论文地址:原文
代码实现
中文翻译
一、精读论文
论文题目
PRUNING FILTER IN FILTER
论文作者
Fanxu Meng 孟繁续
刊物名称
NeurIPS 2020
出版日期
2020
摘要
剪枝已成为现代神经网络压缩和加速的一种非常有效的技术。现有的剪枝方法可分为两大类:滤波器剪枝(FP)和权重剪枝(WP)。与WP相比,FP在硬件兼容性方面胜出,但在压缩比方面失败。为了收敛两种方法的强度,我们提出在滤波器中对滤波器进行剪枝。具体来说,我们将滤波器F∈RC×K×K视为K个×K条,即1 × 1个滤波器∈RC,然后通过修剪条纹而不是整个滤波器,我们可以在硬件友好的同时实现比传统FP更细的粒度。我们称我们的方法为SWP (Stripe-Wise Pruning)。SWP的实现是通过引入一个新的可学习的矩阵,称为滤波器骨架,其值反映了每个滤波器的形状。正如一些最近的工作表明,修剪的结构比继承的重要权值更重要,我们认为单个过滤器的结构,即形状,也很重要。通过大量的实验,我们证明了SWP比之前基于fp的方法更有效,并在cifa10和ImageNet数据集上实现了最先进的剪枝率,而精度没有明显下降。有关代码载于[this url].
关键词
剪枝、SWP
总结
这篇文章的工作总结为:
认为隐含在滤波器参数中的形状属性是很重要的。
用滤波器骨架(Filter Skeleton)学习滤波器形状,将形状和参数分离。
以滤波器的任意一条(Stripe)为单位,将滤波器裁剪为任意形状。
通过卷积计算方式变换,结构化实现逐条剪枝(Stripe-Wise Pruning)。
二、研读总结(分三段总结,500字左右)
1、 针对问题与解决方法
这篇文章主要考虑的是神经网络的结构属性。他这里的做法很有启发性,结合了两种结构化和非结构化剪枝中的典型方法。就是对weights剪枝和对filters剪枝,因为这两种剪枝方法各有优劣。非结构化的剪枝在硬件方面需要有专用的库支持,但是它的压缩率较高,对filters剪枝在硬件方面更兼容,但在压缩率方面不如前者。所以作者提出了一个方法,叫做在filters中剪枝filter。
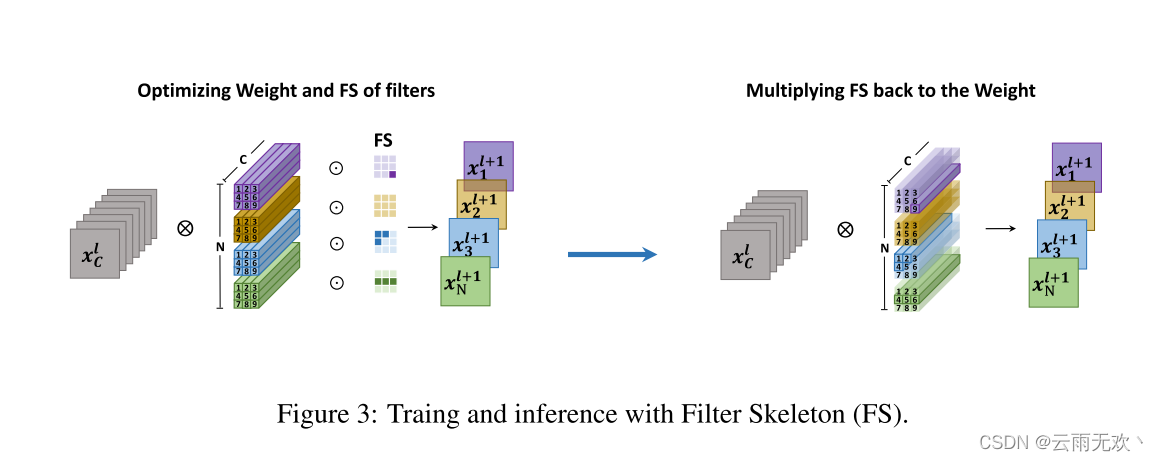
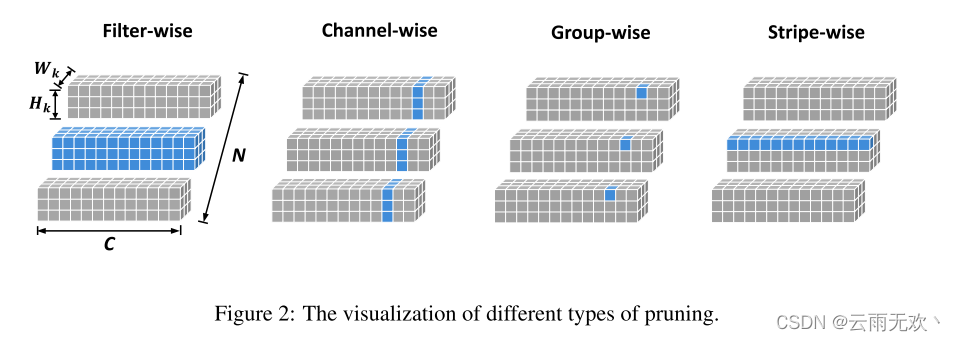
那这是怎么做的呢?如上图中一个kernel,它的长和宽是相等的,是k×k×c,那我们就可以按照他的size把它剪成k×k个条,比如一个3×3的卷积,我们就可以把它剪成9 个条纹,然后通过修剪整个条而不是剪掉整个filter,显然就可以实现比传统的filters pruning更精细的一个粒度。这个方法作者叫做SWP。
这篇论文的作者跟rethinking the value of network pruning思路是一样的。 都是认为网络的体系结构很重要。而且本文中作者认为,Filter本身的结构也很重要。而且他的观点是,内核越大的filters性能越好。就要提出一个形状的概念。这个形状是什么意思呢?比如这个图

这是通道的L1范数值的示意图。从这个图可以看出,filters中并非所有的条纹贡献都相等,对应L1范数非常低的条带就可以删除。那删除以后保留最少条数的,同时保持filters功能的形状就叫做最佳的Filter形状。所以将要解决的一个问题就是我们怎么找到最佳的形状,还提出了一种filters框架来学习这个最佳形状。
2、 数据实验与结论分析
将每个条纹分为多个组,并修剪每个组中的权重。然而,这些非结构化剪枝方法的一个缺点是所得到的权重矩阵是稀疏的,这在没有专用硬件/库的情况下不能实现压缩和加速。所以虽然这个方法很新颖,但是还是只能在GPU上加速,至于在IC或者ASIC上就很难支持了。
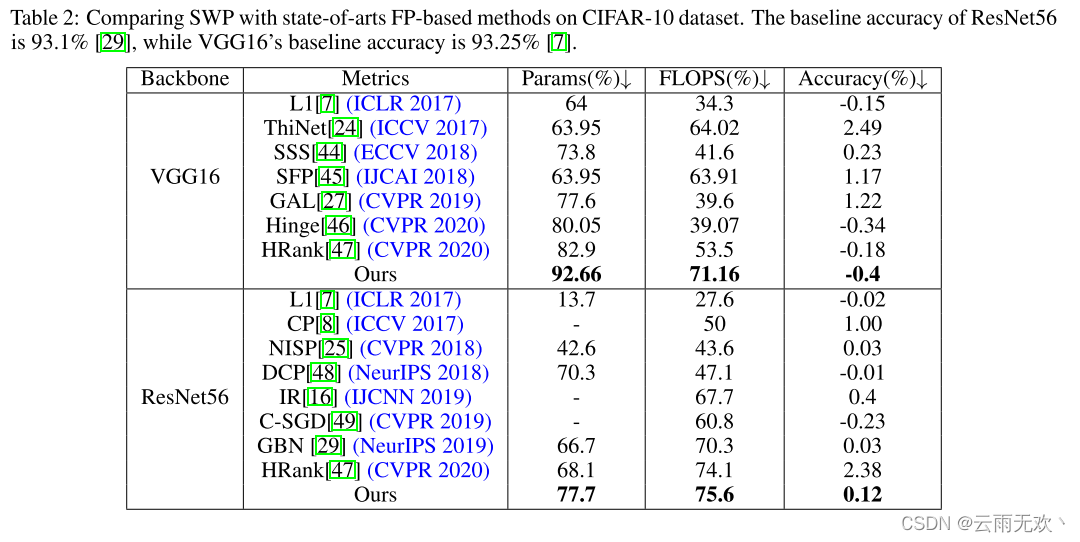
3、 科研启发与积累工作
实现了对VGG网络模型的复现工作。