前向传播之-得分函数
1.1 得分函数:
剧透:深度学习必备的两个大知识点分别是前向传播和反向传播啦,这里节课我们会先着手把前方传播的所涉及的所有知识点搞定!我相信这部分对于咱们即便没有什么基础的同学来说也是很容易理解的。
得分函数:这个就是咱们这节课最核心的一个问题啦。什么叫得分函数呢?下面这个图就给了我们一个最直接的答案!

得分函数的目的:我们要做的就是对于一个给定的输入,比如一张小猫的图片,通过一系列复杂的变换(中间的过程咱们暂且当做一个黑盒子)能得到这个输入对应于每个类别的得分数值。
可能有些同学对于一个输入的图片如何计算出它的得分还有点困惑,这里我简单的来说一下从输入到输出的一个矩阵计算过程。
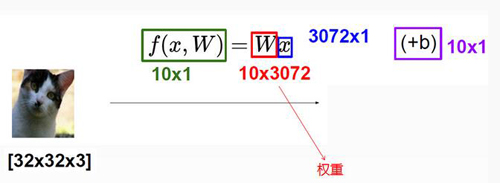
矩阵求解过程理解:首先对于一个32 * 32 * 3的输入,我们把它拉伸成一个列向量,也就是一个3072 * 1的向量,咱们下面用最简单的线性分类来解释整个过程,在线性分类中,我们需要权重参数W和偏移量B,那么W是整个线性分类的核心参数,我们要把一个输入分成10个类别并且对于每个类别给定一个得分数值,这样咱们的W参数矩阵就是一个10*3072的矩阵,我们可以通俗的理解成对于每一个类别我们都有3072个小参数去和咱们的输入(3072维的列向量)去计算最终的的分值,那么10就是我们最终要输入多少个类别。参数B就很好理解啦,这里咱们就不说啦。

得分函数计算实例:上图就是一个得分函数计算的最简单的一个流程,我们假设图像是有4个像素点组成的,然后咱们把它拉成了一个列向量(Xi),权重参数W是一个3*4的矩阵**(这里3行,是代表三个分类:猫、狗、船)(每行有四个值:分别代表着四个像素点的权重。W越大,说明这个像素点越是区分的依据)**,因为咱们要把输入分成三个类别,最终再加上参数b得到了最终这只小猫属于每个类别的得分数值。最终得出-96.8 、437.9、61.95这三个结果,根据这三个中结果值最大的437.9判定出这个图像是狗(当然这个结果是错的,他的损失函数比较大,不准确)
如何计算出最终的-96.8 、437.9、61.95这几个结果呢。
以437.9为例:
(0.2 * 56 )+ (-0.5* 231)+ (0.1 * 24) + (2.0 * 2) + 3.2 = 437.9
1.2 决策边界:
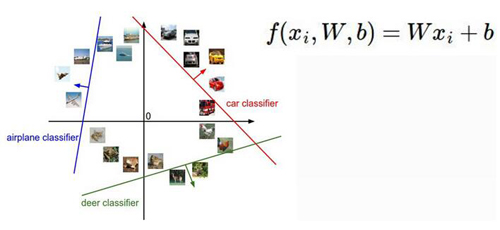
理解参数W和b:下面咱们再通过这张图来形象的理解下参数W和b,在真实的情况下对于每一个类别的参数W是一个3072维的,但是咱们为了形象化理解把它画在了2维的空间中,我们可以从图中看到三种颜色的线代表了三个线性分类器,参数W的每一个小权重的改变(共有3072个小权重)意味着这条线在改变的小参数的那个维度发生了偏转,我们可以想象2维空间中对于W的改变意味着什么然后再去想象这个3072维的空间。那么这个b参数是不是就没用呢?(有用你干嘛一直不说?)其实参数b是比不可少的,因为如果没有b那么所有的分类线都会交集与零点,这显然是不可取的嘛。
小总结:咱们这节课很轻松吧,但是如何从一个输入计算出它最终属于每一个类别的得分在一个实际的深度学习网络中可没这么简单就搞定,我这样做只是让大家能更好的理解这个得分函数。
1.3 Softmax分类器:
- 什么是Softmax分类器?
把得分值转换成一个概率

- 蓝色框:
是我们通过“得分函数”计算出来的值
-
红色框:
e的x次方(其中x就是蓝色框中我们得出来的值),为什么要这么做呢???e的x函数是爆炸式增长函数,放大差距,使他们的差距看起来更明显。
-
绿色框:
归一化处理,就是 24.5/ (24.5+164+0.8) = 0.13
-
损失函数L:
通过log对数函数来计算, 概率值越x接近1 ==>L越接近0,说明我们做的越好,损失越小

1.4 前向传播:
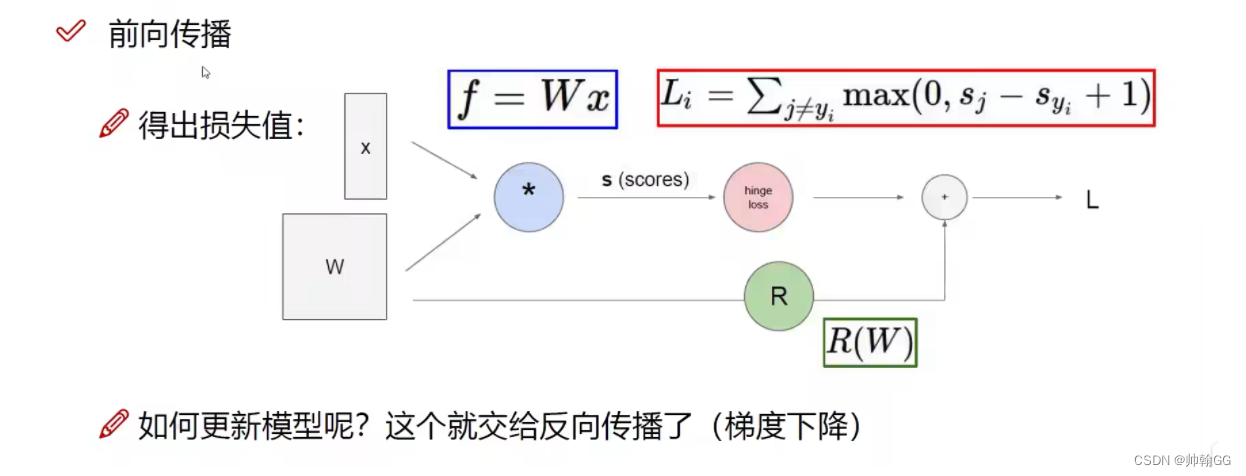
- 对“前向传播”的解释:
通过W(权重),Xi 计算出 损失值(LOSS)
1.5 引出 反向传播:
因为 前向传播计算出Loss损失函数,那么xi是给定的,我们只有通过修改W(权重),来进行梯度下降,一点一点修改我们的函数(修改W,让他变成损失值越来越小的函数)。
那么如何更新模型呢???这个就交给了反向传播(梯度下降)
【注释】:
32 * 32 *3来历:
其实我们计算机上看到的图像是0~255的像素点(0最暗,225最亮),*3是一个三维度GRB图像(分别代表红、绿、蓝),三维图像合并在一起。