cut
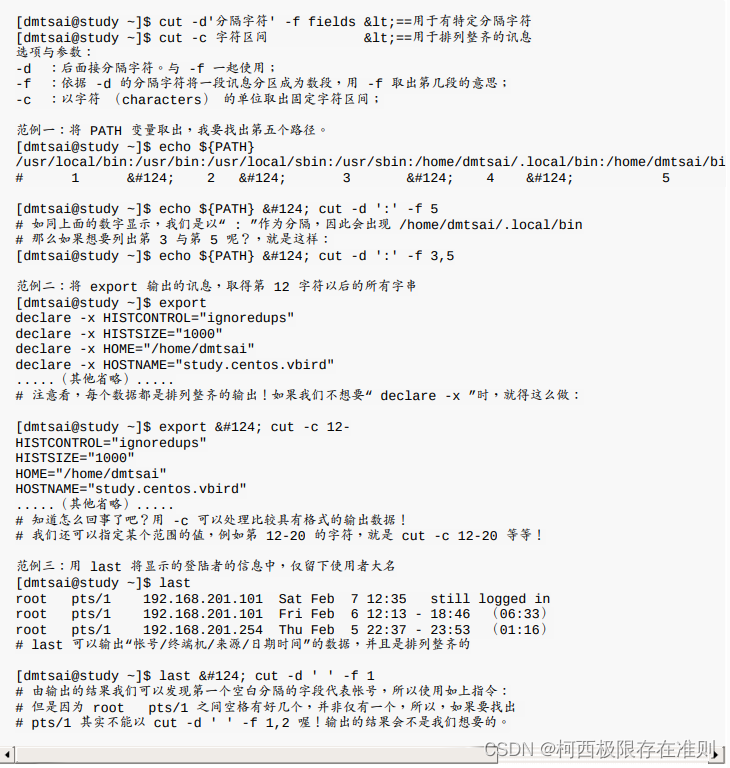
cut 主要的用途在于将“同一行里面的数据进行分解!”最常使用在分析一些数据或文字数据的时候。这是因为有时候我们会以某些字符当作分区的参数,然后来将数据加以切割,以取得我们所需要的数据。
grep

10.6.2 排序命令: sort, wc, uniq
很多时候,我们都会去计算一次数据里头的相同型态的数据总数,举例来说, 使用 last 可以查得系统上面有登陆主机者的身份。
sort 是很有趣的指令,他可以帮我们进行排序,而且可以依据不同的数据型态来排序。例如数字与文字的排序就不一样。此外,排序的字符与语系的编码有关。

uniq
如果我排序完成了,想要将重复的数据仅列出一个显示,可以怎么做呢?

这个指令用来将“重复的行删除掉只显示一个”,举个例子来说, 你要知道这个月份登陆你主机的使用者有谁,而不在乎他的登陆次数,那么就使用上面的范例, (1)先将所有的数据列出;(2)再将人名独立出来;(3)经过排序;(4)只显示一个! 由于这个指令是在将重复的东西减少,所以当然需要“配合排序过的文件”来处理。
wc
如果我想要知道 /etc/man_db.conf 这个文件里面有多少字?多少行?多少字符的话, 可以利用 wc 这个指令来达成,他可以帮我们计算输出的讯息的整体数据!

10.6.3 双向重导向: tee

图10.6.2、tee 的工作流程示意图
tee 会同时将数据流分送到文件去与屏幕 (screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理。

tee 可以让 standard output 转存一份到文件内并将同样的数据继续送到屏幕去处理! 这样除了可以让我们同时分析一份数据并记录下来之外,还可以作为处理一份数据的中间暂存盘记录之用。