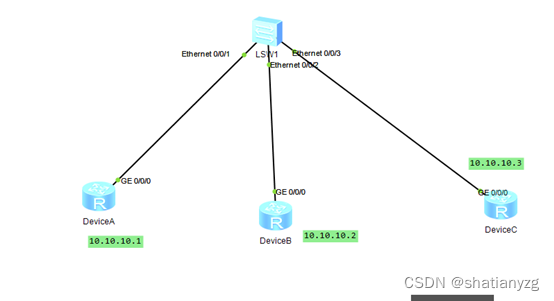
在当今软件开发领域,代码优化对于提高性能和减小代码体积至关重要。在这方面,内联(Inlining)被认为是一项关键的优化技术之一。而MLGO能够在编译过程中智能地做出内联/非内联的决策,从而提供更高效、更紧凑的代码。本文将深入探讨MLGO的工作原理,让您全面了解这一令人激动的技术。

内联(Inlining)是一种优化技术,旨在通过删除冗余代码来减小代码大小。在代码中存在大量的函数相互调用时,构成了一个称为调用图(Call graph)的结构。在内联阶段,编译器遍历整个调用图,并根据一定的决策规则来确定是否内联某些调用者-被调用者对。这是一个连续的决策过程,因为之前的内联决策会改变调用图,从而影响后续的决策和最终的结果。通过内联调用者-被调用者对,编译器可以生成更简洁的代码,从而减小代码的体积。
然而,在传统的启发式方法中,内联/非内联的决策通常是基于一些经验规则或启发式规则进行的。随着时间的推移,这种方法越来越难以改进,特别是在面对复杂的代码结构和大规模软件包时。为了解决这个问题,MLGO(Machine Learning Guided Optimization)引入了机器学习模型来替代传统的启发式方法。MLGO使用策略梯度和进化策略算法对决策网络进行强化学习训练,以提供内联/非内联的决策建议。
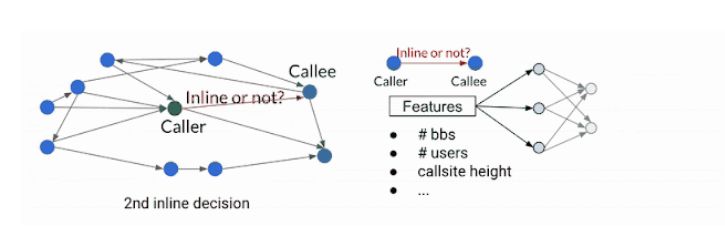
在MLGO中,编译器在遍历调用图的过程中,通过提取相关特征作为输入,向神经网络模型咨询是否对特定的调用者-被调用者对进行内联。根据模型的建议,编译器依次做出内联/非内联的决策,直到整个调用图都被遍历完毕。这样的迭代决策过程将收集状态、行动和奖励的日志,在线强化学习(Online Reinforcement Learning)的方式下,不断改进策略,并更新模型。
在训练过程中,编译器使用经过训练的策略来进行内联/非内联决策,并记录下顺序决策过程的日志。然后,这些日志被传递给训练器,用于更新神经网络模型。这一训练过程不断迭代,直到获得一个满意的模型。

训练完成后,训练好的策略被嵌入到编译器中,在实际的编译过程中提供内联/非内联的决策。与训练阶段不同,该策略不再生成日志。通过将TensorFlow模型嵌入到XLA AOT(Ahead-of-Time Compilation)中,可以将模型转换为可执行代码,避免了TensorFlow运行时的依赖和额外的时间与内存开销。
在大型内部软件包上进行的实验表明,通过MLGO训练得到的内联策略可以在其他软件的编译过程中推广使用,并减少3%至7%的时间和内存开销。这种通用性不仅适用于不同软件之间的比较,而且在软件和编译器的持续发展中也具有跨时间的通用性。经过三个月的评估,该模型在相同软件集合上的性能只出现轻微退化。
随着机器学习技术的不断进步和发展,我们可以期待MLGO在未来进一步推动代码优化领域的创新,为我们带来更高效、更可靠的软件。