文章目录
- 1.前言
- 2.调度中心流程
- 2.1.任务配置扫描流程
- 2.2.计算任务触发时机
- 2.2.1.已超时5秒以上
- 2.2.2.超时未超过5秒
- 2.2.3.还未到触发时间
- 2.3.任务触发流程
- 2.3.1.任务触发线程池
- 2.3.2.参数处理
- 2.3.3.任务触发
- 2.3.4.分片广播策略(补充)
- 3.执行器流程
- 3.1.任务处理器初始化
- 3.2.执行器任务处理流程
- 3.2.1.jobThread创建
- 3.2.2.阻塞策略判断
- 3.2.3.任务执行
- 3.3.任务回调流程
- 4.结语
1.前言
XXL-JOB专题历史文章列表:
- XXL-JOB调度中心集群部署配置(一)
- XXL-JOB执行器配置及定时任务的创建(二)
- XXL-JOB调度中心对执行器的上下线感知实现原理(三)
本篇的主要内容是XXL-JOB的任务调度流程及其实现原理,包含了两个部分:
- 调度中心如何进行任务调度
- 执行器执行任务需要注意哪些问题
在开始研究XXL-JOB的调度流程之前,我们不妨先思考一下,如果让自己来实现一个任务调度,需要从哪些方面去入手呢?
对调度流程的思考
在前面的配置相关的文章中,我们已经实现了一个调度中心集群、以及一个执行器,并创建了一个定时任务配置,在这样的基础上,要实现一个简单的任务调度Demo是非常简单的。
不记得定时任务的配置过程的同学,可以回顾一下前两篇关于调度中心和执行器配置的文章。
- 对调度中心来说:
只需要启动一个线程,让这个线程不断的去查询定时任务配置表,拿到配置数据之后,与当前系统时间做对比,判断任务是否到了触发时间,如果到了触发时间就调用执行器执行定时任务。 - 对执行器来说:
等待调度中心进行任务调度,收到调度请求后执行任务,响应执行结果。
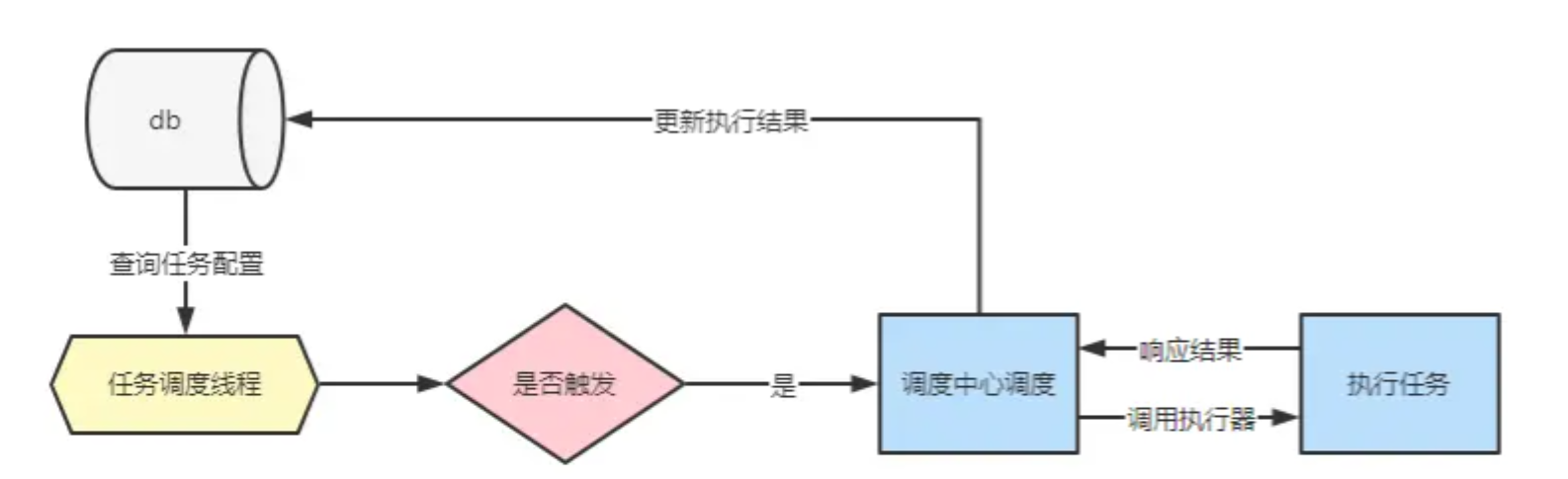
这样,一个最简单定时任务就完成了。当然,这样的任务调度流程是非常粗糙,只能存在于Demo中,想要在生产环境中运行,还需要解决很多问题,例如:
调度中心需要解决的问题:
- 调度中心集群是否会产生重复调度问题?
- 间隔多长时间查询一次数据库合适?
- 如何判断任务已经到了触发时间?
- 如果查询出的任务,已经过了触发时间了怎么办?
- 如何获取执行器?
- 有多个执行器怎么处理呢?
- 任务执行时间过长,阻塞其他任务执行怎么处理?
- ……
执行器需要解决的问题:
- 如果前一个任务没有执行完,后一个任务又来了,怎么处理?
- 一个执行器中有多个任务时,如何找到当前应该执行的任务?
- 多个任务之间如何避免互相影响?
- 任务执行超时如何处理?
- ……
后面可以带着这些问题,一起看看XXL-JOB是如何处理的,在看调度中心的流程之前,先熟悉一下本篇文章中需要用到的几张表:
xxl_job_registry:执行器注册表,保存活跃的执行器信息
xxl_job_group:执行器配置表
xxl_job_info:定时任务配置表
xxl_job_lock:分布式锁信息表
2.调度中心流程
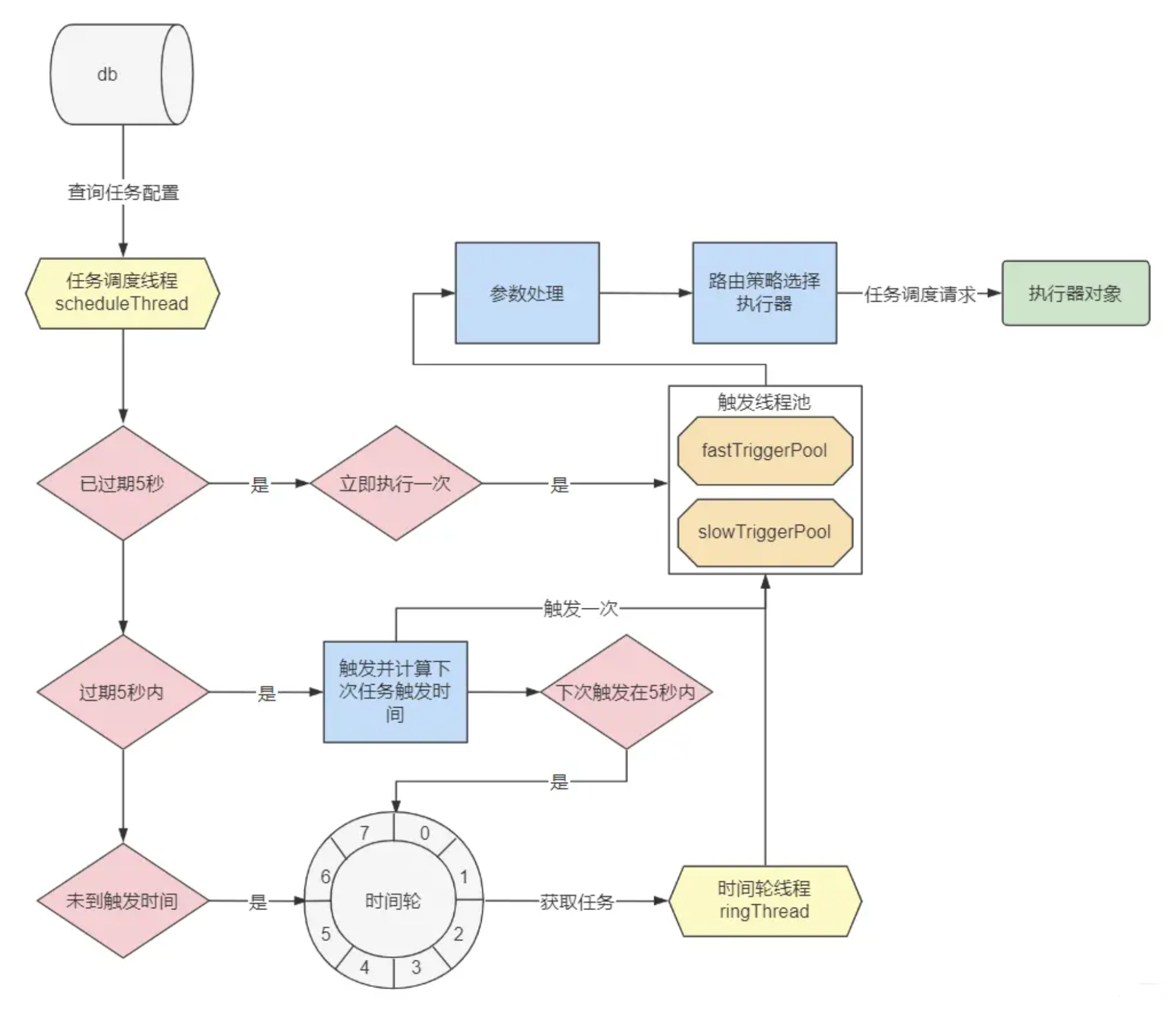
调度中心做的第一件事,就是启动一个线程不断的扫描定时任务配置表 xxl_job_info,我们可以从初始化方法 com.xxl.job.admin.core.scheduler.XxlJobScheduler#init 中找到这个线程的初始化过程,如下图:
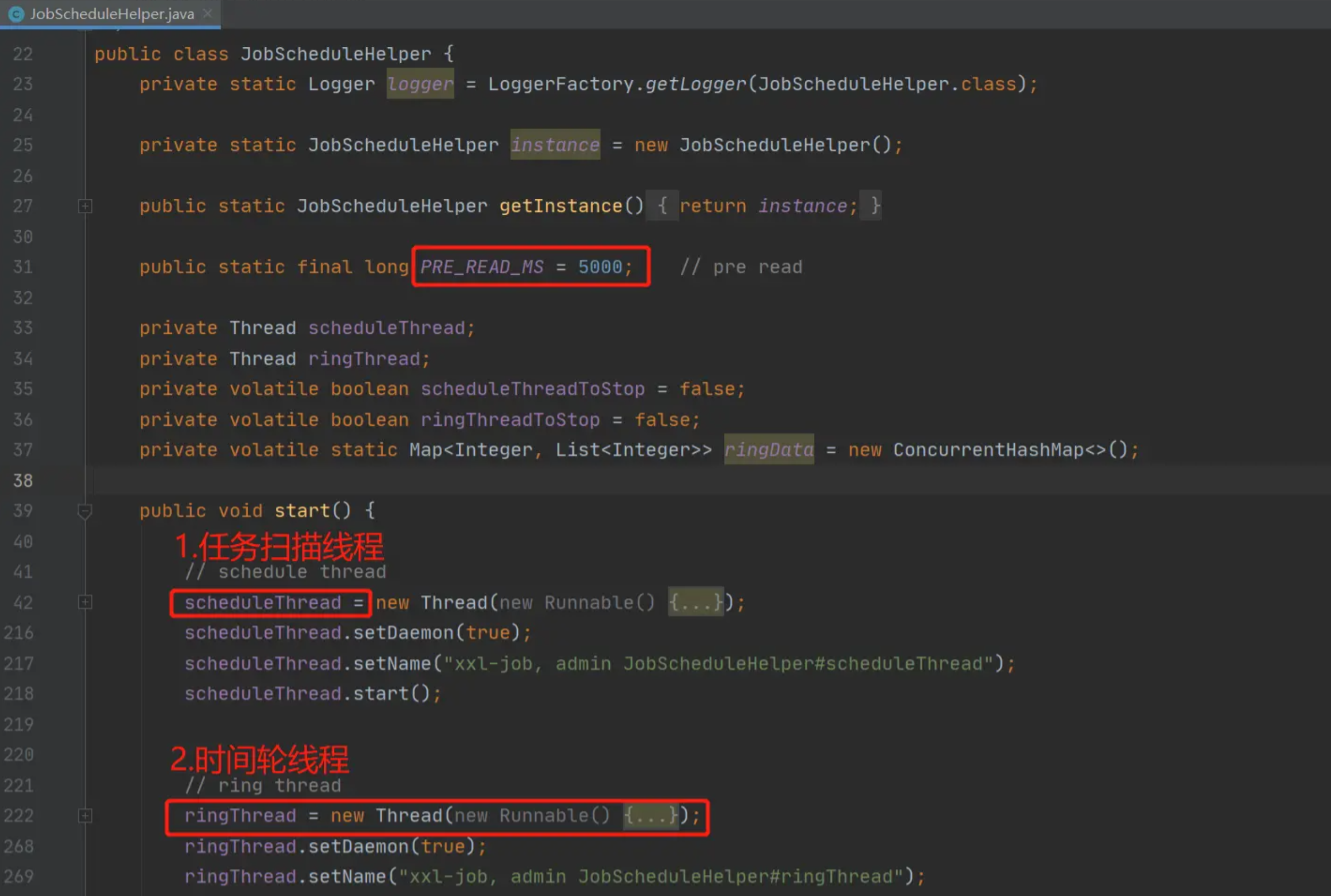
可以看到在初始化方法中启动两个线程,分别是:
- scheduleThread:任务扫描线程,用来扫描任务配置表,并判断当前任务是否应该触发
- ringThread:时间轮线程,除少部分直接触发的任务以外,其余任务触发都由时间轮线程调度。
此外,可以注意一下图中的 5000,这是一个时间值,在任务扫描和处理的过程中,还会多次使用到。先看一下任务配置的扫描细节。
2.1.任务配置扫描流程
scheduleThread启动之后就会循环扫描定时任务配置表,先看一下代码:


也就是说,每次扫描,会查询xxl_job_info中,处于启动状态,且下次执行时间 trigger_next_time <= 当前时间 + 5000ms的数据,最多可以获取到pagesize大小的列表。
这里的 trigger_next_time 指的是下次任务触发时间,是在定时任务配置保存、更新、启动时,通过Cron表达式进行计算的,并且在每次定时任务触发时,也会更新trigger_next_time的值。
为什么不能用系统时间精确匹配呢?
使用当前系统时间进行精确匹配查询的话,查询出的数据是有可能不准确的。例如:当前获取到的时间是2022年12月6日18点整,有两个定时任务的触发时间分别是18:00:00和18:00:01,这时候可以匹配到第一个定时任务。但是第一个任务的调度时间大于1s的话,下一次进入循环时第二个任务就匹配不上了。
为了解决这个问题,会采用将时间点扩大为一个时间段的方式,这也就是为什么会使用 <=当前时间 + 5s 来作为查询条件。
pageSize的值是怎么来的呢?
这里的pagesize的值是6000,也就是我们经常在说的,XXL-JOB默认支持定时任务数量,这是通过一个公式在进行计算的。
经过作者大量的数据验证,发现大多数定时任务的触发耗时都在 50ms 以内,可以得到qps为 20。
在xxl-job-admin的配置文件中,有这么两个默认配置:
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
即触发线程池中的线程一共有300个,所以理论上每秒能处理的触发任务就是(200+100)×20=6000个,实际能处理多少还得看硬件配置。
注:这里的fast和slow指的是快慢线程池,下面的内容会讲到。
如果多部署几个调度中心的节点,可以增加可用的任务配置数量吗?
很遗憾,并不能,为了避免调度中心集群重复调度的问题,使用数据库做了一个分布式锁,在每个调度中心的scheduleThread在扫描任务表之前,都会先执行下面的SQL语句
select * from xxl_job_lock where lock_name = 'schedule_lock' for update;
for update语法会给lock_name = schedule_lock的数据加上行锁,这是一个独占锁,所以,不管部署多少个节点,同一时间只可能有一个线程可以查出数据,其他线程都会被阻塞。
间隔多长时间查询一次数据库合适?
不间断的循环查询数据库可能会导致大量出现无效的查询(例如:每次都查不到结果,但还是一直查),这不是一种很好的方式,一般我们在循环扫描数据库时,都会加上一个间隔时间。
XXL-JOB对间隔时间的定义分别是,1s 和 5s,我们先看一下实现的代码:
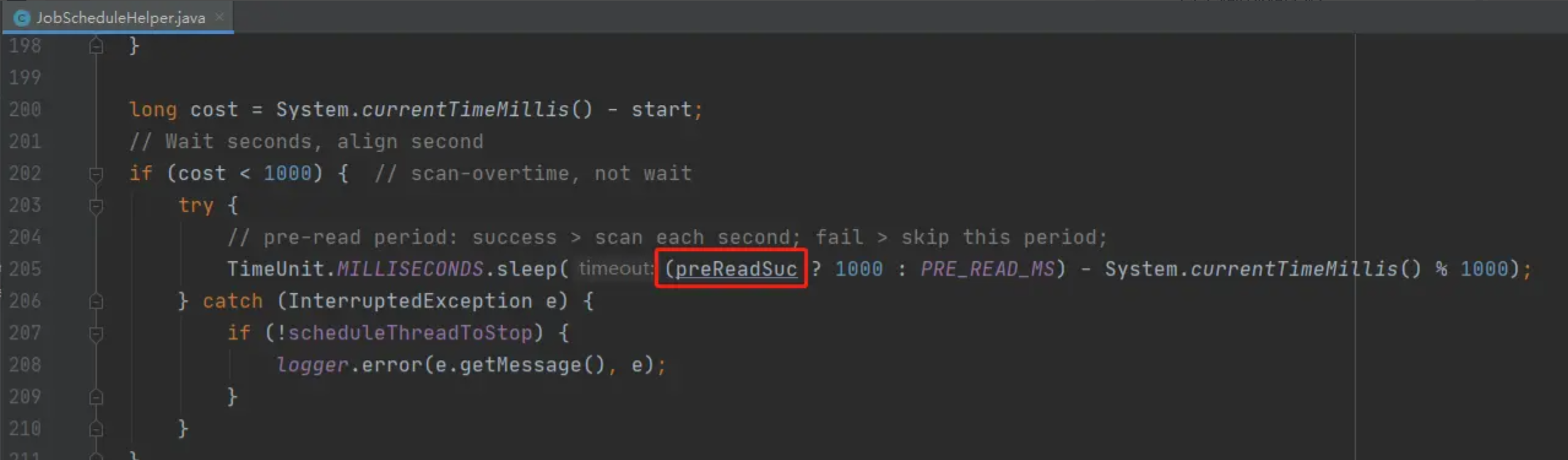
图中的preReadSuc:是一个boolean值,当有查询出了可调度的定时任务时,值为true,反之为false。
也就是说,如果执行了调度且调度时间小于1s时,就会等待1s再执行下一次循环,如果没有执行调度,则等待5s。至于为什么是5s,是因为在查询出定时任务配置后,还通过5s这个时间段,做了一个触发时机的判断,达到一个既不影响任务触发,又能降低数据库查询次数的平衡。
图中还有一个System.currentTimeMillis() % 1000,猜测这个代码的目的是让不同节点的睡眠时间分散一点,避免集中触发。
现在已经查询出了定时任务列表,由查询方式决定了不是列表中的每个任务都应该触发,所以对查询出的列表还需要做一次触发时机的计算。
2.2.计算任务触发时机
在任务触发时机的计算中,还会用到常量PRE_READ_MS,通过这个常量的值5s,XXL-JOB将查询出的任务列表数据划分为三个部分:
- 已超时5s以上
- 已超时但不足5s
- 还未到触发时间
由于当前时间nowTime已经固定,而每个任务的触发时间可能会不一样,以触发时间来做一个时间轴,就可以用图示直观的表示这三个部分的数据,如下图:
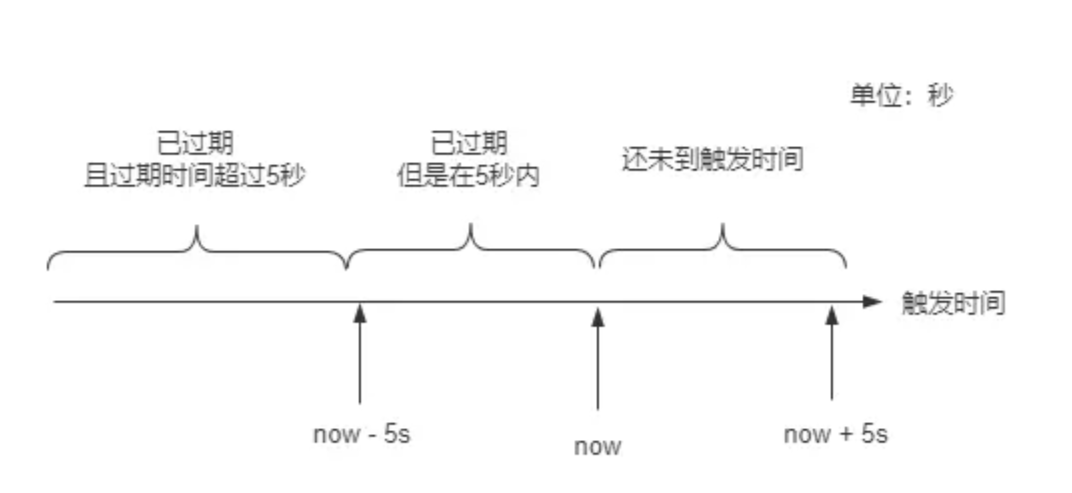
这里的触发时间,就是上面提到的 xxl_job_info 表中 trigger_next_time 字段值,接下来可以看看这几个部分,分别做了什么处理。
2.2.1.已超时5秒以上
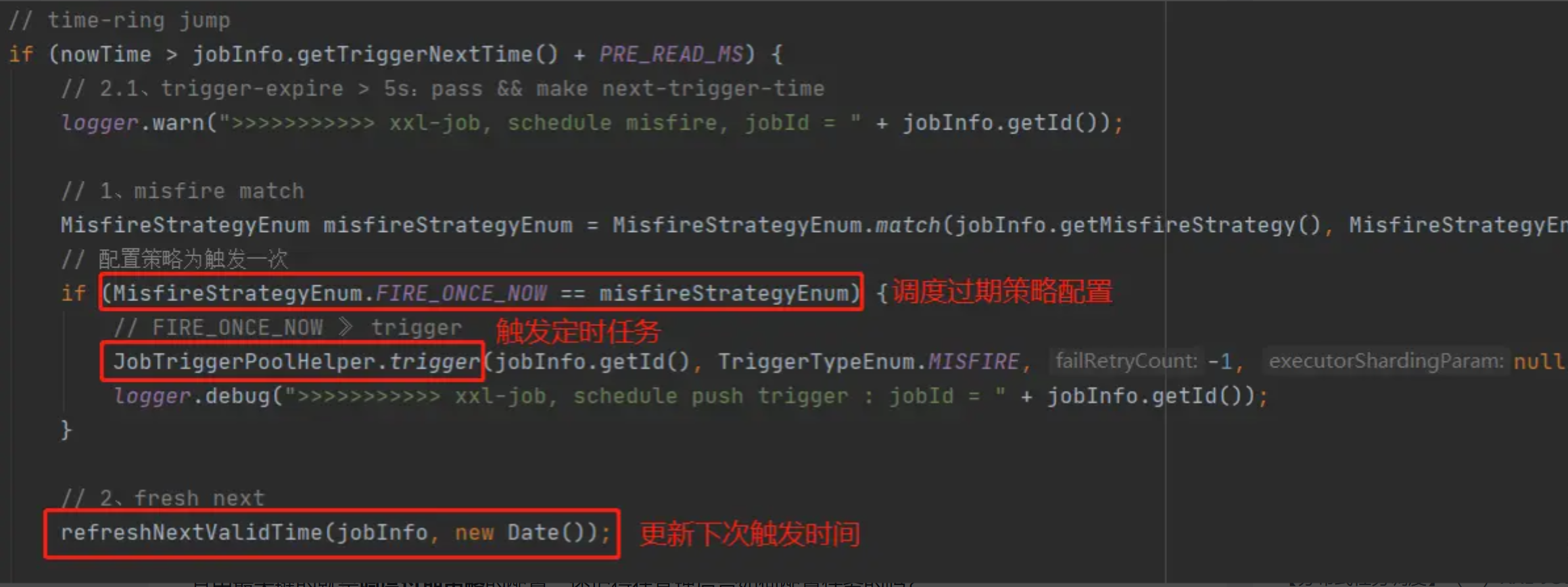
图中的代码块对应就是已超时5秒以上的数据,if条件转换一下就是now - 5s > 触发时间。
其中最关键的就是调度过期策略的配置,还记得在管理后台如何配置任务的吗?
这里有有两种不同的执行流程,默认情况下的调度过期策略是忽略,已经超时5秒以上的任务会被丢弃掉,另外一种策略是立即执行一次,就是字面意思,立即触发一次任务调度。
此外,trigger方法和refreshNextValidTime方法分别对应任务触发和更新下次触发时间,在另外两个部分还会使用到。
2.2.2.超时未超过5秒
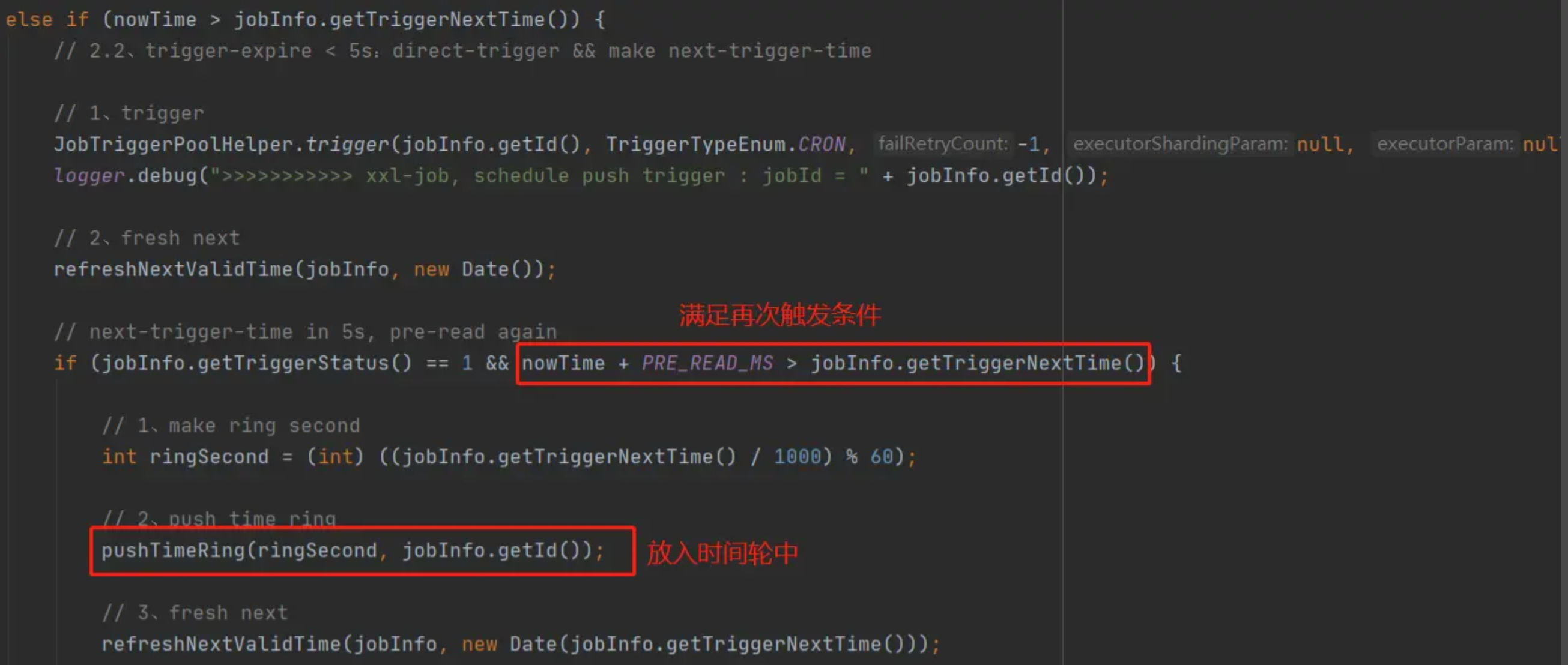
按照当前对数据库的查询方式,这部分定时任务就是最应该直接触发的,此处会立即触发一次,并更新下次触发时间。此外,如果发现在5秒内会再次触发,还会将这个任务直接放入到时间轮中,由时间轮来进行下一次调度。
2.2.3.还未到触发时间
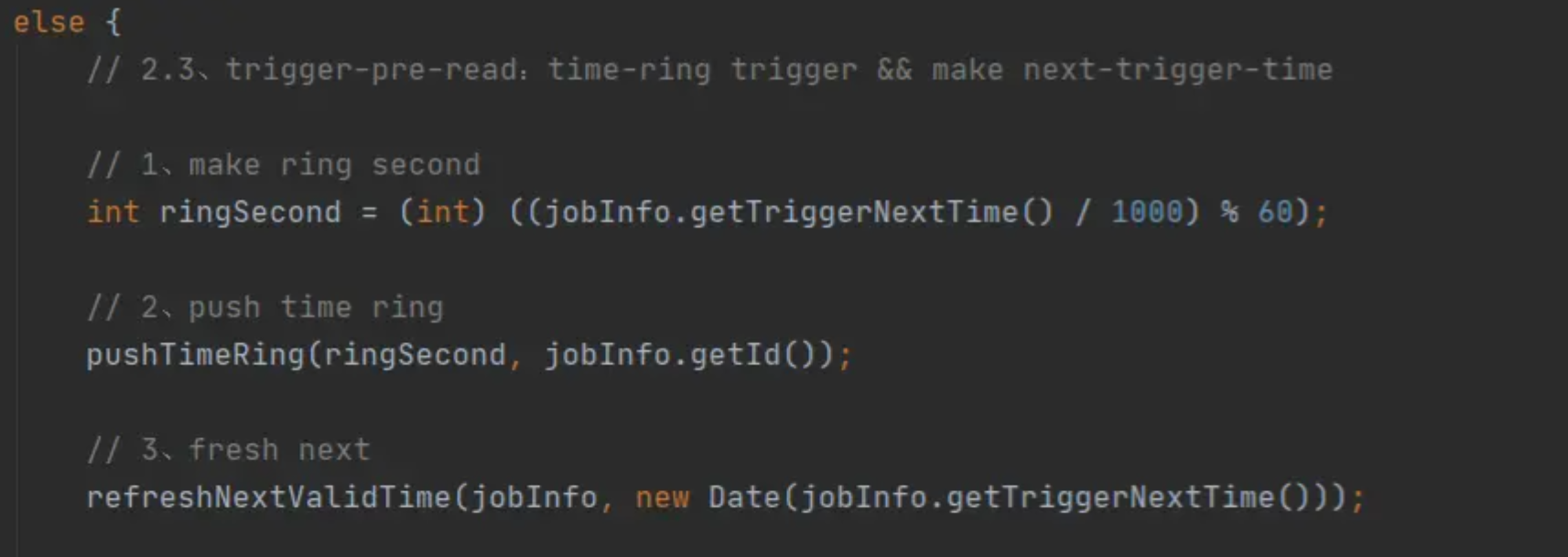
可以看到这个代码和上面放入时间轮的代码一模一样,都是将未来5s会触发的定时任务放入到了时间轮中,本篇到现在已经多次提到了时间轮,它到底是个什么东西呢?
接下来就简单聊一下XXL-JOB中使用的时间轮。
时间轮是一种用于实现定时器、延时调度等功能的算法,广泛的运用于各种中间件中,例如:Netty、Kafka、Dubbo等,在XXL-JOB中,实现方式非常简单,通过一个HashMap来实现的,具体的做法是:
先获取到triggerNextTime的值,这是一个时间戳,通过下面的算法可以获取到这个时间戳对应的秒数,在0-59之间。
// [0,59]
int ringSecond = (int) ((jobInfo.getTriggerNextTime() / 1000) % 60);
然后 以 ringSecond 为key,jobId(任务Id)为value,put到HashMap中。
private volatile static Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>();
private void pushTimeRing(int ringSecond, int jobId){
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
}
下面是从百度图片中找到的一张时间轮的图片,这张图片很形象的展示了时间轮的数据结构。
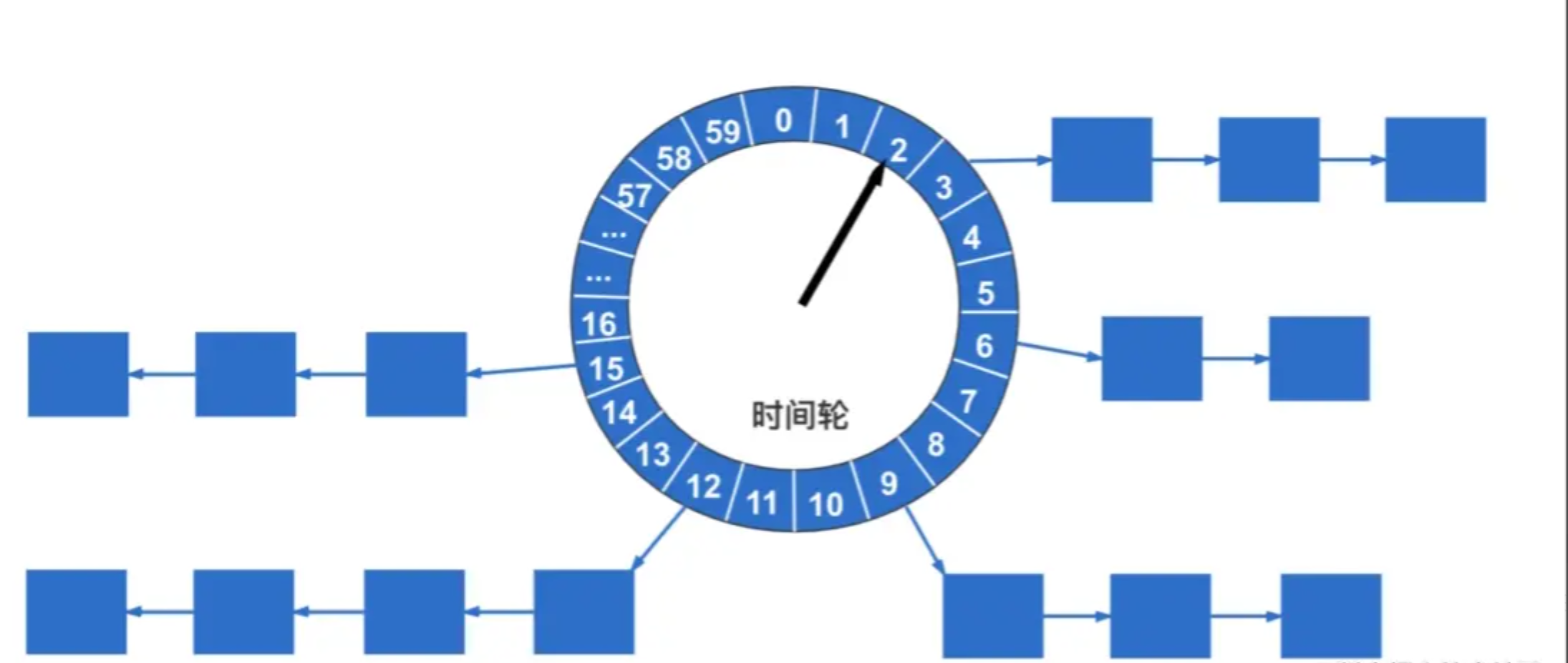
图中的数组代表的是秒数,链表代表的是这一秒钟有多少任务需要执行。
剥开时间轮神秘的面纱,其实实现起来非常的简单,当然XXL-JOB中的时间轮算法只是一种最简单的运用,由于本篇并不是在讲时间轮算法,如果想详细的了解时间轮算法,可以百度一下,有非常多的资料。
接下来就该时间轮线程登场了,即ringThread,除了上述的两种在scheduleThread直接触发的任务外,其他的任务都是通过时间轮线程来触发的,下面为实现代码:
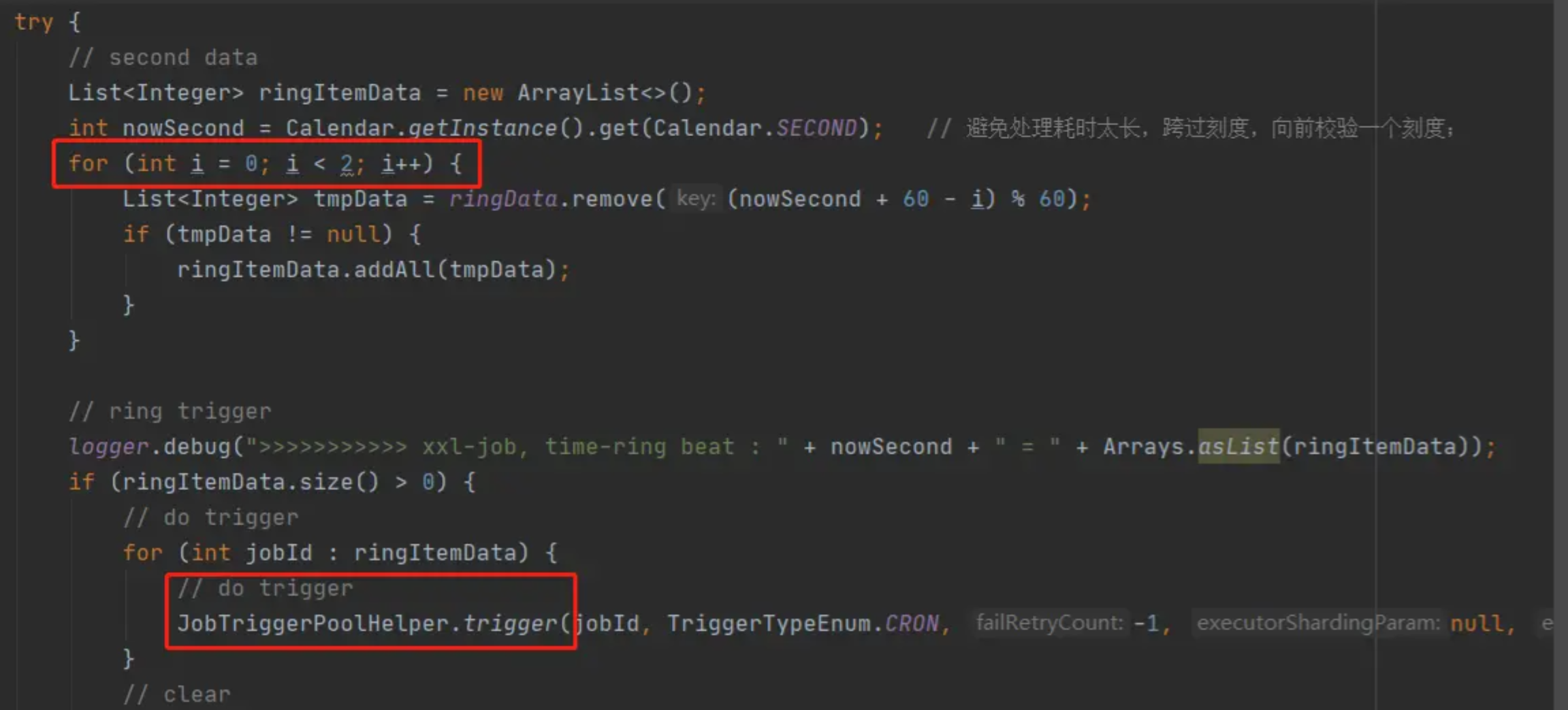
先获取到当前时间的秒数,然后从时间轮中取出当前秒和前一秒的所有任务,循环ringItemData,依次触发其中的每一个任务。为什么需要获取前一秒的数据,作者在注释中已经解释了,就不多做赘述了。
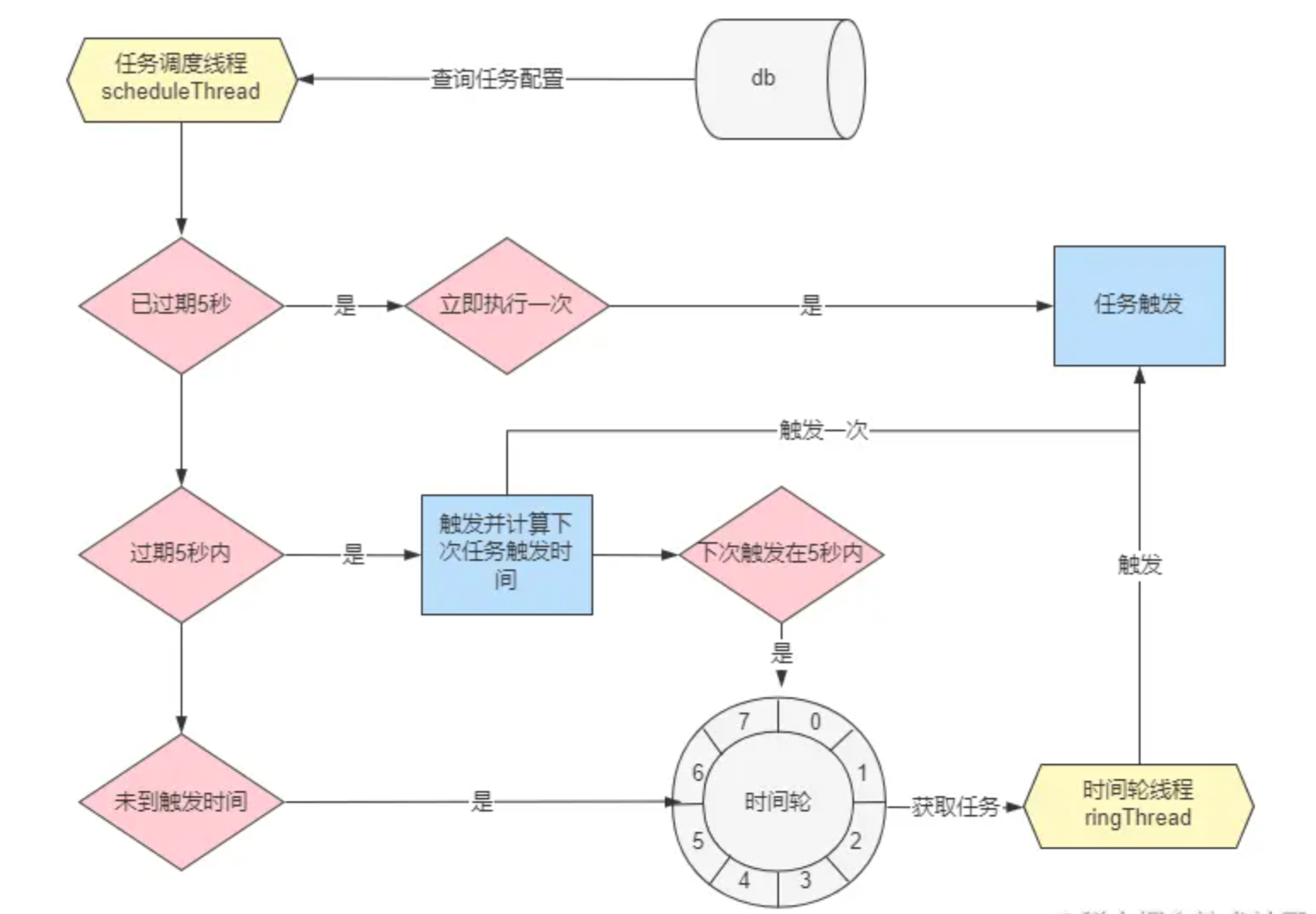
至此,定时任务的查询和触发时机的计算过程就完结了,下面一张这部分的流程图。
2.3.任务触发流程
在上面的代码中,我们看到JobTriggerPoolHelper.trigger()一共出现了3次,把这三次调用放在一起对比一下:
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.MISFIRE, -1, null, null, null);
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
可以看到,在任务调度的流程中,只需要关注3个关键字段:

- jobId:定时任务配置id,用于查询定时任务配置。
- triggerType:定时任务的触发类型,用于记录日志。
- failRetryCount:失败重试次数,这里传入-1,表示使用定时任务配置中的重试次数。
这行代码的意思就是将应该触发的定时任务,放入任务触发线程池中。
后面三个参数会在什么时候用到呢?
我们配置的定时任务,除了等待到指定时间触发以外,有时候也需要手动触发,在管理后台提供了任务的手动触发功能。
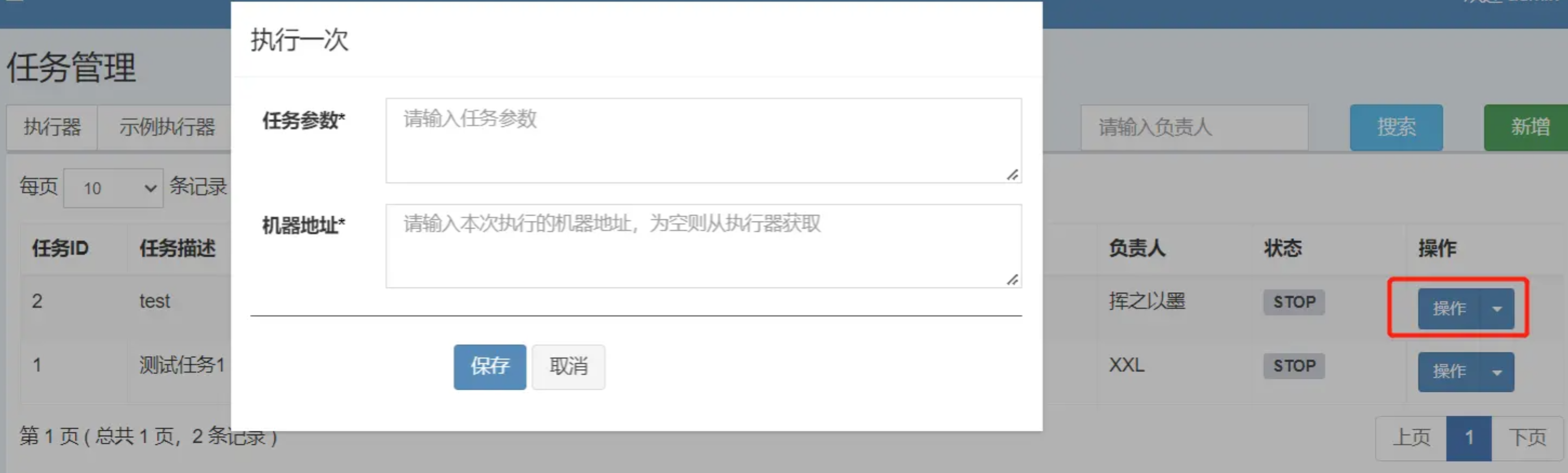
图中的任务参数 和 机器地址对应的就是参数列表中的executorParam和addressList。剩下的executorShardingParam要特殊一点,只有在使用分片广播这个路由策略,且失败重试次数大于0时才有可能使用到。
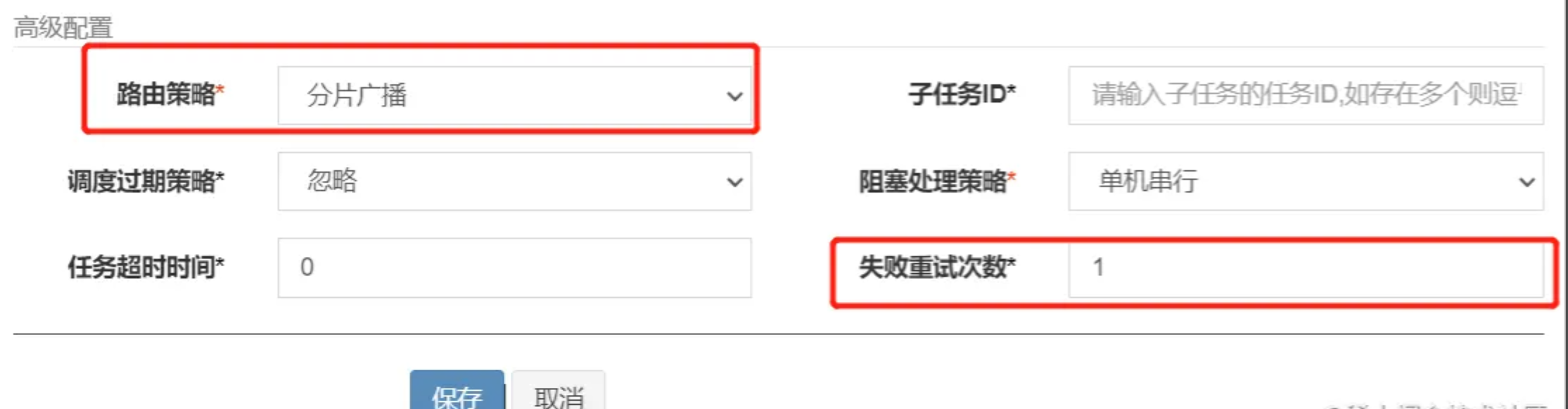
参数是由这个路由策略生成的,并在发起调度请求时保存到任务日志中,重试的时候会查询出来使用。
2.3.1.任务触发线程池
触发线程池其实在前面已经提到过了,有两种线程池fastTriggerPool与slowTriggerPool,初始化的方式也非常简单,就是按照配置文件中配置的线程池大小创建线程池就OK了。
为什么会有快慢两种线程池呢?
主要是为了做一个线程池的隔离,将正常执行的任务放入到fastTriggerPool中,将执行偏慢的任务放到slowTriggerPool中,避免执行较慢的任务占用过多资源,影响到了其他正常任务的调度。
什么样的任务算作是慢任务?
在程序中使用ConcurrentHashMap维护了一个计数器,key为jobId,value为超时次数,当任务触发时间超过500ms时,超时次数 + 1,同一个任务在1分钟内超时超过了10次,这个任务就会被定义为慢任务,后续就会由slowTriggerPool来进行调度。
后续通过helper.addTrigger,就会从线程池中获取一个线程,执行任务触发操作,在做实际的触发操作之前,还需要处理一下传入的参数。
2.3.2.参数处理
这个步骤的代码很多,这里就不大篇幅的贴代码截图了,通过文件描述的形式,来描述一下流程。
第一步:使用jobId查询出数据库中的定时任务配置,后续的流程以此为基础。
第二步:如果传入的执行参数executorParam,则优先使用传入的,反之使用任务配置中的参数。
第三步:计算失败重试次数,如果传入的是-1,则使用任务配置中的失败重试次数。
finalFailRetryCount = failRetryCount >= 0 ? failRetryCount : jobInfo.getExecutorFailRetryCount();
第四步:如果传入了执行器地址,则以传入的为准,反之使用注册中心中的执行器地址。
第五步:如果传入了分片参数executorShardingParam则直接使用。
参数处理完成之后就会进入到执行流程,在执行流程中分片广播这个特殊的路由策略会做特殊的处理,如果是这个策略,会将注册中心中,同一个定时任务对应的所有执行器节点都调用一遍,我们可以后面再聊这个策略,先看非分片广播策略的处理方式。
2.3.3.任务触发
这一步是对执行器的实际调用方法,有两个需要注意的点:阻塞策略 和 路由策略的处理。
先说阻塞策略,XXL-JOB提供的阻塞策略一共有三种:
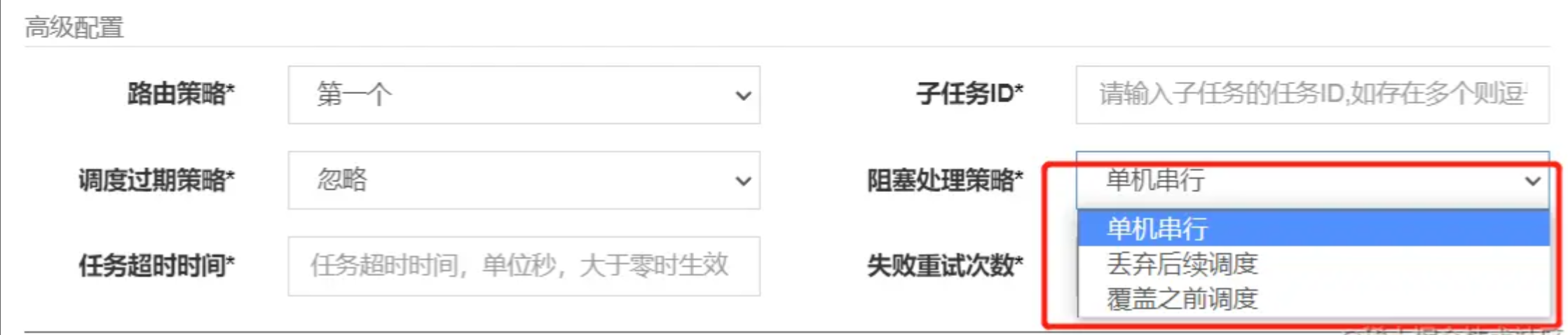
这里会获取到任务配置中的阻塞策略,封装到调用参数中发送给执行器,执行器会按照传入的策略进行处理,这个在下面的执行器部分会详聊。
至于路由策略,当执行器部署为集群节点时,才会发挥作用,XXL-JOB提供了如下路由策略:
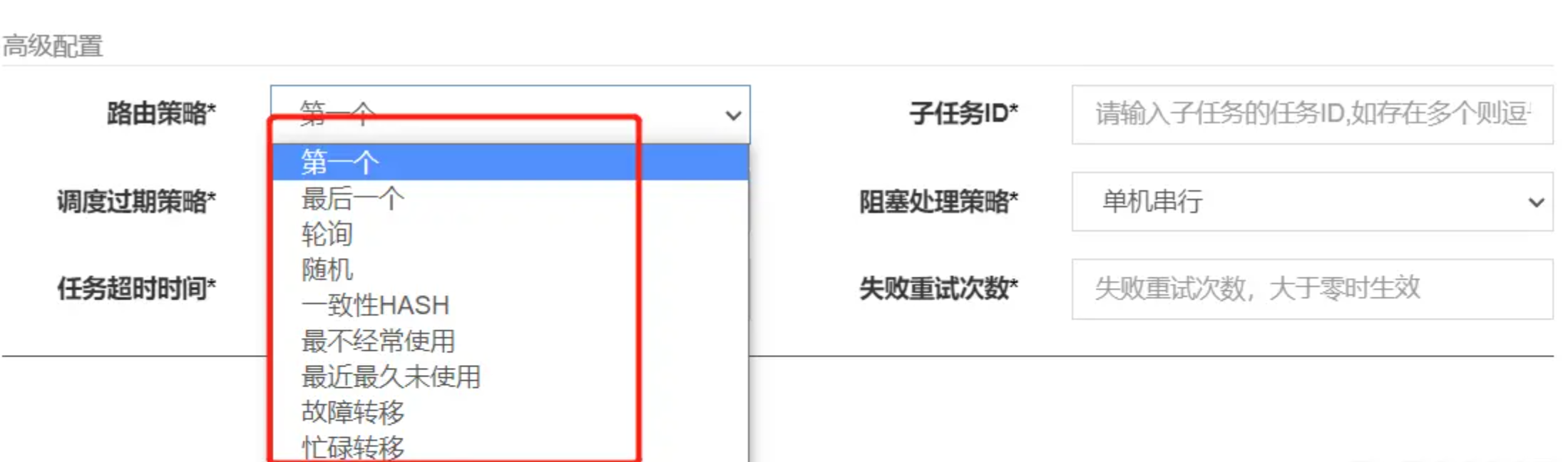
除了分片广播外,其他路由的作用,都是从执行器的集群节点中,获取其中一个节点来进行调用,通过下面的接口发起HTTP请求。

最后,会收到执行器响应的调用结果,保存到日志表中。
2.3.4.分片广播策略(补充)
用一张图来描述分片广播:
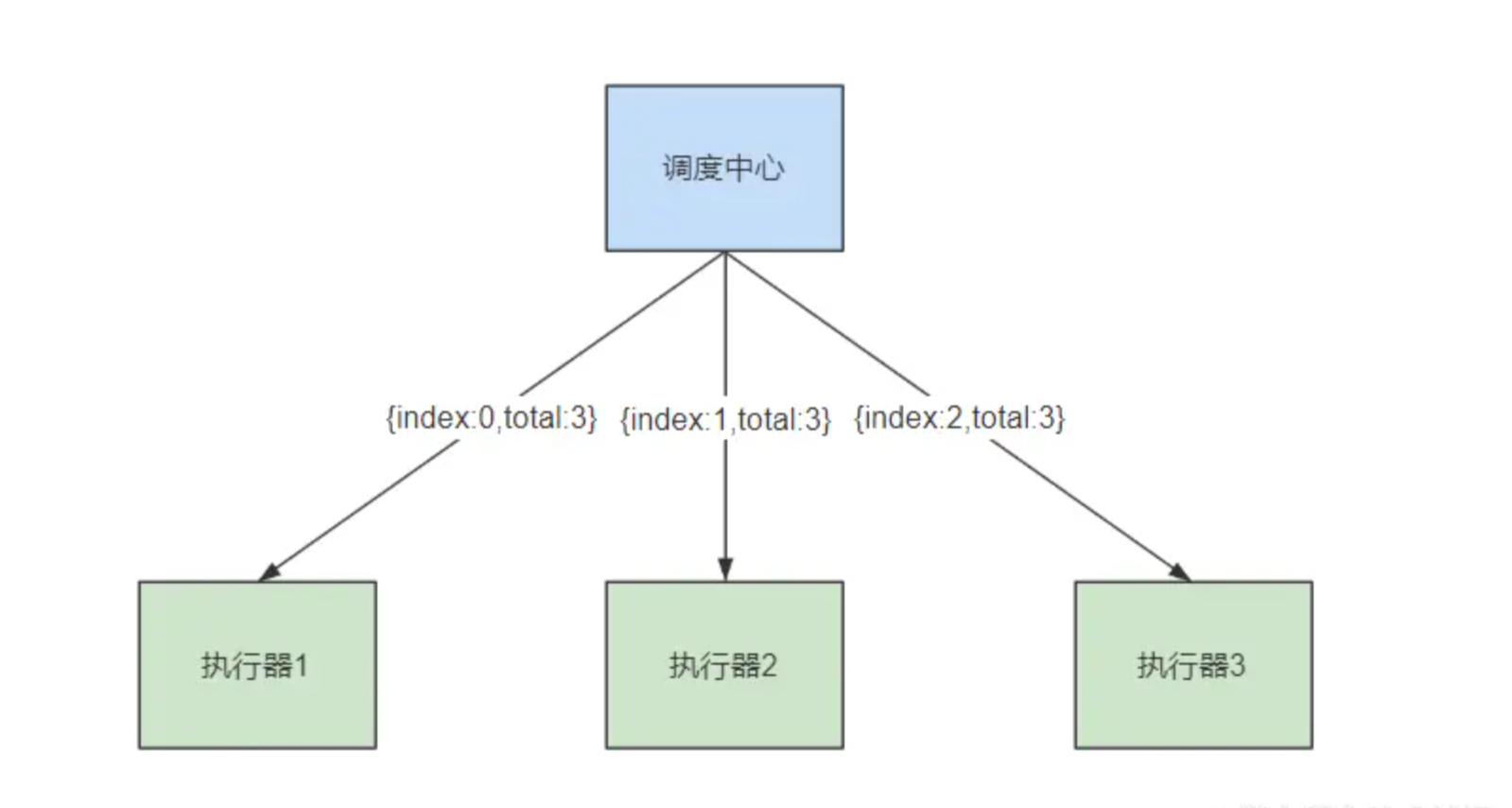
调度中心会向当前任务的所有执行器节点都发起一个调度请求,并且带上分片参数。执行器在收到请求之后,可以通过index的值,以不同index的值来做分片策略。
在官方示例中,有分片广播的用法,可以参考:
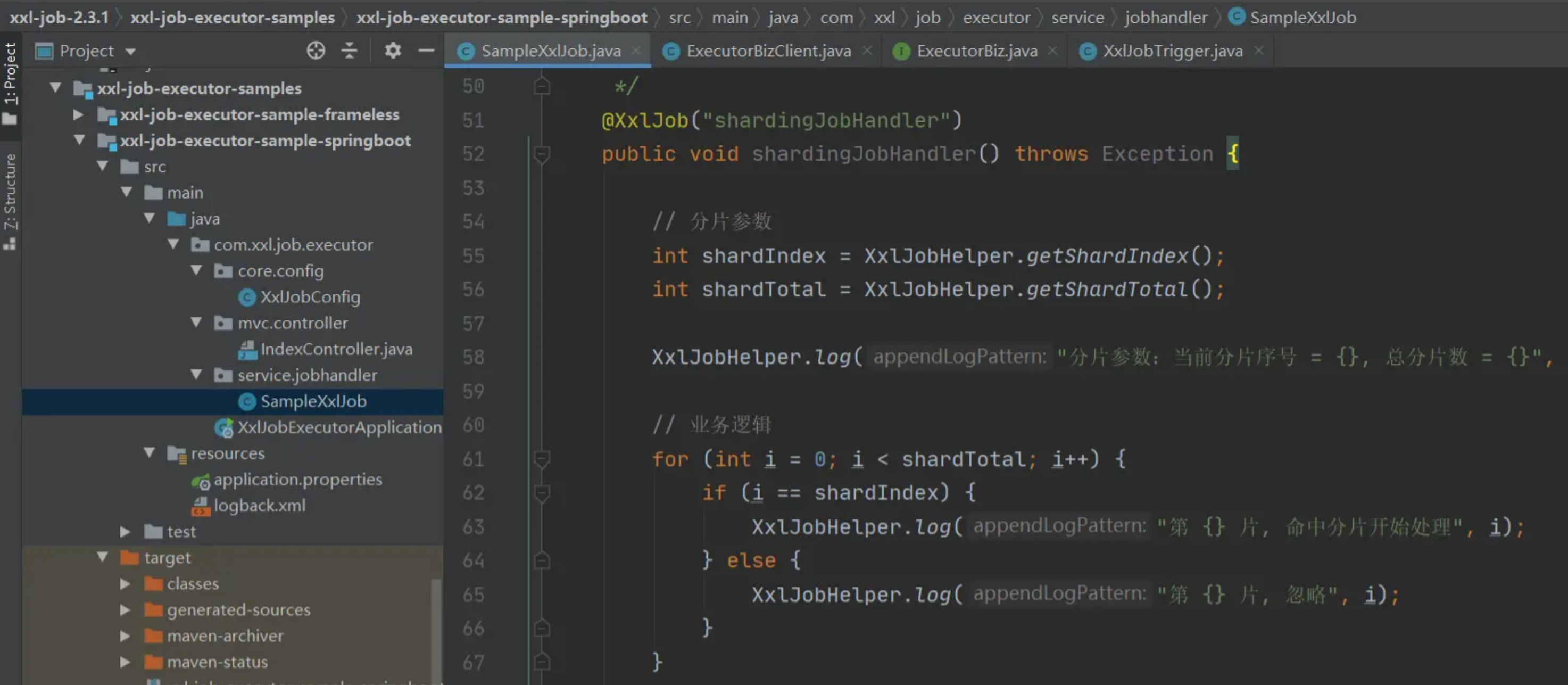
至此,调度中心的调度流程就已经结束了,流程图更新为:
接下来就等待执行器回调,获取任务执行结果。
3.执行器流程
由于本系列文章中的相关配置都是以SpringBoot为基础来创建的,所以这里只分析Bean模式的执行器。当执行器通过NettyServer收到调度请求后,会通过调度请求中传入的参数executorHandler来选择任务处理器。
什么是任务处理器呢?
就是实际执行任务的方法,我们创建一个定时任务需要在两处配置任务处理器:管理后台 和方法注解,两处填写一样的处理器名称。

一般情况下,方法使用注解标注后,都会在服务启动的时候将注解信息集中管理起来,例如这里就会将@XxlJob的注解信息,及其所在的Bean和Method存入一个CurrentHashMap中。
3.1.任务处理器初始化
Spring提供了一个扩展点,在bean对象初始化完成之后,做一些额外的操作,这里只需要实现SmartInitializingSingleton的接口afterSingletonsInstantiated方法,然后在这个方法中,扫描每一个bean对象,找到被@XxlJob标记的方法,就可以获取到每一个任务处理器与它所在的bean对象、方法之间的对应关系。
以上图中的demoJobHandler为例,初始化流程会先将sampleXxlJob对象与demoJobHandler方法封装到一个实体对象MethodJobHandler中。
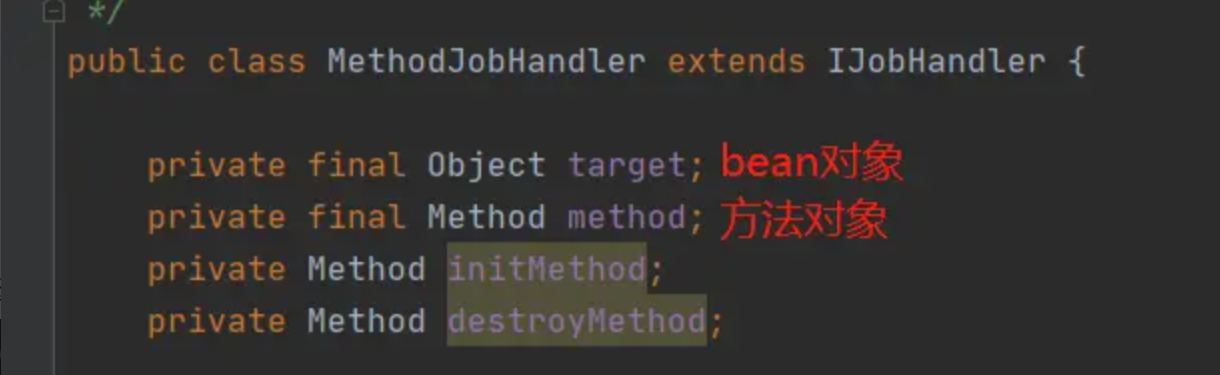
然后,以@XxlJob注解中的value为key,MethodJobHandler为value,保存到Map中

在任务处理的流程中,只需以调度请求中的任务处理器参数为key,就可以获取到任务处理器对象了。
3.2.执行器任务处理流程
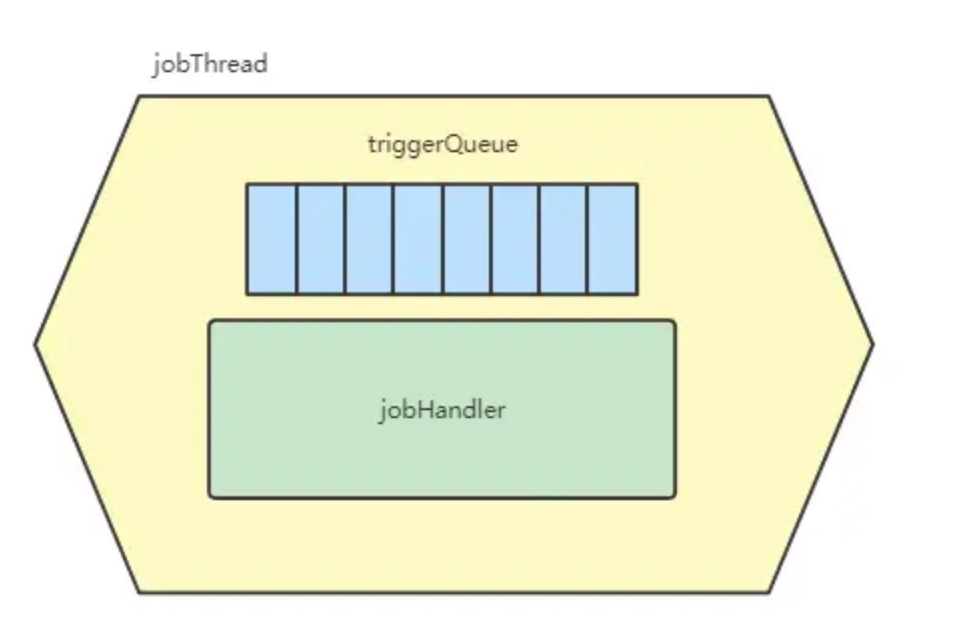
XXL-JOB给每一个任务处理器都分配了一个单独的线程来做任务处理,这么做的好处是,任务之间是隔离的,互不影响。之所以可以这么做,是因为架构设计中将定时任务执行器内聚到每个业务中,从而一个服务所需要的定时任务数量(线程数)并不会太多。
同时,还给每个定时任务都提供了一个队列,用于处理那种 前一个任务还没执行完,后一个任务又被调度过来了 的情况。
就是下图中的结构:
3.2.1.jobThread创建
和jobHandler不一样的是,jobThread不是在执行器初始化的时候创建的,而是在执行器接收到调度请求时,判断当前jobId有没有已经生成的jobThread,如果没有则会创建一个放入CurrentHashMap中。
之所以使用这个即时创建的方式,是因为我们有可能会在后台配置中切换运行模式:
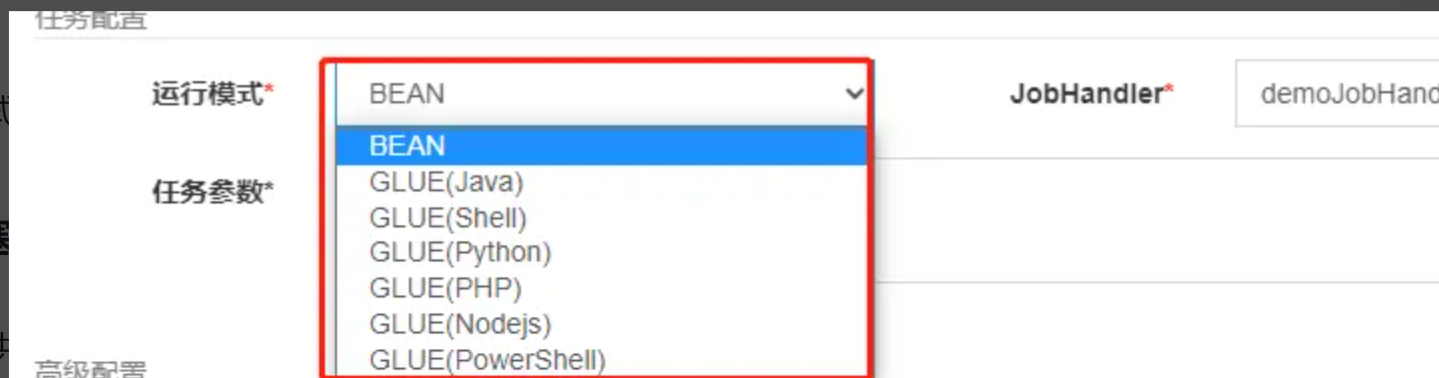
每种运行模式切换后对用的jobHandler是不一样的,所以jobThread也需要重新生成。
3.2.2.阻塞策略判断
XXL-JOB提供了三种阻塞策略,分别是:
- 单机串行:前一个任务还没有执行完毕,就等前一个任务执行完再执行当次的任务
- 丢弃后续调度:前一个任务没有执行完毕,就终止当次任务。
- 覆盖之前调度:不管前一个任务有没有执行完毕,都直接执行当次任务。
需要注意的是,当前定时任务是第一次被调度时,不会触发阻塞策略,其实也很好理解,第一次被调用时,会创建一个新的jobThread,triggerQueue里面肯定是空的,就没有触发阻塞策略的必要。
对于三种策略的实现方式,也很简单:
- 单机串行:将当次请求直接push到triggerQueue中。
- 丢弃后续调度:如果triggerQueue中还有正在执行的任务,则不将本次请求放入到队列中。
- 覆盖之前调度:重新创建一个jobThread执行任务,先前的线程会在执行完毕后,被下一次GC回收。
3.2.3.任务执行
triggerQueue的类型是LinkedBlockingQueue,是一种阻塞队列,根据阻塞队列的特性,使用poll()方法获取队列头的任务,如果队列为空后,当前线程会被阻塞,直到有新的任务push到队列中才会唤醒线程。
所以,只需要在jobThread的run()方法中,通过一个循环来获取队列中的任务即可。
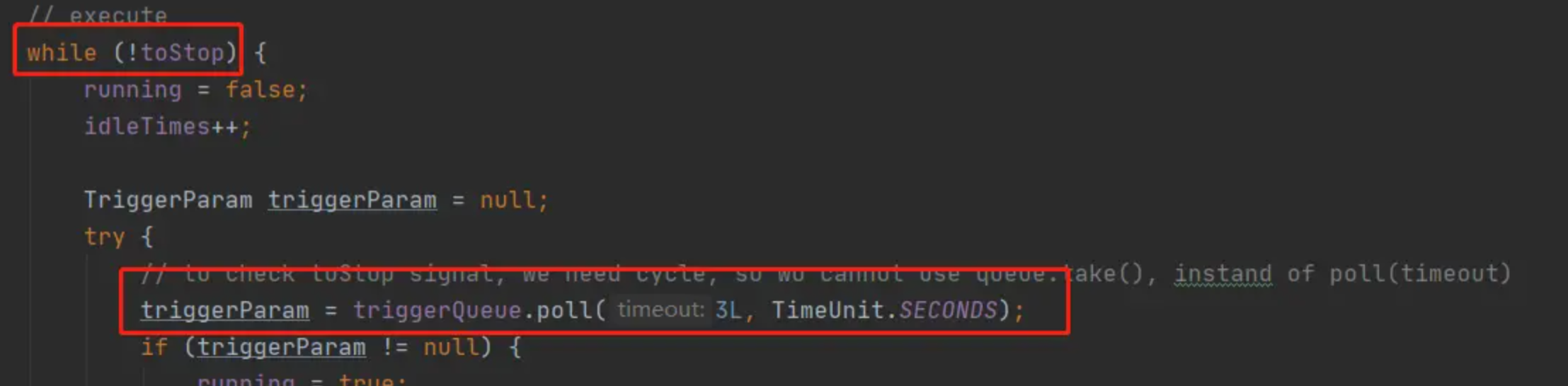
获取到triggerParam,表示有新的调度请求,这时候会先通过triggerParam中的值,打印一个请求日志,然后请求就会通过jobThread中引用的jobHandler执行方法的调用。
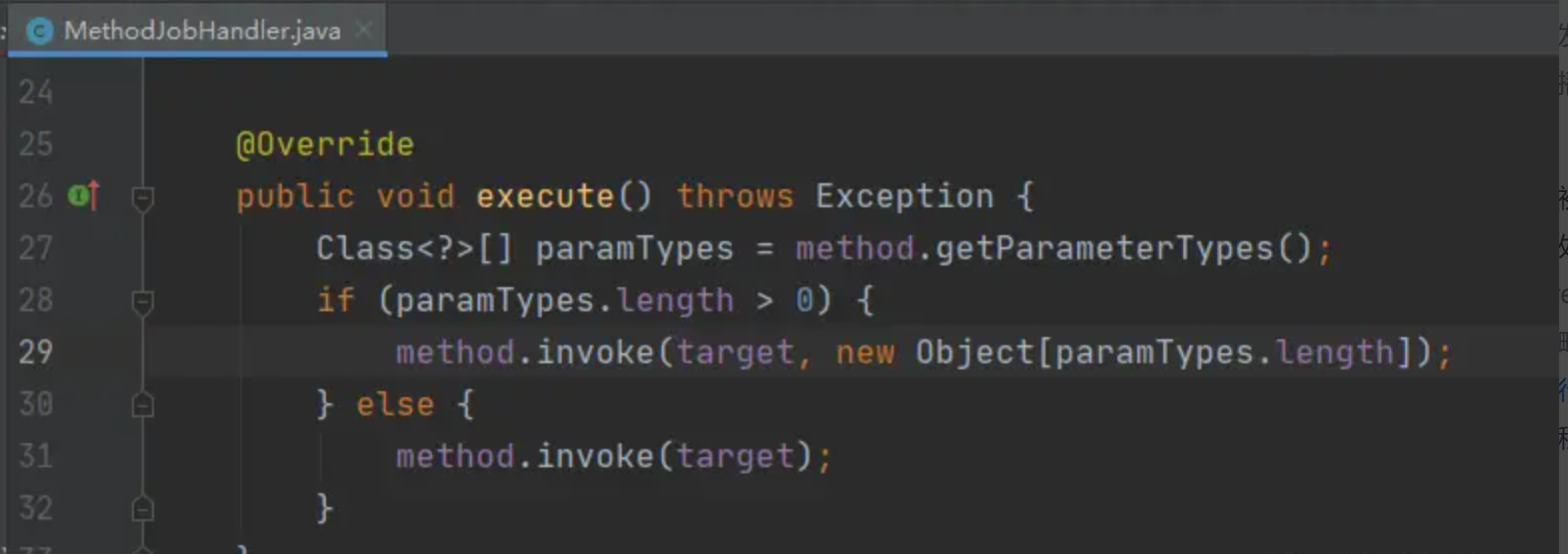
可以看到,是一个很常见的方法反射调用方式。
triggerParam还有其他的作用吗?
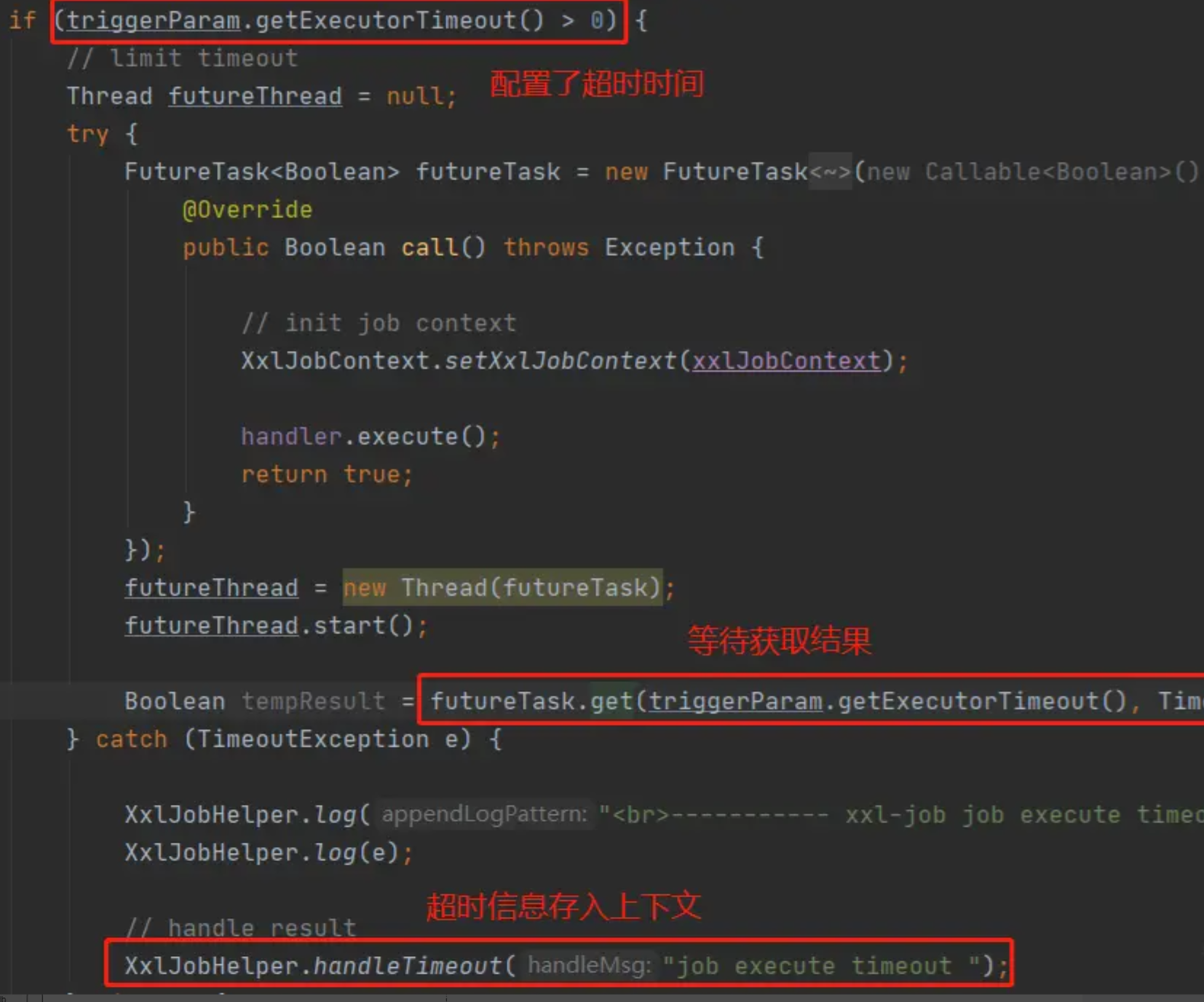
我们在管理后面创建定时任务的时候,有一个超时时间的配置:
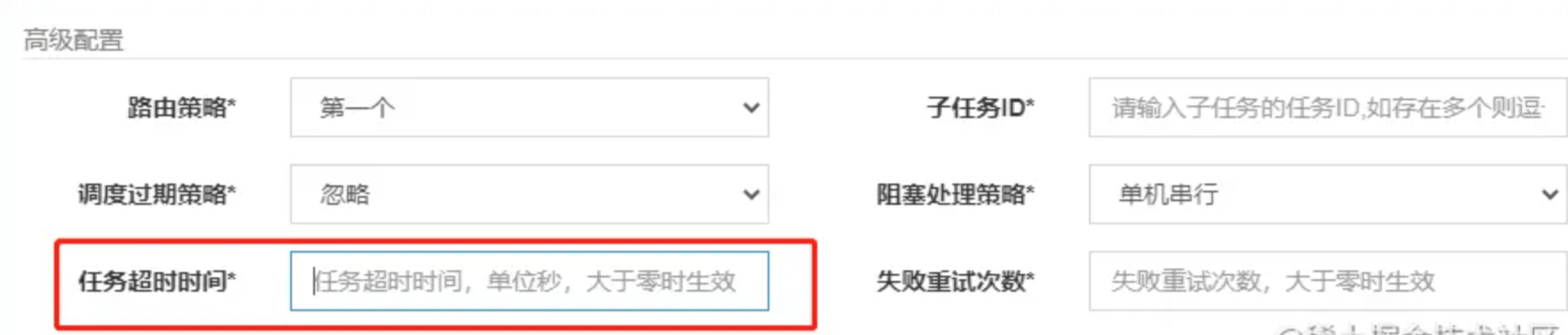
如果这个配置有值的话,就不会直接使用当前线程来执行方法调用,而是通过一个futureTask来做异步调用,在get()方法中传入超时时间,如果超过了配置的超时时间都没有收到返回值,则会抛出TimeoutException。外层业务捕获超时异常后,会将超时信息封装到上下文中,供后续回调流程使用。

3.3.任务回调流程
回调流程也是异步处理的,不管任务是否执行成功,最终都将上下文信息xxlJobContext被push到回调队列callBackQueue中,回调线程triggerCallbackThread会从队列中获取到回调信息,通过callback方法回调调度中心,这个流程与上面的任务执行流程是非常类似的,它们的区别在于回调线程对象是单例的,只会存在一个(想想为什么)。
执行器最终会调用回调的Http接口,将信息传回调度中心。

调度中心在获取到回到的信息之后,通过callbackThreadPool对回调请求做异步处理,更新日志中的调用结果。(所以执行器的回调线程只做了一个远程调用操作,不等待后续流程,一个完全够用了)。
至此,一次任务调度触发定时任务执行的流程就结束了。
4.结语
现在再回想一下开篇提出的那些问题,是否已经有了答案了呢?尝试一下回答吧。
调度中心需要解决的问题:
- 调度中心集群是否会产生重复调度问题?
- 间隔多长时间查询一次数据库合适?
- 如何判断任务已经到了触发时间?
- 如果查询出的任务,已经过了触发时间了怎么办?
- 如何获取执行器?
- 有多个执行器怎么处理呢?
- 任务执行时间过长,阻塞其他任务执行怎么处理?
- ……
执行器需要解决的问题:
- 如果前一个任务没有执行完,后一个任务又来了,怎么处理?
- 一个执行器中有多个任务时,如何找到当前应该执行的任务?
- 多个任务之间如何避免互相影响?
- 任务执行超时如何处理?
- ……
异步实践
XXL-JOB的调度流程中使用了大量的异步用法,总结起来就是两种:
- 通过线程池来执行异步操作
- 通过自旋线程 + 阻塞队列的方式来执行异步操作
源码中对多线程的使用方式是一种非常好的示例,我们完全可以参照这里的源码,在自己的项目里面实现异步调度。
调度流程
XXL-JOB调度流程的思想是比较容易理解的,整个流程看起来很舒服。
- 获取任务:调度线程不断的扫描任务表,查询出将要执行的任务。
- 前置处理:对每一个任务都做一次触发时间的计算,能够立即触发的就立即触发,不能立即触发的就放在时间轮中触发,不能触发的就抛弃掉。
- 路由策略:在执行器集群中选择一个节点执行定时任务。
- 触发任务:调度线程不断的从时间轮中获取任务并触发。
- 异步调度:调度中心将调度与触发做了异步处理,使用触发线程池来做Http调用。
- 阻塞策略:根据阻塞策略判断当前的调用请求是否执行。
- 任务执行:执行器为每个任务都分配了一个线程,自己处理自己的任务,任务之间不会互相影响。
- 任务回调:将执行结果回传到调度中心中,更新任务执行状态。
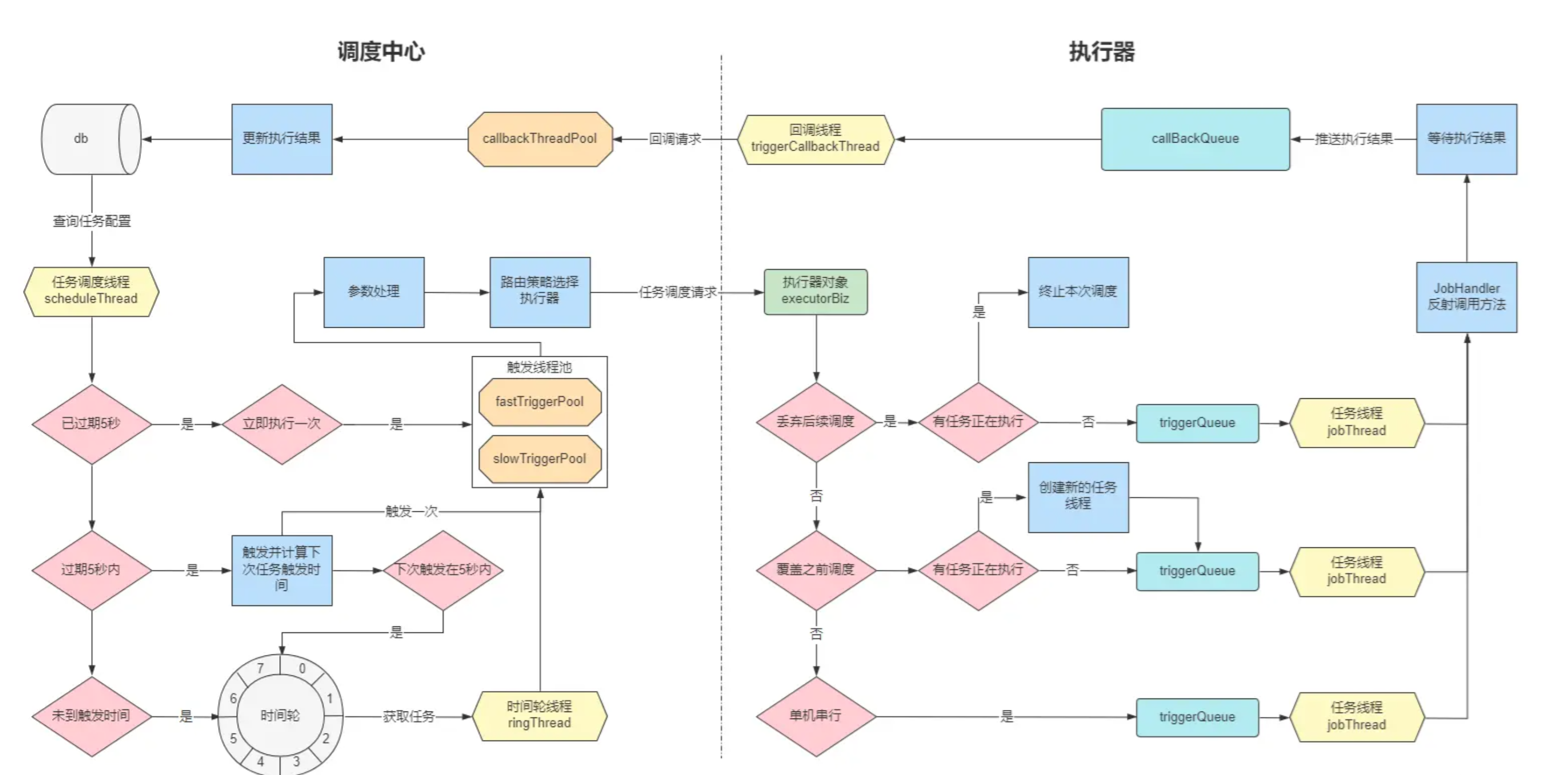
最后,再附上一张完整的流程图:
如果觉得本文对你有所帮助,可以帮忙点点赞哦!你的支持是我更新最大的动力!