
论文题目:Time-Series Representation Learning via Temporal and Contextual Contrasting
论文地址:https://www.ijcai.org/proceedings/2021/0324.pdf
代码地址:GitHub - emadeldeen24/TS-TCC: [IJCAI-21] "Time-Series Representation Learning via Temporal and Contextual Contrasting"
摘要
从具有时间动态的未标记时间序列数据中学习合适的表示是一项非常具有挑战性的任务。在本文中,我们提出了一个通过时间和上下文对比(TS-TCC)的无监督时间序列表示学习框架,从未标记的数据中学习时间序列表示。首先,使用弱增强和强增强将原始时间序列数据转换为两个不同但相关的视图。其次,我们提出了一个新的时间对比模块,通过设计一个严格的跨视图预测任务来学习鲁棒的时间表征。最后,为了进一步学习判别表征,我们提出了一个基于时间对比模块的语境对比模块。它试图最大化相同样本的不同上下文之间的相似性,同时最小化不同样本的上下文之间的相似性。在三个真实的时间序列数据集上进行了实验。结果表明,在我们提出的TS-TCC学习的特征之上训练线性分类器的性能与监督训练相当。
此外,我们提出的TS-TCC在少标记数据和迁移学习场景下表现出很高的效率。该代码可在https://github.com/emadeldeen24/TS-TCC上公开获得。
创新点
-
在对比学习框架中为时间序列数据设计了简单而有效的增强。
-
提出了一个新的时间对比模块,通过设计一个严格的交叉视图预测任务,从时间序列数据中学习鲁棒表示。此外,我们提出了一个上下文对比模块,在鲁棒表示的基础上进一步学习判别表示。
-
使用三个数据集对我们提出的TSTCC框架进行了广泛的实验。实验结果表明,在监督学习、半监督学习和迁移学习设置下,学习表征对下游任务是有效的。
相关工作
自监督学习
-
MoCo [He et al ., 2020]利用动量编码器学习从记忆库中获得的负对的表示。
-
SimCLR [Chen et al ., 2020]通过使用更大量的负对来替代动量编码器。
-
BYOL [Grill等人,2020]即使不使用负样本,也可以通过自举表征来学习表征。
-
SimSiam [Chen and He, 2020]支持忽略负样本的想法,仅依靠Siamese网络和停止梯度操作来实现最先进的性能。
虽然所有这些方法都成功地改进了视觉数据的表示学习,但它们可能不适用于具有不同属性(如时间依赖性)的时间序列数据。
对于时间序列中的自监督学习,现有的方法要么使用时态特征,要么使用全局特征。
不同的是,我们首先通过设计特定于时间序列的增强来为输入数据构建不同的视图。此外,我们提出了一种新的跨视图时间和上下文对比模块,以改进对时间序列数据的学习表示。
模型框架
-
首先基于强增强和弱增强生成输入数据的两个不同但相关的视图。
-
然后,提出了时间对比模块,利用自回归模型探索数据的时间特征。这些模型通过使用一个视图的过去来预测另一个视图的未来,从而执行一项艰巨的跨视图预测任务。
-
通过上下文对比模块进一步最大化自回归模型上下文之间的一致性。
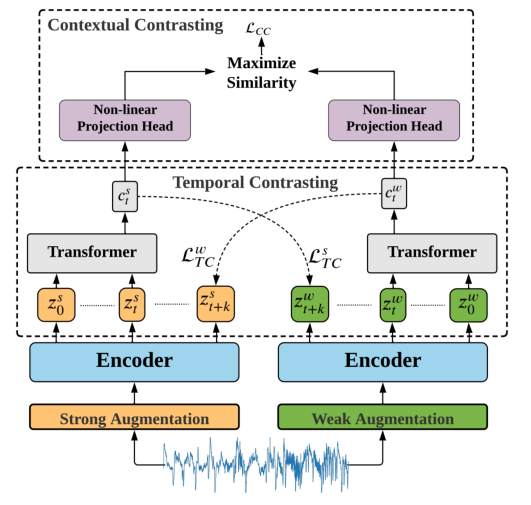
时间序列数据增强
通常,对比学习方法使用相同增强的两个(随机)变体。给定一个样本x,它们产生两个视图x1和x2,从相同的增广族T中采样,即x1 ~ T和x2 ~ T。
然而,我们认为使用不同的增强可以提高学习表征的鲁棒性。因此,我们建议应用两个单独的增广,这样一个增广是弱的,另一个是强的。在本文中,弱增强是一种抖动-规模策略。具体来说,我们在信号中加入随机变化,并按比例增大其幅度。对于强增强采用置换和抖动策略,其中置换包括将信号分成随机数目的片段,最大为M,并随机洗牌。接下来,将随机抖动添加到置换信号中。值得注意的是,应根据时间序列数据的性质仔细选择增广超参数。例如,在应用置换时,序列较长的时间序列数据的M值应该大于序列较短的时间序列数据的M值。类似地,归一化时间序列数据的抖动率应该远小于非归一化数据的抖动率。
编码器encoder
对于每个输入样本x,我们将其强增广视图表示为xs,将其弱增广视图表示为xw;然后将这些视图传递给编码器以提取它们的高维潜在表示。
编码器具有[Wang et al ., 2017]中提出的3块卷积架构。对于输入x,编码器将x映射为高维潜在表示z = fenc(x)。我们定义z = [z1, z2,…,zT],其中T为总时间步长。因此,我们得到zs表示强增强视图,zw表示弱增强视图,然后将其输入时间对比模块。
时间对比
时间对比模块使用自回归模型在潜在空间中使用对比损失来提取时间特征。
给定潜在表示 z ,自回归模型 f (Transformer结构)将所有 t时刻前的 z 归纳为上下文向量 ct = f (z),然后使用语境向量 ct 来预测从 z t+1 到 z t+k 的时间步长。为了预测未来的时间步长,使用对数双线性模型,该模型将保留输入x t+k和 ct 之间的互信息,使得
![]()
其中Wk是一个线性函数,它将 ct 映射回与 z 相同的维度。
强增强产生cst,弱增强产生cwt。我们提出了一个严格的交叉视图预测任务,通过使用强增强c st来预测弱增强z w t+k的未来时间步长,反之亦然。对比损失试图最小化同一样本的预测表示与真实表示之间的点积,同时最大化与小批量内其他样本Nt,k之间的点积。据此,我们计算两种损失如下:

使用Transformer作为自回归模型,主要由连续的多头注意块(MHA)组成,然后是一个MLP块。MLP块由两个完全连接的层组成,具有非线性ReLU函数和中间的dropout。我们的Transformer采用了能产生更稳定梯度的预范数剩余连接。我们堆叠L个相同的层来生成最终的特征。在输入中添加了一个 token,其状态在输出中充当代表性上下文向量。最后,从最终输出中取出添加的 token 作为上下文向量 ct,此上下文向量将是以下上下文对比模块的输入。

上下文对比
上下文对比模块,旨在学习更多的判别表征。它首先使用非线性投影头对上下文应用非线性变换,投影头将上下文映射到应用上下文对比的空间。
给定一批N个输入样本,我们将为每个样本的两个增强视图提供两个上下文,因此有2N个上下文。对于cit,我们将cit+表示为cit的正样本,该样本来自相同输入的另一个增广视图,因此,(cit, cit+)被认为是一个正对。同时,同一批次中其他输入的剩余(2N−2)个上下文被认为是cit的负样本,即cit可以与其负样本形成(2N−2)个负对。因此,我们可以推导出上下文对比损失,以最大化正对之间的相似性,最小化负对之间的相似性。因此,最终的表示可以是有区别的。

其中,sim计算的是余弦相似度。
整体损失
整体自我监督损失是两种时间对比损失和语境对比损失的组合,其中λ1和λ2是固定的标量超参数,表示每个损失的相对权重。
![]()
实验设置
数据集
采用了三个公开可用的数据集,分别用于人类活动识别HAR、睡眠阶段分类(Sleep-EDF)和癫痫发作预测(Epilepsy)。此外,我们还研究了我们学习到的特征在故障诊断数据集上的可转移性。
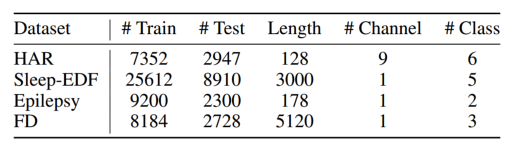
实验参数
数据分成60%,20%,20%用于训练,验证和测试,并考虑对Sleep-EDF数据集进行主题划分以避免过拟合。
用5种不同的种子重复实验5次,并报告平均值和标准差。
预训练和下游任务完成了40个epoch,因为我们注意到性能并没有随着进一步训练而提高。
批大小为128(在少量标记的数据实验中减少到32,因为数据大小可能小于128)。
使用Adam优化器,其学习率为3e-4,权重衰减为3e-4, β1 = 0.9, β2 = 0.99。
对于强增强,我们设置MHAR = 10, MEp = 12, MEDF = 20,而对于弱增强,我们将所有数据集的缩放比设置为2。我们设λ1 = 1,当λ2≈1时,我们获得了很好的性能。特别是,我们在四个数据集上的实验中将其设置为0.7。
对于Transformer,设置层数为 4,并且头的数量为4。我们调整h∈{32,50,64,100,128,200,256},并设置维度hHAR,Ep = 100, hEDF = 64。我们还将其差值设置为0.1。
在上下文对比中,设置τ = 0.2。
实验结果
在三种不同的训练设置上进行了测试,包括线性评估、半监督训练和迁移学习。使用准确性和宏观平均f1分数(MF1)两个指标来评估性能。
基线方法对比
-
随机初始化:在随机初始化的编码器上训练一个线性分类器;
-
Supervised:对编码器和分类器模型进行监督训练;
-
SSL-ECG [2020];
-
CPC [2018];
-
SimCLR [2020]。
结果均使用线性探测,在冻结的自监督预训练编码器模型上训练了一个线性分类器(单个MLP层)。
总体而言,我们提出的TS-TCC优于所有三种最先进的方法。此外,仅使用线性分类器的TS-TCC在三个数据集中的两个上表现最好,同时在第三个数据集上实现与监督方法相当的性能。这证明了我们的TS-TCC模型具有强大的表征学习能力。
对比方法(如CPC, SimCLR和TS-TCC)通常比基于借口的方法(如SSL-ECG)取得更好的结果,这反映了对比方法学习不变特征的效果较好。
此外,CPC方法的结果优于SimCLR方法,表明时间序列数据中时间特征比一般特征更重要。

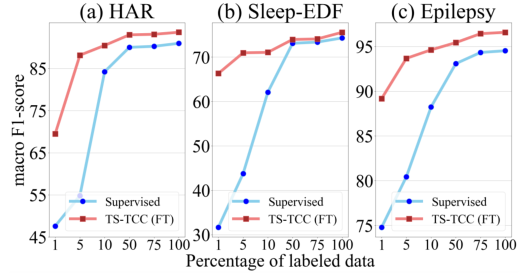
半监督训练
通过使用1%、5%、10%、50%和75%的随机选择的训练数据实例来训练模型,特别地,TS-TCC微调(红色曲线)用很少的标记样本对预训练的编码器进行微调。
监督训练在有限的标记数据下表现不佳,而我们的TS-TCC微调在只有1%的标记数据时取得了明显更好的性能。仅使用10%的标记数据进行TS-TCC微调,就可以达到与三个数据集中使用100%的标记数据进行监督训练相当的性能,证明了TS-TCC方法在半监督设置下的有效性
迁移学习
在一个条件(即源域)上训练模型,并在另一个条件(即目标域)上测试它。特别地,我们在源域上采用了两种训练方案,即(1)监督训练和(2)TS-TCC微调,其中我们使用源域的标记数据对预训练的编码器进行微调。
带有微调(FT)的预训练TSTCC模型在12个跨域场景中的8个中始终优于监督预训练。在8个获胜场景中,TS-TCC模型在7个场景中(D→B场景除外)可以实现至少7%的改进。

消融实验
首先,在没有交叉视图预测任务的情况下训练时间对比模块(TC),其中每个分支预测相同增强视图的未来时间步长。这种变体表示为“TC only”。
其次,通过增加交叉视图预测任务来训练TC模块,该任务记为“TC + XAug”。
第三,训练整个TS-TCC模型,表示为“TC + X-Aug + CC”。
另外,研究了单次增强对TS-TCC的影响。特别是,对于输入x,我们从相同的增广类型生成两个不同的视图x1和x2。
提出的交叉视图预测任务产生了鲁棒性特征,从而在HAR数据集上提高了5%以上的性能,在Sleep-EDF和Epilepsy数据集上提高了约1%。此外,上下文对比模块进一步提高了性能,因为它帮助特性更具区别性。研究增强效应,我们发现从相同的增强类型生成不同的视图对HAR和Sleep-EDF数据集没有帮助。另一方面,Epilepsy数据集仅通过一次增强就可以达到相当的性能。

敏感性分析
对HAR数据集进行敏感性分析,研究三个参数,即时间对比模块中预测的未来时间步数K,以及损失计算中的λ1和λ2。
K对整体性能的影响,其中x轴是百分比K/d, d是特征的长度。增加预测的未来时间步的百分比可以提高性能。然而,较大的百分比可能会损害性能。
固定λ1 = 1,改变λ2的值,当λ2≈1时,模型表现良好,其中λ2 = 0.7时,模型表现最佳。
固定λ2 = 0.7,并调整λ1的值,当λ1 = 1时,模型达到了最佳性能。

总结
-
采用不同数据增强的方式对不同数据集的提升不一样,对个别数据集并不明显
-
上下文对比是对transformer的输出计算传统的对比损失,有正样本和负样本概念,同一样本的不同视图的特征作为正样本,不同样本的特征之间作为负样本
-
交叉视图预测任务的结果比相同视图间的预测任务有改进,与采用不同数据增强的结果类似,都在HAR数据集中结果较好
-
在加入上下文对比的改进上,在除HAR的另外两个数据集中,加入上下文对比的改进比采用交叉视图效果更明显
代码部分
pretrain:encoder + transformer
finetune:encoder
linear probing:encoder + linear
-
encoder结构为三层卷积层,每层都有Conv,BatchNorm,ReLU和MaxPool
encoder输出 zt 特征和 一个预测特征,预测特征由 zt 拉伸后经过一个线性层得到,该预测特征是用于有监督任务的,自监督训练只使用zt
zt 特征经过一次 normalize(dim=1)后,经过transformer得到对另一视图的预测
-
TC模块计算预测任务损失时,根据用于预测的特征长度timestep,随机数据起点 t_samples (范围在0到 len-timestep 之间)
-
在特征1中选择一部分(0:t_samples + 1)经过transformer,然后每个位置的结果经过不同的线性层(timestep个)得到对timestep个位置的预测结果
-
在特征2中的对应部分(t_samples:t_samples+timestep),根据预测timestep的长度,计算每一个预测位置的损失
-
计算预测损失的方式是计算两个矩阵点乘后的LogSoftmax,再对对角线求和
t_samples = torch.randint(seq_len - self.timestep, size=(1,)).long().to(self.device) # randomly pick time stamps nce = 0 # average over timestep and batch encode_samples = torch.empty((self.timestep, batch, self.num_channels)).float().to(self.device) for i in np.arange(1, self.timestep + 1): encode_samples[i - 1] = z_aug2[:, t_samples + i, :].view(batch, self.num_channels) forward_seq = z_aug1[:, :t_samples + 1, :] c_t = self.seq_transformer(forward_seq) pred = torch.empty((self.timestep, batch, self.num_channels)).float().to(self.device) for i in np.arange(0, self.timestep): linear = self.Wk[i] pred[i] = linear(c_t) for i in np.arange(0, self.timestep): total = torch.mm(encode_samples[i], torch.transpose(pred[i], 0, 1)) nce += torch.sum(torch.diag(self.lsoftmax(total))) nce /= -1. * batch * self.timestep -
-
NTXentLoss计算两个视图 ct 之间的对比损失,完全按照有正负样本的对比损失,通过矩阵计算结果










![[论文分享]ConvMAE:Masked Convolution Meets Masked Autoencoders](https://img-blog.csdnimg.cn/img_convert/aa25e15bb07d3f98b7adddc33247a4d7.png)

