2-3高可用设计
高可用复杂度模型
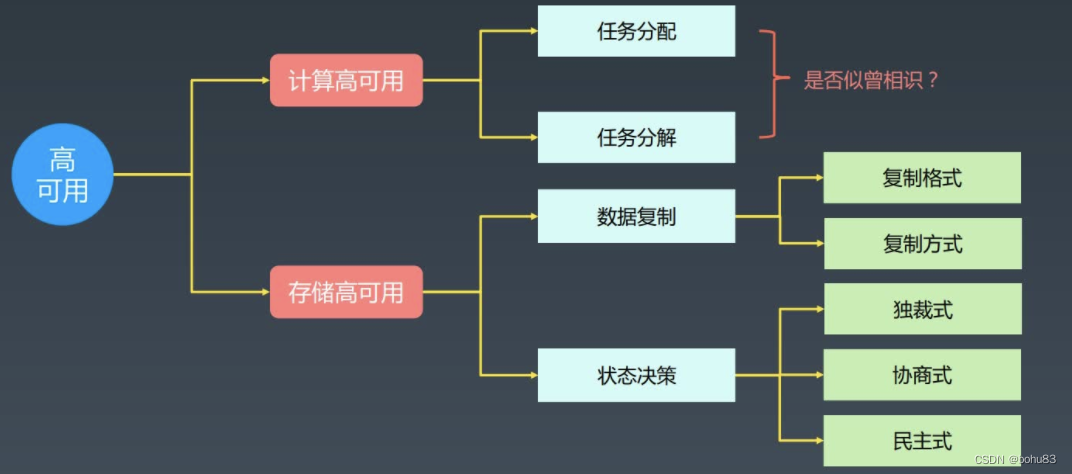
分为计算高可用,存储高可用,高可用本质上需要冗余,这里是集群,没有单机。
计算高可用:分为任务分配与任务分解。
计算高可用对比之前的高性能,就是多了状态检测。
任务分配:
将任务分配给多个服务器执行
改动点:任务分配器需要监控业务服务器的状态,在故障时进行切换

任务分解:
将服务器拆分为不同角色,不同服务器处理不同的业务
任务分解器需要监控业务服务器的状态,在故障时进行切换

存储高可用复杂度模型
包含数据复制和状态决策

数据复制格式
复制命令
【优缺点】1)实现简单,复制数据量小2)数据可能不一致(SQL函数)
【适应场景】增量复制
复制数据
【优缺点】1)实现简单2)保证数据一致3)复制流量可能会很大
【适应场景】增量复制
复制文件(数据块)
【优缺点】1)实现复杂,复制的时候数据在变2)保证数据一致3)复制流量可能会很大
【适应场景】全量复制
数据复制方式

同步复制:
【优缺点】1)最强一致性,故障容忍度低2)写入性能低【适应场景】主备/主从架构
异步复制:
【优缺点】1)写入性能高,故障容忍度高2)容易出现数据不一致【适应场景】数据存储集群
 半同步复制
半同步复制
【优缺点】同步复制和异步复制的折衷方案【适应场景】数据存储集群
多数复制:
【优缺点】1.数据强一致性,最强可用性,故障容忍度高2.写入性能不高,实现复杂【适应场景】分布式一致性、分布式协同(OceanBase)
高可用存储中间件:
redis :复制格式:命令+文件(RDB)复制方式:异步+wait(指定半同步)
hadoop 复制格式:数据块(Block)复制方式:Replication Pipelining
Mysql:复制格式:命令(statement)+数据(Row)复制方式:异步+半同步
存储高可用状态决策-独裁式
【优缺点】1)决策逻辑简单2)决策者要做到高可用,整体架构复杂,常用ZooKeeper/Raft/Keepalived3)数据一致性强度中等
【应用场景】绝大部分业务都可以应用
案例:Redis:使用sentinel集群来解决“决策者”单点问题,sentinel又是通过Raft算法进行选举的。
Hadoop:使用Zookeeper集群来解决“决策者”单点问题。
存储高可用状态决策-协商式
【优缺点】1)架构实现简单,决策逻辑简单,一般是心跳机制2)如果是链路问题,会导致双主,可以用双通道来缓解3)数据一致性弱
【应用场景】内部系统、网络设备(用串口相连)
存储高可用状态决策-民主式/选举式
【优缺点】1)决策过程复杂,决策逻辑复杂,一般用标准算法进行选举,例如Raft、ZAB、Paxos2)可用性最高,数据一致性最强3)可能出现“脑裂”问题,可以采用quorum来控制
【应用场景】对数据一致性要求很高的场景,例如余额、库存
ZooKeeper:基于ZAB算法选举
2-4 如何全面提升架构设计的质量?
低成本
低成本本质上是对架构的一种约束,与高性能、高可用等架构是冲突的。
先设计架构方案,再看如何降低成本!
降低成本方式:
优化:1.引入缓存2.虚拟化3.性能调优4.采用高性能硬件5.采用开源方案
创新:1.NoSQLvsSQL2.SQLvs倒排索引3.HadoopvsMySQL4.FacebookHHVM5.云计算/K8s弹性集群
安全性

分为架构安全与业务安全,架构设计主要解决架构安全问题,业务安全更多依赖具体技术实现。

案例的DDos攻击通常是运营商阿里云这种提供了防护措施。
业务安全:

可测试性/可维护性/可观测性
可测试性:
软件系统在测试环境下能否方便的支持测试各种场景的能力

可维护性

可观测性

可观测性本质上是应用输出信息,可维护、可测试类似,都是为了解决问题。
架构设计步骤