论文笔记--TinyBERT: Distilling BERT for Natural Language Understanding
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 Transformer Distillation
- 3.2 两阶段蒸馏
- 4. 数值实验
- 5. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:TinyBERT: Distilling BERT for Natural Language Understanding
- 作者:Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu
- 日期:2019
- 期刊:arxiv preprint
2. 文章概括
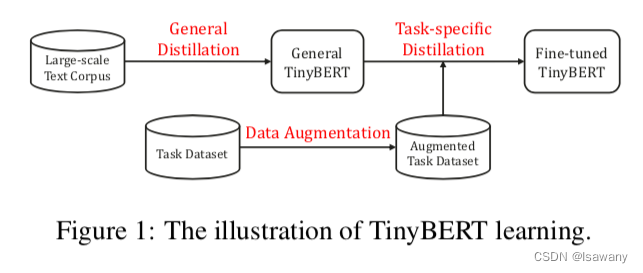
文章提出了一种两阶段的BERT蒸馏模型TinyBERT。TinyBERT在GLUE上击败了所有当前的SOTA蒸馏BERT模型[1],且参数量仅为SOTA的38%,推理时间仅为SOTA的31%。此外TinyBERT在所有GLUE任务中平均表现约为96.8%,几乎完美还原BERT的能力。
TinyBERT的整体学习步骤如下
3 文章重点技术
3.1 Transformer Distillation
所谓Transformer Distillation(TD),即对Transformer架构的蒸馏。假设教师模型和学生模型的层数分别为 N N N和 M M M,则首先定义一个映射函数 n = g ( m ) n=g(m) n=g(m)表示用学生模型的第 m m m层去学习教师模型的第 n = g ( m ) n=g(m) n=g(m)层的信息。文章通过数值实验选用了 g ( m ) = 3 m g(m)=3m g(m)=3m。定义第 0 0 0层为嵌入层,第 M + 1 M+1 M+1层为预测层,则我们可以将模型的损失函数写作 L m o d e l = ∑ x ∈ X ∑ m = 0 M + 1 λ m L l a y e r ( f m S ( x ) , f g ( m ) T ( x ) ) (1) \mathcal{L}_{model} = \sum_{x\in\mathcal{X}} \sum_{m=0}^{M+1} \lambda_m \mathcal{L}_{layer} (f_m^S(x), f_{g(m)}^T(x)) \tag{1} Lmodel=x∈X∑m=0∑M+1λmLlayer(fmS(x),fg(m)T(x))(1),其中 L l a y e r \mathcal{L}_{layer} Llayer表示 l a y e r layer layer层的损失函数, f m S ( x ) , f g ( m ) T ( x ) f_m^S(x), f_{g(m)}^T(x) fmS(x),fg(m)T(x)分别表示学生和教师模型在第 m m m或 g ( m ) g(m) g(m)层的函数, λ m \lambda_m λm为超参数,表示第 m m m层的重要性。下面为针对不同层的蒸馏方式
- Transformer-layer Distillation:

如上图所示,Transformer-layer Distillation包含以下两种蒸馏方法- Attention based distillation:蒸馏注意力机制矩阵,损失函数为 L a t t n = 1 h ∑ i = 1 h M S E ( A i S , A i T ) (2) \mathcal{L}_{attn} = \frac 1h \sum_{i=1}^h MSE(A_i^S, A_i^T) \tag{2} Lattn=h1i=1∑hMSE(AiS,AiT)(2),其中 h h h为多头注意力机制的head数目, M S E MSE MSE表示Mean Squared Error, A i S , A i T A_i^S, A_i^T AiS,AiT分别表示学生模型和教师模型的注意力矩阵。
- hidden tsates based distillation:蒸馏隐藏层(即FFN的输出层)状态,蒸馏的损失函数为 L h i d n = M S E ( H S W h , H T ) (3) \mathcal{L}_{hidn} = MSE(H^SW_h, H^T) \tag{3} Lhidn=MSE(HSWh,HT)(3),其中 H S , H T H^S, H^T HS,HT分别表示学生模型和教师模型的隐藏层状态, W h W_h Wh为可学习的参数,旨在将学生模型的隐藏向量映射到和教师模型隐藏状态相同的高维空间
- Embedding-layer Distillation:对嵌入层进行蒸馏,损失函数为 L e m b d = M S E ( E S W e , E T ) (4) \mathcal{L}_{embd} = MSE(E^SW_e, E^T) \tag{4} Lembd=MSE(ESWe,ET)(4),其中 E S , E T E^S, E^T ES,ET分别表示学生模型和教师模型的嵌入层向量, W e W_e We和上述 W h W_h Wh作用相同,旨在将学生模型的嵌入向量映射到和教师模型嵌入向量相同的高维空间
- Prediction-layer Distillation:采用损失函数
L
p
r
e
d
=
C
E
(
z
T
/
t
,
z
S
/
t
)
(5)
\mathcal{L}_{pred} =CE(z^T/t, z^S/t) \tag{5}
Lpred=CE(zT/t,zS/t)(5),其中
z
S
,
z
T
z^S, z^T
zS,zT分别表示学生模型和教师模型的输出logits,
t
t
t表示蒸馏的温度。此设置参考原始蒸馏论文中的设置。
最后,将上述所有损失函数进行统一,得到 ( 1 ) (1) (1)式中的损失函数可表示为 L l a y e r = { L e m b d , m = 0 L h i d n + L a t t n , M ≥ m > 0 L p r e d , m = M + 1 \mathcal{L}_{layer} = \begin{cases}\mathcal{L}_{embd}, &m = 0\\\mathcal{L}_{hidn} + \mathcal{L}_{attn}, &M\ge m >0\\\mathcal{L}_{pred}, &m=M+1\end{cases} Llayer=⎩ ⎨ ⎧Lembd,Lhidn+Lattn,Lpred,m=0M≥m>0m=M+1
3.2 两阶段蒸馏
TinyBERT采用两阶段蒸馏:general distillation和task-specific distillation,每一步骤通过上节介绍的蒸馏方式进行蒸馏
- General Distillation:使用原始的BERT模型作为教师模型在大量无标注文本语料库上蒸馏得到General TinyBERT
- Task-specific Distillation:通过数据增强构造一个下游任务的数据集,使用微调后的BERT在增强后的数据集上对general TinyBERT进行蒸馏,得到TinyBERT模型,这里相当于使用general TinyBERT作为第二次蒸馏的初始模型。具体来说,文章采用的数据增强方法为:首先使用BERT/GloVe预测随机掩码掉的单词,然后使用最相近的单词代替掩码位置,并随机将其增强入数据集。具体算法如下

4. 数值实验
文章用BERT[1]原文训练方法训练了和TinyBERT模型大小相同的
BERT
TINY
\text{BERT}_{\text{TINY}}
BERTTINY模型,对比
BERT
TINY
\text{BERT}_{\text{TINY}}
BERTTINY,TinyBERT,
BERT
BASE
\text{BERT}_{\text{BASE}}
BERTBASE,DistilBERT[2]等先进的BERT蒸馏模型,得到以下实验结果
-
BERT
TINY
\text{BERT}_{\text{TINY}}
BERTTINY相比于
BERT
BASE
\text{BERT}_{\text{BASE}}
BERTBASE 性能下降很多
- TinyBERT相比于 BERT TINY \text{BERT}_{\text{TINY}} BERTTINY有大幅的性能提升,说明文章提出的KD算法是有效的
- TinyBERT和当前的SOTA蒸馏模型(DistilBERT)等相比参数量降低28%,推理速度快3.1倍,且模型表现提升了4.4%
- TinyBERT相比于KaTeX parse error: Expected '}', got 'EOF' at end of input: …T}_{\text{BASE}参数量降低7.5倍,速度快9.4倍,效果为BERT的96.8%,基本还原BERT能力
5. 文章亮点
文章提出了对Transformer的两阶段蒸馏方法,相比于当前的SOTA蒸馏模型速度更快、参数量更小、表现更加出色。TinyBERT基本完美还原BERT在GLUE任务上的分析能力,可在对存储、运行效率要求更高的场景,如移动设备,作为BERT的替代模型。
5. 原文传送门
TinyBERT: Distilling BERT for Natural Language Understanding
6. References
[1] 论文笔记–BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] 论文笔记–DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter