:指令依赖]
前面这个模型看起来很美,但实际上不是这样的,有很多问题会破坏流水线。最常见的破坏是指令依赖。比如你写如下汇编:
add r1, r2, r3 #r1=r2+r3
add r1, 1 #r1=r1+1
add r4, 2
这里第一条指令计算r1,第二条指令使用r1,第一条指令没有执行完,第二条指令译码完了,一看,我靠,要用r1,前面的还没有搞完,等等吧,就成这样了:

你看,CPU其实又闲下来了。(注:有人说,这个地方处理器可以通过寄存器改名实现不用等待,这句话没有错,但其实芯片不止这一种优化方法,我们要理解核心逻辑,在主线逻辑上拉这种逻辑没有意义,我们还是先聚焦原理,如果你有兴趣讨论这种细节,我们可以单独拉线索来讨论)
高级的CPU,编译器,都会进行指令调度。比如我们看到第三条指令跟谁没有没有依赖,我们可以把它调整到第二条的前面,这样可以填补一定的时间空间,这个执行会变成这样:

这个效率就又高了一点了。
流水线是个很麻烦的事情,而且你在玩这种小聪明,芯片设计师也在玩这种小聪明,所以,不到严重破坏的程度,我们不会在设计的时候就考虑它,尽量把它交给编译器和CPU自己。很多半桶水的程序员,会以为用汇编写的程序比用C写的程序效率高,其实这个基本上都是错的。因为你写汇编代码很难考虑流水线(特别是这里不光有指令的调度,还有寄存器的调度,用不同的寄存器,可能可以造成不同的依赖,从而优化流水线的执行),如果你强行考虑流水线了,你的代码也没法看了,因为它不是以人脑为对象的了,完全是机器的思维),而编译器考虑这样的东西,毫无压力。所以,我们只在流水线特别糟糕的地方考虑用汇编优化一下,而不会吃饱没事到处写汇编。这也是为什么多言数穷,不如守中。大家都想耍小聪明,这个系统就不聪明了,各守本分才“合道”。
[流水线的破坏2:跳转]
跳转指令也会引起流水线的破坏。考虑如下序列:
1:
...
add r1, r2, r3
jmp 1b #jump back to label 1
add r2, 1
add r3, 2
流水线确实把4条指令都执行了,但没有什么鬼用,因为第二条指令跳转到别的地方去了,后面两条指令执行了也是白执行。这种情况叫“指令预测失效”,也是破坏流水线的行为。
所以你经常看到一些高性能程序里面写这样的代码:
for(i=0; i<800; i+=4) {
a[i] = x;
a[i+1] = x;
a[i+2] = x;
a[i+3] = x;
}这个代码看起来完全可以用这样一个简单的代码代替:
for(i=0; i<800; i++) {
a[i] = x;
}
而作者要写成上面那个鬼样子,很多时候就是为了优化流水线。让跳转不要那么快发生。但还是那句话,不要在开始设计的时候就优化,否则自取其辱。
如果读者习惯Linux的代码,会经常看到likely和unlikely这个宏,它的作用也是这个,考虑一下如下汇编:
xor r1, r1, r1
jz 2f #jump forward to label 2 if zero
add r2, r2, 1
...
2:
我们把分支放在jz后面还是放在2:后面呢?放在jz后面预测就会成功,放到2:后面预测就会失败。那我们就应该把最可能的结果放在jz后面,所以我们才有likely和unlikely,通知编译器,谁才是最有可能的,这样也能有效提高CPU的执行效率。
[流水线的破坏3:内存访问和Cache模型]
指令依赖中, 有一种依赖是要特别注意的,就是访存指令。访问内存是很慢的,你这样想象一下吧:我们执行一条指令可能就是几个时钟周期,但访问一次内存的时间可能就是几百个时钟周期。想象一下下面这个执行过程:
ldr r1, [addr1]
add r1, r1, 3
add r2, r2, 4
add r3, r3, 5你以为这4条指令在一个流水线周期里就可以执行完了,实际是几百个时钟周期。这个效率一下就慢下来了。
我们当然可以把第三,四条指令提前,勉强填补一下中间的等待,但杯水车薪,也没有什么用。
这种时候,我们就要依赖Cache了,现代CPU系统有多级Cache,类似这样:

L1 Cache中有的,就从L1取,没有的就从L2取,……如此类推。这个问题考虑到他们的速度的时候,你就会发现其实是很严重的。
我们这样考虑这个问题吧:L1 Cache的访问速度是几个时钟周期(常常会是1个),L2是十几个,L3是几十个,到了内存上,就是几百个,如果是多道系统,插几个CPU,跨Socket的时候,就会更慢。
如果我们保证我们的执行尽量都在Cache的范围内,我们的性能就会提高。Cache Line的长度常常比寄存器的长度长,比如64位系统一个寄存器是8个字节,而Cache Line的长度常常可以达到128个字节。如果你的访问是对齐的,很多一次内存操作可以完成了动作,就不需要两次才能完成,这会大大提高执行的效率。另外,如果你在访存之前还有很多准备动作要做(memcpy一类的程序经常如此),你还可以通过Cache预取指令提前把内存的数据拉到Cache中,这也能大大提高效率。
还有一种会严重破坏性能的模型。称为Cache污染,大概的模型是:你的算法做得不好,总是访问一个Cache刚刚干掉的数据,每次访问都导致一次Cache刷新,性能就会严重下降。这个有很多论文了,我就不介绍了。基本上不是专业的研究者,我们也不用专门去记住这些模型,我们只要按功能,按软件构架的要求,把代码写出来,然后通过profiling工具去发现密集出现branch-miss,cache-miss的地方,根据情况作出优化就好了。
[异步调度模型]
上面我们给了一个基本的流水线模型。但实际上……呵呵,又来了……这种叫同步模型,现代的CPU,基本上不是这样的同步模型。现在CPU是异步调度模型。类似下面这样(网上随便找的图,侵删):
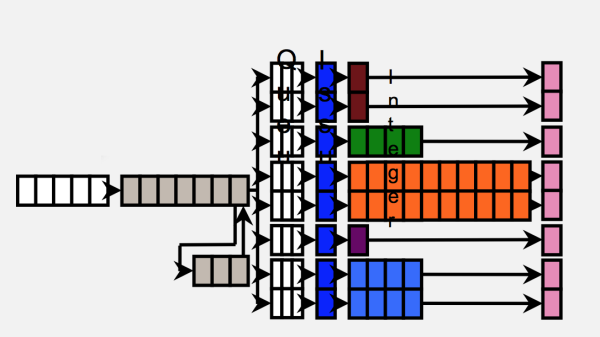
从中间开始,CPU的执行分成了两段。前面一段是取指有关的操作,后面一段是执行有关的操作。CPU有很多的执行通道,可以有多个定点或者浮点加法器,几个取指器等等。这样,实际上整个CPU就像一个多线程的软件程序:有一组线程负责把指令读出来,解码,然后送入队列,另一组线程负责从队列中把指令取出来,投入执行。这个执行并非严格的流水线模型,而更像我们这个系列文章最前面提到的那个队列模型。
在芯片的优化手册中,会给出前端和后端有哪些执行部件(比如一个比较新的RISC CPU上的前端是Fetch, Decode/Rename/Dispatch和Issue,后端是Branch, Int0, Int1, Int Multi-Cycle,FP0, FP1, Load, Store)。然后它还会给出每个指令需要占用哪些执行部件,已经这个指令的执行时延和执行通量。如果你要进行汇编一级的优化(比如为这个CPU配套编译器),你就需要根据这个优化手册对指令进行重排。而对于优化者,则首先看重程序的IPC(每个cycle执行多少条指令),然后查对应的stall参数,看有没有机会特别重排程序特定的部分,从而加快执行效率。
下面这个是Intel的一个Top Down模型(侵删):

前面一段就是取指有关的,是In-Order的操作,这部分是符合原来的流水线模型的。后面一段就是纯粹的调度。这个性能就不能完全按严格的流水线模型来考虑(加上超线程技术就会更加复杂)。所以现在你用perf stat执行一个程序,它会给你这个总结(不是每个CPU都支持这两个统计):
你可以看到了,它首先给你统计了一个stalled-cycles-frontend,和一个stalled-cycles-backend,通过这两个统计,你可以看到,无论你如何执行,你的系统到底有多少花在了前端的等待上,多少花在在后端的执行上。前者说明你供指令的速度不够快,后者说明你CPU处理不过来。我们可以以这个为基础,进一步找到系统的执行瓶颈。
Intel处理器上,这个模型称为Top-Down模型(现在ARMv8也开始用一样的名字了,据说这个名字原来来自IBM),以这个为分界,可以一步步分解下去,最终找到执行瓶颈在什么地方,我们从而可以找到合适的软件执行模型,提高系统的执行效率。这些模型首先和CPU的微架构是相关的,但基于我们原来的流水线中形成的经验,我们在一定程度上,到都有相当的机会了解到我们可以调整软件的什么设计来让CPU执行得更快。
[小结]
本文介绍了一些基础的CPU执行模型,一定程度上了解CPU的执行模型,有助于我们正确找到系统的性能瓶颈。但从这些模型中,我们也看到了,其实整个系统的每个模块都在尝试优化自己的执行效率,而作为最高层的软件,其实是最需要遵守“多言数穷,不如守中”策略的角色。从设计的角度,软件引导了整个需求的响应方法,软件守不稳,所有其他的小九九都是水月镜花,留不住的,我们不能理解这一点,也就不能理解为什么软件架构这么重要。
越是混沌的系统,越需要我们守得住基本面。
很多人也许觉得这里讨论的问题都很简单,但越是简单的东西你越守不住,当你被眼花缭乱的变化吸引了大部分的注意力的时候,你回过头来想一想,你当初的需求到底是什么。这就是我们说的:执古之道,以御今只有,能知古始,是谓道纪。我们能掌握现在的复杂局面,我们必须回到最开始解决的问题上,我们才有可能理解和控制现在的一切变化。