文章目录
- IP地址的基础知识
- IP地址的定义
- IP地址由网络和主机两部分标识组成
- IP地址的分类
- 广播地址
- IP多播
- 子网掩码
- IPv4首部
IP地址的基础知识
在用TCP/IP通信时,用IP地址识别主机和路由器。为了保证正常通信,有必要为每个设备配置正确的IP地址。在互联网通信中,全世界都必须设定正确的IP地址。否则,根本无法实现正常的通信。
因此,IP地址就像是TCP/IP通信的一块基石。
IP地址的定义
IP地址(IPv4地址)由32位正整数来表示。TCP/IP通信要求将这样的IP地址分配给每一个参与通信的主机。IP地址在计算机内部以二进制(二进制是指用0、1表示数字的方法。) 方式被处理。然而,由于人类社会并不习惯于采用二进制方式,需要采用一种特殊的标记方式。那就是将32位的IP地址以每8位为一组,分成4组,每组以“.”隔开,再将每组数转换为十进制数(这种方法也叫做“十进制点符号”(Dot-decimal notation)。) 。下面举例说明这一方法。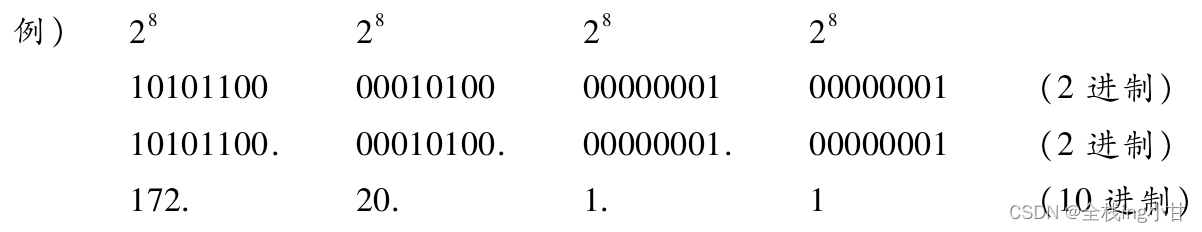
将表示成IP地址的数字整体计算,会得出如下数值。
232 =4 294 967 296
从这个计算结果可知,最多可以允许43亿台计算机连接到网络(虽然43亿这个数字听起来还算比较大,但是还不到地球上现有人口的总数。) 。
实际上,IP地址并非是根据主机台数来配置的,而是每一台主机上的每一块网卡(NIC)都得设置IP地址(Windows或Unix中设置IP地址的命令分别为ipconfig/all和ifconfig-a。) 。通常一块网卡只设置一个IP地址,其实一块网卡也可以配置多个IP地址。此外,一台路由器通常都会配置两个以上的网卡,因此可以设置两个以上的IP地址。
因此,让43亿台计算机全部连网其实是不可能的。由于P地址的两个组成部分网络标识和主机标识,其实实际能够连接到网络的计算机个数更是少了很多(根据一种可以更换IP地址的技术NAT,可连接计算机数超过43亿台。) 。
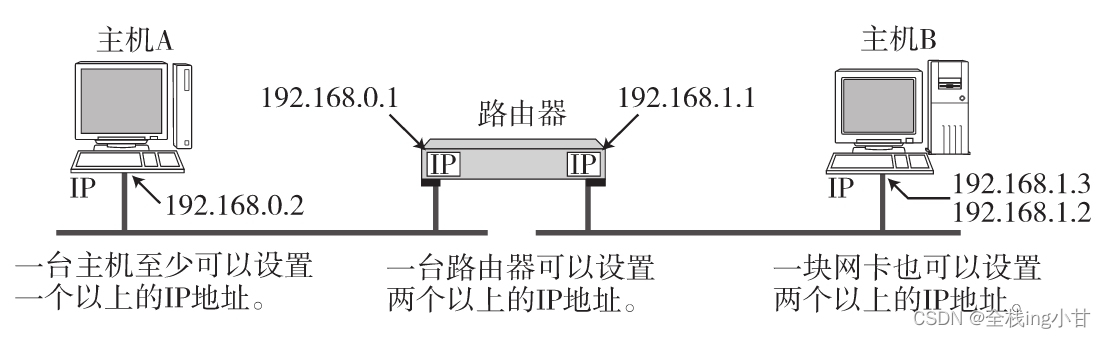
IP地址由网络和主机两部分标识组成
IP地址由“网络标识(网络地址)”和“主机标识(主机地址)”两部分组成(192.168.128.10/24中的“/24”表示从第1位开始到多少位属于网络标识。在这个例子中,192.168.128之前的都是该IP的网络地址。) 。
如图所示,网络标识在数据链路的每个段配置不同的值。网络标识必须保证相互连接的每个段的地址不相重复。而相同段内相连的主机必须有相同的网络地址。IP地址的“主机标识”则不允许在同一个网段内重复出现。
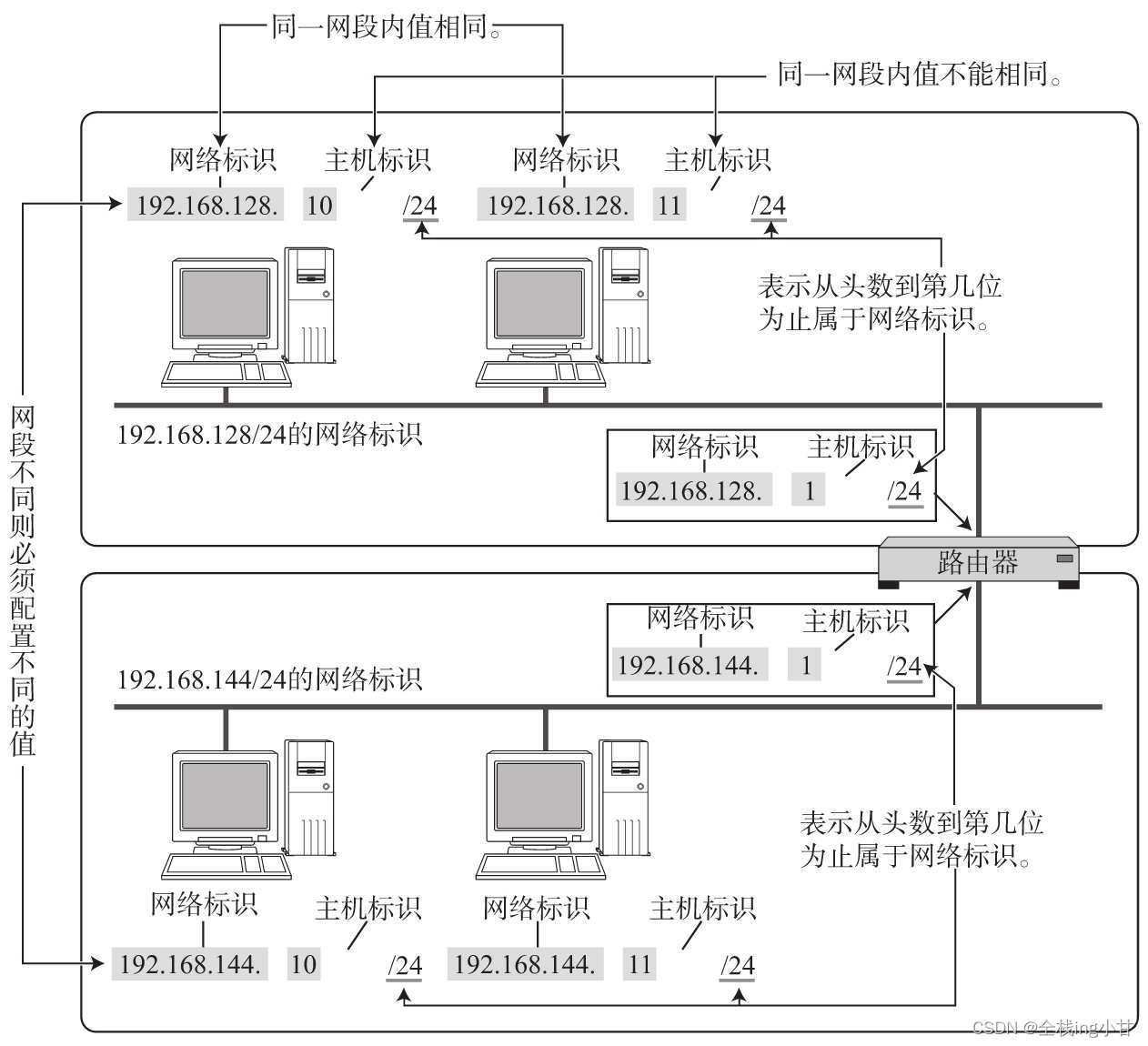
由此,可以通过设置网络地址和主机地址,在相互连接的整个网络中保证每台主机的IP地址都不会相互重叠。即IP地址具有了唯一性(唯一性是指在整个网络中,不会跟其他主机的IP地址冲突。) 。
如图所示,IP包被转发到途中某个路由器时,正是利用目标IP地址的网络标识进行路由。因为即使不看主机标识,只要一见到网络标识就能判断出是否为该网段内的主机。
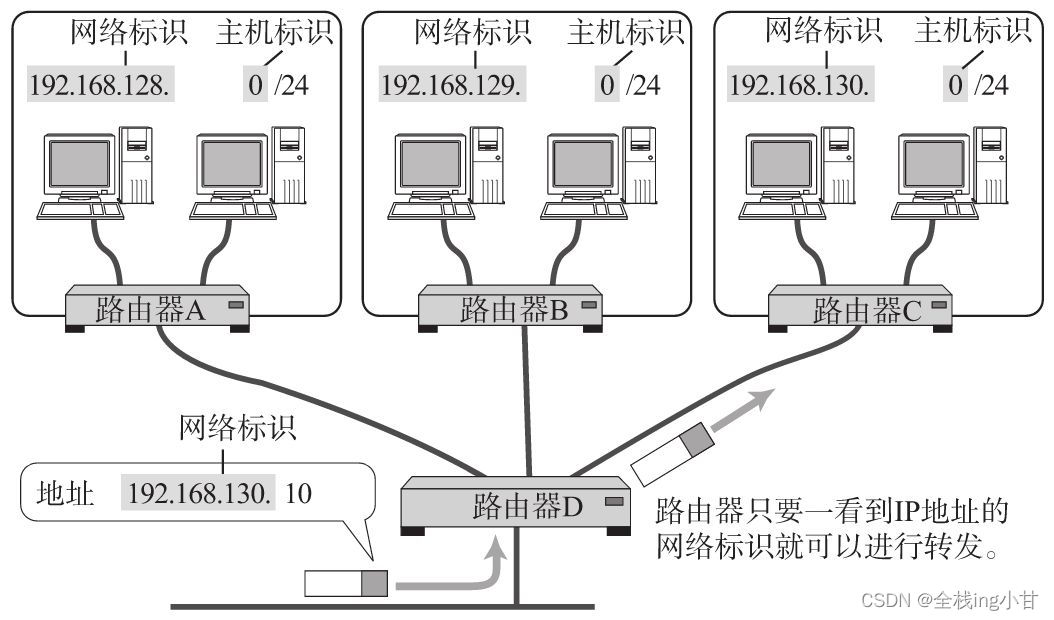
那么,究竟从第几位开始到第几位算是网络标识,又从第几位开始到第几位算是主机标识呢?
关于这点,有约定俗成的两种类型。最初二者以分类进行区别。而现在基本以子网掩码(网络前缀)区分。不过,在有些情况下依据部分功能、系统和协议的需求,前一种的方法依然存在。
IP地址的分类
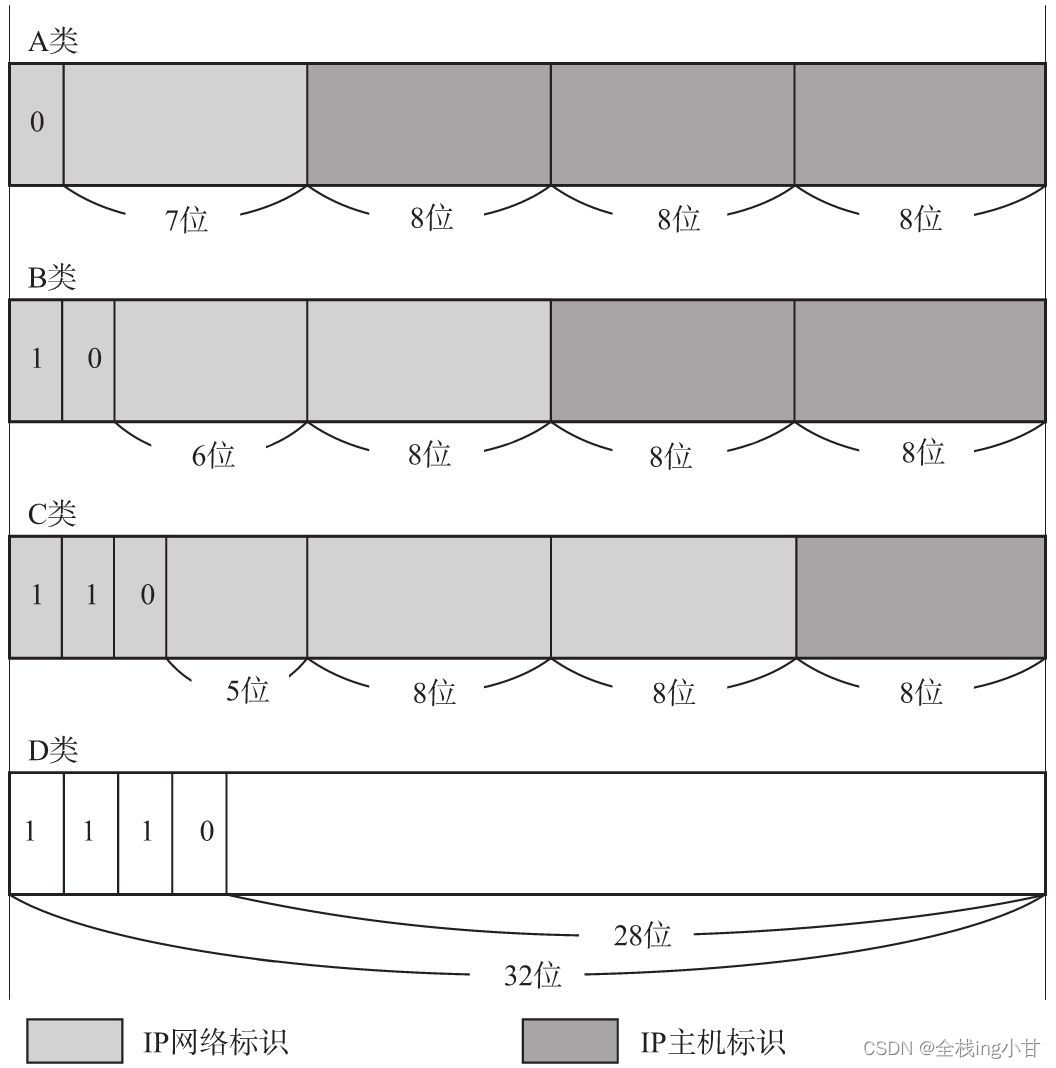
IP地址分为四个级别,分别为A类、B类、C类、D类(还有一个一直未使用的E类。) 。它根据IP地址中从第1位到第4位的比特列对其网络标识和主机标识进行区分。
■ A类地址
A类IP地址是首位以“0”开头的地址。从第1位到第8位(去掉分类位剩下7位。) 是它的网络标识。用十进制表示的话,0.0.0.0~127.0.0.0是A类的网络地址。A类地址的后24位相当于主机标识。因此,一个网段内可容纳的主机地址上限为16,777,214个。
■ B类地址
B类IP地址是前两位为“10”的地址。从第1位到第16位(去掉分类位剩下14位。) 是它的网络标识。用十进制表示的话,128.0.0.1~191.255.0.0是B类的网络地址。B类地址的后16位相当于主机标识。因此,一个网段内可容纳的主机地址上限为65,534个。
■ C类地址
C类IP地址是前三位为“110”的地址。从第1位到第24位(去掉分类位剩下21位。) 是它的网络标识。用十进制表示的话,192.168.0.0~239.255.255.0是C类的网络地址。C类地址的后8位相当于主机标识。因此,一个网段内可容纳的主机地址上限为254个 。
■ D类地址
D类IP地址是前四位为“1110”的地址。从第1位到第32位(去掉分类位剩下28位。) 是它的网络标识。用十进制表示的话,224.0.0.0~239.255.255.255是D类的网络地址。D类地址没有主机标识,常被用于多播。
■ 关于分配IP主机地址的注意事项
在分配IP地址时关于主机标识有一点需要注意。即要用比特位表示主机地址时,不可以全部为0或全部为1。因为全部为只有0在表示对应的网络地址或IP地址不可获知的情况下才使用。而全部为1的主机地址通常作为广播地址。
因此,在分配过程中,应该去掉这两种情况。这也是为什么C类地址每个网段最多只能有254(28 -2=254)个主机地址的原因。
广播地址
广播地址用于在同一个链路中相互连接的主机之间发送数据包。将IP地址中的主机地址部分全部设置为1,就成为了广播地址(以太网中如果将MAC地址的所有位都改为1,则形成FF:FF:FF:FF:FF:FF的广播地址。因此,广播的IP包以数据链路的帧的形式发送时,得通过MAC地址为全1比特的FF:FF:FF:FF:FF:FF转发。) 。例如把172.20.0.0/16用二进制表示如下:
10101100.00010100.00000000.00000000 (二进制)
将这个地址的主机部分全部改为1,则形成广播地址:
10101100.00010100.11111111.11111111 (二进制)
再将这个地址用十进制表示,则为172.20.255.255。
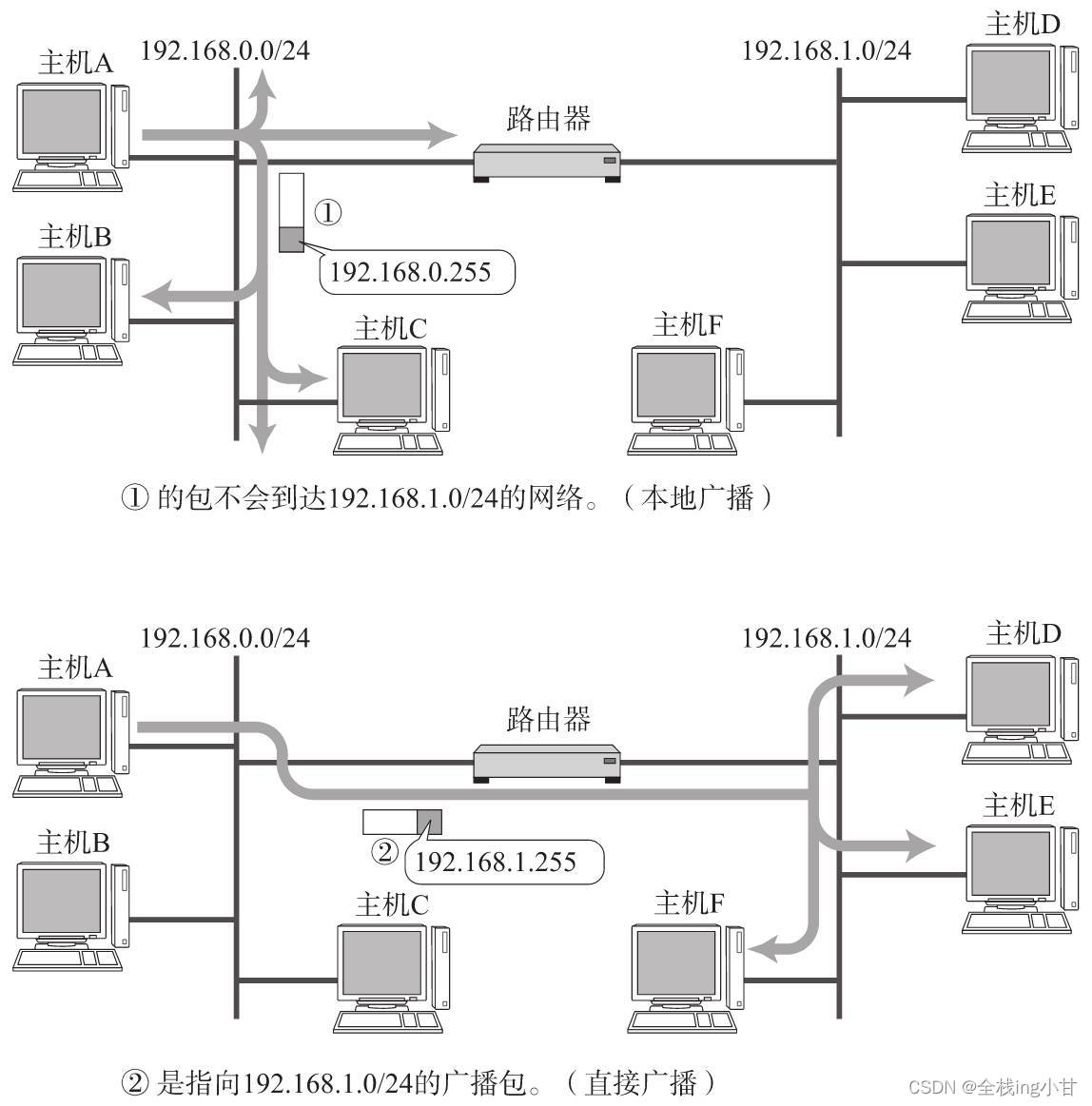
■ 两种广播
广播分为本地广播和直接广播两种。
在本网络内的广播叫做本地广播。例如网络地址为192.168.0.0/24的情况下,广播地址是192.168.0.255。因为这个广播地址的IP包会被路由器屏蔽,所以不会到达192.168.0.0/24以外的其他链路上。
在不同网络之间的广播叫做直接广播。例如网络地址为192.168.0.0/24的主机向192.168.1.255/24的目标地址发送IP包。收到这个包的路由器,将数据转发给192.168.1.0/24,从而使得所有192.168.1.1~192.168.1.254的主机都能收到这个包(由于直接广播有一定的安全问题,多数情况下会在路由器上设置为不转发。) 。
IP多播
■ 同时发送提高效率
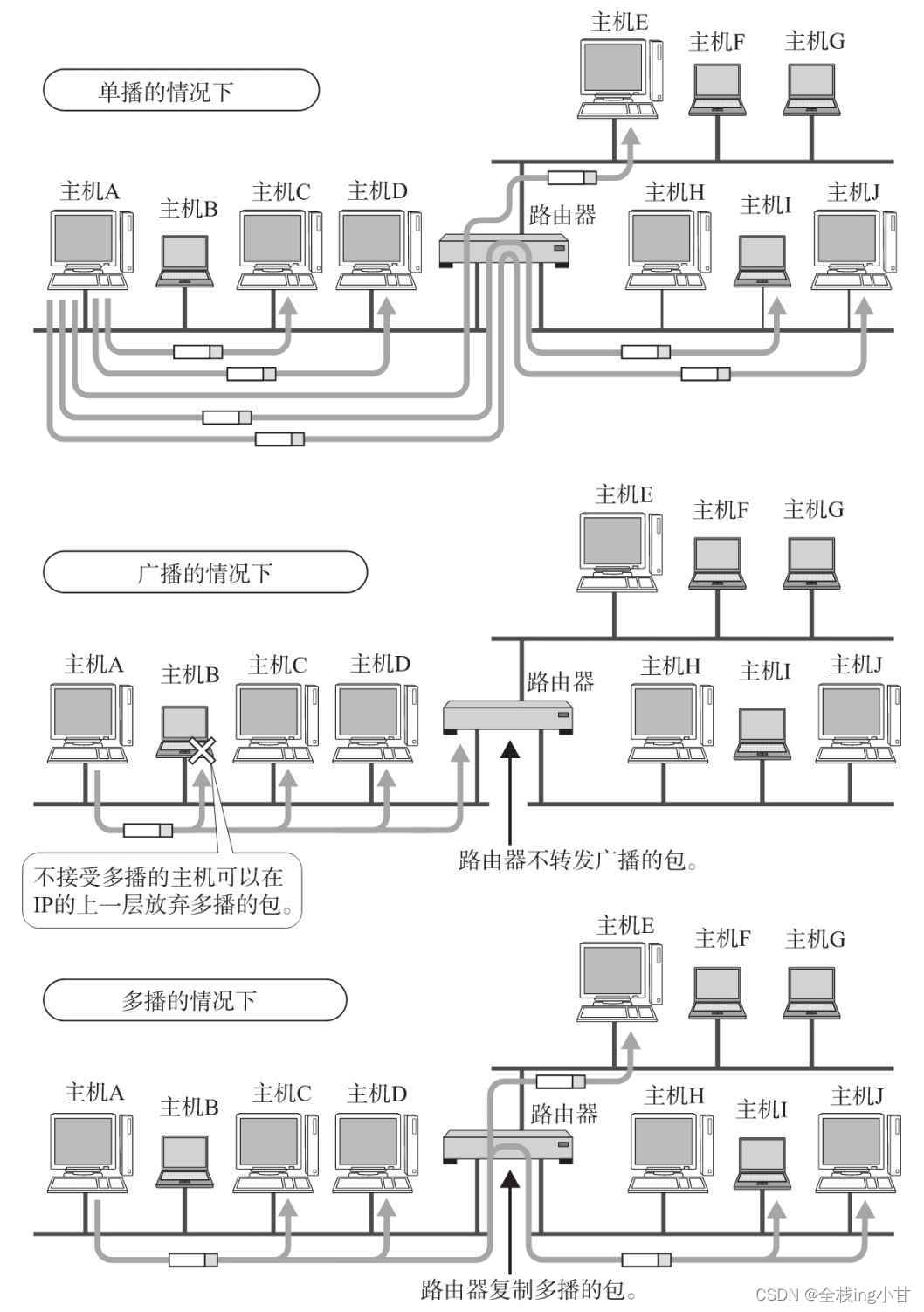
多播用于将包发送给特定组内的所有主机。由于其直接使用IP协议,因此也不存在可靠传输。
而随着多媒体应用的发展,对于向多台主机同时发送数据包,在效率上的要求也日益提高。在电视会议系统中对于1对N、N对N通信的需求明显上升。而具体实现上往往采用复制1对1通信的数据,将其同时发送给多个主机的方式。
在人们使用多播功能之前,一直采用广播的方式。那时广播将数据发给所有终端主机,再由这些主机IP之上的一层去判断是否有必要接收数据。是则接收,否则丢弃。
然而这种方式会给那些毫无关系的网络或主机带来影响,造成网络上很多不必要的流量。况且由于广播无法穿透路由,若想给其他网段发送同样的包,就不得不采取另一种机制。因此,多播这种既可以穿透路由器,又可以实现只给那些必要的组发送数据包的技术就成为必选之路了。
■ IP多播与地址
多播使用D类地址。因此,如果从首位开始到第4位是“1110”,就可以认为是多播地址。而剩下的28位可以成为多播的组编号。

从224.0.0.0到239.255.255.255都是多播地址的可用范围。其中从224.0.0.0到224.0.0.255的范围不需要路由控制,在同一个链路内也能实现多播。而在这个范围之外设置多播地址会给全网所有组内成员发送多播的包(可以利用生存时间(TTL,Time To Live)限制包的到达范围。) 。
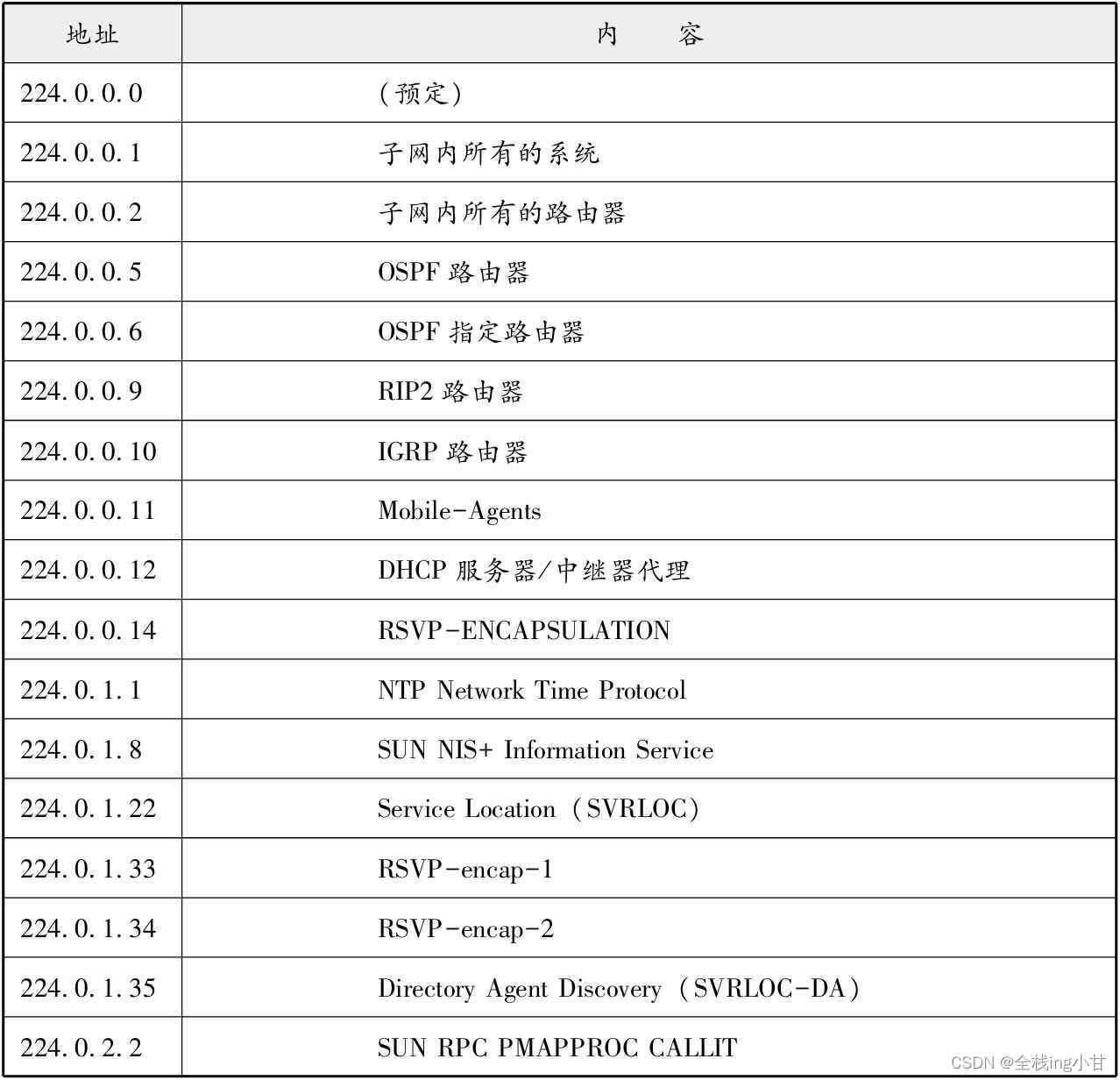
此外,对于多播,所有的主机(路由器以外的主机和终端主机)必须属于224.0.0.1的组,所有的路由器必须属于224.0.0.2的组。类似地,多播地址中有众多已知的地址,它们中具有代表性的部分已在下表列出。
利用IP多播实现通信,除了地址外还需要IGMP(Internet Group Management Protocol) 等协议的支持。
子网掩码
■ 分类造成浪费?
一个IP地址只要确定了其分类,也就确定了它的网络标识和主机标识。例如A类地址前8位(除首位“0”还有7位)、B类地址前16位(除首位“10”还有14位)、C类地址前24位(除首位“110”还有21位)分别是它们各自的网络标识部分。
由此,按照每个分类所表示的网络标识的范围如下所示。

用“1”表示IP网络地址的比特范围,用“0”表示IP主机地址范围。将它们以十进制表示,如下所示。其中“1”的部分是网络地址部分,“0”的部分是主机地址部分。
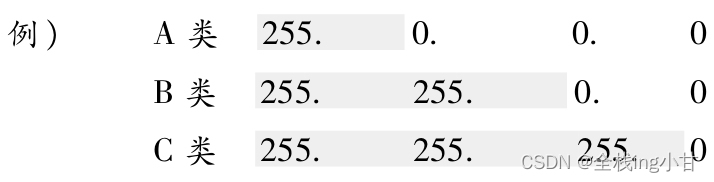
网络标识相同的计算机必须同属于同一个链路。例如,架构B类IP网络时,理论上一个链路内允许6万5千多台计算机连接。然而,在实际网络架构当中,一般不会有在同一个链路上连接6万5千多台计算机的情况。因此,这种网络结构实际上是不存在的。
因此,直接使用A类或B类地址,确实有些浪费。随着互联网的覆盖范围逐渐增大,网络地址会越来越不足以应对需求,直接使用A类、B类、C类地址就更加显得浪费资源。为此,人们已经开始一种新的组合方式以减少这种浪费。
■ 子网与子网掩码
现在,一个IP地址的网络标识和主机标识已不再受限于该地址的类别,而是由一个叫做“子网掩码”的识别码通过子网网络地址细分出比A类、B类、C类更小粒度的网络。这种方式实际上就是将原来A类、B类C类等分类中的主机地址部分用作子网地址,可以将原网络分为多个物理网络的一种机制。
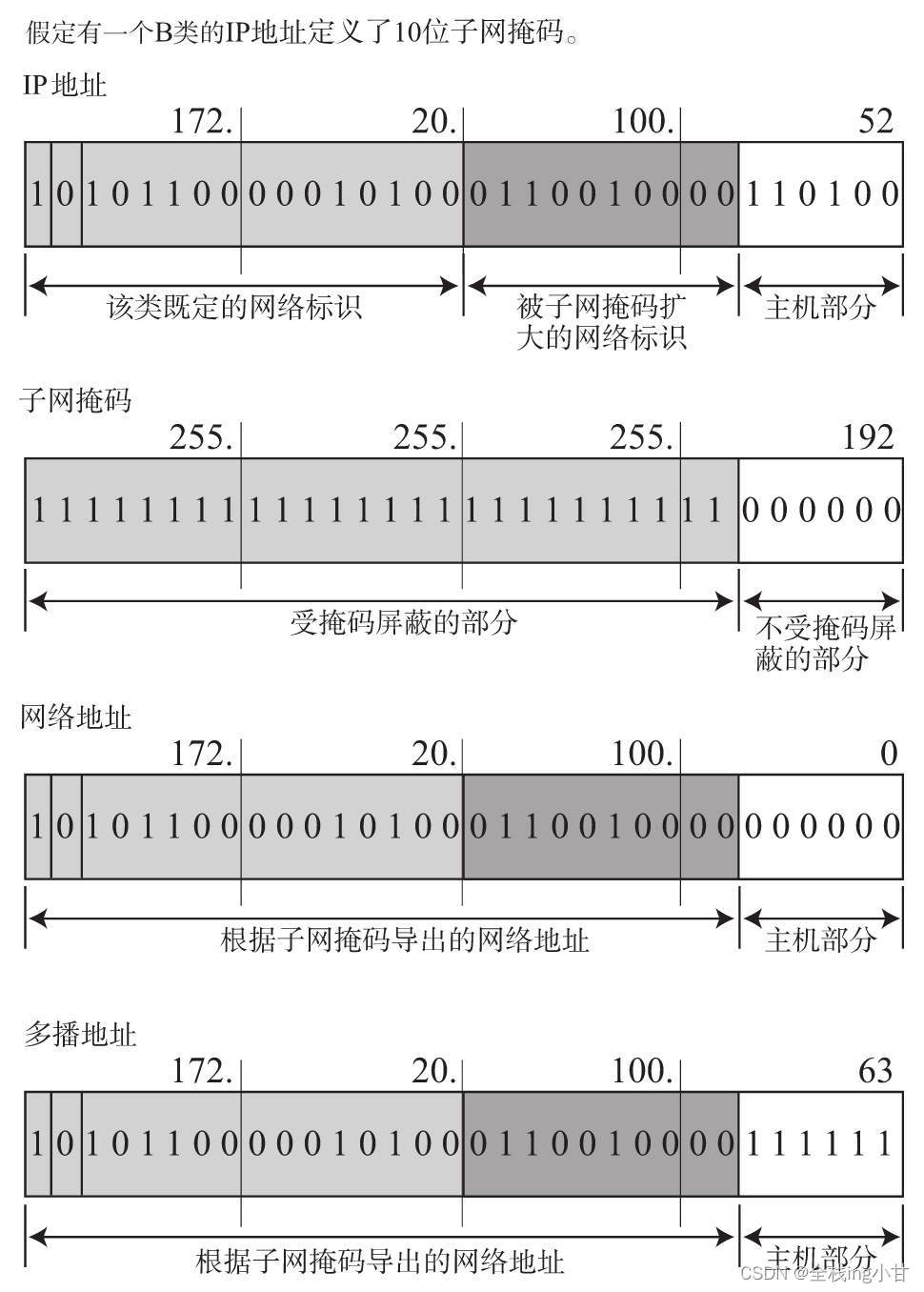
自从引入了子网以后,一个IP地址就有了两种识别码。一是IP地址本身,另一个是表示网络部的子网掩码。子网掩码用二进制方式表示的话,也是一个32位的数字。它对应IP地址网络标识部分的位全部为“1”,对应IP地址主机标识的部分则全部为“0”。由此,一个IP地址可以不再受限于自己的类别,而是可以用这样的子网掩码自由地定位自己的网络标识长度。当然,子网掩码必须是IP地址的首位开始连续的“1”(最初提出子网掩码时曾允许出现不连续的子网掩码,但现在基本不允许出现这种情况。) 。
对于子网掩码,目前有两种表示方式。以172.20.100.52的前26位是网络地址的情况为例,以下是其中一种表示方法,它将IP地址与子网掩码的地址分别用两行来表示。

另一种表示方式如下所示。它在每个IP地址后面追加网络地址的位数(这种方式也叫“后缀”表示法。) 用“/”隔开。
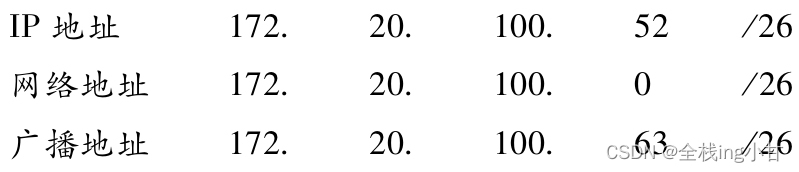
不难看出,在第二种方式下记述网络地址时可以省略后面的“0”。例如172.20.0.0/16跟172.20/16其实是一个意思。
IPv4首部
通过IP进行通信时,需要在数据的前面加入IP首部信息。IP首部中包含着用于IP协议进行发包控制时所有的必要信息。了解IP首部的结构,也就能够对IP所提供的功能有一个详细的把握。
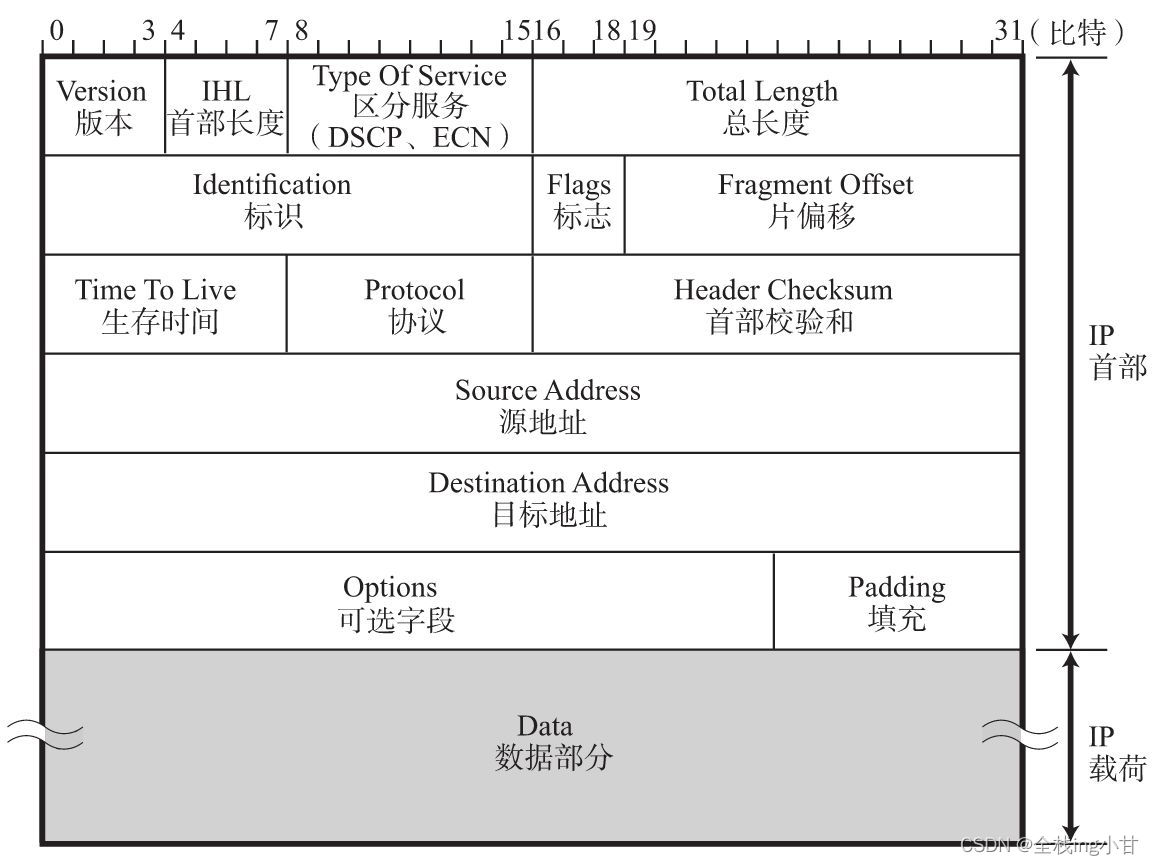
■ 版本(Version)
由4比特构成,表示标识IP首部的版本号。IPv4的版本号即为4,因此在这个字段上的值也是“4”。
■ 首部长度(IHL:Internet Header Length)
由4比特构成,表明IP首部的大小,单位为4字节(32比特)。对于没有可选项的IP包,首部长度则设置为“5”。也就是说,当没有可选项时,IP首部的长度为20字节(4×5=20)。
■ 区分服务(TOS:Type Of Service)
由8比特构成,用来表明服务质量。每一位的具体含义如表所示。

■ DSCP段与ECN段
DSCP(Differential Services Codepoint,差分服务代码点)是TOS(Type Of Service)的一部分。现在统称为DiffServ ,用来进行质量控制。
如果3~5位的值为0,0~2位则被称作类别选择代码点。这样就可以像TOS的优先度那样提供8种类型的质量控级别。对于每一种级别所采取的措施则由提供DiffServ的运营管理者制定。为了与TOS保持一致,值越大优先度也越高。如果第5位为1,表示实验或本地使用的意思。
ECN(Explicit Congestion Notification,显式拥塞通告)用来报告网络拥堵情况,由两个比特构成。
第6位的ECT用以通告上层TCP层协议是否处理ECN。当路由器在转发ECN为1的包的过程中,如果出现网络拥堵的情况,就将CE位设置为1 。
■ 总长度(Total Length)
表示IP首部与数据部分合起来的总字节数。该字段长16比特。因此IP包的最大长度为65535(=216 )字节。
目前还不存在能够传输最大长度为65535字节的IP包的数据链路。不过,由于有IP分片处理,从IP的上一层的角度看,不论底层采用何种数据链路,都可以认为能够以IP的最大包长传输数据。
■ 标识(ID:Identification)
由16比特构成,用于分片重组。同一个分片的标识值相同,不同分片的标识值不同。通常,每发送一个IP包,它的值也逐渐递增。此外,即使ID相同,如果目标地址、源地址或协议不同的话,也会被认为是不同的分片。
■ 标志(Flags)
由3比特构成,表示包被分片的相关信息。每一位的具体含义请参考下表。

■ 片偏移(FO:Fragment Offset)
由13比特构成,用来标识被分片的每一个分段相对于原始数据的位置。第一个分片对应的值为0。由于FO域占13位,因此最多可以表示8192(=213 )个相对位置。单位为8字节,因此最大可表示原始数据8×8192=65536字节的位置。
■ 生存时间(TTL:Time To Live)
由8比特构成,它最初的意思是以秒为单位记录当前包在网络上应该生存的期限。然而,在实际中它是指可以中转多少个路由器的意思。每经过一个路由器,TTL会减少1,直到变成0则丢弃该包(TTL占8位,因此可以表示0~255的数字。因此一个包的中转路由的次数不会超过28 =256个。由此可以避免IP包在网络内无限传递的问题。) 。
■ 协议(Protocol)
由8比特构成,表示IP首部的下一个首部隶属于哪个协议。
■ 首部校验和(Header Checksum)
由16比特(2个字节)构成,也叫IP首部校验和。该字段只校验数据报的首部,不校验数据部分。它主要用来确保IP数据报不被破坏。校验和的计算过程,首先要将该校验和的所有位置设置为0,然后以16比特为单位划分IP首部,并用1补数(1补数 通常计算机中对整数运算采用2补数的方式。但在校验和的计算中采用1补数运算方法。这样做的优点在于即使产生进位也可以回到第1位,可以防止信息缺失并且可以用2个0区分使用。) 计算所有16位字的和。最后将所得到这个和的1补数赋给首部校验和字段。
■ 源地址(Source Address)
由32比特(4个字节)构成,表示发送端IP地址。
■ 目标地址(Destination Address)
由32比特(4个字节)构成,表示接收端IP地址。
■ 可选项(Options)
长度可变,通常只在进行实验或诊断时使用。该字段包含如下几点信息:
安全级别
源路径
路径记录
时间戳
■ 填充(Padding)
也称作填补物。在有可选项的情况下,首部长度可能不是32比特的整数倍。为此,通过向字段填充0,调整为32比特的整数倍。
■ 数据(Data)
存入数据。将IP上层协议的首部也作为数据进行处理。