公式不清楚的地方请对照英文原文进行查看:原文链接
剪枝已成为现代神经网络压缩和加速的一种非常有效的技术。现有的剪枝方法可分为两大类:滤波器剪枝(FP)和权重剪枝(WP)。与WP相比,FP在硬件兼容性方面胜出,但在压缩比方面失败。为了收敛两种方法的强度,我们提出在滤波器中对滤波器进行剪枝。具体来说,我们将滤波器F∈RC×K×K视为K个×K条,即1 × 1个滤波器∈RC,然后通过修剪条纹而不是整个滤波器,我们可以在硬件友好的同时实现比传统FP更细的粒度。我们称我们的方法为SWP (Stripe-Wise Pruning)。SWP的实现是通过引入一个新的可学习的矩阵,称为滤波器骨架,其值反映了每个滤波器的形状。正如一些最近的工作表明,修剪的结构比继承的重要权值更重要,我们认为单个过滤器的结构,即形状,也很重要。通过大量的实验,我们证明了SWP比之前基于fp的方法更有效,并在cifa10和ImageNet数据集上实现了最先进的剪枝率,而精度没有明显下降。有关代码载于[this url].(https://github.com/fxmeng/Pruning-Filter-in-Filter)
1 Introduction简介
深度神经网络(DNN)在许多领域取得了显着进展,包括语音识别[1],计算机视觉[2,3],自然语言处理[4]等。然而,由于DNN中的大量参数,模型部署有时是昂贵的。为了缓解这样的问题,已经提出了许多方法来压缩DNN并减少计算量。这些方法可分为两大类:权重修剪(WP)和滤波器(信道)修剪(FP)。
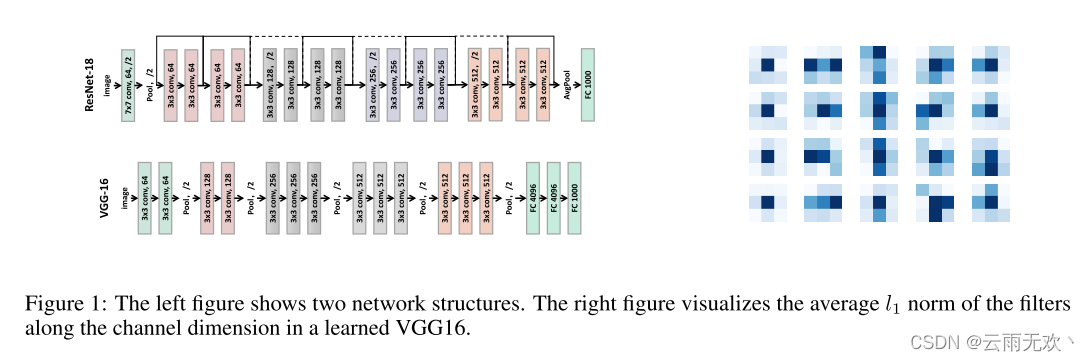
WP是细粒度修剪方法,其修剪各个权重,例如,其值接近0,在网络[5,6]内,导致稀疏网络而不牺牲预测性能。然而,由于非零权重的位置是不规则和随机的,我们需要额外记录权重位置,并且由于网络内部的随机性,WP修剪的稀疏网络无法像FP那样以结构化的方式呈现,使得WP无法在通用处理器上实现加速。相比之下,基于FP的方法[7,8,9]修剪卷积层内的滤波器或通道,因此修剪后的网络仍然以结构方式组织良好,并且可以在通用处理器中轻松实现加速。标准过滤器修剪流水线如下:1)训练更大的模型直到收敛。2)3)对修剪后的网络进行微调。[10]观察到训练修剪模型随机初始化也可以实现高性能。因此,重要的是网络架构,而不是训练的权重。在本文中,我们认为,不仅是网络的架构,但架构的过滤器本身也很重要。[11,12]也得出类似的论点,即具有较大内核大小的滤波器可能导致更好的性能。然而,计算成本昂贵。因此,对于给定的输入特征图,[11,12]使用具有不同内核大小的过滤器(例如,1 × 1、3 × 3和5 × 5)来执行卷积并连接所有输出特征图。但是每个过滤器的核大小是手动设置的。设计高效的网络结构需要专业的经验和知识。我们想知道,如果我们可以学习的最佳内核大小ofeach过滤器修剪。我们的直觉如图1所示。我们知道深度网络的结构对学习任务很重要。例如,残差网络更容易优化,并且表现出比VGG更好的性能。然而,我们发现网络内部隐藏着另一种结构,我们称之为“过滤器的形状”。来自图1,并非滤波器中的所有条纹都有相同的贡献[13]。一些条带具有非常低的l1范数,这指示可以从网络中移除这样的条带。保持滤波器的功能同时留下最少数量的条纹的形状被称为最佳形状。为了捕获与滤波器权重一起的“滤波器形状”,我们提出了“滤波器骨架(FS)”来学习该“形状”属性并使用FS来指导有效的修剪(即学习最佳形状)(见第3节)。与传统的基于FP的剪枝方法相比,该剪枝方法实现了更细的粒度,因为我们使用条带而不是整个过滤器进行操作。
类似地,在[14,15,16]中引入的按组修剪也实现了比滤波器/信道修剪更精细的粒度,其移除位于某个层中的所有滤波器之间的相同位置的权重。然而,分组式修剪打破了对过滤器的独立假设。举例来说,每一滤波器中的权重的无效位置可不同。通过使用分组修剪来正则化网络,网络可能会在大的修剪率下失去表示能力(参见第4.2节)。在本文中,我们还提供了一个比较组明智的修剪实验。相比之下,SWP保持每个滤波器彼此独立,这不打破滤波器之间的独立假设。在整个实验中,SWP实现了更高的修剪比相比,过滤器明智的,通道明智的,和组明智的修剪方法。我们总结了我们的主要贡献如下:
- 我们提出了一种新的修剪范式,称为SWP。SWP实现了比传统过滤器修剪更细的粒度,并且修剪后的网络仍然可以被有效地推断
- 我们引入过滤器骨架(FS),以有效地学习每个过滤器的形状,并深入分析FS的工作机制。使用FS,我们在CIFAR-10和ImageNet数据集上实现了最先进的剪枝率,而没有明显的准确性下降。
2 Related Work相关工作
权重修剪: 权重修剪(WP)可以追溯到最佳脑损伤和最佳脑外科医生[17,18],其基于损失函数的Hessian来修剪权重。[5]基于l1范数准则修剪网络权重并重新训练网络以恢复性能,并且该技术可以通过修剪、量化和霍夫曼编码被并入深度压缩流水线[6]。[19]通过进行动态连接修剪来降低网络复杂度,其将连接拼接并入整个过程中以避免不正确的修剪,并使其成为持续的网络维护。[20]通过求解凸优化程序来移除每个DNN层处的连接。该程序在每一层寻找一组稀疏的权重,使层的输入和输出与最初训练的模型保持一致。[21]提出了一种频域动态修剪方案,以利用CNN上的空间相关性。在每次迭代中动态地修剪频域系数,并且考虑到不同频带对准确度的不同重要性,有区别地修剪不同频带。[22]将每个条带分成多个组,并修剪每个组中的权重。然而,这些非结构化修剪方法的一个缺点是所得到的权重矩阵是稀疏的,这在没有专用硬件/库的情况下不能导致压缩和加速[23]。
过滤器/通道修剪: 过滤器/通道修剪(FP)在过滤器、通道甚至层的级别上进行修剪。由于原始卷积结构仍然被保留,因此不需要专用硬件/库来实现益处。与权值剪枝[5]类似,[7]也采用了l1范数准则来剪枝不重要的滤波器。代替修剪滤波器,[8]提出通过基于LASSO回归的信道选择和最小二乘重构来修剪信道。[9]优化BN层中的缩放因子γ作为信道选择指示符以决定哪个信道是不重要的并且可以被移除。[24]介绍了ThiNet,正式建立过滤器修剪作为一个优化问题,并揭示了我们需要修剪过滤器的统计信息计算的基础上,从它的下一层,而不是当前层。类似地,[25]优化了最终响应层的重建误差,并为每个通道传播“重要性分数”。[26]首先提出利用AutoML进行模型压缩,其利用强化学习来提供模型压缩策略。[27]提出了一种有效的结构化修剪方法,该方法以端到端的方式联合修剪过滤器以及其他结构。具体来说,作者引入了一个软掩模来缩放这些结构的输出,方法是定义一个具有稀疏正则化的新目标函数,以将基线和网络的输出与该掩模对齐。[28]为深度CNN引入了一个预算正则化修剪框架,自然适合传统的神经网络训练。该框架包括一个可学习的掩蔽层,一个新的预算意识的目标函数,并使用知识蒸馏。[29]提出了一种称为Gate Decorator的全局滤波器修剪算法,该算法通过将其输出乘以通道缩放因子来转换香草CNN模块,即门,并在CIFAR数据集上实现了最先进的结果。[30,10]通过大量的实验结果深入分析了初始化是如何影响剪枝的。
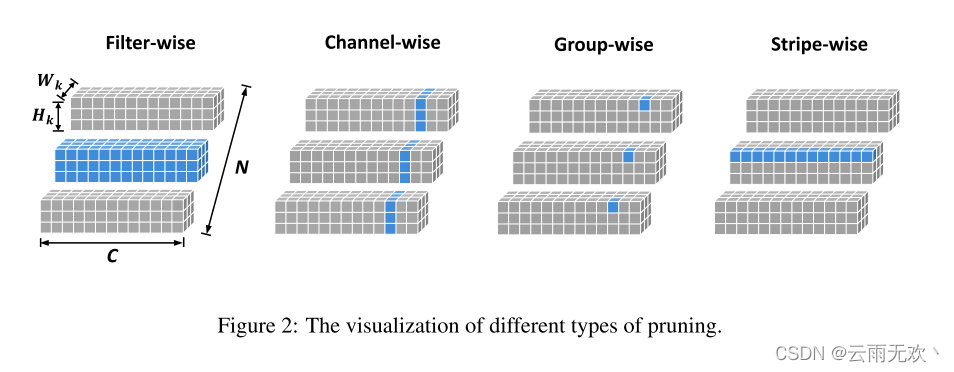

分组修剪: [14,15]介绍了分组修剪,它使用组套索正则化来学习神经网络中的结构化稀疏性。使用“im2col”实现方式作为滤波器式和通道式修剪,仍然可以有效地处理组式修剪。[31]进一步探讨了一个完整的范围内的修剪粒度,并评估它如何影响预测精度。[16]通过提出动态正则化方法改进了分组剪枝。然而,逐组修剪移除位于某一层中的所有滤波器之间的相同位置的权重。由于每个滤波器的无效位置可能不同,因此按组修剪可能导致网络丢失有效信息。相比之下,我们的方法保持每个过滤器彼此独立,从而可以导致一个更有效的网络结构。不同类型的修剪在图2中示出。
修剪中的Mask: 使用(软)掩码来表示网络中组件的重要性已经在修剪工作中进行了深入研究[32,33,34,35,27,36,37,9,8]。然而,大多数工作都是从滤波器或通道的角度来设计掩模,很少有工作关注条纹。此外,过滤器骨架(FS)不仅仅是一个掩码,我们认为每个过滤器都有两个属性:重量和形状。FS是学习“形状”属性。从本文的第3.1节中,网络仍然具有良好的性能,仅学习滤波器的“形状”,保持滤波器权重随机初始化。
3 The proposed Method提出的方法
3.1 Filter Skeleton (FS)过滤器骨架(FS)
引入FS是为了学习过滤器的另一个重要属性以及它们的权重:形状,其是与滤波器的条纹相关的矩阵。假设第1个卷积层的权重W1的大小为RN×C×K×K,其中,N是滤波器的数量,C是信道维度,并且K是核大小。则该层中FS的大小为RN×K×K。即,FS中的每个值对应于滤波器中的条带。首先用全一矩阵初始化每层中的FS。在训练过程中,我们将过滤器的权重乘以FS。在数学上,损失由下式表示:

,其中I表示FS, 表示点积。对于I,前向过程是:
表示点积。对于I,前向过程是:

.关于W和I的梯度为:
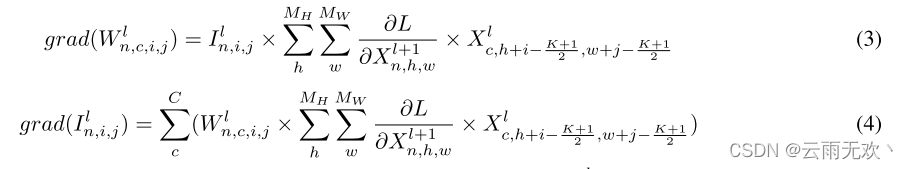
其中MH、MW分别表示特征图的高度和宽度。当p MH或q MW时,Xlc,p,q = 0< 1 or p >< 1 or q >(这对应于填充和移位[38,39]过程)。
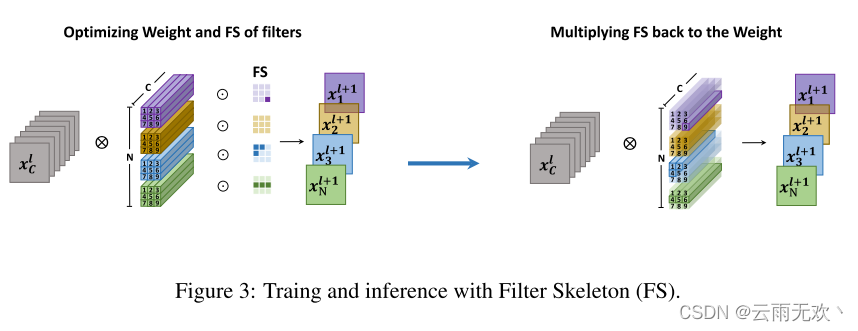
根据(1),在训练期间联合优化滤波器权重和FS。在训练之后,我们将I合并到滤波器权重W(即,W ←W I),并且仅在评估期间使用W。因此,当应用推理时,不会给网络带来额外的成本。整个过程如图3所示。为了进一步显示“形状”属性的重要性,我们进行了一个实验,其中过滤器的权重是固定的,只有FS可以在训练过程中进行优化。结果示于表1中。可以看出,在不更新过滤器权重的情况下,网络仍然可以获得不错的结果。我们还发现,使用过滤器骨架,网络的权重变得更加稳定。图4显示了基线网络和由过滤器骨架(FS)训练的网络的权重分布。可以看出,通过FS训练的权重是稀疏和平滑的,其对输入图像具有低方差,从而导致稳定的输出。因此,网络对输入数据或特征的变化是鲁棒的。
3.2 Stripe-wise pruning with FS带FS的条带修剪
从图1中可以看出,并非所有条带在网络中的贡献都是相等的。为了构建紧凑且高度修剪的网络,过滤器骨架(FS)需要稀疏。即,当FS中的一些值接近0时,可以修剪对应的条带。因此,当使用FS训练网络时,我们对FS施加正则化以使其稀疏:
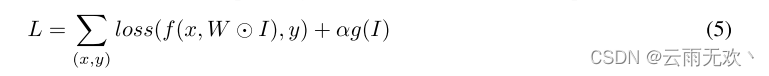
,其中α控制正则化的大小,g(I)表示I上的l1范数惩罚,这通常用于许多修剪方法[7,8,9]。具体地,g(I)被写为:
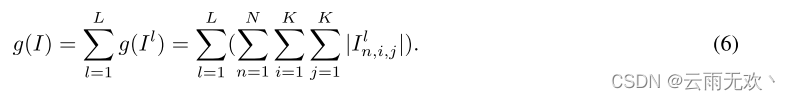
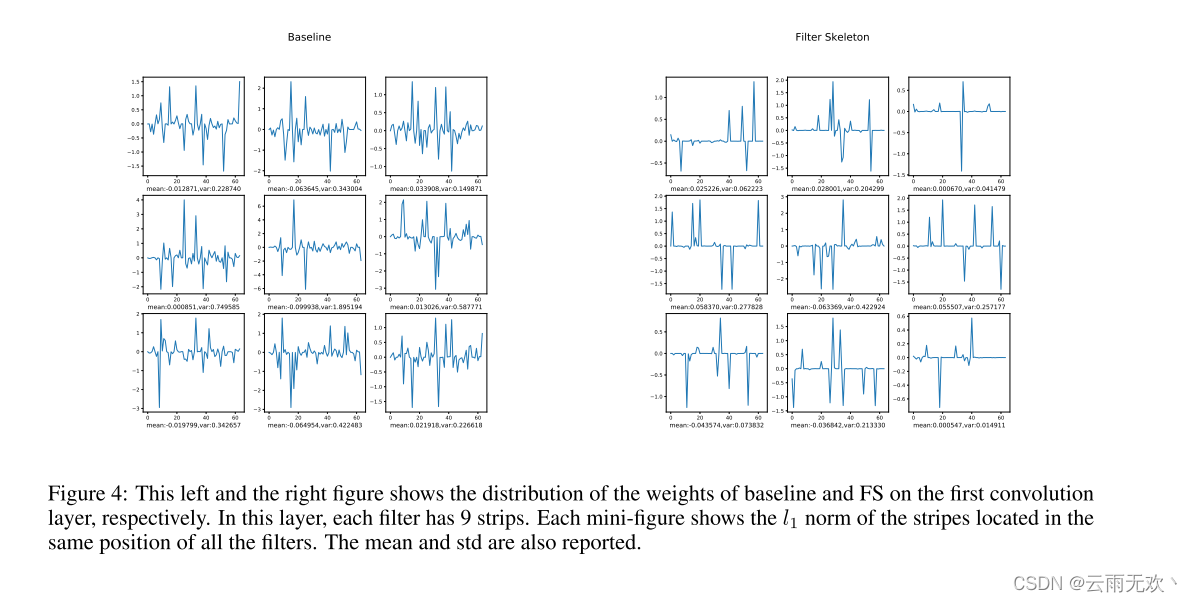
图4:这张左图和右图分别显示了基线和FS在第一个卷积层上的权重分布。在该层中,每个过滤器具有9个条带。每个迷你图示出了位于所有滤波器的相同位置的条纹的l1范数。还报告了平均值和标准差。
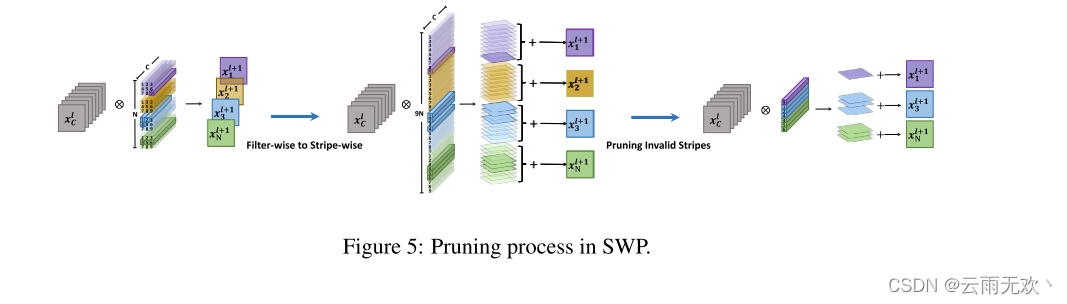
从(5),FS隐式地学习每个滤波器的最佳形状。在第4.4节中,我们将滤波器的形状可视化,以进一步显示这种现象。为了进行有效的修剪,我们设置了一个阈值δ,FS中对应值小于δ的条带在训练期间将不会更新,并且可以在之后进行修剪。值得注意的是,当对修剪后的网络进行推理时,由于过滤器被破坏,我们不能直接使用过滤器作为一个整体对输入特征图进行卷积。相反,我们需要独立地使用每个条带来执行卷积,并对每个条带产生的特征图求和,如图5所示。在数学上,SWP中的卷积过程被写为:
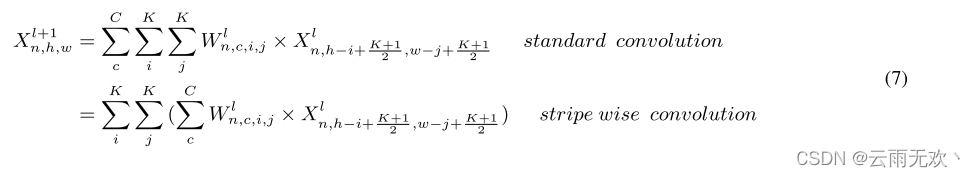
其中Xl+1n,h,w是第1 + 1层中的特征图的一个点。根据(7),SWP仅修改传统卷积过程中的计算顺序,因此没有向网络添加额外的操作(触发器)。值得注意的是,由于每个条纹在过滤器中具有其自己的位置。SWP需要记录所有条带的索引。然而,与整个网络参数相比,它的成本很小。假设第1个卷积层的权重W1的大小为RN×C×K×K。对于SWP,我们需要记录N ×K ×K个索引。与记录N ×C ×K ×K指标的个体权重剪枝相比,权重剪枝的指标减少了C倍。此外,我们不需要记录过滤器的索引,如果在这样的过滤器中的所有条纹从网络中删除,SWP退化到传统的过滤器式修剪。为了与传统的基于FP的方法进行公平的比较,我们在计算网络参数的数量时添加了索引的数量。
与传统的基于FP的修剪相比,SWP有两个优点:
- 假设核的大小为K×K,则SWP比传统的基于FP的剪枝算法获得了K2倍更细的粒度,从而获得了更高的剪枝率。
- 对于某些数据集,例如,CIFAR-10,网络修剪SWP保持高性能,即使没有一个微调过程。这将SWP与需要多个微调过程的许多其他基于FP的修剪方法分开。原因是FS学习每个滤波器的最佳形状。通过修剪不重要的条纹,过滤器不会丢失很多有用的信息。相比之下,FP剪枝直接删除可能损坏网络学习到的信息的过滤器。
4 Experiments实验
本节安排如下:在第4.1节中,我们介绍了论文中的实现细节;在4.2节中,我们比较了SWP和分组剪枝;在第4.3节中,我们展示了SWP在CIFAR-10和ImageNet数据集上实现了最先进的剪枝率,与滤波器、通道或形状剪枝相比;在第4.4节中,我们可视化修剪的过滤器;在第4.5节中,我们进行消融研究以研究超参数如何影响SWP。
4.1 Implementation Details实施细节
数据集和模型: CIFAR-10 [40]和ImageNet [41]是两个流行的数据集,并在我们的实验中采用。CIFAR-10数据集包含10个类的50 K训练图像和10 K测试图像。ImageNet包含128万张训练图像和50 K张测试图像,用于1000个类。在CIFAR-10上,我们在两种流行的网络结构上评估了我们的方法:VGG16 [42]、ResNet56 [43]。在ImageNet数据集上,我们采用ResNet 18。
基线设置:我们的基准设置与[9]一致。对于CIFAR-10,该模型被训练了160个时期,批量大小为64。初始学习率被设置为0.1,并在时期80和120处将其除以10。简单的数据增强(随机裁剪和随机水平翻转)用于训练图像。对于ImageNet,我们遵循官方的PyTorch实现1,该实现训练模型90个epoch,批量大小为256。初始学习率被设置为0.1,并且每30个时期将其除以10。图像大小调整为256 × 256,然后从原始图像中随机裁剪224 × 224区域进行训练。测试是在224 × 224像素的中心裁剪上进行的。
SWP设置:基本超参数设置与基线一致。在(5)中,α被设置为1 e-5,并且阈值δ被设置为0.05。对于CIFAR-10,我们在条带选择后不对网络进行微调。对于ImageNet,我们在修剪后执行一次性微调。
4.2 Group-wise pruning vs stripe-wise pruning分组剪枝与条带剪枝
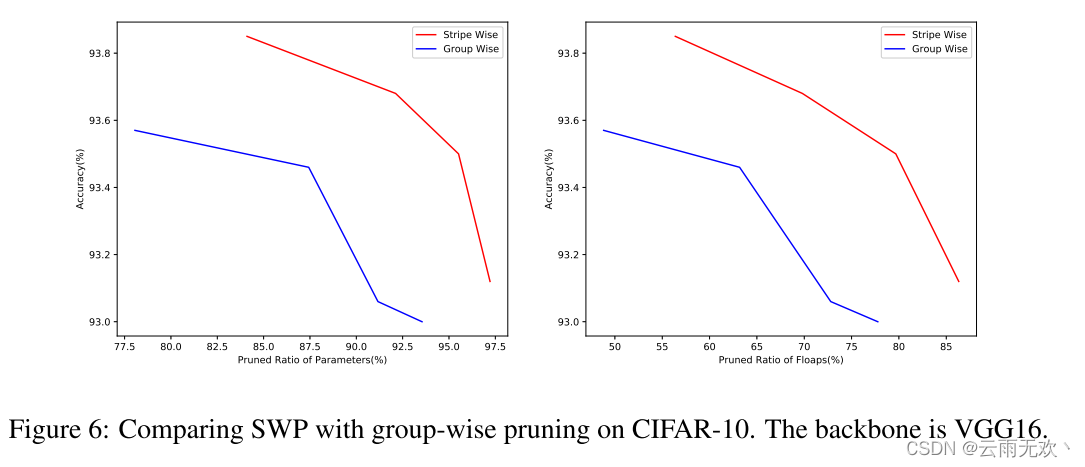
由于分组剪枝也可以通过骨架实现,因此我们基于骨架执行分组剪枝和SWP。图6显示了结果。我们可以看到,在相同数量的参数或触发器下,SWP与分组剪枝相比实现了更高的性能。我们还发现,在分组修剪中,layer2.7.conv1和layer2.7.conv2将被标识为无效(即,当剪枝率达到76.64%时,该层中的所有权重将被该算法剪枝)。然而,这种现象并没有出现在条带式修剪,即使有87.36%的修剪率,这进一步验证了我们的假设,即分组式修剪打破了独立的假设上的过滤器,很容易失去代表性的能力。相比之下,SWP保持每个过滤器彼此独立,从而可以实现更高的剪枝率。
4.3 Comparing SWP with state-of-art methods SWP与最新方法的比较
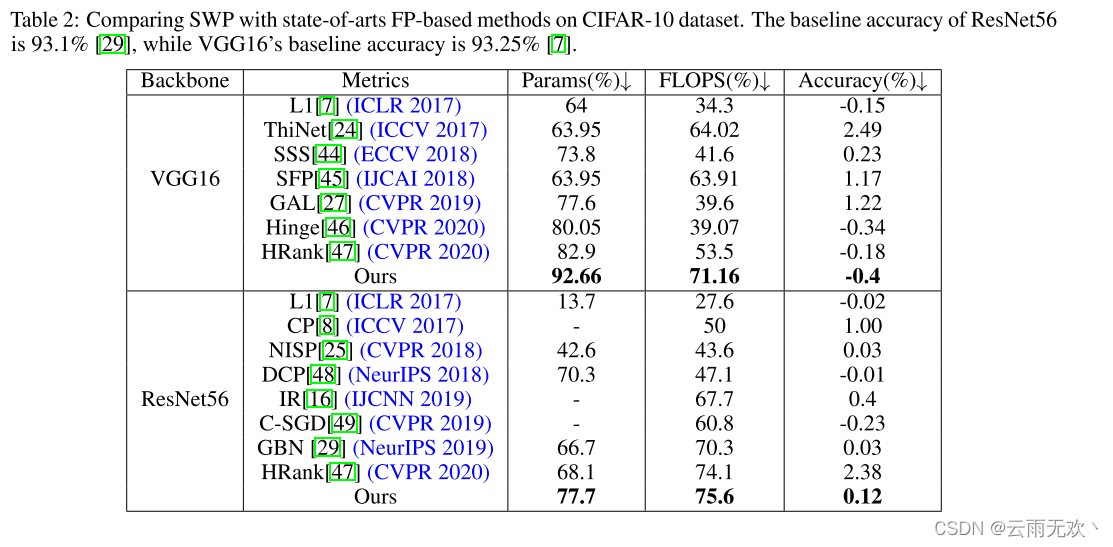
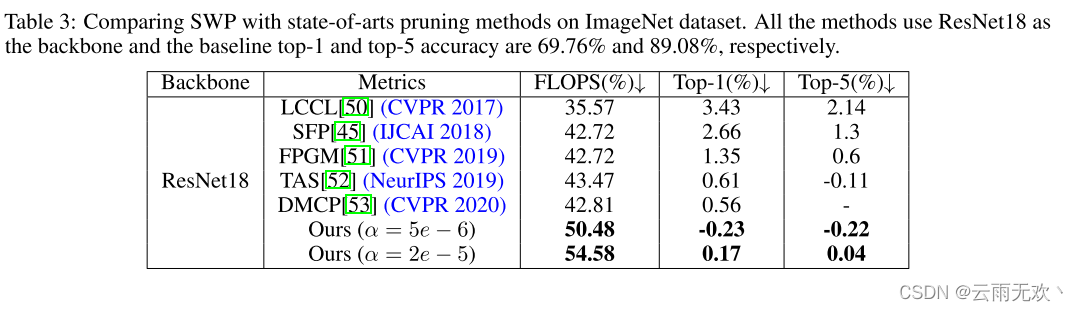
我们比较SWP与最近的国家最先进的修剪方法。表2和表3分别列出了CIFAR-10和ImageNet上的比较。在表2中,IR [16]是按组修剪方法,除SWP之外的其他方法是按滤波器或按通道方法。我们可以看到GBN [29]甚至优于形状修剪方法。根据我们的分析,分组剪枝将网络的权重规则化在所有过滤器的相同位置,这可能会导致网络丢失有用的信息。因此,分组修剪可能不是最佳选择。然而,SWP优于其他方法的大幅度。例如,当修剪VGG 16时,SWP可以将参数的数量减少92.66%,将触发器的数量减少71.16%,而不会损失网络性能。在ImageNet上,SWP也可以实现比最近的基准测试方法更好的性能。例如,SWP可以将FLOP降低54.58%而没有明显的精度下降。我们想强调的是,即使SWP带来了条带的索引,成本也很小。在计算参数个数时,我们在表2和表3的计算中加入了这些指标。SWP的剪枝率仍然是显着的,并达到最先进的结果。
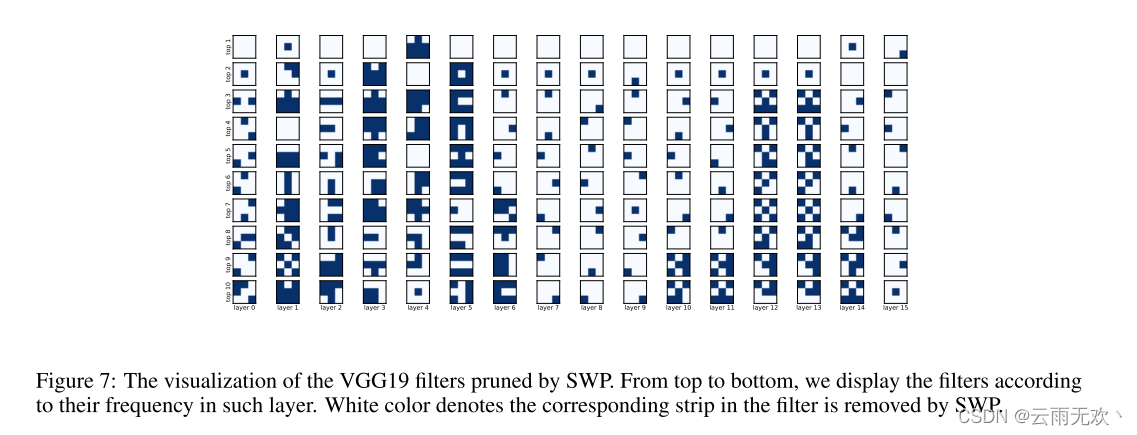
4.4 Visualizing the pruned filter可视化修剪的过滤器
我们将VGG19的过滤器可视化,以显示通过SWP修剪后的稀疏网络的外观。VGG19的核大小为R3×3,因此每个过滤器中有9个条带。每个过滤器有29种形式,因为每个条带都可以删除或保留。我们根据每种形式的频率显示每层的过滤器。图7显示了可视化结果。有一些有趣的现象:
- 对于每个层,大多数过滤器直接用所有条带修剪。
- 在中间层中,大多数保留的过滤器仅具有一个条带。然而,在靠近输入的层中,大多数保留的层具有多个条带。表明冗余大多发生在中间层。
我们相信这种可视化可以更好地理解CNN。在过去,我们总是把滤波器作为CNN中的最小单元。然而,从我们的实验中,过滤器本身的架构也很重要,可以通过修剪来学习。更多的可视化结果可以在补充材料中找到。
4.5 Ablation Study消融研究
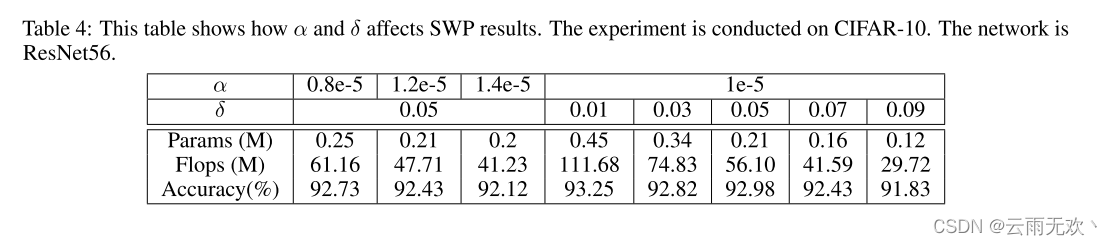
在本节中,我们将研究不同的超参数如何影响剪枝结果。我们主要研究了(1)中的加权系数α和剪枝阈值δ。表4示出了实验结果。我们发现α = 1e − 5和δ = 0.05给出了可接受的剪枝率和测试精度。
5 Conclusion结论
在本文中,我们提出了一个新的修剪范式称为SWP。代替修剪整个滤波器,SWP将每个滤波器视为多个条带的组合(即,1 × 1过滤器),并对条带执行修剪。我们还引入了过滤器骨架(FS),以有效地学习过滤器的最佳形状进行修剪。通过大量的实验和分析,我们证明了SWP框架的有效性。未来的工作可以开发更有效的正则化器来进一步优化DNN。
6 Supplementary Material补充材料
这是论文“过滤器中的修剪过滤器”的补充材料。第6.1节显示,我们可以使用SWP来继续修剪由其他基于FP(过滤器修剪)的方法修剪的网络。第6.2节显示,在SWP框架中,Filter Skeleton比lasso正则化更好。第6.3节显示了更多的可视化结果。
6.1 Continual Pruning in SWP SWP中的连续剪枝
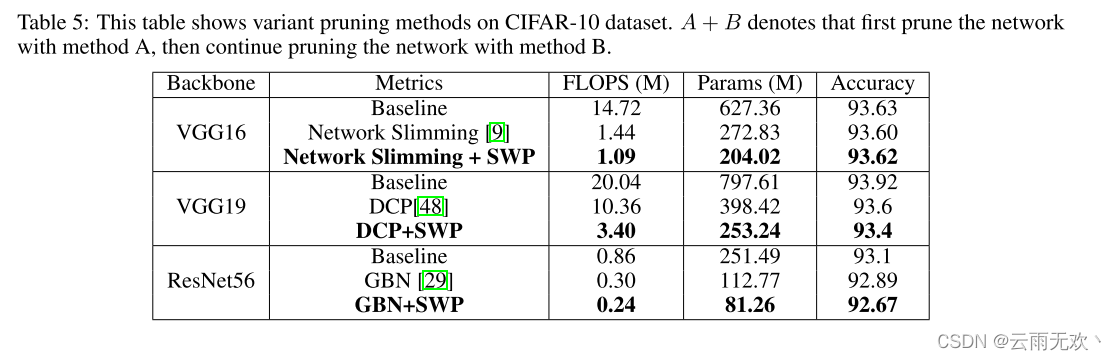
由于SWP可以达到比传统过滤器修剪方法更细的粒度,我们可以使用SWP继续修剪网络修剪由其他方法修剪没有明显的准确性下降。表5示出了实验结果。可以观察到,SWP可以帮助其他基于FP的修剪朝向更高的修剪比率。
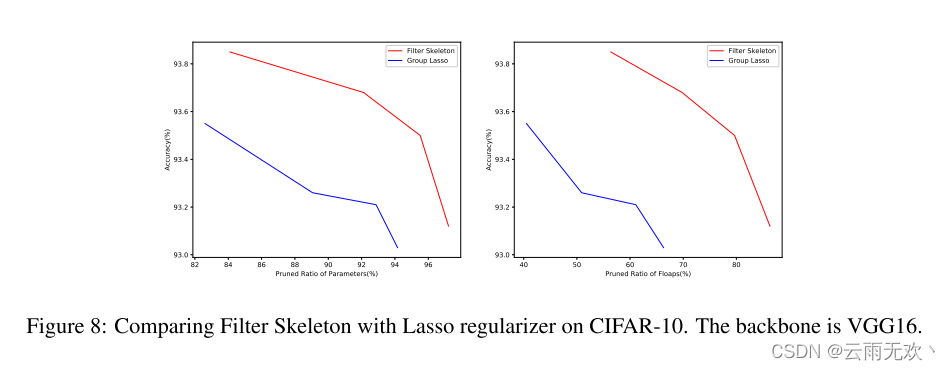
6.2 Filter Skeleton v.s. Group Lasso过滤器骨架与集团套索
在本文中,我们使用过滤器骨架(FS)来学习每个过滤器的最佳形状,并修剪不重要的条纹。然而,存在其他技术来正则化网络以使其稀疏。例如,基于Lasso的正则化器[15],它直接正则化网络权重。我们在本节中提供了与Group Lasso正则化器的比较。图8显示了结果。我们可以看到,在相同的参数或触发器数量下,具有过滤器骨架的PFF实现了更高的性能。
6.3 More Visualization Results更多可视化结果
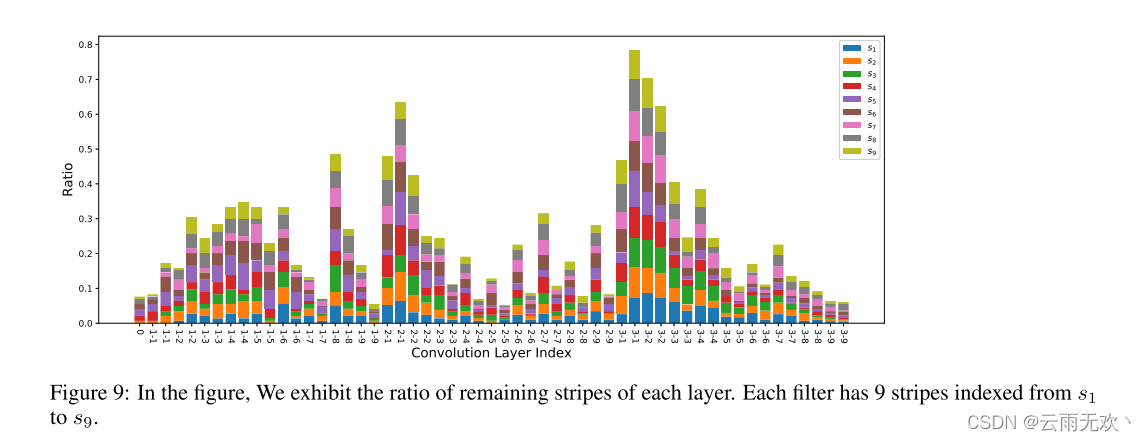
在本节中,我们将展示SWP修剪后的网络。图9显示了ResNet 56在CIFAR-10上的可视化结果。可以观察到,(1)SWP在中间层上具有较高的修剪比率,例如,层2.3至层2.9。(2)每一条带的修剪率是不同的,并且在每一层上变化。表6显示了ImageNet上的修剪网络。例如,在layer1.1.conv2中,原始的64个过滤器的大小为R62×3×3。修剪后的条纹大小为R62×1×1,共300条。该层中的剪枝比为1 − 300×62×1×1 64×62×3×3 = 0.47。