内容总结自《微服务架构设计模式》
使用事件溯源开发业务逻辑
- 一、传统持久化技术的问题
- 二、什么是事件溯源
- 三、好处和弊端
- 四、实现事件存储库
- 五、与Saga结合
- 六、总结
一、传统持久化技术的问题
1、对象与关系的"阻抗失调"
所谓的对象与关系的“阻抗失调”是一个古老的问题。关系型数据的表格结构模式,与领域模型及其复杂关系的图状结构之间,存在基本的概念不匹配问题。
2、缺乏聚合的历史
传统持久化的另一个限制是它只存储聚合的当前状态.聚合更新后,其先前的状态将丢失。如果应用程序必须保留聚合的历史记录(可能是出于监管目的),那么开发人员必须自己实现此机制.实现聚合历史记录机制是非常耗时的一项工作,其中还会涉及复制那些必须与业务逻辑保持同步的代码。
3、实施审计功能将非常烦琐且容易出错
另一个问题是审计功能。许多应用程序必须维护审计日志,用于跟踪哪些用户更改了聚合。某些应用程序需要审计功能,以满足安全性或监管的要求。在一些应用程序中,记录用户操作历史是一个重要的功能。
4、事件发布是凌驾于业务逻辑之上
传统持久化的另一个限制是它通常不支持发布领域事件。领域事件在状态发生变化的时候,是在微服务架构中同步数据和发送通知的有效机制。某些ORM框架(如Hibernate)可以在数据对象更改时调用应用程序提供的回调接口。但是,我们无法把自动发布消息作为更新数据事务的一部分。因此,与操作历史和审计一样,开发人员必须自己处理事件生成的逻辑,这可能会与业务逻辑代码不完全同步。幸运的是,这些问题有一个解决方案:事件溯源。
二、什么是事件溯源
事件溯源是一种以事件为中心的技术,用于实现业务逻辑和聚合的持久化。聚合作为一系列事件存储在数据库中。每个事件代表聚合的状态变化。聚合的业务逻辑围绕生成和使用这些事件的要求而构建。
1、事件溯源通过事件来持久化聚合
将聚合的字段映射到数据库表的列,将聚合的实例映射到数据库表的行。事件溯源采用基于领域事件的概念来实现聚合的持久化,这是一种非同寻常的方法。它将每个聚合持久化为数据库中的一系列事件,我们称之为事件存储。
2、事件代表状态的改变
使用事件溯源时,事件不再是可有可无的。包括创建在内的每一个聚合状态变化,都由领域事件表示。每当聚合的状态发生变化时,它必须发出一个事件。这是一个比以前更严格的要求,在此之前,聚合只需要发出那些外部接收方感兴趣的事件。
3、聚合方法都和事件相关
业务逻辑通过调用聚合根上的命令方法 ( command method)来处理对聚合的更新请求。在传统的应用程序中,命令方法通常会验证其参数,然后更新一个或多个聚合字段。基于事件溯源的应用程序中的命令方法则通过生成事件来起作用。调用聚合命令方法的结果是一系列事件,表示必须进行的状态更改。这些事件将保存在数据库中,并应用于聚合以更新其状态。
4、使用事件溯源的注意事项
- 使用乐观锁处理并发:可以使用乐观锁解决并发问题;
- 使用轮训发布事件:可以增加事件是否执行列,发布事件时根据event_id和是否执行列共同决定下次执行的事件;
- 使用快照提升性能:可以使用JSON序列化聚合的状态,达到快照效果;
- 消息需要进行幂等处理(业务层面处理、框架层面处理):消息通病都需要进行幂等处理。业务层面就是在业务逻辑层面先查询,再处理。框架层面则为新增一个消息记录映射,每次接收到消息都进行消息重复判定,判定为重复的消息,直接在框架层面过滤,不再透出给业务接口。
三、好处和弊端
事件溯源好处(就是传统持久化技术的问题):
- 可靠地发布领域事件。
- 保留聚合的历史。
- 最大限度地避免对象与关系的"阻抗失调"问题。
- 为开发者提供一个“时光机”
弊端:
- 这类编程模式有一定的学习曲线。
- 基于消息传递的应用程序的复杂性。处理事件的演化有一定难度。
- 删除数据存在一定难度。
- 查询事件存储库非常有挑战性。
四、实现事件存储库
1、一种选择是实现自己的事件存储库和事件溯源代码框架。例如,你可以在关系型数据库中执行事件。可以让订阅者轮询EVENT表的方式发布事件,这种发布事件的方法简单但性能低下。其挑战是确保订阅者按顺序处理所有事件;
2、另一种选择是使用专用事件存储库,它通常提供丰富的功能集、更好的性能和可扩展性。如Event Store、Lagom、Axon、Eventuate等
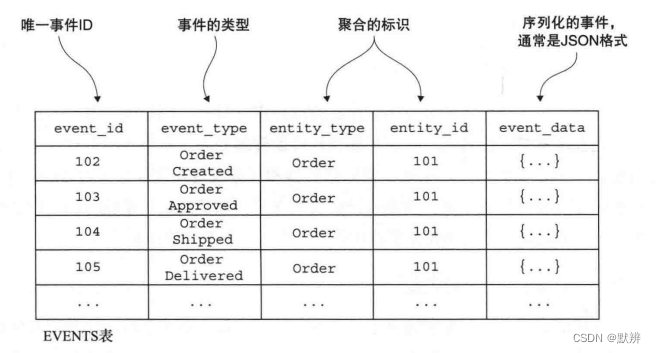
Eventuate Local的事件数据库的结构,主要由三个表组成,具体如下图:
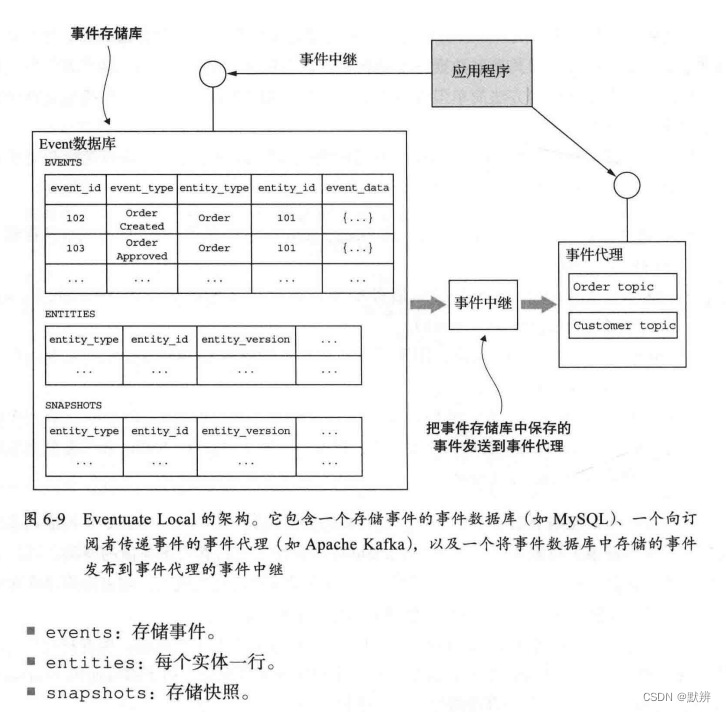
Eventuate Local的事件中继把事件从数据库传播到消息代理,事件中继将插入事件数据库的事件传播到事件代理。它尽可能使用事务日志拖尾,或轮询其他数据库。例如,MySQL 版本的事件中继使用MySQL主/从复制协议。事件中继连接到MySQL服务器,就好像它是一个从服务器,通过读取MySQL binlog对数据库进行同步更新。对EVENTS表的插入操作,将作为对应事件发布到相应的Apache Kafka主题。事件中继忽略任何其他类型的更改。
事件中继部署为独立进程。为了正确地重新启动,它会定期将当前在binlog 的位置(文件名和偏移量)保存到一个特殊的Apache Kafka主题中。在启动时,它首先从主题中检索最后记录的位置。事件中继然后开始从该位置读取MySQL的 binlog。
事件数据库、消息代理和事件中继这三个部分构成了事件存储库。
五、与Saga结合
事件溯源的事件驱动属性使得实现基于协同式的Saga非常简单。当聚合被更新时,它会发出一个事件。不同聚合的事件处理程序可以接收该事件,并更新该聚合。事件溯源框架自动使每个事件处理程序具有幂等性。
使用事件进行Saga协同的问题在于,在这样的场景下,事件体现出了双重目的。事件溯源使用事件来表示状态更改,但是使用事件实现Saga协同,需要聚合即使没有状态更改也必须发出事件。例如,如果更新聚合会违反业务规则,则聚合必须发出事件以报告错误。更糟糕的问题是当Saga参与方无法创建聚合时。没有会发布错误事件的聚合。
由于存在这些问题,最好使用编排式来实现复杂的Saga。
六、总结
- 事件溯源将聚合作为一系列事件持久化保存。每个事件代表聚合的创建或状态更改。应用程序通过重放事件来重建聚合的当前状态。事件溯源保留领域对象的历史记录,提供准确的审计日志,并可靠地发布领域事件。
- 快照通过减少必须重放的事件数来提高性能。
- 事件存储在事件存储库中,该存储库是数据库和消息代理的混合。当服务在事件存储库中保存事件时,它会将事件传递给订阅者。
- Eventuate Local是一个基于MySQL和Apache Kafka的开源事件存储库。开发人员使用Eventuate Client框架来编写聚合和事件处理程序。
- 使用事件溯源的一个挑战是处理事件的演变。应用程序在重放事件时可能必须处理多个事件版本。一个好的解决方案是使用向上转换,当事件从事件存储库加载时,它会将事件升级到最新版本。
- 在事件溯源应用程序中删除数据非常棘手。应用程序必须使用加密和假名等技术,以遵守欧盟GDPR等法规,确保在应用程序中彻底清除个人数据。
- 事件溯源可以很容易实现基于协同的Saga。服务具有事件处理程序,用于监听基于事件溯源的聚合发布的事件。
- 我们也可以使用事件溯源技术实现Saga编排器。你可以编写专门使用事件存储库的应用程序。