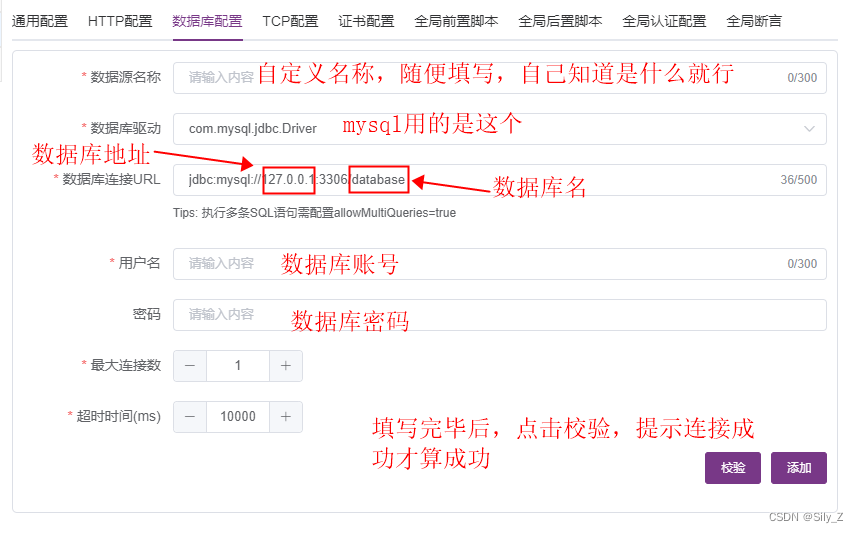
作者:Christofer Dutz
得益于 Timecho 的组织和安排,我最近参加了一个精彩绝伦的活动 “AI in the Alps”,并从中收获颇丰。
这次活动是由德国工业界知名博客 “Industrial AI Podcast”(http://aipod.de)的组织者 Robert Weber 与 Peter Seeberg 举办的。30位分别来自西门子(Siemens),通快(Trumpf),费斯托(Festo),菲尼克斯电气(Phoenix Contact),科控(KEBA),杜尔(Dürr)等工业龙头的决策者抱着对工业 AI 应用的浓厚兴趣聚集在奥地利阿尔卑斯山脉美丽的 Rote Wand 酒店,通过特邀嘉宾 Sepp Hochreiter 教授(奥地利林茨大学)、Cees Snoek教授(荷兰阿姆斯特丹大学)和 Marco Huber 教授(德国斯图加特大学、弗劳恩霍夫协会)的引导,在两天的时间里深入交流人工智能的发展及在工业领域的应用。此外,奥地利数字化和电信部国务秘书 Florian Tursky 也作为特邀访客出席了活动。
与其他深耕人工智能领域多年的到场专家相比,我之前对 AI 的了解较为有限,因此请对我所分享的“事后感想”持保留态度,因为我可能会因为对相关领域研究得不够透彻而没有完全领会其他人所探讨的一些主题。
热点话题
在两天的交流中,被提及最多的主题无疑是"Foundation Models"(基础模型)。据我所了解,ChatGPT 这类人工智能工具都是基于此。一般来说,它们通过处理大量的文本数据进行训练,以使模型能够理解和生成文本内容。这种方法的特殊之处在于,通常只需将大量数据输入模型,让其自行学习,而无需通过包含上千张猫和狗的图片的照片集作为训练依据。这些模型是基于未标记的数据得出的。
ChatGPT 的巨大关注度使得人工智能(AI)和大语言模型(LLMs)短时间内成为全球瞩目的焦点,一度连我的父亲都尝试使用过它 —— 这对我来说是衡量一个话题热度的主要参考指标。当全球的目光都汇集到这个行业,大量的资金也必然接踵而至,因此目前 AI 和 LLM 的研究非常活跃。
创建工业基础模型的愿景
许多公司和开发者梦想着简单地创建一个工业领域的基础模型。然而问题并没有那么简单,对于ChatGPT模型而言,只需利用“人类语言”的共享数据格式从公开可获取的网络部分收集数据即可。而对其他领域来说,这样的做法是非常具有挑战甚至说不可能实现的,因为这会需要企业之间分享他们的工业生产经验,甚至有时候还需要共享他们宝贵的工业数据。
基于我在工业领域多年的 IT 工作经验,我知道让工业自动化公司自愿共享他们的生产数据的机会可能比地球改变自转方向的机会更小。在一个每一点信息都被视为商业机密的领域,训练这样一个模型是不可行的。然而,仅在一家本地公司进行局部训练将无法产生通用的 LLM,就像仅根据一家公司的网页出版物来训练 ChatGPT 模型并不能得到有用的结果一样。
在两天的交流讨论中,经常被提到的解决方案之一是联邦学习(Federated Learning)。这种方法下数据不需要离开公司,而是只需要在公司内部进行数据的训练,然后共享训练结果。然而,这种方法需要大量的计算能力,因为共享模型权重需要进行多次训练迭代。实际上,这种方法恐怕需要数倍于集中训练所需的计算资源。
尤其对于欧洲而言,对美国和中国公司提供的计算能力的依赖是一个大问题。欧洲必须建立起欧洲基础设施,才能实现对这类人工智能模型的训练。而目前欧洲的投入还远远不够,因此正面临着越来越落后的风险。

(图片:Sepp Hochreiter 教授介绍 LSTM 架构; 摄影:Peter Seeberg)
信任危机
即使马上拥有了无限的计算能力,我认为这种方法仍然面临一个更大的问题:信任。联邦学习要求本地数据的所有者允许外部代理访问他们珍贵的核心数据,这无疑是非常困难的。甚至我们可以将这个问题再上升一个高度:我们如何信任一个人工智能模型?这可能是最大的问题,也似乎是公众共同关注的问题。
随着 ChatGPT 的流行,许多人对当今人工智能的能力感到印象深刻,同时也开始对其可能导致的后果感到担忧。即使这个领域的专家也不一定能解释清楚人工智能模型的工作原理,我们又如何能够全面信任它呢?
公众对人工智能的兴趣和对其能力的担忧导致了全球范围内的人工智能监管倡议。然而,所有这些倡议目前仍在不断完善,并且可能会持续很长时间。问题在于:我们如何对一件我们并不完全了解和无法解释的事物进行监管?
Sepp Hochreiter 教授提到,他已经帮助奥地利技术监督协会(TÜV)开发和提供 AI 模型认证。然而,即使这些认证也不能保证 AI 将会做什么,它只能确保合理的设置、处理过程和测试数据被用于训练一个表现良好的 AI “大脑”。但就像养孩子一样,即使父母提供了最优渥的条件,也无法保证孩子永远不会走上歧途。关于这一点,国务秘书 Florian Tursky 作为特别嘉宾也向我们介绍了他在欧洲 AI 法案工作中的一些思考与规划。

(图片:奥地利国务秘书 Florian Tursky 介绍欧洲 AI 法案;摄影:Robert Weber)
因此,当前的研究工作也非常注重可解释性:我们如何让 AI 解释为什么它得出了一个结论,并导致了某个特定的行为。对于视觉模型来说,这相对容易,通过突出显示影响决策的图像部分,我们可以看到模型对输入数据的哪些部分产生了最大影响,从而推断出它的工作原理。
对于正在进行的所有的 AI 模型的研究来说,这注定不是一项轻松的任务。
空中楼阁
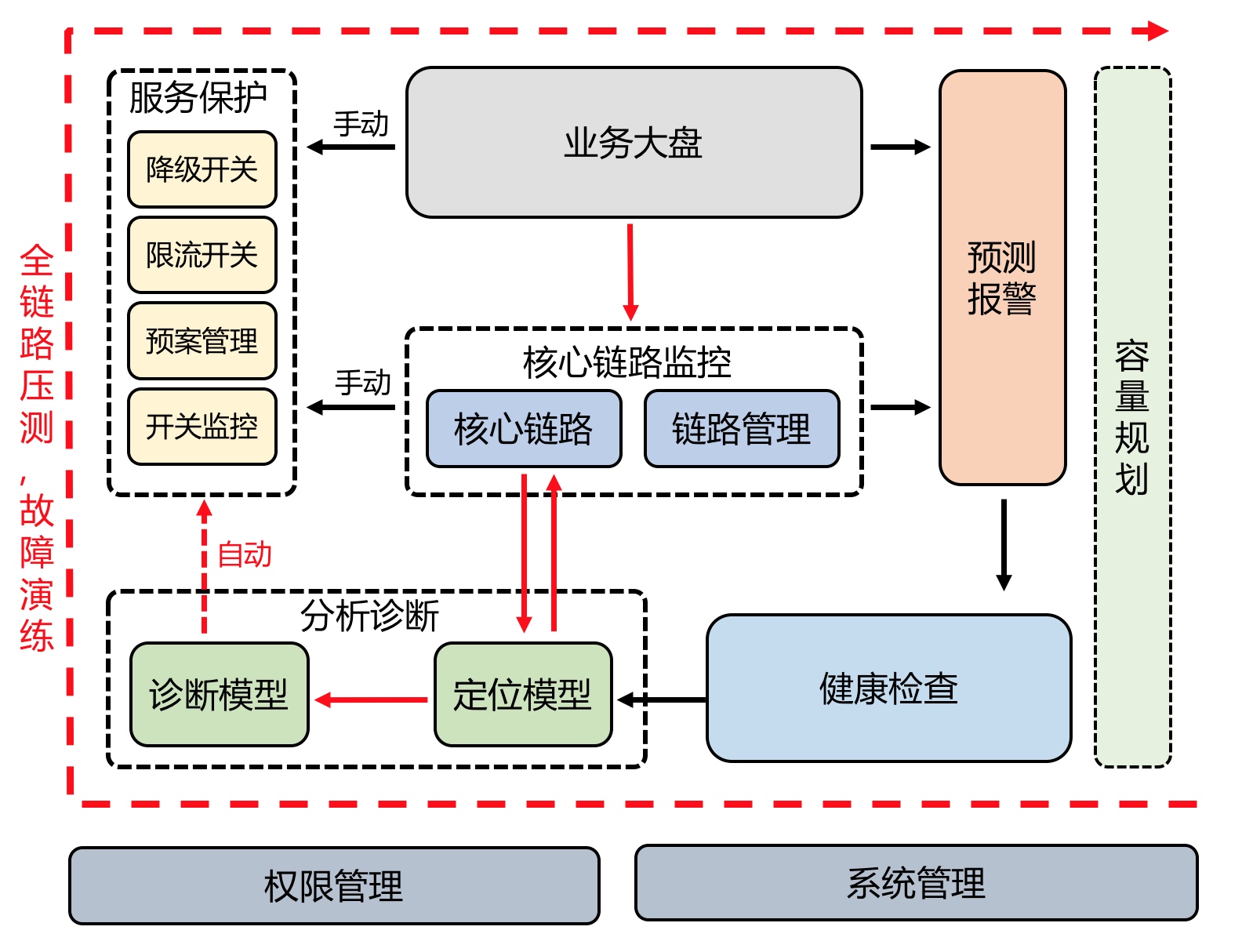
然而,最令我惊讶却也令我满意的一点是,工业应用领域有一件事情始终没有改变:如何普遍访问工业自动化数据并有效地访问这些数据依旧是一个悬而未决的问题。
工业自动化存在大量互相竞争的产品和协议。每个产品都需要不同的数据访问方式,因为标准和协议不同。为了实现自动化,除了工业生产中的实时数据以外,作为时间序列数据(timeseries data)被存储的信息也必须随时可用,因为对自动化流程与模式的监测和改进不仅需要实时数据,还需要其历史数据。
理论上,工业领域对时间序列数据库的使用要更早于 IT 领域。自工业自动化诞生以来,一直存在着所谓的"实时/历史数据库"系统。然而,这些系统被用来存储历史生产数据,主要用于归档和监管目的,并且仅用于存储特定设备的数据。这些设备适合检查系统的当前状态,以及查看一定时间范围内某个参数的历史数据,但它们绝对不适合进行复杂查询。据我所知,想要检索某个数据点在过去几年的历史数据需要花费几分钟甚至几小时的时间。查询的不灵活性和低下的查询性能导致这类系统完全不适合用于 AI 或 机器学习(ML)的训练。如果所有这些依旧不是问题,那么历史数据库的价格对于一般的IT人员来说可能是荒谬的 —— 据说,能够存储10,000个数据点的系统售价可能要100,000欧元,而这个价格在业内甚至可能会被认为是“合理的”。恐怕我们必须通过 AI 模型大幅优化生产线以带来更多盈利,这样才能负担起这部分成本。
目前来说,我们需要可扩展的系统工具用于查询各种不同系统的数据,并将这些信息安全地存储在一个能够处理海量数据的系统中,同时不能影响对这些数据进行基于时间戳或是时间窗口的高级查询。
对各种不同数据源的支持会带来了另一个问题:乱序数据。一些工业系统提供的数据具有毫秒甚至纳秒的延迟,而其他系统可能需要几秒甚至更长时间。这种数据乱序到达的情况工业实时库根本无法处理,不仅如此,大多数时间序列数据库也难以应对这个问题。
从开源项目中寻找解法
然而,Apache PLC4X 和 Apache IoTDB 在解决这些问题方面表现得很出色。
Apache PLC4X 是 Apache 软件基金会的一个开源项目,能在大多数情况下解决工业数据的可用难题。它是基于最流行的工业协议的抽象层,客服了集成工业硬件的复杂性难题,以出色的简洁和性能保证工业数据的可用性(大多数 PLC4X 驱动程序的性能要远远高于昂贵的商业驱动程序)。概括的说,PLC4X 是一种通用协议转换器,如果你看过《银河系漫游指南》的话,可以将其视为一条“巴别鱼”,即工业自动化的"通用翻译器" 。想了解更多 PLC4X 的信息,可以访问官网 plc4x.apache.org.

Apache IoTDB 是一个时序数据管理系统,它并不是在传统关系数据库系统之上对时间序列功能进行深化,而是从一开始就专为物联网场景下的数据处理而构建的,并且能够在高效处理海量数据的同时对乱序数据进行重新排序和存储。与传统历史数据库不同,它可以非常高效地查询时间序列数据并拥有非常强大的时间聚合功能。想了解更多 PLC4X 的信息,可以访问官网 iotdb.apache.org.

(摄影:Robert Weber)
作为 ASF 基金会的开源项目,两者都可以被安全并快速地上手使用,而且无需投入太多前期成本。如果想从简单的概念验证过渡到复杂的生产环境,还可以使用 Timecho 提供的商业版本 TimechoDB,其中包含了很多工业企业领域所需的优化和定制的功能,以及一切所需的技术支持。
综上所述,AI 领域存在许多需要解决的问题,但如果我们不能解决真实工业场景中数据可用和数据质量这些痛点以作为先决条件的话,那么讨论这些问题也没有意义了。当我意识到这一点时,我感到非常高兴,因为我知道我们在Timecho 正在正确的道路上大步迈进。
注:
本文发表于 Medium,原文链接:https://medium.com/@christofer.dutz/ai-in-the-alps-excellent-banquet-for-the-body-and-the-mind-8d87cebb4ed5
以下为文章英文原文:
"AI in the Alps": excellent banquet for the body and the mind
Admittedly, I was one of the few participants of the event that hadn't been digging big in the AI world before. So please treat my "lessons learned" with a grain of salt and I will probably be missing some of the topics others took with them, simply because I didn't quite understand them

The event was organized by the people behind the "Industrial AI podcast" (https://aipod.de/), and supported by Hannover Messe, Ionos and Timecho. It brought together 30 individuals who were involved in and greatly interested in the topic of industrial AI to meet in the Hotel "Rote Wand" in the beautiful Austrian Alps and discuss the topic, guided by special guests: Prof. Dr. Sepp Hochreiter, Prof. Dr. Cees Snoek and Prof. Marco Huber. It was two days of very intensive workshops and fruitful discussions.
The Hot Topics
The probably most mentioned topic was definitly "Foundation Models". As far as I understood it, these are something that for example ChatGPT are based on. Here, in general, textual data was processed in enormous quantities to train a model that understands textual content and is able to produce it. The speciality of it is, that in general you just feed enormous amounts of data to it, and the training sort of figures out things on it's own without having to provide the famous 1,000 pictures of cats and dogs as training base. These models are derived from untagged data.
After the huge attention ChatGPT brought to this technology, all of a sudden AI and LLMs have been put into the spotlight of word-wide attention. Even my dad has played with it, which I would consider my measure of something having hit the attention of the mainstream.
This global attention has been also directing huge amounts of corporate attention and money to this field, which is currently resulting in an unmatched activity on the side of research as well as corporate initiatives.
The dream of creating an industrial Foundation-Model
Many are dreaming of simply creating a foundation-model of the industrial domain. The main problem however is, that for the ChatGPT model, all that had to be done, was scraping the publicly available part of the web using the shared data-formats of "human languages". However, applying the same approach to other domains is considered extremely challenging, if not impossible, as it would require a shared representation of industrial knowledge and what makes things even more difficult: it would require the industry sharing their sacred industrial data.
Having worked in the industry as an IT guy for the last 6 years, I know that the chance for the earth spontaneously changing it's rotation direction is probably more likely to happen than any company in industrial automation freely giving away their production data. In an area where every bit of information is considered a corporate secret, training such a model is just out of the question. Locally training a model in a local company however will never be able to produce a general purpose LLM. Similarly like training ChatGPT solely on the Web-publications of one company will not result in anything useable.
One alternative discussed quite often was the concept of Federated learning. In this approach the Data doesn't need to leave the company, but training happens where the data is and only the results are then shared with the rest of the world.
The main problem with this, is that this approach would require an enormous amount of compute power as the sharing of model weights would require many, many iterations of training. This approach would effectively require multiple times the computational power of training it in a central way.
Especially for Europe, having to rely on compute power that is mainly provided by US and Chinese companies is a big problem. Europe definitely needs to build up the European infrastructure allowing the training of such AI models. All efforts that are currently on the way are absolutely not sufficient and Europe is currently at risk of being left behind.

Photo: Peter Seeberg
Trust
Even if for some reason we'd instantly have unlimited compute-power at our disposal, in my opinion this approach has one even bigger problem: Trust. Federated learning requires the entity who's data is being used to train locally to accept an agent from the outside to play with his crown-jewels (yes ... They named it that way ... multiple times).
And I think we can lift this problem even one level higher: How can we trust an AI model in general? This is probably the biggest problem and the only of the AI-related problems that the public seems to be sharing.
With the huge popularity of ChatGPT many people have been both impressed with what AI today is capable of, but also have started to become worried of where it could lead at the same time. If not even experts are some times able to explain how an AI model works, how can we trust it in general?
This public interest and fear of what AI can do resulted in AI regulation initiatives all over the planet. However, all of these are currently being refined and probably will continue to be refined for a long, long time. The main problem here is: How do we regulate something we don't quite understand and can't explain?
Prof. Sepp Hochreiter mentioned, that he has helped TÜV Austria develop and offer certifications on AI models. However, even these certifications can't guarantee what an AI will be doing. It just ensures the training setup, the procedure and the test-data were selected and prepared in a way to allow training of a well-behaving AI master-mind. But just like raising a child in ideal conditions, it can't guarantee the kid won't become some crazy mass-murderer.
Something down this line was what our special guest: Florian Tursky, who is the Austrian state secretary in the area of digitization and telecommunication, reported from the work on the European AI Act.
Therefore currently a lot of research effort also goes into explainability. How can we make an AI explain why it drew a conclusion and this resulted in a certain action. With visual models this has been relatively easy, by highlighting the parts of the image, that have been influencing the decision. This way we can see which parts of the input data the model had the biggest influence and then sort of derive how it works from that.
With all other models, however, this is a non-trivial task and a lot of research is currently happening in this sector.
Dreaming of flying without being able to walk
But for me, the most surprising but admittedly also most satisfying thing I've learned, was that one thing hasn't changed in the field of industrial use-cases. The one problem that hasn't been considered solved is universal access to industrial automation data and being able to access this data efficiently.
In industrial automation a huge amount of competing products and protocols are being used. Each requiring different ways of accessing data, because of differing standards and protocols.
Besides live data from Automation, this information needs to be available as Timeseries data. As in order to detect and learn from patterns, you don't only need the current values, but also their history.
Theoretically the industry has been using Timeseries databases a lot longer than we have been in the IT world. So-called Historians have been around since the dawn of industrial automation. However have these systems serverd different purposes. They were created to store historic production data, mainly for documentation and regulatory purposes. And have been built to store data from only particular devices. The result is, that these devices are fine for inspecting the current state of a system and to look at historic data for one parameter and a given timeframe, however they absolutely are optimized for injesting big amounts of pre-defined data and to store this information over a long period of time and lack at options to do complex queries. I have heard that retrieving the data for a given datapoint a few years in the past can take up to several minutes if not hours. Both the inflexibility of query options and the query performance totally disqualify these systems for AI or ML training purposes. If all of this was not a problem, Historinans usually have a price-tag that normal IT folks would consider ridiculous. I have heard that 100000€ for a system that is able to store 10000 datapoints would be considered "reasonably-priced". You definitely need to optimize your procuction line quite a bit with your AI model in order to finance allone that part.
In the current world, we need scalable systems to query data from a big variety of different systems, to store this information in a system capable of injesting and storing this high volume data securly and to still be able to run advanced time-based queries on this data.
Supporting a big variety of different sources adds another problem to the picture: Out-of-sequence data. Some industrial systems provide data with a millisecond or even nanosecond delay, others take seconds and more. This is something Historians can't really cope with at all and even most modern Timeseries databases have problems handling.
Open-Source to the rescue

However, these are all areas in which Apache PLC4X and Apache IoTDB excel at.
When it comes to making industrial data available, Apache PLC4X is an ASF open-source project that is able to solve most of the problems. It's an abstraction layer over the most popular industrial protocols and hides the complexities of integrating industrial hardware and makes industrial data available with an unmatched simplicity and performance (Most PLC4X drivers outperform most expensive commercial drivers by far). Think of it as a "babelfisch" for industrial automation - a universal protocol converter (Excuse the "hitchhiker's guide to the galaxy" reference ... It just fits so well). (https://plc4x.apache.org)
Apache IoTDB is not an abstraction of Timeseries features on top of classical relational database systems, but was built from the start for handling IoT usecases and especially made for efficiently handling out-of-sequence data while injesting enormous amounts of data at the same time. In contrast to classical Historians, it still allows querying the timeseries data very efficiently and using very advanced time-aggregation functions. (https://iotdb.apache.org)
Both being open-source projects at the ASF, it is safe to simply start using them without having to invest too much upfront, but when moving from a simple POC to a complex production scenario, Timecho with it's commercial version of Apache IoTDB called TimechoDB adds some optimizations and featrues needed in the enterprise field, is able to provide the levels of support needed.
So in order to summarize everything: There are many problems that need solving in the AI world, but none of these truely matter in an industrial scenario, if we don't solve the problems of making data available with the right performance and the right quality. It made me very happy when I realized this, knowing that what we're working on solving all of these problems at Timecho.