1.前置概念
- 应⽤(Application)/系统(System)
为了完成一整套服务的一个程序或相互配合的程序群
- 模块(Module)/组件(Component)
当应⽤较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于理解
- 分布式(Distributed)
分布式(Distributed)是指将计算、任务或数据分散到多个独立的计算机或节点上进行处理的方式。与传统的集中式系统相比,分布式系统具有更高的灵活性、可扩展性和冗余性。
在分布式系统中,各个节点可以通过网络进行通信和协作,共同完成任务。每个节点独立地执行一部分工作,并根据需要与其他节点进行交互。节点之间可以相互传递消息、共享资源和数据,以实现更加复杂和大规模的计算和服务。
- 集群(Cluster)
被部署于多台服务器上的、为了实现特定⽬标的⼀个/组特定的组件,整个整体被称为集群。
比如,多个MySQL⼯作在不同服务器上,共同提供数据库服务⽬标,可以被称为⼀组数据库集群
- 主(Master)/从(Slave)
集群中,通常有⼀个程序需要承担更多的职责,被称为主;其他承担附属职责的被称为从。⽐如MySQL集群中,只有其中⼀台服务器上数据库允许进⾏数据的写⼊(增/删/改),其他数据库的数据修改全部要从这台数据库同步⽽来,则把那台数据库称为主库,其他数据库称为从库。
- 中间件(Middleware)
⼀类提供不同应⽤程序⽤于相互通信的软件,即处于不同技术、⼯具和数据库之间的桥梁
评价指标(Metric)
- 可⽤性(Availability)
考察单位时间段内,系统可以正常提供服务的概率/期望
年化系统可⽤性=系统正常提供服务时⻓/⼀年总时⻓。
- 响应时⻓(ResponseTimeRT)
指⽤⼾完成输⼊到系统给出⽤⼾反应的时⻓。
- 吞吐(Throughput)vs并发(Concurrent)
吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同⼀时刻⽀持的请求最⾼量。
2.服务端⾼并发分布式结构演进之路
1.单机架构
单机架构:只有一台服务器,这台服务器用来负责所有的工作。整个系统在物理上只由一个节点组成,所有的计算和存储都发生在这个节点上。以一个电商网站为例
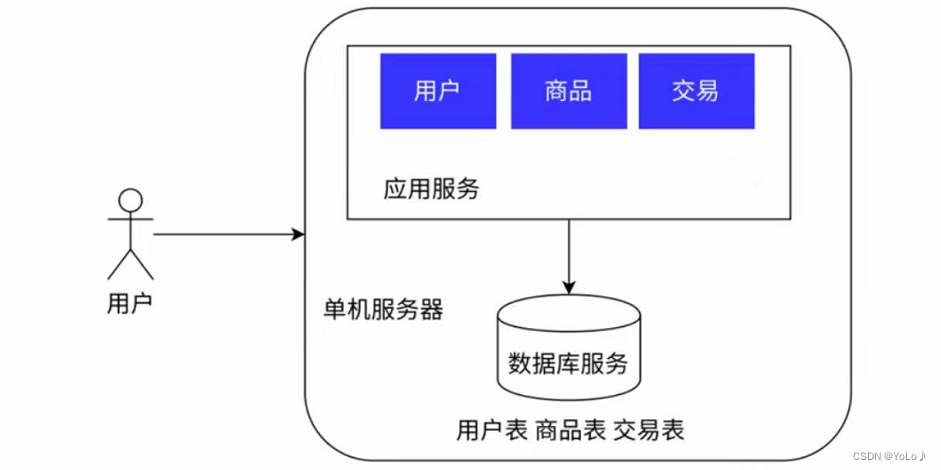
大部分的中小公司的产品,都是这种单机架构,整个系统只有一个单机服务器。由于计算机硬件发展速度非常之快,主机的性能都很高,能支持非常高的并发和非常大的数据存储,已经能满足大部分中小公司的需求。
单机架构相对于分布式架构来说,系统比较容易进行管理和维护,数据传输和处理的延迟较低,易于部署
当业务需求进一步增长时,用户量和数据量等都会增加,一台服务器难以应对时,就需要引入更多的主机和其他硬件资源
单机架构的缺点:
-
有限的性能和扩展性:由于计算和存储资源都集中在一个节点上,无法有效地利用分布式环境下多个节点的计算和存储能力。当系统的工作负载和数据量增加时,单机架构可能无法满足性能和扩展性(比如主机上能够增加的硬件资源等,都是有限的)的要求。
-
单点故障:由于只有一个节点,如果这个节点出现故障或停机,整个系统将无法正常运行。
-
硬件资源限制:单个节点的硬件资源(CPU、内存、磁盘等)是有限的,无法满足大规模数据处理和存储的需求。
一台主机的性能和扩展性满足不了需求,就需要引入多台主机了。引入多台主机后需要在软件上做出对应的调整和适配。
2.应⽤数据分离架构
引入多台主机后,就不是单机架构了,系统就可称为“分布式系统”
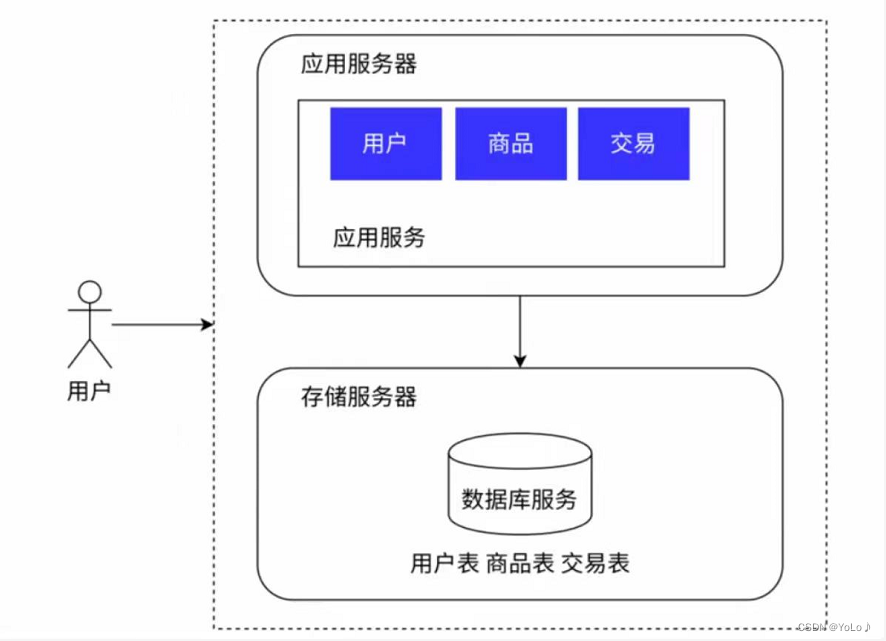
应用服务器和数据库服务器就是不同的服务器。并且可以根据不同服务器的特点配置不同的服务器,应用服务器会包含更多的业务逻辑,需要大量的计算分析,对cpu,内存性能要求高。数据库服务器需要更大的硬盘空间,更快的数据访问速度,对空间要求高。从而达到更高的性价比
3.应⽤服务集群架构
随着数据量进一步增加,单台应⽤服务器已经⽆法满⾜需求了。通过调整软件架构,增加应⽤层硬件,将用户流量分担到不同的应⽤层服务器上,来提升系统的承载能⼒。

负载均衡器(Load Balancer):也是一个单独的服务器,或者称为网关。是一种用于分发网络流量的设备或软件。它位于应用程序和网络基础设施之间,将传入的流量分配到多个服务器或计算资源上,以实现负载的均衡和性能的优化。(和之前学习的多线程思想相似,都是通过流量分发到多处进行处理,以提高效率)
负载均衡器的主要功能包括:
-
流量分发:接收传入的请求流量,将其分发到后端的多个服务器或计算资源上,以确保每个服务器都能得到相对均等的工作负载。
-
负载调度:采用不同的调度算法,如轮询、权重、最少连接等,来决定请求应该被分发到哪个后端服务器上。根据服务器的性能和负载情况,动态地调整流量分发策略。
-
高可用性:可以监控后端服务器的可用性,并在某个服务器发生故障或不可用时,自动将流量转移到其他正常工作的服务器上,确保服务的连续性和高可用性。
-
健康检查:可以定期检查后端服务器的健康状态,如响应时间、负载情况等,并根据检查结果来决定是否将流量分发给该服务器。
-
扩展性:通过添加更多的后端服务器,可以实现系统的水平扩展,以满足不断增长的流量需求。
负载均衡器的流量承担能力是远远超过应用服务器的,因为它只用单纯的分配任务,服务器是需要进行执行任务的,所花时间是更长的。如果超过负载均衡器的承受能力,就引入更多的负载均衡器,也就是多个机房,用来分担流量
4.读写分离/主从分离架构
我们通过负载均衡解决了请求量过大的问题,大量请求可以得到并行处理了,但是这些请求最终都要落到数据库的读写上,那么到一定程度上,就会到达瓶颈点。并且不能将数据库服务器和应用服务器一样进行扩展,将数据分散到不同的数据库后,会破坏数据的一致性,例如转账,如果一个数据库的数据修改了,另一个数据库没修改,就造成数据不一致
解决办法:数据库读写分离(主从分离)
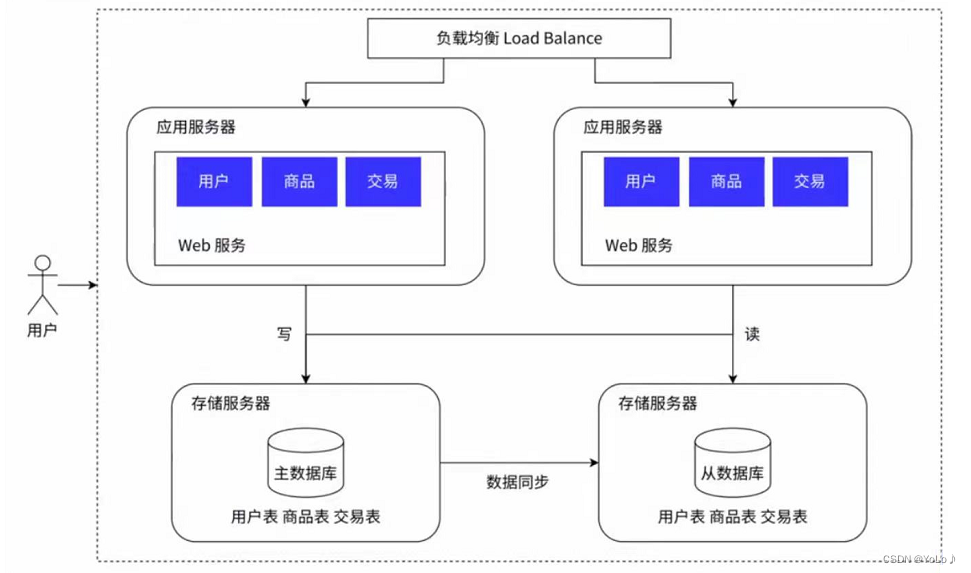
这样就引入了更多的硬件资源。写时向主数据库写,主数据库将数据同步给从数据库,读时从从数据库读。这样就分担了大量的读写请求。
5.引⼊缓存⸺冷热分离架构
实际上读的频率是远高于写的频率,因此主数据库服务器一般是一个,从数据库服务器有多个(一主多从),同时从数据库通过负载均衡的方式,让应用服务器进行访问。
针对数据库响应速度比较慢的问题,将数据进行“冷热”划分
热点数据放到缓存中,冷的数据放到硬盘。

缓存服务器中存放一小部分热点数据,根据二八原则,20%的数据,能够支持80%的访问量。数据库中存储的还是完整的数据,只是将热点数据放到缓存中了,缓存的速度非常快,但是容量小,成本高,也是Redis出现的位置。Redis的核心功能就是作为缓存服务器
也会付出一定的代价,就是数据的一致性问题,如果存储服务器的数据被修改,访问时使用的是缓存的数据,那就出现错误了,后续会学习如何解决。
6.分库分表
引入分布式系统不光要去应对高的请求量,也需要应对更大的数据量。虽然一个服务器存储的数据量可以达到几十个TB,即使如此面对不同的应用场景,也会存不下。需要使用多台主机存储数据
针对数据库进行分库分表
原本是一个数据库服务器,这个服务器上存储了多个数据库,create database 创建的数据库。现在由于数据量太大,一个数据库服务器存不下那么多数据,就引入多个数据库服务器,每个服务器上存储一个或一部分数据库
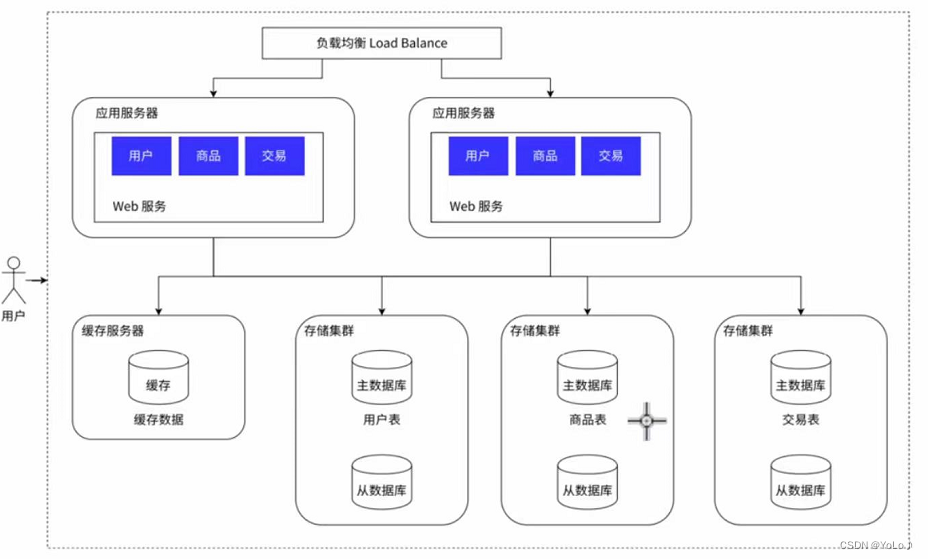
如果某个表特别大,一台服务器存不下,也可以针对表进行拆分,使用多个存储服务器及逆行存储
7.业务拆分⸺微服务
之前的应用服务器,一个服务器中要实现所有的业务,会导致这一个服务器的代码越来越复杂。按照功能拆成多组微服务,就可以便于代码的维护。
应用服务器复杂了之后,就需要更多的人力资源进行维护,增加了管理成本。为了减少管理成本,就可以把一个复杂的服务器,拆分成更多的,功能单一的,更小的服务器(微服务),就有利于划分组织结构,分多组进行管理。
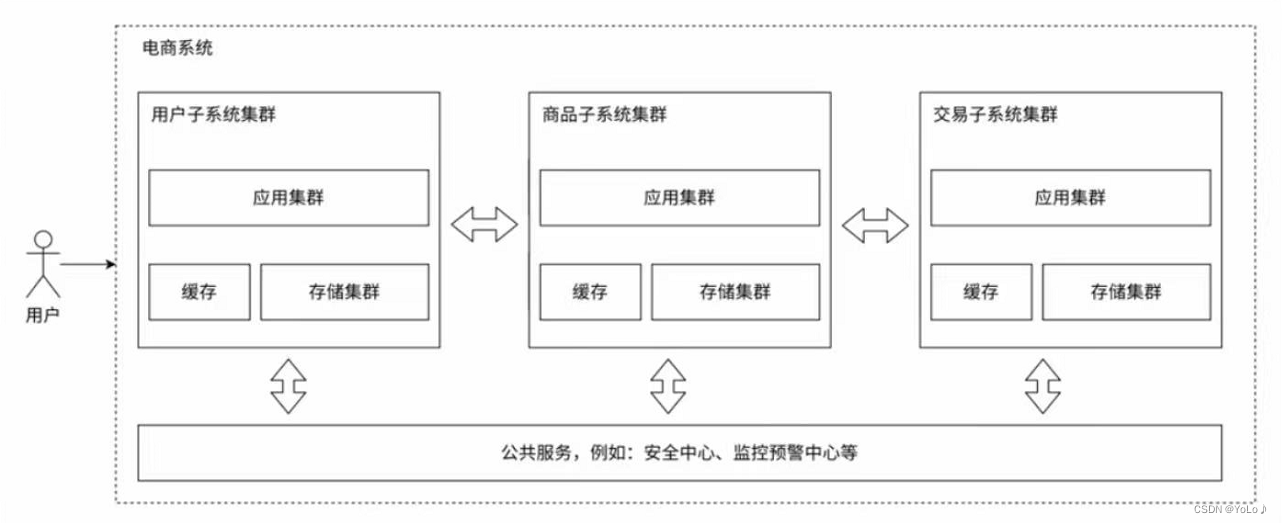
引入微服务主要是为了解决人的管理问题,付出的代价有:
1.系统性能下降,多个被拆出来的服务,功能之间需要更依赖网络通信。引入更多的机器提升性能,万兆网卡等等配套设施
2.系统复杂程度提高,可用性降低,出现问题的概率增加,引入更丰富的报警机制,监控系统,以及运维人员