文章目录
- 1. 前言
- 2. 背景
- 3. DMA 硬件基础
- 3.1 什么是 DMA?
- 3.2 为什么需要 DMA?
- 3.3 DMA 传送模式
- 3.4 DMA 常见硬件拓扑
- 3.4.1 ARM 架构常见 DMA 硬件拓扑
- 3.4.2 其它架构 DMA 硬件拓扑
- 4. Linux 下的 DMA
- 4.1 DMA 内存地址和区域
- 4.1.1 DMA 内存涉及的3种地址
- 4.1.2 DMA 内存区域
- 4.1.2.1 DMA 可以访问的内存区域范围
- 4.1.2.2 主存:DMA CMA 内存区
- 4.1.2.3 主存:普通内存区
- 4.1.2.4 设备 IO 内存区
- 4.1.2.5 DMA 内存池
- 4.2 DMA 内存的 分配 和 映射
- 4.2.1 分配 DMA 内存
- 4.2.2 映射 DMA 内存
- 4.3 DMA 和 cache 一致性
- 4.3.1 问题的软件解决方案一:禁用 DMA 内存 cache
- 4.3.2 问题的软件解决方案二:主动刷 DMA 内存 cache
- 4.4 DMA 控制器
- 4.4.1 DMA 控制器的存在形式
- 4.4.2 独立于设备的 DMA 控制器驱动
- 4.4.2.1 DMA 控制器驱动加载和注册
- 4.4.2.2 外设对 DMA 控制器的使用
- 4.5 DMA 使用范例
- 4.5.1 DMA 控制器集成到设备的场景
- 4.5.2 DMA 控制器独立于设备的场景
- 4.5.2.1 DMA 传输的准备工作
- 4.5.2.2 DMA 传输启动工作
- 4.5.2.3 DMA 传输以及收尾工作
- 5. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 背景
本文基于 Linux 4.14 内核源码 + ARM32 架构 进行分析。本文涉及所有代码均来自于开源社区。
3. DMA 硬件基础
3.1 什么是 DMA?
DMA 全称为 Direct Memory Access ,通常情形时:通过给定 DMA 控制器 数据的 源地址(从主存传送数据到外设) 或 目的地址(从外设传递数据到主存),以及 数据的长度,然后指示 DMA 控制器 发起数据传送。数据传送期间,DMA 控制器 占据 数据总线,CPU 此时无法使用 数据总线 访问主存数据;数据传送完毕后,DMA 控制器 给出数据传送完毕信号,并把 数据总线 让出来。
当然,DMA 不仅用于 主存 和 外设 之间的数据传送,也可用于 主存不同地址范围间的数据传送。
3.2 为什么需要 DMA?
引入 DMA 一方面是为在数据传送期间将 CPU 解放出来,虽然期间 CPU 不能通过 数据总线(数据总线被 DMA 控制器占据) 访问主存,但可以做只涉及寄存器操作的运算;另一方面,如果采用 CPU 搬运数据的方式,数据首先从主存到数据总线,再到 CPU,然后再从 CPU 到数据总线,需要两条 CPU 指令,而 DMA 数据按块传送,传送期间不需要 CPU 干预。
不要误解 DMA 是用于高速传送,事实上 DMA 也用于低速传送的场合。对于 DMA 低速传送,DMA 可以在数据达到指定数量后,再发出通知信号。当然这期间阻止了 CPU 对数据总线的访问,为此 DMA 给出了解决方案,在接下来的 2.3 小节我们会了解到这一点。
3.3 DMA 传送模式
常见 DMA 传送方式 有以下3种:
1. Block DMA: 一次性传送所有要求的数据长度,期间占据数据总线,CPU 无法访问数据总线。
2. Burst mode: 一次传送总数据的一小段,而不是全部,间歇期间 CPU 可以访问数据总线。
3. Transparent DMA: 在 CPU 不访问数据总线期间偷偷的传输数据,这样避免和 CPU 争抢数据总线。
上述的 Burst mode 和 Transparent DMA 两种 DMA 传输模式,可以减少 CPU 因 DMA 传送期间,数据总线被占用而 stall 的时间。当然凡事皆有代价,相比于 Block DMA ,Burst mode 和 Transparent DMA 的传送时间要更长。
3.4 DMA 常见硬件拓扑
3.4.1 ARM 架构常见 DMA 硬件拓扑
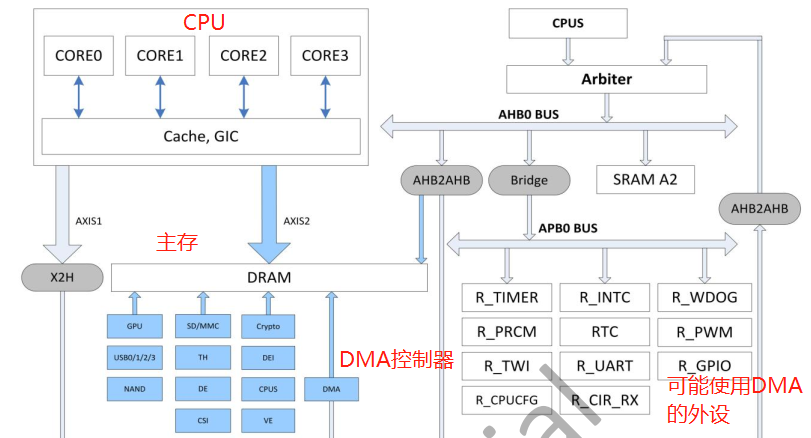
3.4.2 其它架构 DMA 硬件拓扑
(待续)
4. Linux 下的 DMA
笔者将 Linux DMA 分作以下 3 部分来进行讲述:
. DMA 内存区域
. DMA API
. DMA 控制器
4.1 DMA 内存地址和区域
4.1.1 DMA 内存涉及的3种地址
不同于 CPU 通过 MMU 对 主存 进行访问,DMA 对 主存 的访问,不会经过 MMU 。当我们从 主存 分配了一块 用于 DMA 传输 的内存,从 CPU 的角度来看,它看到的是这块内存的 虚拟地址 ,并通过 MMU 将 虚拟地址 映射为内存的 物理地址,来访问这块内存;那么从 DMA 控制器 或 外设(内置 DMA控制器) 的角度来看,这块内存的地址是多少?又该如何来访问?我们把从 DMA 控制器 或 外设(内置 DMA控制器) 视角出发,DMA 控制器 或 外设(内置 DMA控制器) 用来访问主存的地址称为 总线地址 。在不带 IOMMU 的情形下,总线地址 和 主存的物理地址 相同,或 彼此之间存在一个偏移值; 在 带有 IOMMU(ARM 架构下通常称为 SMMU) 的情形下,通过 IOMMU 将 总线地址 映射为 主存的物理地址 ,类似于 CPU 通过 MMU 访问 主存 的方式。通过下面这张图,描述前文提到的3种地址(虚拟地址,物理地址,总线地址)之间的转换关系(图片来源于内核文档 Documentation/DMA-API-HOWTO.txt):
CPU CPU Bus
Virtual Physical Address
Address Address Space
Space Space
+-------+ +------+ +------+
| | |MMIO | Offset | |
| | Virtual |Space | applied | |
C +-------+ --------> B +------+ ----------> +------+ A
| | mapping | | by host | |
+-----+ | | | | bridge | | +--------+
| | | | +------+ | | | |
| CPU | | | | RAM | | | | Device |
| | | | | | | | | |
+-----+ +-------+ +------+ +------+ +--------+
| | Virtual |Buffer| Mapping | |
X +-------+ --------> Y +------+ <---------- +------+ Z
| | mapping | RAM | by IOMMU
| | | |
| | | |
+-------+ +------+
我们来小结下这3种地址:
虚拟地址:CPU 看到的地址,通过 MMU 转换为 主存的物理地址
物理地址:主存的地址
总线地址:DMA 控制器 或 外设 用来访问主存的地址。
在不带 IOMMU 的情形下,等于 主存的物理地址 或 彼此存在一个偏移值;
在带 IOMMU 的情形下,通过 IOMMU 将 总线地址 映射为 主存的物理地址。
4.1.2 DMA 内存区域
4.1.2.1 DMA 可以访问的内存区域范围
对于 DMA 可以访问的内存区间,我们分别从 CPU 和 设备 两边来讨论它们各自可以访问的内存区间范围。
先说 CPU 一侧。CPU 一侧可以访问的 DMA 内存区间范围,取决于 CPU 硬件架构的设计。在有的 CPU 架构下,DMA 只能访问 主存特定区间(ZONE_DMA),而另外一些情形下 DMA 可以访问 所有主存空间 (譬如 ARMv7)。对于 DMA 只能访问主存特定区间 的情形,内存子系统会建立 专用于 DMA 的 ZONE_DMA 内存区域,而后 kmalloc() 系列内存分配接口,可以 通过指定 __GFP_DMA 标志位,指示内存子系统从 专用于 DMA 的 ZONE_DMA 内存区域 分配用于 DMA 的内存,这种情形在现今的硬件架构上,已经不太常见,本文也不对此种情形做展开;而对于 DMA 可以访问整个主存 的情形,kmalloc() 系列内存分配接口,可以 不用指定 __GFP_DMA 标志位,分配用于 DMA 的内存。当然,DMA 内存分配,除 kmalloc() 外,还有更多的专用分配接口,将在后文展开。
再说 设备一侧。设备一侧可以访问的 DMA 内存区间,由设备(设备独立的 或 内置于设备的 DMA 控制器)自身硬件能力决定,系统提供如下接口:
dma_set_mask()
dma_set_coherent_mask()
dma_set_mask_and_coherent()
dma_coerce_mask_and_coherent()
来设定设备可以访问的主存内存区域范围掩码;而后在为设备分配 DMA 内存时,会用该掩码验证可以分配的内存区间是否符合掩码要求,如果不符合则分配 DMA 内存失败,在后面我们将展开这一细节。
4.1.2.2 主存:DMA CMA 内存区
由于 DMA 可以访问的内存,要求 内存区间物理地址上的连续性,这对内存子系统 DMA 内存分配接口提出了要求:
1. 对内存分配发起方式提出了要求,如 `vmalloc()` 分配的内存,就没法保证物理空间的连续性。
2. 由于主存是整个系统共享的,随着分配的进行,系统中的内存会逐渐趋于碎片化,可能没办法保
证随时都能满足 DMA 对连续内存区间的要求。
3. 内存伙伴管理系统 的 MAX_ORDER 限定了最大可以分配的连续内存空间大小。
对于内核中对 大块物理地址空间连续内存 的请求(kmalloc(), __get_dma_pages() 都无法满足的分配满足,常见于视频类设备驱动:可能因为要求内存块太大,超过 MAX_ORDER 最大连续页面;也可能因为随着分配释放,内存碎片增多导致无法分配),对此 Linux 引入 CMA(Contiguous Memory Allocator) 内存分配器,通过预先为该分配器保留一块内存,之后通过 CMA 内存分配器 进行分配,以此来满足对连续大块内存的分配要求。这块预留内存不会纳入 内存伙伴管理系统 的管理。
DTS 可以用 reserved-memory 来声明 保留专用于 CMA 内存分配器 的内存区,来看一个例子:
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
cma: linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x4000000>; /* 保留 64MB 专用于 CMA 分配器的内存 */
alignment = <0x2000>;
linux,cma-default; /* 指示用于 CMA 分配器 */
};
};
来看 ARM32 架构下,Linux 内核是怎么处理这些 CMA 专用内存区的:
start_kernel() /* init/main.c */
setup_arch() /* arch/arm/kernel/setup.c */
arm_memblock_init(mdesc) /* arch/arm/mm/init.c */
early_init_fdt_scan_reserved_mem() /* drivers/of/fdt.c */
/* 扫描解析 DTS 的 "reserved-memory" 节点,将其中的内存区域信息提取到 reserved_mem[] 全局数组 */
of_scan_flat_dt(__fdt_scan_reserved_mem, NULL)
/* 扫描登记 保留内存区 */
fdt_init_reserved_mem() /* drivers/of/of_reserved_mem.c */
/* reserve memory for DMA contiguous allocations */
//dma_contiguous_reserve(arm_dma_limit);
/* 扫描解析 DTS 的 "reserved-memory" 节点,将其中的内存区域信息提取到 reserved_mem[] 全局数组 */
int __init of_scan_flat_dt(int (*it)(unsigned long node,
const char *uname, int depth,
void *data),
void *data)
{
const void *blob = initial_boot_params;
const char *pathp;
int offset, rc = 0, depth = -1;
...
for (offset = fdt_next_node(blob, -1, &depth);
offset >= 0 && depth >= 0 && !rc;
offset = fdt_next_node(blob, offset, &depth)) {
pathp = fdt_get_name(blob, offset, NULL);
if (*pathp == '/')
pathp = kbasename(pathp);
/* 对一个 reserved-memory 节点,会以不同的 @depth 值,两次进入 __fdt_scan_reserved_mem() ,细节见后面 */
rc = it(offset, pathp, depth, data); /* __fdt_scan_reserved_mem() */
}
return rc;
}
static int __init __fdt_scan_reserved_mem(unsigned long node, const char *uname,
int depth, void *data)
{
static int found;
if (!found && depth == 1 && strcmp(uname, "reserved-memory") == 0) {
...
/*
* 第 1 次 进入函数,匹配到名为 "reserved-memory" 节点后就立即返回,等搜索
* 深度进入下一层,即到达 "cma: linux,cma" 节点后(即 第 2 次进入函数),再做
* 内部节点 cma: linux,cma 的处理。
*
* reserved-memory {
* #address-cells = <1>;
* #size-cells = <1>;
* ranges;
*
* cma: linux,cma {
* compatible = "shared-dma-pool";
* reusable;
* size = <0x4000000>;
* alignment = <0x2000>;
* linux,cma-default;
* };
* };
*/
found = 1;
/* scan next node */
return 0;
}
...
/*
* 第 2 次进入函数: 处理 cma: linux,cma 节点。
*/
/*
* 如果 cma: linux,cma 节点 【有 "reg" 属性】:
* 按 "reg" 信息登记 reserved memory 区间
*/
err = __reserved_mem_reserve_reg(node, uname);
/*
* 如果 cma: linux,cma 节点 【没有 "reg" 属性, 但配置了 "size" 属性】:
* 登记一个 reserved memory 区间(登记区间的 base == 0 && size == 0).
*/
if (err == -ENOENT && of_get_flat_dt_prop(node, "size", NULL))
fdt_reserved_mem_save_node(node, uname, 0, 0); // 这是我们例子中的情形
/* scan next node */
return 0;
}
/* 登记一个 保留内存区域 */
void __init fdt_reserved_mem_save_node(unsigned long node, const char *uname,
phys_addr_t base, phys_addr_t size)
{
struct reserved_mem *rmem = &reserved_mem[reserved_mem_count];
...
rmem->fdt_node = node;
rmem->name = uname;
rmem->base = base;
rmem->size = size;
reserved_mem_count++;
return;
}
到此为止,还只是保留了一块内存,但这块内存的用途还没明确,它还没有进入 CMA 内存分配器 的视野。接下来,我们看这块内存是如何和 CMA 内存分配器 关联的:
/* drivers/of/of_reserved_mem.c */
void __init fdt_init_reserved_mem(void)
{
int i;
...
for (i = 0; i < reserved_mem_count; i++) {
struct reserved_mem *rmem = &reserved_mem[i];
unsigned long node = rmem->fdt_node;
int len;
const __be32 *prop;
int err = 0;
/*
* 如果登记的保留内存区没有指定物理内存区域,从 memblock 分配空间,
* 同时设定保留内存区间的 物理基址(rmem->base) 和 大小(rmem->size) 。
*/
if (rmem->size == 0) // 这是我们例子中的情形
err = __reserved_mem_alloc_size(node, rmem->name,
&rmem->base, &rmem->size);
/* 保留了内存总是要用的,在此处将这些保留内存和内存分配器(如 CMA)关联起来 */
if (err == 0)
__reserved_mem_init_node(rmem);
}
}
/**
* res_mem_init_node() - call region specific reserved memory init code
*/
static int __init __reserved_mem_init_node(struct reserved_mem *rmem)
{
/* 这个 __reservedmem_of_table[] 是通过 RESERVEDMEM_OF_DECLARE() 建立的,详见后面的分析 */
extern const struct of_device_id __reservedmem_of_table[];
const struct of_device_id *i;
for (i = __reservedmem_of_table; i < &__rmem_of_table_sentinel; i++) {
reservedmem_of_init_fn initfn = i->data;
const char *compat = i->compatible;
if (!of_flat_dt_is_compatible(rmem->fdt_node, compat))
continue;
/*
* drivers/base/dma-coherent.c: rmem_dma_setup()
* drivers/base/dma-contiguous.c: rmem_cma_setup()
*/
if (initfn(rmem) == 0) { // 我们例子情形匹配 rmem_cma_setup()
pr_info("initialized node %s, compatible id %s\n",
rmem->name, compat);
return 0;
}
}
}
/* drivers/base/dma-contiguous.c */
static const struct reserved_mem_ops rmem_cma_ops = {
.device_init = rmem_cma_device_init,
.device_release = rmem_cma_device_release,
};
static int __init rmem_cma_setup(struct reserved_mem *rmem)
{
struct cma *cma;
...
/* 将 保留内存区 注册给 CMA 内存分配器使用 */
err = cma_init_reserved_mem(rmem->base, rmem->size, 0, rmem->name, &cma);
/* "linux,cma-default" 属性 指示 将 保留内存区 设为全局共享的 DMA CMA 内存池 */
if (of_get_flat_dt_prop(node, "linux,cma-default", NULL))
dma_contiguous_set_default(cma);
rmem->ops = &rmem_cma_ops;
rmem->priv = cma;
pr_info("Reserved memory: created CMA memory pool at %pa, size %ld MiB\n",
&rmem->base, (unsigned long)rmem->size / SZ_1M);
return 0;
}
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
/* mm/cma.c */
/* 将 保留内存区 注册给 CMA 内存分配器使用 */
int __init cma_init_reserved_mem(phys_addr_t base, phys_addr_t size,
unsigned int order_per_bit,
const char *name,
struct cma **res_cma)
{
...
/*
* Each reserved area must be initialised later, when more kernel
* subsystems (like slab allocator) are available.
*/
cma = &cma_areas[cma_area_count];
if (name) {
cma->name = name;
} else {
cma->name = kasprintf(GFP_KERNEL, "cma%d\n", cma_area_count);
if (!cma->name)
return -ENOMEM;
}
cma->base_pfn = PFN_DOWN(base);
cma->count = size >> PAGE_SHIFT;
cma->order_per_bit = order_per_bit;
*res_cma = cma; /* 返回分配的 CMA 内存区 */
cma_area_count++;
totalcma_pages += (size / PAGE_SIZE);
return 0;
}
/* include/linux/dma-contiguous.h */
/* 设置全局共享的 DMA 的 CMA 内存池(需启用 CONFIG_DMA_CMA 配置) */
static inline void dma_contiguous_set_default(struct cma *cma)
{
dma_contiguous_default_area = cma;
}
关联了 保留内存区 和 CMA 分配器 后,还不能保证这些 保留内存区 可以用于 DMA 。如果 保留内存区 的 DTS 配置,没有通过 "shared-dma-pool" 属性,指示系统将 保留内存区设为 DMA 可用的 CMA 内存池(CMA 内存池理论上并非专用于 DMA),那是不是 DMA 就没有了自己的 CMA 内存池,专门用来分配物理地址连续的大块内存呢?如果没有开启 CONFIG_DMA_CMA 配置,不管保留内存区的 DTS 配置有没有设置 "shared-dma-pool" 属性,都不会存在 DMA 的 CMA 内存池;相反,在开启了 CONFIG_DMA_CMA 配置的情形下,不管保留内存区的 DTS 配置有没有设置 "shared-dma-pool" 属性,都会有 DMA 的 CMA 内存池:对于设置了 "shared-dma-pool" 属性的情形,前面已经描述过了;对于没有设置 "shared-dma-pool" 属性的情形,内核也将从系统内存中,分配一个 DMA 的 CMA 内存池。细节如下:
start_kernel() /* init/main.c */
setup_arch() /* arch/arm/kernel/setup.c */
arm_memblock_init(mdesc) /* arch/arm/mm/init.c */
//early_init_fdt_scan_reserved_mem() /* drivers/of/fdt.c */
/* 扫描解析 DTS 的 "reserved-memory" 节点,将其中的内存区域信息提取到 reserved_mem[] 全局数组 */
//of_scan_flat_dt(__fdt_scan_reserved_mem, NULL)
/* 扫描登记保留内存区 */
//fdt_init_reserved_mem() /* drivers/of/of_reserved_mem.c */
/* reserve memory for DMA contiguous allocations */
dma_contiguous_reserve(arm_dma_limit); /* 如果尚未建立 DMA 的 CMA 内存池,从系统内存分配一块,用于 DMA 连续内存块分配处理 */
void __init dma_contiguous_reserve(phys_addr_t limit)
{
...
/* 确定 DMA 的 CMA 内存池大小 */
if (size_cmdline != -1) { /* 命令行参数 cma=xxx 指定保留DMA CMA区间大小 */
selected_size = size_cmdline;
selected_base = base_cmdline;
selected_limit = min_not_zero(limit_cmdline, limit);
if (base_cmdline + size_cmdline == limit_cmdline)
fixed = true;
} else {
#ifdef CONFIG_CMA_SIZE_SEL_MBYTES
selected_size = size_bytes;
#elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE)
selected_size = cma_early_percent_memory();
#elif defined(CONFIG_CMA_SIZE_SEL_MIN)
selected_size = min(size_bytes, cma_early_percent_memory());
#elif defined(CONFIG_CMA_SIZE_SEL_MAX)
selected_size = max(size_bytes, cma_early_percent_memory());
#endif
}
if (selected_size && !dma_contiguous_default_area/*尚未指定*/) {
...
/* 从系统内存分配用于 DMA 的 CMA 内存池 */
dma_contiguous_reserve_area(selected_size, selected_base,
selected_limit,
&dma_contiguous_default_area,
fixed);
}
}
int __init dma_contiguous_reserve_area(phys_addr_t size, phys_addr_t base,
phys_addr_t limit, struct cma **res_cma,
bool fixed)
{
int ret;
ret = cma_declare_contiguous(base, size, limit, 0, 0, fixed,
"reserved", res_cma);
...
return 0;
}
/* mm/cma.c */
int __init cma_declare_contiguous(phys_addr_t base,
phys_addr_t size, phys_addr_t limit,
phys_addr_t alignment, unsigned int order_per_bit,
bool fixed, const char *name, struct cma **res_cma)
{
...
/* 分配 DMA 的 CMA 内存池空间 */
addr = memblock_alloc_range(size, alignment, base,
limit,
MEMBLOCK_NONE);
...
/* 注册 分配 DMA 的 CMA 内存池空间 到 CMA 分配器 */
ret = cma_init_reserved_mem(base, size, order_per_bit, name, res_cma);
pr_info("Reserved %ld MiB at %pa\n", (unsigned long)size / SZ_1M,
&base);
return 0;
}
以上,就是 可用于所有设备的、 从主存内预留的、全局 DMA CMA 内存池 建立过程。
4.1.2.3 主存:普通内存区
用于 DMA 的内存,也不一定非得从 预留内存 中分配,也可以通过 kmalloc() 从普通内存区直接分配;在硬件对 DMA 能够访问的主存区间范围做了限定的情形下,需指定 __GFP_DMA 标志位从 ZONE_DMA, ZONE_DMA32 内存区域(zone) 进行分配。
4.1.2.4 设备 IO 内存区
有些设备带有专用于 DMA 的 IO 内存区,这时候可以通过接口 dev_set_cma_area() ,将设备的 IO 内存区域,设定为设备 dev_set_cma_area() 设定 设备专用的 DMA CMA 内存。来看个简单的例子:
struct resource *res;
res = platform_get_resource(pdev, IORESOURCE_MEM, 1);
dma_declare_coherent_memory(&pdev->dev, res->start,
res->start, resource_size(res), DMA_MEMORY_EXCLUSIVE)
dma_init_coherent_memory(phys_addr, device_addr, size, flags, &mem)
struct dma_coherent_mem *dma_mem = NULL;
/*
* 将 DMA IO 内存地址空间 映射到 虚拟地址空间.
* 在 ARM32 架构下, MEMREMAP_WC 意味着是读写都不会经过 cache.
*/
mem_base = memremap(phys_addr, size, MEMREMAP_WC);
dma_mem = kzalloc(sizeof(struct dma_coherent_mem), GFP_KERNEL);
dma_mem->bitmap = kzalloc(bitmap_size, GFP_KERNEL);
dma_mem->virt_base = mem_base;
dma_mem->device_base = device_addr;
dma_mem->pfn_base = PFN_DOWN(phys_addr);
dma_mem->size = pages;
dma_mem->flags = flags;
*mem = dma_mem;
dma_assign_coherent_memory(dev, mem)
dev->dma_mem = mem;
4.1.2.5 DMA 内存池
内核用 struct dma_pool 来描述分配固定大小空间的 DMA 内存池,其包含的空间用 struct dma_page 来描述,这些空间组织在 struct dma_page 列表中,列表头部位于 struct dma_pool 内。DMA 内存池相对简单,这里就不做更多展开。后续在 4.2 节会列举 struct dma_pool 的 创建销毁、分配释放 接口;在 4.3 节会描述从 DMA 内存池分配内存的 cache 属性。
4.2 DMA 内存的 分配 和 映射
4.2.1 分配 DMA 内存
了解了 DMA 内存区间,接下来我们要了解如何去分配这些 DMA 内存区间。接下来我们说明 Linux 系统提供 DMA 内存分配 API,以及每个 API 的内存可能是来自哪些 DMA 内存区。
/* include/linux/slab.h */
static __always_inline void *kmalloc(size_t size, gfp_t flags) {...}
/* include/linux/gfp.h */
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))
注意,在 CPU 架构限定了 DMA 访问区间的情形下,kmalloc() 需传递 __GFP_DMA 标记来指示从 ZONE_DMA* 内存 zone 分配内存。上面的两个 API 分配的内存,来自伙伴管理系统管理的内存区域(zone)。
/* include/linux/dma-mapping.h */
/*
* Managed DMA API
*/
extern void *dmam_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp);
extern void dmam_free_coherent(struct device *dev, size_t size, void *vaddr,
dma_addr_t dma_handle);
extern void *dmam_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp,
unsigned long attrs);
...
static inline void *dma_alloc_wc(struct device *dev, size_t size,
dma_addr_t *dma_addr, gfp_t gfp)
{
return dma_alloc_attrs(dev, size, dma_addr, gfp,
DMA_ATTR_WRITE_COMBINE);
}
#ifndef dma_alloc_writecombine
#define dma_alloc_writecombine dma_alloc_wc
#endif
static inline void dma_free_wc(struct device *dev, size_t size,
void *cpu_addr, dma_addr_t dma_addr)
{
return dma_free_attrs(dev, size, cpu_addr, dma_addr,
DMA_ATTR_WRITE_COMBINE);
}
#ifndef dma_free_writecombine
#define dma_free_writecombine dma_free_wc
#endif
/* include/linux/dmapool.h */
/* DMA 内存池 创建、销毁 接口 */
struct dma_pool *dma_pool_create(const char *name, struct device *dev,
size_t size, size_t align, size_t allocation);
void dma_pool_destroy(struct dma_pool *pool);
/* DMA 内存池 分配、释放 接口 */
void *dma_pool_alloc(struct dma_pool *pool, gfp_t mem_flags,
dma_addr_t *handle);
void dma_pool_free(struct dma_pool *pool, void *vaddr, dma_addr_t addr);
包括 DMA 内存池的分配接口在内,以上的所有分配接口,最终都会调用 dma_alloc_attrs(),它们的返回值是分配的 DMA 内存区间的 虚拟地址,而内存区间的总线地址从参数 dma_handle 返回。以 dma_alloc_attrs() 为起点,来看一下分配过程细节(以 ARM32 架构为例):
/* include/linux/dma-mapping.h */
static inline void *dma_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
/*
* 首先尝试从设备 @dev 自身的 DMA 内存池(device::dma_mem) 分配内存.
* 如 4.1.2.4 例子中设定的设备 IO 内存区。
* 非典型情形。
*/
if (dma_alloc_from_dev_coherent(dev, size, dma_handle, &cpu_addr))
return cpu_addr; /* 成功从设备内存空间分配 dma 内存,@cpu_addr 返回分配的虚拟地址 */
...
/*
* 典型的分配路径.
* 如果设备的 DTS 节点设置了 dma-coherent 属性,则会调用 arm_coherent_dma_alloc()
* 而不是 arm_dma_alloc() 了。
*/
cpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs); /* arm_dma_alloc() */
return cpu_addr;
}
/* arch/arm/mm/dma-mapping.c */
void *arm_dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, unsigned long attrs)
{
pgprot_t prot = __get_dma_pgprot(attrs, PAGE_KERNEL);
return __dma_alloc(dev, size, handle, gfp, prot, false,
attrs, __builtin_return_address(0));
}
static void *__dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, pgprot_t prot, bool is_coherent,
unsigned long attrs, const void *caller)
{
/* 4.1.2.1 提到,设备可以通过掩码告知内核,其可以访问的内存区间范围,在分配过程体现在此处 */
u64 mask = get_coherent_dma_mask(dev);
struct page *page = NULL;
void *addr;
bool allowblock, cma;
struct arm_dma_buffer *buf;
struct arm_dma_alloc_args args = {
.dev = dev,
.size = PAGE_ALIGN(size),
.gfp = gfp,
.prot = prot,
.caller = caller,
.want_vaddr = ((attrs & DMA_ATTR_NO_KERNEL_MAPPING) == 0),
.coherent_flag = is_coherent ? COHERENT : NORMAL,
};
if (!mask) /* 没有设备 @dev 的 DMA 内存掩码指定的能访问内存区 */
return NULL;
buf = kzalloc(sizeof(*buf),
gfp & ~(__GFP_DMA | __GFP_DMA32 | __GFP_HIGHMEM));
if (!buf)
return NULL;
if (mask < 0xffffffffULL)
gfp |= GFP_DMA;
gfp &= ~(__GFP_COMP);
args.gfp = gfp;
*handle = ARM_MAPPING_ERROR;
allowblock = gfpflags_allow_blocking(gfp);
cma = allowblock ? dev_get_cma_area(dev) : false;
/* 不同的参数,将决定从哪个 DMA 内存区分配内存 */
if (cma) /* 分配 CMA 内存 */
buf->allocator = &cma_allocator;
else if (is_coherent) /* 分配 coherent 内存 */
buf->allocator = &simple_allocator;
else if (allowblock)
buf->allocator = &remap_allocator;
else
buf->allocator = &pool_allocator;
addr = buf->allocator->alloc(&args, &page);
if (page) {
unsigned long flags;
*handle = pfn_to_dma(dev, page_to_pfn(page)); /* 将分配的 页面物理地址 转换为 DMA 总线地址 */
buf->virt = args.want_vaddr ? addr : page;
spin_lock_irqsave(&arm_dma_bufs_lock, flags);
list_add(&buf->list, &arm_dma_bufs); /* 每次分配需要增加一个 arm_dma_buffer */
spin_unlock_irqrestore(&arm_dma_bufs_lock, flags);
} else {
kfree(buf);
}
return args.want_vaddr ? addr : page;
}
上面的 get_coherent_dma_mask() 调用值得特别注意,其逻辑体现了设备 DMA 掩码,对可访问内存区间范围的限制作用:
/* arch/arm/mm/dma-mapping.c */
static u64 get_coherent_dma_mask(struct device *dev)
{
/* 指示可以从掩码 0x00000000FFFFFFFF 指示所有 4G 物理分配 DMA 内存 */
u64 mask = (u64)DMA_BIT_MASK(32);
if (dev) { /* 设备可能设定了自己可以访问的 DMA 内存区间掩码 */
mask = dev->coherent_dma_mask;
if (mask == 0) {
dev_warn(dev, "coherent DMA mask is unset\n");
return 0;
}
if (!__dma_supported(dev, mask, true))
return 0;
}
return mask;
}
static int __dma_supported(struct device *dev, u64 mask, bool warn)
{
unsigned long max_dma_pfn;
if (sizeof(mask) != sizeof(dma_addr_t) &&
mask > (dma_addr_t)~0 &&
dma_to_pfn(dev, ~0) < max_pfn - 1) {
if (warn) {
dev_warn(dev, "Coherent DMA mask %#llx is larger than dma_addr_t allows\n",
mask);
dev_warn(dev, "Driver did not use or check the return value from dma_set_coherent_mask()?\n");
}
return 0;
}
max_dma_pfn = min(max_pfn, arm_dma_pfn_limit);
if (dma_to_pfn(dev, mask) < max_dma_pfn) {
if (warn)
dev_warn(dev, "Coherent DMA mask %#llx (pfn %#lx-%#lx) covers a smaller range of system memory than the DMA zone pfn 0x0-%#lx\n",
mask,
dma_to_pfn(dev, 0), dma_to_pfn(dev, mask) + 1,
max_dma_pfn + 1);
return 0;
}
return 1;
}
另外,__dma_alloc() 逻辑也表明,前述通过 dma_alloc_attrs() 分配 DMA 内存的 API,所分配的内存区域来源,根据传递参数的不同,可能来自: CMA,伙伴管理系统,设备 IO 内存区,相关细节读者可自行分析。
4.2.2 映射 DMA 内存
分配的 DMA 内存,我们要拿到它的两个地址: CPU 经 MMU 访问的虚拟地址,设备经所在总线访问的总线地址,才能对 DMA 内存进行双向访问。对于经过 dma_alloc_attrs() 接口分配的 DMA 内存,同时返回了需要的两个地址;而对于 kmalloc() 或 __get_dma_pages() 分配的 DMA 内存,我们只拿到内存的虚拟地址,还需要拿到 DMA 内存的总线地址,这时可以通过 dma_map_single_attrs() 接口来完成:
/* include/linux/dma-mapping.h */
/* 将虚拟地址 @ptr 映射为 总线地址 后返回 */
static inline dma_addr_t dma_map_single_attrs(struct device *dev, void *ptr,
size_t size,
enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
dma_addr_t addr;
/* arm_coherent_dma_map_page() 或 arm_dma_map_page() */
addr = ops->map_page(dev, virt_to_page(ptr),
offset_in_page(ptr), size,
dir, attrs);
return addr; /* 返回 @ptr 映射的 总线地址 */
}
看一下 ARM32 的 arm_dma_map_page() 的调用细节:
/* arch/arm/mm/dma-mapping.c */
static dma_addr_t arm_dma_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size, enum dma_data_direction dir,
unsigned long attrs)
{
if ((attrs & DMA_ATTR_SKIP_CPU_SYNC) == 0)
/* 刷区间 DMA 内存的 cache , 以保持 cache 一致性 */
__dma_page_cpu_to_dev(page, offset, size, dir);
return pfn_to_dma(dev, page_to_pfn(page)) + offset; /* 将 DMA 内存 struct page 转换为 总线地址 返回 */
}
static inline dma_addr_t pfn_to_dma(struct device *dev, unsigned long pfn)
{
if (dev)
pfn -= dev->dma_pfn_offset;
return (dma_addr_t)__pfn_to_bus(pfn);
}
我们这里的讨论不考虑使用 IOMMU 的情形。建立了映射,自然有取消映射的对称操作,使用接口 dma_unmap_single_attrs() 取消上述映射。
前文提到,DMA 要求连续的物理内存,如果这块连续内存很大,可能不容易分配到,随着 DMA 技术的发展,有了一种 Scatter/Gather 的技术,该技术可以将连续的大块内存,拆分成更小的、单个物理空间连续的多块内存,可以分多次传送完成,然后在所有块传输完成后生成一个中断,此时就需要做多个内存块的总线地址映射,于是接口 dma_map_sg_attrs() 就产生了:
/* include/include/dma-mapping.h */
/*
* @sg 包含多个要映射 的 DMA 内存块 列表 ,
* 之后 各个 DMA 内存块 映射的 总线地址也从从 @sg 返回。
*/
static inline int dma_map_sg_attrs(struct device *dev, struct scatterlist *sg,
int nents, enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
int ents;
ents = ops->map_sg(dev, sg, nents, dir, attrs); /* arm_dma_map_sg() */
return ents; /* 返回成功映射的 DMA 内存块数目 */
}
/* arch/arm/mm/dma-mapping.c */
int arm_dma_map_sg(struct device *dev, struct scatterlist *sg, int nents,
enum dma_data_direction dir, unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
struct scatterlist *s;
int i, j;
for_each_sg(sg, s, nents, i) {
#ifdef CONFIG_NEED_SG_DMA_LENGTH
s->dma_length = s->length;
#endif
/*
* arm_coherent_dma_map_page() 或 arm_dma_map_page()
* 后续逻辑和前面的一样。
*/
s->dma_address = ops->map_page(dev, sg_page(s), s->offset,
s->length, dir, attrs);
if (dma_mapping_error(dev, s->dma_address))
goto bad_mapping;
}
return nents; /* 返回成功映射的 DMA 内存块数目 */
}
dma_unmap_page_attrs() 是取消 dma_map_sg_attrs() 建立的映射接口。
除了上面的映射接口,还有针对 DMA 内存页面管理对象 struct page 建立/取消映射的一对接口 dma_map_page_attrs()/dma_unmap_page_attrs(),以及针对设备 IO 内存(如设备的 FIFO 硬件缓冲)资源建立和取消映射的一对接口 dma_map_resource()/dma_unmap_resource() 。
4.3 DMA 和 cache 一致性
假设有一块用于 DMA 操作的主存空间,CPU 曾经对它进行过读写,于是这块内存有部分内容进入了 CPU 的 Cache;接着,某个设备覆写了该块内存中进入 CPU cache 的区域,CPU 对这个覆写操作一无所知,CPU 的读操作仍然从 cache 取得旧数据,CPU 的写操作会覆盖设备更新的数据,造成问题的根本原因是 CPU cache 和 DMA 内存块不一致造成的。
解决 DMA 造成的 Cahche 不一致性问题,可以有3中解决方案:
1. 硬件方案:系统硬件集成一种称为 Cache Coherent interconnect 的硬件,当 DMA 传输造成
CPU cache 不一致时,自动帮 CPU 刷新 Cache 。
2. 软件方案:禁用用于 DMA 操作内存页面 cache 属性,这就是所谓的 DMA 一致性映射。
3. 软件方案:使能用于 DMA 操作内存页面 cache 属性,然后在 DMA 传输完成时,主动刷新
cache,这就是所谓的 DMA 流式映射(DMA Streaming Mapping)。
接下来,我们深入讨论两种软件方案的更多细节。
4.3.1 问题的软件解决方案一:禁用 DMA 内存 cache
首先来看 禁用 DMA 内存 cache 方案,通过接口 dma_alloc_coherent() 分配的内存(包括从 DMA 内存池分配的内存),默认就是禁用了 cache 的:
static inline void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag)
{
return dma_alloc_attrs(dev, size, dma_handle, flag, 0);
}
static inline void *dma_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
void *cpu_addr;
...
/* arm_dma_alloc() / arm_coherent_dma_alloc() */
cpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);
return cpu_addr;
}
这里只看 arm_dma_alloc() 的情形 (arm_coherent_dma_alloc() 也会禁用页面的 cahce):
void *arm_dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, unsigned long attrs)
{
pgprot_t prot = __get_dma_pgprot(attrs, PAGE_KERNEL); /* 决定页面的属性 */
return __dma_alloc(dev, size, handle, gfp, prot, false,
attrs, __builtin_return_address(0));
}
static inline pgprot_t __get_dma_pgprot(unsigned long attrs, pgprot_t prot)
{
/* 不管 @attrs 为何值,内存页面都不会经过 CPU cache */
prot = (attrs & DMA_ATTR_WRITE_COMBINE) ?
pgprot_writecombine(prot) :
pgprot_dmacoherent(prot);
return prot;
}
/* arch/arm/include/asm/pgtable.h */
#define pgprot_writecombine(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE)
#ifdef CONFIG_ARM_DMA_MEM_BUFFERABLE
#define pgprot_dmacoherent(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_BUFFERABLE | L_PTE_XN)
...
#else
#define pgprot_dmacoherent(prot) \
__pgprot_modify(prot, L_PTE_MT_MASK, L_PTE_MT_UNCACHED | L_PTE_XN)
#endif
4.3.2 问题的软件解决方案二:主动刷 DMA 内存 cache
通过 kmalloc() 或 __get_dma_pages() 分配的内存,没有主动禁用 cache,此时这些内存经过 4.2.2 小节接口进行映射用于 DMA 传输,在传输完成后,根据数据的传输方向(向设备发送数据,从设备接收数据),调用下列 DMA cache 刷新接口,维持 cache 一致性:
/*
* 如果外设覆写 DMA 内存数据(dir == DMA_FROM_DEVICE), 应调用此接口,
* 接口将把 内存区对应的 CPU cache line 置为无效,这样 CPU 接下来的
* 读写操作会重新从主存加载数据,避免读写旧数据。
* 如 接收完网卡的 DMA 数据后。
*/
static inline void dma_sync_single_for_cpu(struct device *dev, dma_addr_t addr,
size_t size,
enum dma_data_direction dir)
{...}
/*
* 如果 CPU 覆写 DMA 内存数据(dir == DMA_TO_DEVICE), 应调用此接口,
* 接口将把 内存区对应的 CPU cache line 刷到 DMA 内存区,这样接下
* 来通过 DMA 向设备传输的数据就是 CPU 写入的最新数据。
* 如 网卡通过 DMA 发送数据。
*/
static inline void dma_sync_single_for_device(struct device *dev,
dma_addr_t addr, size_t size,
enum dma_data_direction dir)
{...}
static inline void dma_sync_single_range_for_cpu(struct device *dev,
dma_addr_t addr,
unsigned long offset,
size_t size,
enum dma_data_direction dir)
{...}
static inline void dma_sync_single_range_for_device(struct device *dev,
dma_addr_t addr,
unsigned long offset,
size_t size,
enum dma_data_direction dir)
{...}
static inline void
dma_sync_sg_for_cpu(struct device *dev, struct scatterlist *sg,
int nelems, enum dma_data_direction dir)
{...}
static inline void
dma_sync_sg_for_device(struct device *dev, struct scatterlist *sg,
int nelems, enum dma_data_direction dir)
{...}
这 6 个接口都是类似,故只对前两个接口进行了说明。
如果是设备通过 DMA 传送数据到主存(DMA_FROM_DEVICE),应调用 dma_sync_*_for_cpu(DMA_FROM_DEVICE) 系列接口,将 DMA 内存区 CPU 对应 cache line 置为无效,由于设备更新了 DMA 内存区的数据,这样,CPU 的读写会重新从主内加载数据到 cache line,而不是使用 cache line 中的旧数据。很显然地,在调用 dma_sync_*_for_cpu(DMA_FROM_DEVICE) 之后,CPU 完成对 DMA 内存区数据操作前,都不应该再有来自设备因 DMA 动作发送过来的数据。
当 CPU 修改了 DMA 内存区的数据后,应该调用 dma_sync_*_for_device(DMA_TO_DEVICE) 系列接口,把 DMA 内存区 CPU 对应 cache line 的最新数据,刷入到 DMA 内存区,避免 DMA 传送给设备的不是最新数据,因为 CPU 写的最新数据可能还在 cache line 里面。 很显然地,在调用 dma_sync_*_for_device(DMA_TO_DEVICE) 之后,DMA 操作将 DMA 内存区数据完全传送给设备前,CPU 都不应该再发起对 DMA 内存数据的任何写操作。
在实际驱动中,你会发现有的驱动并没有显式调用 dma_sync_*_for_*() 系列接口来同步 CPU cache ,这是怎么一回事?为什么这些驱动能够正常工作?事实是,DMA 内存映射系列接口 dma_map_*() ,已经包含了 CPU cache 的同步操作,只要适当的传递 dir 参数给这些接口,就无需额外调用 dma_sync_*_for_*() 系列接口来进行 cache 同步。任选一对映射接口来看下细节。先看 映射建立接口 dma_map_single_attrs() :
static inline dma_addr_t dma_map_single_attrs(struct device *dev, void *ptr,
size_t size,
enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
dma_addr_t addr;
/* arm_dma_map_page() */
addr = ops->map_page(dev, virt_to_page(ptr),
offset_in_page(ptr), size,
dir, attrs);
return addr;
}
static dma_addr_t arm_dma_map_page(struct device *dev, struct page *page,
unsigned long offset, size_t size, enum dma_data_direction dir,
unsigned long attrs)
{
if ((attrs & DMA_ATTR_SKIP_CPU_SYNC) == 0)
__dma_page_cpu_to_dev(page, offset, size, dir); /* cahce 同步 */
return pfn_to_dma(dev, page_to_pfn(page)) + offset;
}
static void __dma_page_cpu_to_dev(struct page *page, unsigned long off,
size_t size, enum dma_data_direction dir)
{
phys_addr_t paddr;
dma_cache_maint_page(page, off, size, dir, dmac_map_area);
paddr = page_to_phys(page) + off;
if (dir == DMA_FROM_DEVICE) {
/*
* 将从设备通过 DMA 传送数据到 主存, 应将 CPU 对应 cache line 置为无效,
* 避免之后 CPU 读写旧数据.
* 同时 DMA 期间 CPU 也不应该写 DMA 缓冲.
*/
outer_inv_range(paddr, paddr + size);
} else {
/*
* 将从 主存 通过 DMA 传送数据到 设备,应将 CPU 对应 cache line 的最新数据
* 刷到主存,避免 设备 拿到的数据不是最新的。
* 同时 DMA 期间 CPU 也不应该写 DMA 缓冲.
*/
outer_clean_range(paddr, paddr + size);
}
}
再看 映射销毁接口 dma_unmap_single_attrs() :
static inline void dma_unmap_single_attrs(struct device *dev, dma_addr_t addr,
size_t size,
enum dma_data_direction dir,
unsigned long attrs)
{
const struct dma_map_ops *ops = get_dma_ops(dev);
...
if (ops->unmap_page)
ops->unmap_page(dev, addr, size, dir, attrs); /* arm_dma_unmap_page() */
...
}
static void arm_dma_unmap_page(struct device *dev, dma_addr_t handle,
size_t size, enum dma_data_direction dir, unsigned long attrs)
{
if ((attrs & DMA_ATTR_SKIP_CPU_SYNC) == 0)
__dma_page_dev_to_cpu(pfn_to_page(dma_to_pfn(dev, handle)),
handle & ~PAGE_MASK, size, dir);
}
static void __dma_page_dev_to_cpu(struct page *page, unsigned long off,
size_t size, enum dma_data_direction dir)
{
phys_addr_t paddr = page_to_phys(page) + off;
if (dir != DMA_TO_DEVICE) {
/*
* map 和 unmap 必须是成对出现的,且 dir 参数也必须是相同的。
* 进入此处代码分支表示 dir == DMA_FROM_DEVICE ,也即 DMA 数据传送方向是
* 从 设备 传送数据到 主存,在这里数据已经传送完毕,此时应该 CPU 的 对应
* cache line 置为无效: 避免 CPU 仍然使用 cache line 里的旧数据。
*/
outer_inv_range(paddr, paddr + size);
dma_cache_maint_page(page, off, size, dir, dmac_unmap_area);
}
/*
* Mark the D-cache clean for these pages to avoid extra flushing.
*/
if (dir != DMA_TO_DEVICE && size >= PAGE_SIZE) {
unsigned long pfn;
size_t left = size;
pfn = page_to_pfn(page) + off / PAGE_SIZE;
off %= PAGE_SIZE;
if (off) {
pfn++;
left -= PAGE_SIZE - off;
}
while (left >= PAGE_SIZE) {
page = pfn_to_page(pfn++);
set_bit(PG_dcache_clean, &page->flags);
left -= PAGE_SIZE;
}
}
}
基于上述分析,很显然,在调用 dma_map_*() 之后,调用 dma_unmap_*() 完成之前,CPU 都不应该去读写 DMA 缓冲的数据。
4.4 DMA 控制器
4.4.1 DMA 控制器的存在形式
DMA 控制器,可能有两种存在形式:
1. 独立于设备的 DMA 控制器,如 3.4.1 小节中那样。这样的 DMA 控制器,可以供所有连接的外设
共享传输通道(DMA Channel)。
2. 集成到设备的 DMA 控制器,这样的 DMA 控制器是某设备专享的,可通过设备的寄存器来操控它。
如相机 CSI 控制器内置的 DMA 。
4.4.2 独立于设备的 DMA 控制器驱动
这里所说的 DMA 控制器驱动,专指以 独立于设备、供所有连接设备共享的 DMA 控制器 的驱动。对于 集成到设备的 DMA 控制器 的驱动,对我们是不可见的,不在我们的讨论范围之内。
下面以 全志 H3 集成的、独立于设备的 DMA 控制器为例,来讨论 DMA 控制器的驱动,以及连接的外设是如何使用该 DMA 控制器的。
4.4.2.1 DMA 控制器驱动加载和注册
先看下 DMA 控制器的 DTS 配置:
dma: dma-controller@01c02000 {
compatible = "allwinner,sun8i-h3-dma";
reg = <0x01c02000 0x1000>;
interrupts = <GIC_SPI 50 IRQ_TYPE_LEVEL_HIGH>;
clocks = <&ccu CLK_BUS_DMA>;
resets = <&ccu RST_BUS_DMA>;
#dma-cells = <1>;
};
对应的 DMA 驱动代码:
/* drivers/dma/sun6i-dma.c */
struct sun6i_dma_dev {
struct dma_device slave; /* DMA 控制器设备 */
...
};
static const struct of_device_id sun6i_dma_match[] = {
...
{ .compatible = "allwinner,sun8i-h3-dma", .data = &sun8i_h3_dma_cfg },
...
{ /* sentinel */ }
};
MODULE_DEVICE_TABLE(of, sun6i_dma_match);
/* DMA 控制器驱动入口 */
static int sun6i_dma_probe(struct platform_device *pdev)
{
struct sun6i_dma_dev *sdc;
/* 创建 DMA 控制设备对象 */
sdc = devm_kzalloc(&pdev->dev, sizeof(*sdc), GFP_KERNEL);
...
/*
* 配置 DMA 控制器设备
*/
/* 设置 DMA 控制器支持的能力 */
dma_cap_set(DMA_PRIVATE, sdc->slave.cap_mask);
dma_cap_set(DMA_MEMCPY, sdc->slave.cap_mask);
dma_cap_set(DMA_SLAVE, sdc->slave.cap_mask);
dma_cap_set(DMA_CYCLIC, sdc->slave.cap_mask);
INIT_LIST_HEAD(&sdc->slave.channels);
...
/* 设置 DMA 控制器接口 */
sdc->slave.device_tx_status = sun6i_dma_tx_status;
sdc->slave.device_issue_pending = sun6i_dma_issue_pending;
sdc->slave.device_prep_slave_sg = sun6i_dma_prep_slave_sg;
...
sdc->slave.device_prep_dma_cyclic = sun6i_dma_prep_dma_cyclic;
...
sdc->slave.device_config = sun6i_dma_config;
...
/* 设置 DMA 控制器的 数据宽度 和 支持的传送方向 */
sdc->slave.src_addr_widths = sdc->cfg->src_addr_widths;
sdc->slave.dst_addr_widths = sdc->cfg->dst_addr_widths;
sdc->slave.directions = BIT(DMA_DEV_TO_MEM) |
BIT(DMA_MEM_TO_DEV);
...
/* 为 DMA 控制器 的 所有通道 创建设备对象 (struct virt_dma_chan) */
sdc->pchans = devm_kcalloc(&pdev->dev, sdc->num_pchans,
sizeof(struct sun6i_pchan), GFP_KERNEL);
sdc->vchans = devm_kcalloc(&pdev->dev, sdc->num_vchans,
sizeof(struct sun6i_vchan), GFP_KERNEL);
...
/* 设置用于调度 DMA 通道传输的 tasklet */
tasklet_init(&sdc->task, sun6i_dma_tasklet, (unsigned long)sdc);
...
/* 添加 DMA 通道设备对象 到 DMA 控制器 */
for (i = 0; i < sdc->num_vchans; i++) {
struct sun6i_vchan *vchan = &sdc->vchans[i];
INIT_LIST_HEAD(&vchan->node);
vchan->vc.desc_free = sun6i_dma_free_desc;
vchan_init(&vchan->vc, &sdc->slave);
}
...
/* 注册 DMA 控制器 中断处理接口: 用来护理 DMA 数据传输引发的中断 */
ret = devm_request_irq(&pdev->dev, sdc->irq, sun6i_dma_interrupt, 0,
dev_name(&pdev->dev), sdc);
/* 注册 DMA 控制器设备 到系统 */
ret = dma_async_device_register(&sdc->slave);
/* 注册 DTS DMA 解析控制器: 用于其它使用 DMA 控制器的设备,来解析 DTS 数据 */
ret = of_dma_controller_register(pdev->dev.of_node, sun6i_dma_of_xlate,
sdc);
...
return 0;
}
static struct platform_driver sun6i_dma_driver = {
.probe = sun6i_dma_probe,
.remove = sun6i_dma_remove,
.driver = {
.name = "sun6i-dma",
.of_match_table = sun6i_dma_match,
},
};
module_platform_driver(sun6i_dma_driver);
/* drivers/dma/virt-dma.c */
/* 添加 DMA 通道设备对象 到 DMA 控制器 */
void vchan_init(struct virt_dma_chan *vc, struct dma_device *dmadev)
{
dma_cookie_init(&vc->chan);
spin_lock_init(&vc->lock);
INIT_LIST_HEAD(&vc->desc_allocated);
INIT_LIST_HEAD(&vc->desc_submitted);
INIT_LIST_HEAD(&vc->desc_issued);
INIT_LIST_HEAD(&vc->desc_completed);
/* DMA 传输的 tasklet */
tasklet_init(&vc->task, vchan_complete, (unsigned long)vc);
vc->chan.device = dmadev;
list_add_tail(&vc->chan.device_node, &dmadev->channels); /* 添加 DMA 通道设备 到 DMA 控制器 */
}
/* drivers/dma/of-dma.c */
/* 注册 DTS DMA 解析控制器: 用于其它使用 DMA 控制器的设备,来解析 DTS 数据 */
int of_dma_controller_register(struct device_node *np,
struct dma_chan *(*of_dma_xlate)
(struct of_phandle_args *, struct of_dma *),
void *data)
{
struct of_dma *ofdma;
/* 创建 DTS DMA 解析控制器对象 */
ofdma = kzalloc(sizeof(*ofdma), GFP_KERNEL);
ofdma->of_node = np;
ofdma->of_dma_xlate = of_dma_xlate; /* sun6i_dma_of_xlate() */
ofdma->of_dma_data = data;
/* Now queue of_dma controller structure in list */
mutex_lock(&of_dma_lock);
list_add_tail(&ofdma->of_dma_controllers, &of_dma_list);
mutex_unlock(&of_dma_lock);
return 0;
}
好,DMA 控制器设备已经注册到系统,接下来,就是其连接的外设对其的使用了。
4.4.2.2 外设对 DMA 控制器的使用
以一个实际的 UART 驱动为例,来说明是如何使用 DMA 控制器传输数据的。先看 UART 的 DTS 配置:
uart0: serial@01c28000 {
compatible = "snps,dw-apb-uart";
reg = <0x01c28000 0x400>;
interrupts = <GIC_SPI 0 IRQ_TYPE_LEVEL_HIGH>;
...
dmas = <&dma 6>, <&dma 6>;
dma-names = "rx", "tx";
...
};
接下看 UART 控制器对 DMA 控制器 数据传送通道的 申请 和 使用(重点关注 DMA 部分):
/* drivers/tty/serial/8250/8250_port.c */
int serial8250_do_startup(struct uart_port *port)
{
...
/*
* Request DMA channels for both RX and TX.
*/
if (up->dma) {
retval = serial8250_request_dma(up);
...
}
...
}
/* drivers/tty/serial/8250/8250_dma.c */
int serial8250_request_dma(struct uart_8250_port *p)
{
...
/* Get a channel for RX */
dma->rxchan = dma_request_slave_channel_compat(mask,
dma->fn, dma->rx_param,
p->port.dev, "rx");
...
dmaengine_slave_config(dma->rxchan, &dma->rxconf);
...
/* Get a channel for TX */
dma->txchan = dma_request_slave_channel_compat(mask,
dma->fn, dma->tx_param,
p->port.dev, "tx");
...
dmaengine_slave_config(dma->txchan, &dma->txconf);
...
}
从 DMA 控制器 申请 DMA 通道:
/* include/linux/dmaengine.h */
#define dma_request_slave_channel_compat(mask, x, y, dev, name) \
__dma_request_slave_channel_compat(&(mask), x, y, dev, name)
static inline struct dma_chan
*__dma_request_slave_channel_compat(const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param,
struct device *dev, const char *name)
{
struct dma_chan *chan;
chan = dma_request_slave_channel(dev, name);
if (chan)
return chan;
...
}
/* drivers/dma/dmaengine.c */
struct dma_chan *dma_request_slave_channel(struct device *dev,
const char *name)
{
struct dma_chan *ch = dma_request_chan(dev, name);
if (IS_ERR(ch))
return NULL;
return ch;
}
struct dma_chan *dma_request_chan(struct device *dev, const char *name)
{
struct dma_chan *chan = NULL;
if (dev->of_node)
chan = of_dma_request_slave_channel(dev->of_node, name);
...
if (chan) {
/* Valid channel found or requester need to be deferred */
if (!IS_ERR(chan) || PTR_ERR(chan) == -EPROBE_DEFER)
return chan;
}
...
}
/* drivers/dma/of-dma.c */
struct dma_chan *of_dma_request_slave_channel(struct device_node *np,
const char *name)
{
struct of_phandle_args dma_spec;
struct of_dma *ofdma;
struct dma_chan *chan;
int count, i, start;
...
static atomic_t last_index;
...
count = of_property_count_strings(np, "dma-names");
start = atomic_inc_return(&last_index);
for (i = 0; i < count; i++) {
if (of_dma_match_channel(np, name,
(i + start) % count,
&dma_spec))
continue;
mutex_lock(&of_dma_lock);
ofdma = of_dma_find_controller(&dma_spec); /* 寻找匹配的 DMA 控制器 */
if (ofdma) {
/* 解析 DTS 配置,按 DTS 配置分配 DMA 控制器通道 */
chan = ofdma->of_dma_xlate(&dma_spec, ofdma); /* sun6i_dma_of_xlate() */
} else {
...
}
mutex_unlock(&of_dma_lock);
of_node_put(dma_spec.np);
if (chan)
return chan; /* 返回从 DMA 控制器申请 DMA 通道 */
}
...
}
/* drivers/dma/sun6i-dma.c */
static struct dma_chan *sun6i_dma_of_xlate(struct of_phandle_args *dma_spec,
struct of_dma *ofdma)
{
struct sun6i_dma_dev *sdev = ofdma->of_dma_data;
struct sun6i_vchan *vchan;
struct dma_chan *chan;
/*
* UART 设备的 DMA 配置:
* dmas = <&dma 6>, <&dma 6>;
* dma-names = "rx", "tx";
*/
u8 port = dma_spec->args[0];
/* 从 DMA 控制器设备 @sdev->slave 申请 DMA 通道 */
chan = dma_get_any_slave_channel(&sdev->slave);
...
vchan = to_sun6i_vchan(chan);
vchan->port = port;
return chan;
}
/* drivers/dma/dmaengine.c */
struct dma_chan *dma_get_any_slave_channel(struct dma_device *device)
{
dma_cap_mask_t mask;
struct dma_chan *chan;
dma_cap_zero(mask);
dma_cap_set(DMA_SLAVE, mask);
/* lock against __dma_request_channel */
mutex_lock(&dma_list_mutex);
chan = find_candidate(device, &mask, NULL, NULL);
mutex_unlock(&dma_list_mutex);
return IS_ERR(chan) ? NULL : chan;
}
/* 从 DMA 控制器设备 @device 申请符合条件的可用通道 */
static struct dma_chan *find_candidate(struct dma_device *device,
const dma_cap_mask_t *mask,
dma_filter_fn fn, void *fn_param)
{
/* 尝试申请一个 DMA 通道 */
struct dma_chan *chan = private_candidate(mask, device, fn, fn_param);
if (chan) {
/* Found a suitable channel, try to grab, prep, and return it.
* We first set DMA_PRIVATE to disable balance_ref_count as this
* channel will not be published in the general-purpose
* allocator
*/
dma_cap_set(DMA_PRIVATE, device->cap_mask);
device->privatecnt++;
/* 分配 DMA 控制器 的 通道 硬件资源,并标记 DMA 通道已被占用 */
err = dma_chan_get(chan);
...
}
return chan ? chan : ERR_PTR(-EPROBE_DEFER);
}
/* 尝试申请一个 DMA 通道 */
static struct dma_chan *private_candidate(const dma_cap_mask_t *mask,
struct dma_device *dev,
dma_filter_fn fn, void *fn_param)
{
struct dma_chan *chan;
if (mask && !__dma_device_satisfies_mask(dev, mask)) {
...
return NULL;
}
/* devices with multiple channels need special handling as we need to
* ensure that all channels are either private or public.
*/
if (dev->chancnt > 1 && !dma_has_cap(DMA_PRIVATE, dev->cap_mask))
list_for_each_entry(chan, &dev->channels, device_node) {
/* some channels are already publicly allocated */
if (chan->client_count) /* 通道已被使用 */
return NULL;
}
list_for_each_entry(chan, &dev->channels, device_node) {
if (chan->client_count) { /* 通道已被使用 */
...
continue;
}
if (fn && !fn(chan, fn_param)) { /* 通道通不过 fn() 过滤 */
...
continue;
}
return chan;
}
return NULL;
}
/* 分配 DMA 控制器 的 通道 硬件资源,并标记 DMA 通道已被占用 */
static int dma_chan_get(struct dma_chan *chan)
{
...
/* allocate upon first client reference */
if (chan->device->device_alloc_chan_resources) {
ret = chan->device->device_alloc_chan_resources(chan);
...
}
...
out:
chan->client_count++; /* 标记 DMA 通道 @chan 已经被占用了 */
return 0;
}
至此,UART 设备已经申请了用来 发送(TX) 和 接收(RX) 的 DMA 通道。接下来要看 UART 对 DMA 通道的使用了。
4.5 DMA 使用范例
DMA 的使用场景,我们按照 4.4.1 的划分,按 独立于设备的 DMA 控制器 和 集成到设备的 DMA 控制器 来分别进行说明。
4.5.1 DMA 控制器集成到设备的场景
先讲 集成到设备的 DMA 控制器 的情形,这种情形的 DMA 相对更为简单(复杂的工作都让集成 DMA 控制器的设备做了)。以 全志 H3 的 CSI 控制器使用集成的 DMA 控制器传输相机数据帧为例来进行说明。细节如下:
/*
* 数据从相机传给 H3 CSI 控制器的 FIFO;然后 H3 CSI 控制器再通过内置的 DMA
* 将 FIFO 里面的数据传送到主存:
* 相机 -> CSI FIFO -> 主存
*/
/*
* 1. 从 主存分配用于 DMA 的内存
*/
// 初始化 v4l2 video 设备(指代 CSI 控制器)的内存分配接口
sun6i_csi_probe()
sun6i_csi_v4l2_init(&sdev->csi)
sun6i_video_init(&csi->video, csi, "sun6i-csi")
struct vb2_queue *vidq = &video->vb2_vidq;
...
vidq->ops = &sun6i_csi_vb2_ops;
vidq->mem_ops = &vb2_dma_contig_memops; // 设置 DMA 内存分配接口
...
vdev->fops = &sun6i_video_fops;
vdev->ioctl_ops = &sun6i_video_ioctl_ops;
...
/*
* 2. 通过 CSI 控制器的寄存器,将 步骤 1 中分配的主存地址,设置为相机数据帧的目的地址
*/
// 在创建 video 设备缓冲队列时,从主存分配用于 DMA 的内存
ioctl(fd, VIDIOC_REQBUFS, ...) /* drivers/media/v4l2-core/v4l2-dev.c */
...
v4l_reqbufs()
// sun6i_video_ioctl_ops.vidioc_reqbuf = vb2_ioctl_reqbufs()
ops->vidioc_reqbufs(file, fh, p) = vb2_ioctl_reqbufs()
vb2_core_reqbufs(vdev->queue, p->memory, &p->count)
allocated_buffers = __vb2_queue_alloc(q, memory, num_buffers, num_planes, plane_sizes)
vb = kzalloc(q->buf_struct_size, GFP_KERNEL);
vb->state = VB2_BUF_STATE_DEQUEUED;
...
__vb2_buf_mem_alloc(vb) // 假定使用 VB2_MEMORY_MMAP 内存管理方式
mem_priv = call_ptr_memop(vb, alloc,
q->alloc_devs[plane] ? : q->dev,
q->dma_attrs, size, q->dma_dir, q->gfp_flags) = vb2_dc_alloc()
vb->planes[plane].mem_priv = mem_priv;
// 走了这么长的路,终于到了分配的主角 vb2_dc_alloc()
vb2_dc_alloc()
struct vb2_dc_buf *buf;
buf = kzalloc(sizeof *buf, GFP_KERNEL);
buf->cookie = dma_alloc_attrs(dev, size, &buf->dma_addr, // buf->dma_addr 是关注点
GFP_KERNEL | gfp_flags, buf->attrs);
...
// 用于 DMA 的内存分配完了,接下来告诉 CSI 控制器 的 DMA,最终把帧数据传送到分配的主存地址.
// 这个操作分两步完成:
// (1) 在 buffer 入队的过程中(VIDIOC_QBUF), 读取前面分配的 DMA 主存总线地址并记录到 CSI 驱动;
// (2) 启动数据帧传送的过程中(VIDIOC_STREAMON),设置 相机数据帧的目的地址 为 DMA 主存的总线地址。
// (1) 在 buffer 入队的过程中(VIDIOC_QBUF), 读取前面分配的 DMA 主存总线地址并记录到 CSI 驱动
ioctl(fd, VIDIOC_QBUF, ...)
...
v4l_qbuf()
vb2_core_qbuf()
__buf_prepare(vb, pb)
vb->state = VB2_BUF_STATE_PREPARING;
__prepare_mmap(vb, pb)
// sun6i_csi_vb2_ops.buf_prepare = sun6i_video_buffer_prepare()
call_vb_qop(vb, buf_prepare, vb) = sun6i_video_buffer_prepare()
// 读取前面分配的 DMA 主存的 总线地址
buf->dma_addr = vb2_dma_contig_plane_dma_addr(vb, 0);
dma_addr_t *addr = vb2_plane_cookie(vb, plane_no);
// vb2_dma_contig_memops.cookie = vb2_dc_cookie()
call_ptr_memop(vb, cookie, vb->planes[plane_no].mem_priv) = vb2_dc_cookie()
struct vb2_dc_buf *buf = buf_priv;
return &buf->dma_addr; // 正是前面分配的 DMA 主存的地址
return *addr;
vb->state = VB2_BUF_STATE_PREPARED;
// (2) 启动数据帧传送的过程中(VIDIOC_STREAMON),设置 相机数据帧的目的地址 为 DMA 主存的总线地址
ioctl(fd, VIDIOC_STREAMON, ...)
...
v4l_streamon()
// sun6i_video_ioctl_ops.vidioc_streamon = vb2_ioctl_streamon()
vb2_ioctl_streamon()
vb2_streamon(vdev->queue, i)
vb2_core_streamon(q, type)
vb2_start_streaming(q)
q->start_streaming_called = 1;
// sun6i_csi_vb2_ops.start_streaming = sun6i_video_start_streaming()
ret = call_qop(q, start_streaming, q,
atomic_read(&q->owned_by_drv_count)) = sun6i_video_start_streaming()
buf = list_first_entry(&video->dma_queue, struct sun6i_csi_buffer, list);
buf->queued_to_csi = true;
sun6i_csi_update_buf_addr(video->csi, buf->dma_addr)
/* 设置 各个 plane 的 DMA 地址 */
regmap_write(sdev->regmap, CSI_CH_F0_BUFA_REG, (addr + sdev->planar_offset[0]) >> 2);
if (sdev->planar_offset[1] != -1)
regmap_write(sdev->regmap, CSI_CH_F1_BUFA_REG, (addr + sdev->planar_offset[1]) >> 2);
if (sdev->planar_offset[2] != -1)
regmap_write(sdev->regmap, CSI_CH_F2_BUFA_REG, (addr + sdev->planar_offset[2]) >> 2);
q->streaming = 1;
/*
* 3. 当 CSI 控制器接收完 1 帧数据后,启动 DMA 将数据从 CSI 控制器的 FIFO 传输到主存
*/
// 数据接收触发 CSI 控制器中断
sun6i_csi_isr()
if (status & CSI_CH_INT_/STA_FD_PD)
sun6i_video_frame_done(&sdev->csi.video)
// 当前用于接收数据帧的 DMA 缓冲
buf = list_first_entry(&video->dma_queue,
struct sun6i_csi_buffer, list);
// 下一个用来接收数据帧的缓冲
next_buf = list_next_entry(buf, list);
next_buf->queued_to_csi = true;
sun6i_csi_update_buf_addr(video->csi, next_buf->dma_addr); // 设置下一个用来接收缓冲的 DMA 地址
// 当前缓冲已接收完数据,从缓冲队列中移出
list_del(&buf->list);
vbuf = &buf->vb;
...
// 将刚接收完数据帧的缓冲,加入到就绪队列
vb2_buffer_done(&vbuf->vb2_buf, VB2_BUF_STATE_DONE);
到此,我们已经完成了相机 DMA 数据帧的传输过程的描述。值得注意的是,例子中使用的 DMA Cache 一致性内存。
4.5.2 DMA 控制器独立于设备的场景
存在多个 DMA 内存分配 API,我们仅就 流式 DMA(需维护 Cache 一致性) 分配 API 做示范说明,其它接口的 API 读者可自行阅读相关源码。
由于我们这里描述的是 独立于设备的 DMA 控制器 场景下 的 DMA 的使用范例,所以第一步操作是向 独立于设备的 DMA 控制器 申请 DMA 通道,我们以 全志 H3 的串口驱动为例,串口驱动 申请 DMA 通道的过程详见 4.4.2.2 小节。
在申请完 DMA 通道后,我们还要申请用于 DMA 数据传输的内存,接着前面,还是以 全志 H3 的串口驱动为例,来看串口驱动 DMA 内存的申请和使用(我们只看 TX 向外传输数据的情形;RX 类似 4.5.1 小节情形,使用的是 Cache 一致性 DMA 内存):
/* drivers/tty/serial/8250/8250_port.c */
serial8250_do_startup()
serial8250_request_dma(up)
// 申请用于 TX 的 DMA 通道,详见前面 4.4.2.2
/* Get a channel for TX */
dma->txchan = dma_request_slave_channel_compat(mask,
dma->fn, dma->tx_param,
p->port.dev, "tx");
// 分配 和 映射 用于 TX 的 DMA 内存。
// 注意: 这里没有分配 DMA 内存 p->port.state->xmit.buf 的代码,
// 这块内存通常是由 tty driver core 接口 tty_port_alloc_xmit_buf() 分配的。
/* TX buffer */
// 映射串口用于 TX 的 DMA 内存,记录其映射的 总线地址 到 dma->tx_addr
dma->tx_addr = dma_map_single(dma->txchan->device->dev,
p->port.state->xmit.buf,
UART_XMIT_SIZE,
DMA_TO_DEVICE);
到此,用于串口 TX 的 DMA 通道 和 内存 已经就绪,接下来就是如何使用 DMA 通道 和 内存,将数据从 TX 传输出去了,来看细节:
/* drivers/tty/serial/8250/8250_dma.c */
serial8250_tx_dma()
// 设置传输数据量大小
dma->tx_size = CIRC_CNT_TO_END(xmit->head, xmit->tail, UART_XMIT_SIZE);
// DMA 控制器通道 的 传输准备工作(后面描述细节)
desc = dmaengine_prep_slave_single(dma->txchan,
dma->tx_addr + xmit->tail,
dma->tx_size, DMA_MEM_TO_DEV,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
dma->tx_running = 1;
desc->callback = __dma_tx_complete; /* DMA 传输完成触发的回调 */
desc->callback_param = p;
/* 提交 DMA 传输请求 */
dma->tx_cookie = dmaengine_submit(desc);
/* DMA cache 管理: 从现在起直到 DMA 传输结束,CPU 都不应该读写 DMA 内存里的数据 */
dma_sync_single_for_device(dma->txchan->device->dev, dma->tx_addr,
UART_XMIT_SIZE, DMA_TO_DEVICE);
/* 启动通道 dma->txchan 上的 DMA 传输(细节后面展开) */
dma_async_issue_pending(dma->txchan);
上面 DMA 例子中的 DMA 传输的准备工作 和 DMA 传输启动工作 有待继续展开,这样我们才能理解整个 DMA 传输过程。在展开这些细节后,我们再来说明 DMA 传输以及收尾工作。
4.5.2.1 DMA 传输的准备工作
使用 独立于设备的 DMA 控制器 传输准备工作,由头文件 include/linux/dmaengine.h 中的 dmaengine_prep_*() 系列接口完成,这些接口返回 struct dma_async_tx_descriptor 用于后续的传输工作。我们这里只说明例子中的 dmaengine_prep_slave_single() 为例进行说明:
/* include/linux/dmaengine.h */
dmaengine_prep_slave_single()
chan->device->device_prep_slave_sg(chan, &sg, 1,
dir, flags, NULL) = sun6i_dma_prep_slave_sg()
/* drivers/dma/sun6i-dma.c */
static struct dma_async_tx_descriptor *sun6i_dma_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_transfer_direction dir,
unsigned long flags, void *context)
{
struct sun6i_dma_dev *sdev = to_sun6i_dma_dev(chan->device);
struct sun6i_vchan *vchan = to_sun6i_vchan(chan);
struct dma_slave_config *sconfig = &vchan->cfg;
struct sun6i_dma_lli *v_lli, *prev = NULL;
struct sun6i_desc *txd;
struct scatterlist *sg;
dma_addr_t p_lli;
u32 lli_cfg;
int i, ret;
/* 配置传输的数据位宽 */
ret = set_config(sdev, sconfig, dir, &lli_cfg);
txd = kzalloc(sizeof(*txd), GFP_NOWAIT);
/* 使用 scatter/gather 传输 */
for_each_sg(sgl, sg, sg_len, i) {
v_lli = dma_pool_alloc(sdev->pool, GFP_NOWAIT, &p_lli);
v_lli->len = sg_dma_len(sg);
v_lli->para = NORMAL_WAIT;
if (dir == DMA_MEM_TO_DEV) { // 这是我们例子中的情形: TX
v_lli->src = sg_dma_address(sg);
v_lli->dst = sconfig->dst_addr;
v_lli->cfg = lli_cfg;
sdev->cfg->set_drq(&v_lli->cfg, DRQ_SDRAM, vchan->port);
sdev->cfg->set_mode(&v_lli->cfg, LINEAR_MODE, IO_MODE);
} else {
...
}
// 添加到 satter 列表
prev = sun6i_dma_lli_add(prev, v_lli, p_lli, txd);
}
return vchan_tx_prep(&vchan->vc, &txd->vd, flags);
}
/* drivers/dma/virt-dma.h */
static inline struct dma_async_tx_descriptor *vchan_tx_prep(struct virt_dma_chan *vc,
struct virt_dma_desc *vd, unsigned long tx_flags)
{
unsigned long flags;
dma_async_tx_descriptor_init(&vd->tx, &vc->chan);
vd->tx.flags = tx_flags;
vd->tx.tx_submit = vchan_tx_submit;
vd->tx.desc_free = vchan_tx_desc_free;
spin_lock_irqsave(&vc->lock, flags);
list_add_tail(&vd->node, &vc->desc_allocated);
spin_unlock_irqrestore(&vc->lock, flags);
return &vd->tx;
}
/* drivers/dma/dmaengine.c */
void dma_async_tx_descriptor_init(struct dma_async_tx_descriptor *tx,
struct dma_chan *chan)
{
tx->chan = chan;
#ifdef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
spin_lock_init(&tx->lock);
#endif
}
好的,传输的准备工作已经完成。接下来,通过接口 dmaengine_submit() 把传输请求提交到 DMA 通道:
/* include/linux/dmaengine.h */
static inline dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
{
return desc->tx_submit(desc); /* vchan_tx_submit(), 由前述准备工作设置 */
}
/* drivers/dma/virt-dma.c */
dma_cookie_t vchan_tx_submit(struct dma_async_tx_descriptor *tx)
{
struct virt_dma_chan *vc = to_virt_chan(tx->chan);
struct virt_dma_desc *vd = to_virt_desc(tx);
unsigned long flags;
dma_cookie_t cookie;
spin_lock_irqsave(&vc->lock, flags);
cookie = dma_cookie_assign(tx);
list_move_tail(&vd->node, &vc->desc_submitted); /* 提交 DMA 传输请求 */
spin_unlock_irqrestore(&vc->lock, flags);
return cookie;
}
4.5.2.2 DMA 传输启动工作
DMA 驱动引擎提供接口 dma_async_issue_pending() 调度 DMA 传输工作:
/* include/linux/dmaengine.h */
static inline void dma_async_issue_pending(struct dma_chan *chan)
{
/* 调用 DMA 控制器驱动 的接口 调度 DMA 传输 */
chan->device->device_issue_pending(chan); /* sun6i_dma_issue_pending() */
}
/* drivers/dma/sun6i-dma.c */
static void sun6i_dma_issue_pending(struct dma_chan *chan)
{
struct sun6i_dma_dev *sdev = to_sun6i_dma_dev(chan->device);
struct sun6i_vchan *vchan = to_sun6i_vchan(chan);
unsigned long flags;
spin_lock_irqsave(&vchan->vc.lock, flags);
if (vchan_issue_pending(&vchan->vc)) { /* 有挂起的 DMA 传输工作 */
spin_lock(&sdev->lock);
if (!vchan->phy && list_empty(&vchan->node)) {
list_add_tail(&vchan->node, &sdev->pending);
tasklet_schedule(&sdev->task); /* 调度 DMA 传输 (sun6i_dma_tasklet()) */
}
spin_unlock(&sdev->lock);
} else {
...
}
spin_unlock_irqrestore(&vchan->vc.lock, flags);
}
4.5.2.3 DMA 传输以及收尾工作
某个中断发生后,softirq 调度 tasklet 执行,其中包括我们的 DMA 传输 tasklet :
irq_exit()
__do_softirq()
h->action(h) = tasklet_action()
t->func(t->data) = sun6i_dma_tasklet()
/* drivers/dma/sun6i-dma.c */
/* 启动 DMA 通道的 DMA 传输 以及 中断 */
static void sun6i_dma_tasklet(unsigned long data)
{
struct sun6i_dma_dev *sdev = (struct sun6i_dma_dev *)data;
struct sun6i_vchan *vchan;
struct sun6i_pchan *pchan;
unsigned int pchan_alloc = 0;
unsigned int pchan_idx;
list_for_each_entry(vchan, &sdev->slave.channels, vc.chan.device_node) {
spin_lock_irq(&vchan->vc.lock);
pchan = vchan->phy;
if (pchan && pchan->done) {
if (sun6i_dma_start_desc(vchan)) {
...
}
}
spin_unlock_irq(&vchan->vc.lock);
}
...
}
上面是真正开始做 DMA 数据的传输,数据传输完成后,会产生 DMA 中断,进入 DMA 控制器的中断处理:
/* drivers/dma/sun6i-dma.c */
static irqreturn_t sun6i_dma_interrupt(int irq, void *dev_id)
{
struct sun6i_dma_dev *sdev = dev_id;
struct sun6i_vchan *vchan;
struct sun6i_pchan *pchan;
int i, j, ret = IRQ_NONE;
u32 status;
for (i = 0; i < sdev->num_pchans / DMA_IRQ_CHAN_NR; i++) {
status = readl(sdev->base + DMA_IRQ_STAT(i)); /* 读取 DMA 通道的中断状态 */
if (!status) /* 通道 @i 没有中断发生 */
continue;
writel(status, sdev->base + DMA_IRQ_STAT(i));
for (j = 0; (j < DMA_IRQ_CHAN_NR) && status; j++) {
pchan = sdev->pchans + j;
vchan = pchan->vchan;
if (vchan && (status & vchan->irq_type)) {
if (vchan->cyclic) { /* 环形缓冲, 收尾相接, 串口驱动使用环形缓冲 */
vchan_cyclic_callback(&pchan->desc->vd);
} else {
spin_lock(&vchan->vc.lock);
vchan_cookie_complete(&pchan->desc->vd);
pchan->done = pchan->desc;
spin_unlock(&vchan->vc.lock);
}
}
}
/* 重新调度 DMA 控制器的 tasklet (sun6i_dma_tasklet()) */
if (!atomic_read(&sdev->tasklet_shutdown))
tasklet_schedule(&sdev->task);
ret = IRQ_HANDLED;
}
return ret;
}
/* drivers/dma/virt-dma.h */
static inline void vchan_cyclic_callback(struct virt_dma_desc *vd)
{
struct virt_dma_chan *vc = to_virt_chan(vd->tx.chan);
vc->cyclic = vd;
tasklet_schedule(&vc->task); /* vchan_complete() */
}
static inline void vchan_cookie_complete(struct virt_dma_desc *vd)
{
struct virt_dma_chan *vc = to_virt_chan(vd->tx.chan);
dma_cookie_t cookie;
cookie = vd->tx.cookie;
dma_cookie_complete(&vd->tx);
list_add_tail(&vd->node, &vc->desc_completed);
tasklet_schedule(&vc->task);
}
在 DMA 传输中断退出时,DMA 控制器中断处理流程中调度的、处理 DMA 传输收尾工作的 tasklet 得以执行:
/* drivers/dma/virt-dma.c */
static void vchan_complete(unsigned long arg)
{
...
dmaengine_desc_callback_invoke(&cb, NULL);
...
}
/* drivers/dma/dmaengine.h */
static inline void
dmaengine_desc_callback_invoke(struct dmaengine_desc_callback *cb,
const struct dmaengine_result *result)
{
struct dmaengine_result dummy_result = {
.result = DMA_TRANS_NOERROR,
.residue = 0
};
if (cb->callback_result) {
...
} else {
/* drivers/tty/serial/8250/8250_dma.c: __dma_tx_complete() */
cb->callback(cb->callback_param);
}
}
/* drivers/tty/serial/8250/8250_dma.c */
static void __dma_tx_complete(void *param)
{
...
/* DMA cache 一致性处理工作, 好了, CPU 可以读写 DMA 缓冲的数据了 */
dma_sync_single_for_cpu(dma->txchan->device->dev, dma->tx_addr,
UART_XMIT_SIZE, DMA_TO_DEVICE);
spin_lock_irqsave(&p->port.lock, flags);
dma->tx_running = 0;
xmit->tail += dma->tx_size;
xmit->tail &= UART_XMIT_SIZE - 1;
p->port.icount.tx += dma->tx_size;
if (uart_circ_chars_pending(xmit) < WAKEUP_CHARS)
uart_write_wakeup(&p->port);
ret = serial8250_tx_dma(p); /* 再一次发起 串口 TX DMA */
if (ret) {
p->ier |= UART_IER_THRI;
serial_port_out(&p->port, UART_IER, p->ier);
}
spin_unlock_irqrestore(&p->port.lock, flags);
}
到此,所有的 DMA 工作已经完成了,过程有些复杂,我们来简单总结一下:
1. 申请 DMA 通道 和 用于 DMA 传输的内存。
2. CPU 初始化 DMA 内存中要传输的数据,然后将 DMA 主存地址映射到总线地址,并处理好
传输前的 Cache 一致性工作。在传输完成前,CPU 都不再应该访问 DMA 内存中的数据。
3. 通过接口 dmaengine_prep_*() 创建指代 DMA 传输工作的 DMA 传输描述符。
4. 通过接口 dmaengine_submit() 将步骤 3 中建立的 DMA 传输描述符 提交 DMA 传输工作。
5. 通过接口 dma_async_issue_pending() 启动 步骤 4 中提交的 DMA 传输工作。
6. 步骤 5 调度了用于 DMA 传输的 tasklet,某中断发生退出时调度该 tasklet 启动 DMA 数据传输。
7. DMA 数据传输完成后,触发 DMA 中断,处理 DMA 中断时,重新调度 DMA 传输的 tasklet;同时调度
处理本次 DMA 完成收尾工作 tasklet (vchan_complete()) 。
8. 本次 DMA 传输中断退出时,调用 vchan_complete() 处理本次 DMA 传输完成的收尾工作。
5. 参考资料
https://embedded.fm/blog/2017/2/20/an-introduction-to-dma
内核文档:Documentation/DMA-API-HOWTO.txt