目录
一、教材观点
二、简述进程是如何运行的
简述进程切换原理:
三、线程是什么
线程底层是如何被管理的
四、重讲线程概念理解
一、教材观点
教材观点:
- 线程是一个执行分支,执行分支更细,调度成本更低。
- 线程是进程内部的一个执行流。
内核观点:线程是cpu调度的基本单位,进程是承担分配系统资源的基本实体。
大部分小伙伴应该理解不了,执行分支是什么、执行颗粒更细、调度成本为什么更低、线程为什么是进程的执行分支、和父子进程有什么区别……这一系列问题,看完了这篇文章就这些问题就能影迎刃而解。
二、简述进程是如何运行的
我们先要了解一下在内核角度,进程是如何执行一个程序的。
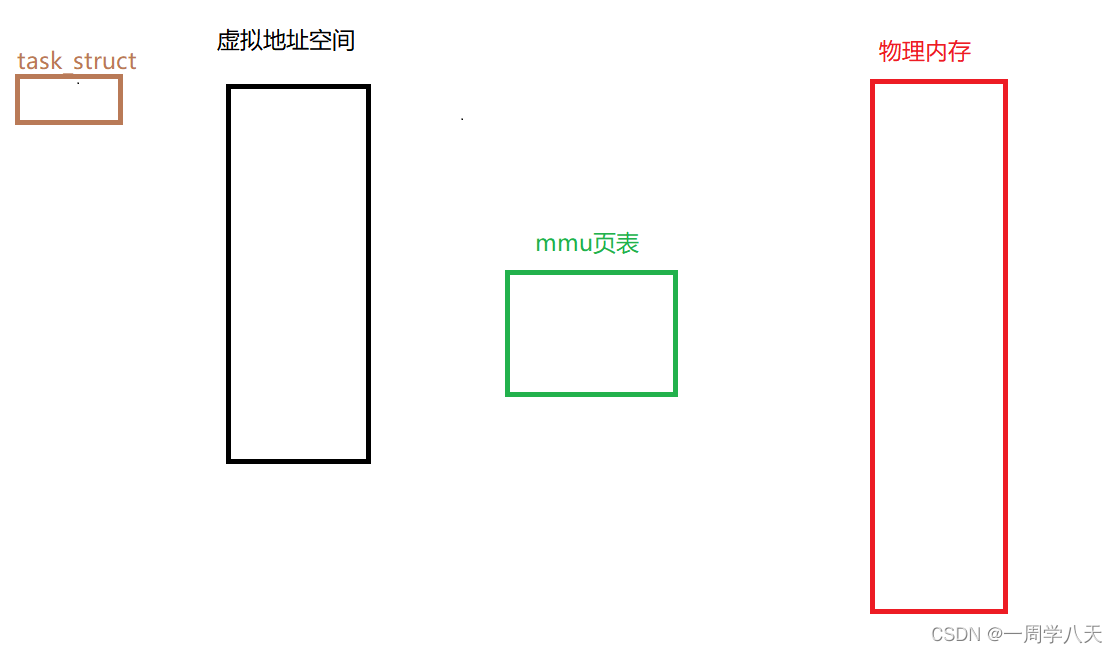
task_struct就代表了一个进程,每个进程都有自己的虚拟地址空间,一个虚拟地址空间又对应一个页表,这个页表会将这个虚拟地址空间映射都物理内存。

当然我们物理内存也是将磁盘上的数据导入进来,因为cpu看到代码或者数据的前提是将数据加载进物理内存。

这就是一个完整的进程运行需要的硬件了。
简述进程切换原理:
一台电脑不可能只有一个进程需要处理,但是cpu一次又只能处理一个进程,因此每个进程占用cpu的时间是有限的,每隔一段很短很短的时间就会有os(操作系统)强制切换一次进程,cpu先将目前进程处理进度记录下来,等下一次再处理这个进程就继续执行。
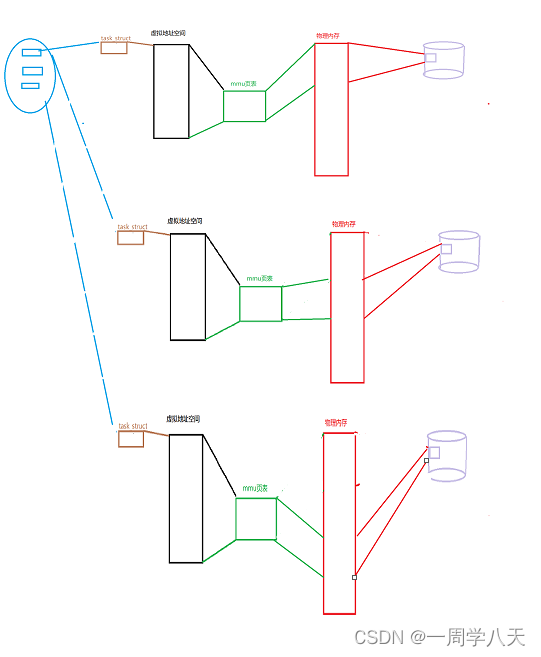
其实我们也可以充这张图看出来,每次切换进程的话,要跟着一起换的就不只是一个task结构体这么简单,要跟着一起换的还有mmu页表以及后面这一套的对应关系。
知识点补充:
进程控制块(Process Control Block,PCB)和任务结构体(Task Struct)是操作系统中用于表示进程的两个数据结构。
进程控制块(Process Control Block,PCB)是操作系统中用于管理和控制进程的一种数据结构。每个进程在操作系统中都有一个对应的 PCB,PCB 中包含了进程的状态信息、所需的系统资源(如 CPU 时间、内存、文件等)、程序计数器、栈指针、进程优先级等内容。当操作系统需要对进程进行调度、阻塞、唤醒等操作时,就需要通过修改相应进程的 PCB 来实现。其中,PCB 的结构和具体内容可能会因操作系统的不同而有所差异。
task_struct是Linux操作系统中用于描述进程和线程的数据结构。它是PCB的一种具体实现,包含了进程的ID、状态、进程命令行参数、内存信息、文件描述符、信号处理函数、调度信息等。Linux中一个进程对应一个task_struct结构体。
因此,PCB和task_struct实际上就是在不同操作系统中表示进程的不同数据结构而已。它们都是用来描述和管理进程的信息,是操作系统中非常重要的数据结构。
这也就是线程调度成本低的其中一个原因,线程是不需要通过多余的系统调用切换资源。
讲完上面的知识铺垫,我们再来聊聊
三、线程是什么
这是一个进程地址空间

我们现在浅显的认为代码段是由很多个函数组成的,

不同的线程就当成是一个个小的执行流,分别负责执行这段代码的不同函数,

中间那些小框框都是该进程创建的一个个线程,这些线程负责处理给他们分配的函数,并且在处理这些函数的同时,他们也共享着地址空间的一切。
os要不要像管理进程一样管理线程呢?答案是要的。
线程底层是如何被管理的
操作系统离不开一句话:先描述,再组织———— 描述:通过一个结构体将我们要储存的东西封装起来,然后再看通过一个数据结构储存起来以便管理。
进程就是通过task_struct和PCB这两种数据结构管理的。那么关于线程要怎么管理不同的操作系统有不同实现方式 。
Windows操作系统:
给线程专门创造一个新的数据结构然后再通过某种数据结构管理起来。这其实就是一般的思路,但相较于windows,Linux操作系统的实现方式就优雅很多。
Linux操作系统:
你进程不也需要先描述再组织吗,进程间不是也要相互切换吗,和我的线程实现除了不需要切换至资源不是一模一样吗?于是Linux操作系统就直接复用了进程的task_struct和PCB这两种结构以及算法。
这样做的好处就是:相较于windows,线程更好维护、效率更高、也更安全。你可别小看了一个区区线程,一款操作系统除了os本身,使用的最平凡的就是就是进程了,所以我们可以看到一种现象——linux系统是可以一直运行的不用关机,但是Windows能开机一个礼拜不管他试试。正是因为Linux对于很多细节的死扣不放,造成了这样的结果😁。
给大家看看我们能接触到的线程长啥样🙂:
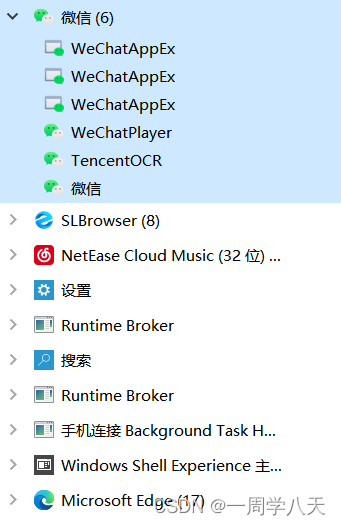
大的分类就是一个个进程,然后进程下面的小分支就是一个个线程,每个线程各司其职,比如微信就有负责窗口的、有负责数据io的、有链接硬件的等等
四、重讲线程概念理解
大部分小伙伴应该理解不了,执行分支是什么、执行颗粒更细、调度成本为什么更低、线程为什么是进程的执行分支、和父子进程有什么区别……这一系列问题,接下来我们会一个一个解释。
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。
- 线程可以同时等待不同的I/O操作。
五、实例操作
光说了这么多,就来见见猪跑吧:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
using namespace std;
void *threadRun1(void *args)
{
while(1)
{
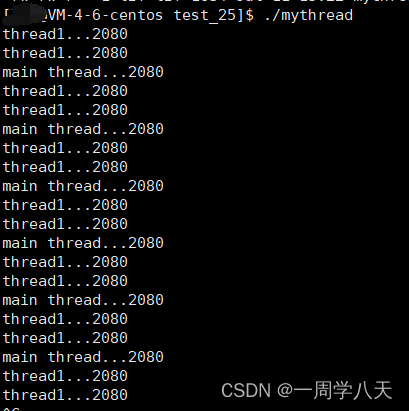
cout<<"thread1..."<<getpid()<<endl;
sleep(1);
}
}
void *threadRun2(void *args)
{
while(1)
{
cout<<"thread1..."<<getpid()<<endl;
sleep(1);
}
}
int main()
{
pthread_t t1,t2;
pthread_create(&t1,nullptr,threadRun1,nullptr);
pthread_create(&t2,nullptr,threadRun2,nullptr);
while(1)
{
sleep(1);
cout<<"main thread..."<<getpid()<<endl;
}
return 0;
}执行结果:




![本地git 提交代码时 报错 [session-4d40e187] Access denied](https://img-blog.csdnimg.cn/ede10e07bf3f47c7b76220bfc906bd27.png)