多线程-初阶
- 4. 多线程带来的的风险-线程安全 (重点)
- 4.1 观察线程不安全
- 原因是 1.load 2. add 3. save
- 4.2 线程安全的概念
- 4.3 线程不安全的原因
- 最根本的是 操作系统对线程的调度是随机的
- ★1. 修改共享数据(多个线程修改同一个变量)
- ★2. 操作不是原子性
- ★3. 可见性
- ★4. 代码顺序性
- 4.4 解决之前的线程不安全问题
4. 多线程带来的的风险-线程安全 (重点)
4.1 观察线程不安全
static class Counter {
public int count = 0;
void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}
大家观察下是否适用多线程的现象是否一致?同时尝试思考下为什么会有这样的现象发生呢?
原因是 1.load 2. add 3. save

注意:可能会导致 小于5w
4.2 线程安全的概念
想给出一个线程安全的确切定义是复杂的,但我们可以这样认为:
如果多线程环境下代码运行的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的
4.3 线程不安全的原因

最根本的是 操作系统对线程的调度是随机的
★1. 修改共享数据(多个线程修改同一个变量)
上面的线程不安全的代码中, 涉及到多个线程针对 counter.count 变量进行修改.
此时这个 counter.count 是一个多个线程都能访问到的 “共享数据”
counter.count 这个变量就是在堆上. 因此可以被多个线程共享访问
★2. 操作不是原子性

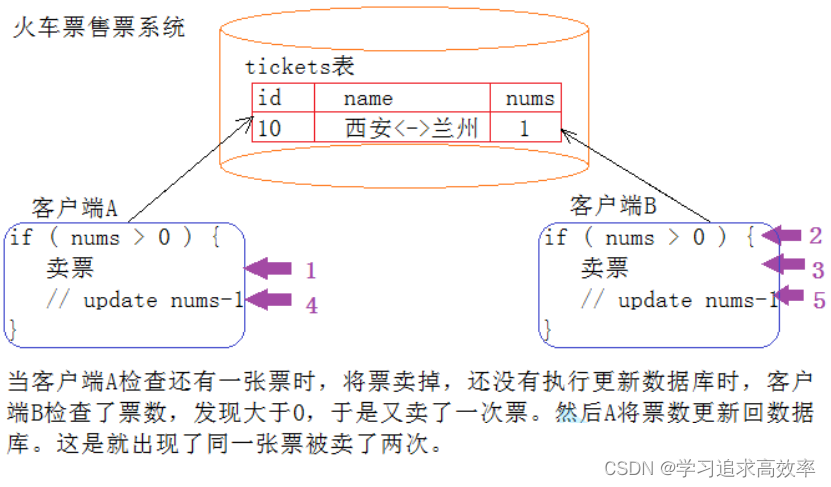
什么是原子性
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,A进入房间之后,还没有出来;B 是不是也可以进入房间,打断 A 在房间里的隐私。这个就是不具备原子性的。
那我们应该如何解决这个问题呢?是不是只要给房间加一把锁,A 进去就把门锁上,其他人是不是就进不来了。这样就保证了这段代码的原子性了。
有时也把这个现象叫做同步互斥,表示操作是互相排斥的
一条 java 语句不一定是原子的,也不一定只是一条指令
比如刚才我们看到的 n++,其实是由三步操作组成的:
- 从内存把数据读到 CPU
- 进行数据更新
- 把数据写回到 CPU
不保证原子性会给多线程带来什么问题
如果一个线程正在对一个变量操作,中途其他线程插入进来了,如果这个操作被打断了,结果就可能是错误的。
这点也和线程的抢占式调度密切相关. 如果线程不是 “抢占” 的, 就算没有原子性, 也问题不大.
★3. 可见性
可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到
Java 内存模型 (JMM): Java虚拟机规范中定义了Java内存模型.
目的是屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果.
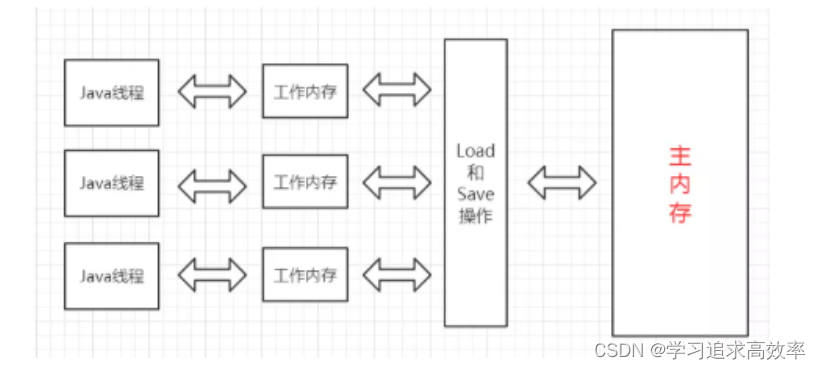
- 线程之间的共享变量存在 主内存 (Main Memory).
- 每一个线程都有自己的 “工作内存” (Working Memory) .
- 当线程要读取一个共享变量的时候, 会先把变量从主内存拷贝到工作内存, 再从工作内存读取数据.
- 当线程要修改一个共享变量的时候, 也会先修改工作内存中的副本, 再同步回主内存
由于每个线程有自己的工作内存, 这些工作内存中的内容相当于同一个共享变量的 “副本”. 此时修改线程1 的工作内存中的值, 线程2 的工作内存不一定会及时变化
- 初始情况下, 两个线程的工作内存内容一致
- 一旦线程1 修改了 a 的值, 此时主内存不一定能及时同步. 对应的线程2 的工作内存的 a 的值也不一定能及时同步.
这个时候代码中就容易出现问题


此时引入了两个问题:
- 为啥要整这么多内存?
- 为啥要这么麻烦的拷来拷去?
- 为啥整这么多内存?
实际并没有这么多 “内存”. 这只是 Java 规范中的一个术语, 是属于 “抽象” 的叫法.
所谓的 “主内存” 才是真正硬件角度的 “内存”. 而所谓的 “工作内存”, 则是指 CPU 的寄存器和高速缓存.- 为啥要这么麻烦的拷来拷去?
因为 CPU 访问自身寄存器的速度以及高速缓存的速度, 远远超过访问内存的速度(快了 3 - 4 个数量级, 也就是几千倍, 上万倍)比如某个代码中要连续 10 次读取某个变量的值, 如果 10 次都从内存读, 速度是很慢的. 但是如果
只是第一次从内存读, 读到的结果缓存到 CPU 的某个寄存器中, 那么后 9 次读数据就不必直接访问
内存了. 效率就大大提高了那么接下来问题又来了, 既然访问寄存器速度这么快, 还要内存干啥??
答案就是一个字: 贵值的一提的是, 快和慢都是相对的. CPU 访问寄存器速度远远快于内存, 但是内存的访问速度又远远快于硬盘.
对应的, CPU 的价格最贵, 内存次之, 硬盘最便宜
★4. 代码顺序性
什么是代码重排序
一段代码是这样的:
- 去前台取下 U 盘
- 去教室写 10 分钟作业
- 去前台取下快递
如果是在单线程情况下,JVM、CPU指令集会对其进行优化,比如,按 1->3->2的方式执行,也是没问题,可以少跑一次前台。这种叫做指令重排序
编译器对于指令重排序的前提是 “保持逻辑不发生变化”. 这一点在单线程环境下比较容易判断, 但是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价
重排序是一个比较复杂的话题, 涉及到 CPU 以及编译器的一些底层工作原理, 此处不做过多讨论
4.4 解决之前的线程不安全问题
这里用到的机制,我们马上会给大家解释
static class Counter {
public int count = 0;
synchronized void increase() {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
final Counter counter = new Counter();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter.count);
}










![[论文分享]SimMIM:一种简单的掩模图像建模框架](https://img-blog.csdnimg.cn/img_convert/26267f694370dd3ec076748bfb3a0323.png)