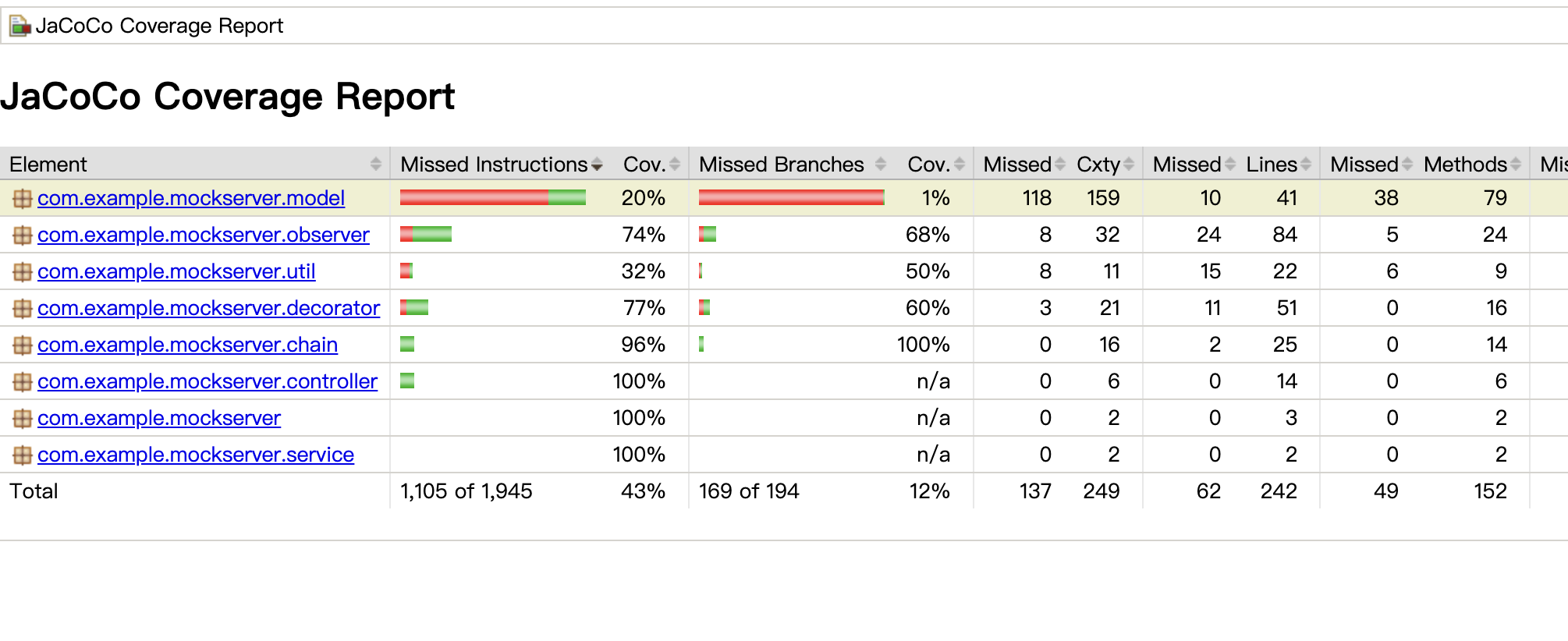
在应用中,我们使用的 SpringData ES的 ElasticsearchRestTemplate来做查询,使用方式不对,导致每次ES查询时都新实例化了一个查询对象,会加载相关类到元数据中。最终长时间运行后元数据出现内存溢出;
问题原因:类加载过多,导致元数据OOM。非类实例多或者大对象问题;
排查方式:
查看JVM运行情况,发现元数据满导致内存溢出;
导出内存快照,通过OQL快速定位肇事者;
排查对应类的使用场景和加载场景(重点序列化反射场景);
起源
06-15 下午正摩肩擦掌的备战着晚上8点。收到预发机器的一个GC次数报警。
【警告】UMP JVM监控
【警告】异步(async采集点:async.jvm.info(别名:jvm监控)15:42:40至15:42:50【xx.xx.xx.xxx(10174422426)(未知分组)】,JVM监控FullGC次数=2次[偏差0%],超过1次FullGC次数>=2次
【时间】2023-06-15 15:42:50
【类型】UMP JVM监控
第一时间诧异了下。该应用主要作用是接MQ消息和定时任务,同时任务和MQ都和线上做了隔离,也没有收到大流量的告警。
先看了下对应JVM监控:

只看上面都怀疑是监控异常(之前用文件采集的时候有遇到过,看CPU确实有波动。但堆基本无涨幅,怀疑非堆。)

问题排查
定位分析
既然怀疑非堆,我们先通过 jstat来看看情况
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 0.89 3.67 97.49 97.96 854 23.720 958 615.300 639.020
0.00 0.00 0.89 3.67 97.49 97.96 854 23.720 958 615.300 639.020
0.00 0.00 0.89 3.67 97.49 97.96 854 23.720 958 615.300 639.020
0.00 0.00 0.89 3.67 97.49 97.96 854 23.720 958 615.300 639.020
0.00 0.00 0.89 3.67 97.49 97.96 854 23.720 958 615.300 639.020
M列代表了metaspace的使用率,当前已经 97.49% 进一步印证了我们的猜测。
接下来通过 jmap 导出内存快照分析。这里我习惯使用 Visual VM 进行分析。
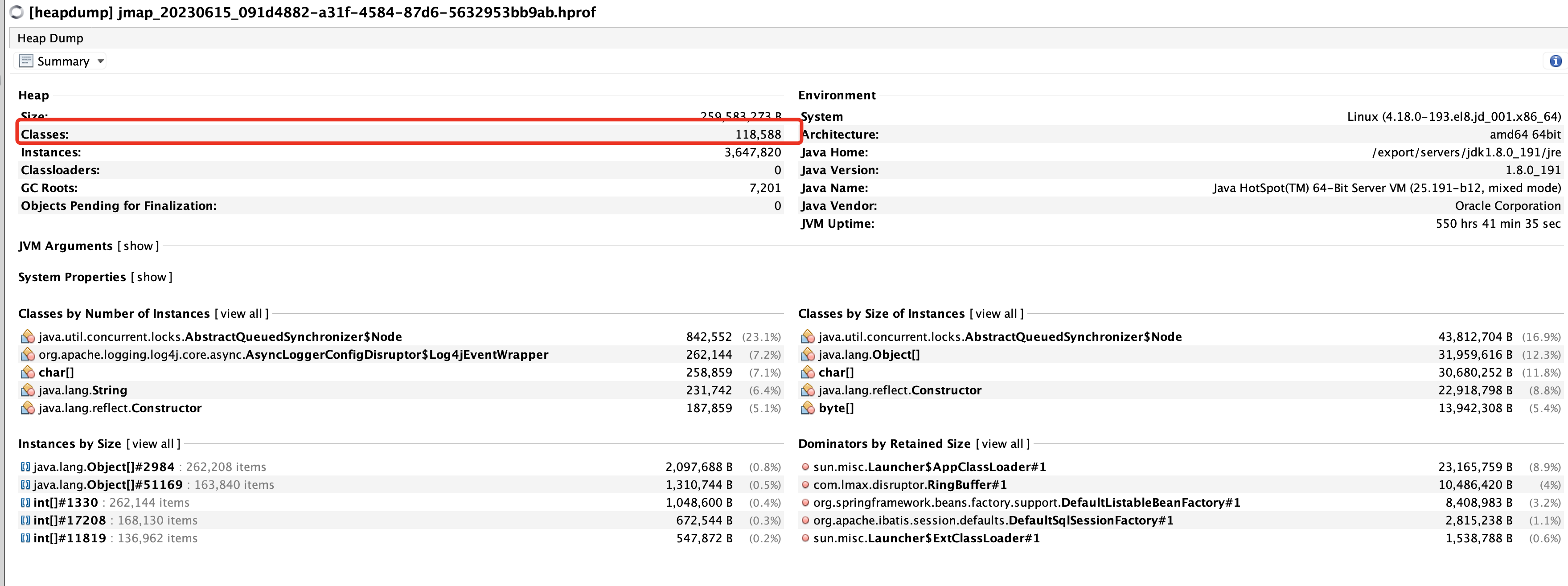
在这里我们看到有 118588 个类被加载了。正常业务下不会有这么多类。
这里我们走了很多弯路。
首先查看内存对象,根据类的实例数排了个序,试图看看是否是某个或某些类实例过多导致。
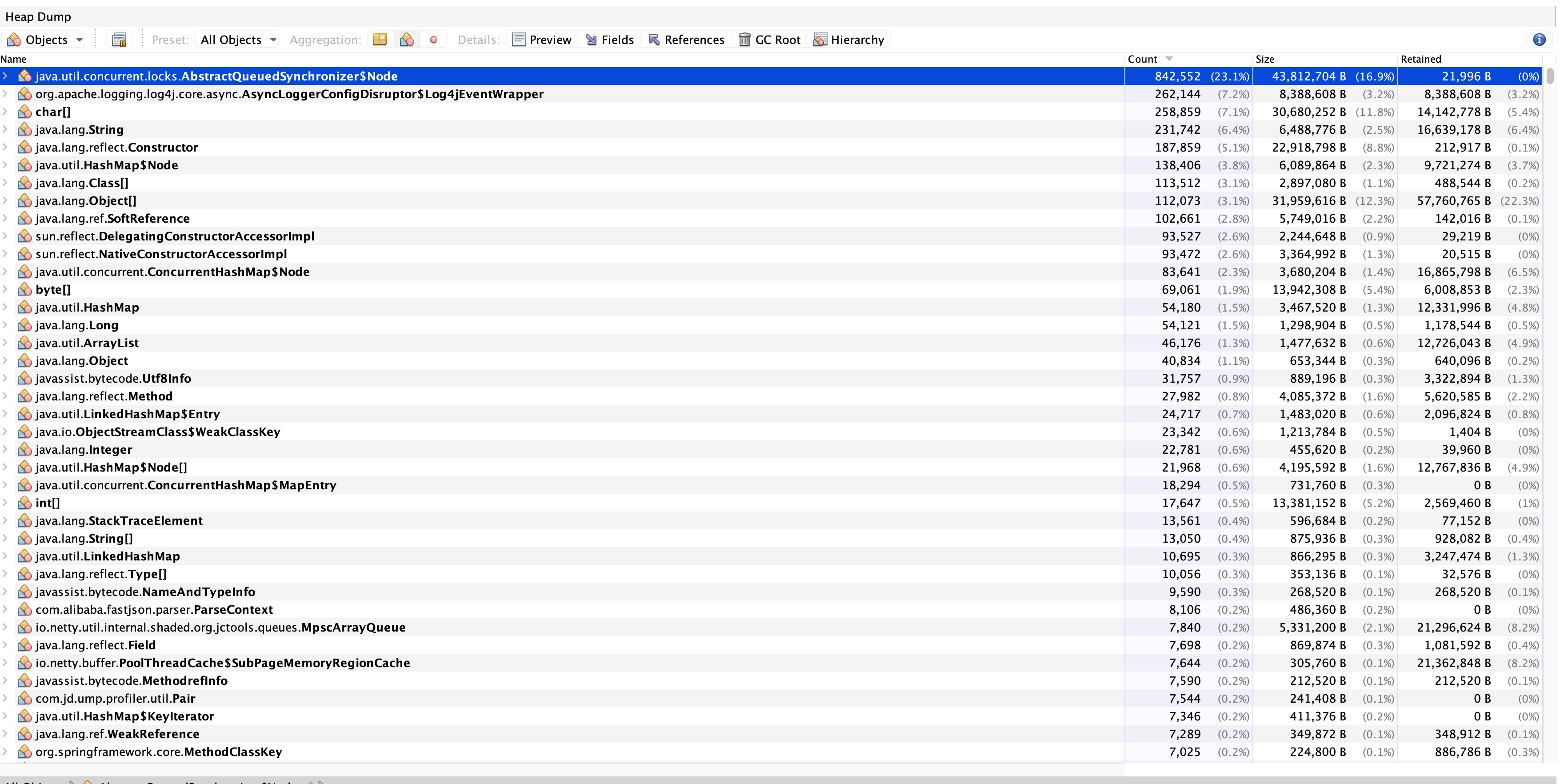
这里一般是排查堆异常时使用,可以看大对象和某类的实例数,但我们的问题是类加载过多。非类实例对象多或者大。这里排除。
后续还尝试了直接使用 Visual VM 的聚合按包路径统计,同时排序。收效都甚微。看不出啥异常来。
这里我们使用 OQL 来进行查询统计。
语句如下:
var packageClassSizeMap = {};
// 遍历统计以最后一个逗号做分割
heap.forEachClass(function (it) {
var packageName = it.name.substring(0, it.name.lastIndexOf('.'));
if (packageClassSizeMap[packageName] != null) {
packageClassSizeMap[packageName] = packageClassSizeMap[packageName] + 1;
} else {
packageClassSizeMap[packageName] = 1;
}
});
// 排序 因为Visual VM的查询有数量限制。
var sortPackageClassSizeMap = [];
map(sort(Object.keys(packageClassSizeMap), function (a, b) {
return packageClassSizeMap[b] - packageClassSizeMap[a]
}), function (it) {
sortPackageClassSizeMap.push({
package: it,
classSize: packageClassSizeMap[it]
})
});
sortPackageClassSizeMap;
执行效果如下:
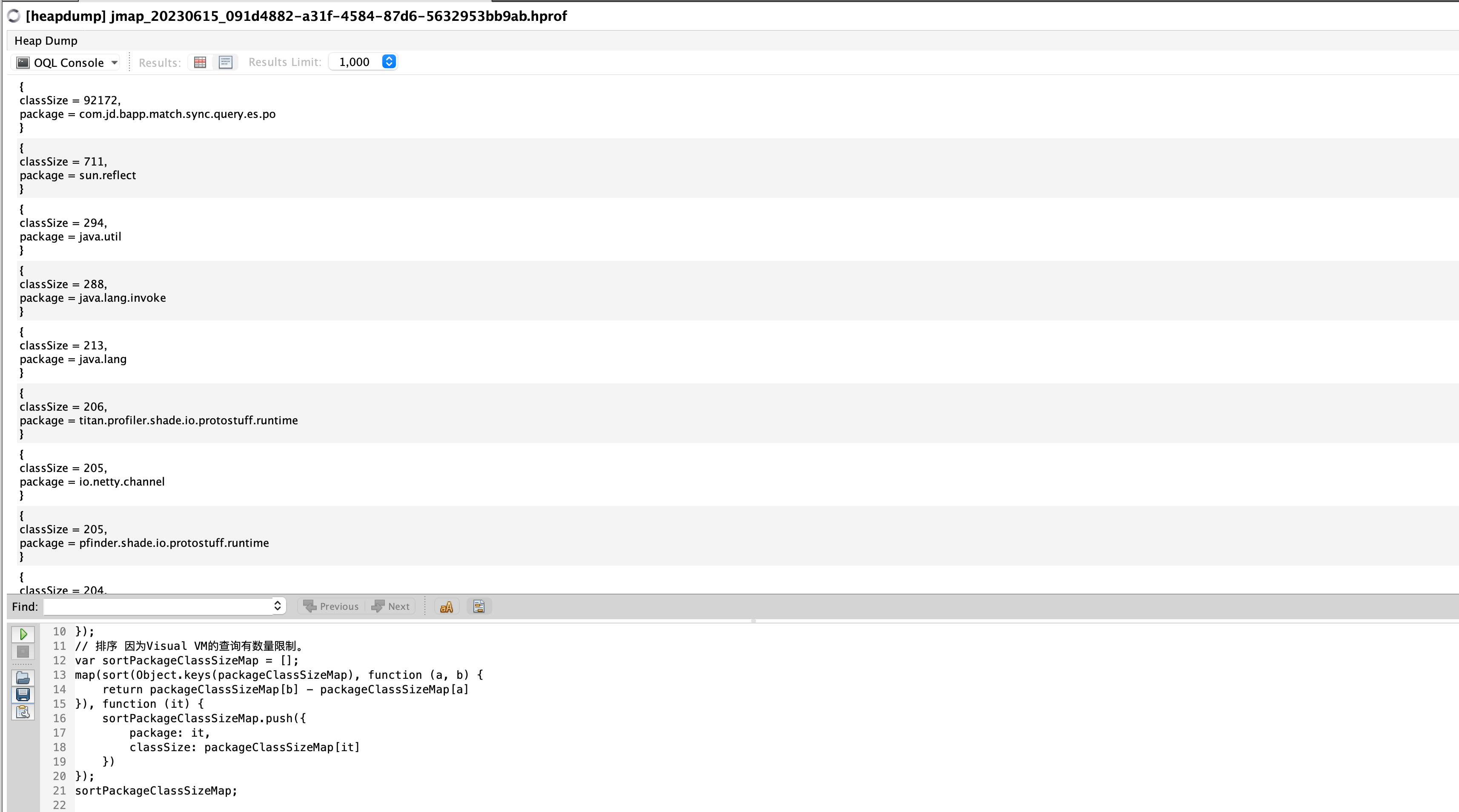
可以看到,com.jd.bapp.match.sync.query.es.po 下存在 92172 个类。这个包下,不到20个类。这时我们在回到开始查看类的地方。看看该路径下都是些什么类。
这里附带一提,直接根据路径获取对应的类数量:
var packageClassSizeMap = {};
// 遍历统计以最后一个逗号做分割
heap.forEachClass(function (it) {
var packageName = it.name.substring(0, it.name.lastIndexOf('.'));
// 加路径过滤版
if (packageName.indexOf('com.jd.bapp.match.sync.query.es.po')){
if (packageClassSizeMap[packageName] != null) {
packageClassSizeMap[packageName] = packageClassSizeMap[packageName] + 1;
} else {
packageClassSizeMap[packageName] = 1;
}
}
});
sortPackageClassSizeMap;
查询 com.jd.bapp.match.sync.query.es.po 路径下的classes
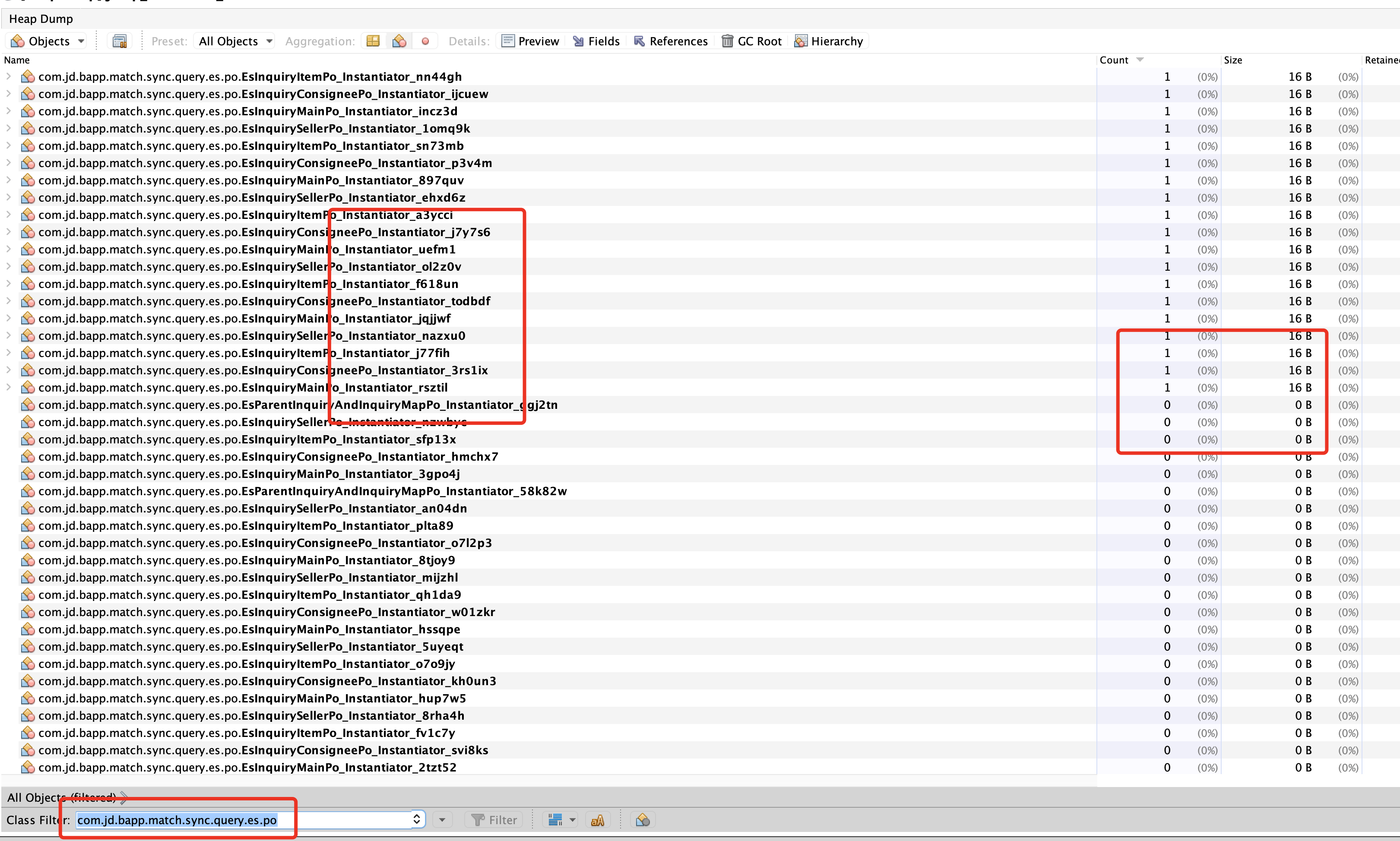
我们可以看到:
- 每个ES的Po对象存在大量类加载,在后面有拼接Instantiator_xxxxx
- 部分类有实例,部分类无实例。(count为实例数)
从上面得到的信息得出是ES相关查询时出现的。我们本地debug查询跟踪下。
抽丝剥茧
这里列下主要排查流程
在应用中,我们使用的 SpringData ES的 ElasticsearchRestTemplate来做查询,主要使用方法 org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate#search
重点代码如下:
public <T> SearchHits<T> search(Query query, Class<T> clazz, IndexCoordinates index) {
// 初始化request
SearchRequest searchRequest = requestFactory.searchRequest(query, clazz, index);
// 获取值
SearchResponse response = execute(client -> client.search(searchRequest, RequestOptions.DEFAULT));
SearchDocumentResponseCallback<SearchHits<T>> callback = new ReadSearchDocumentResponseCallback<>(clazz, index);
// 转换为对应类型
return callback.doWith(SearchDocumentResponse.from(response));
}
加载
首先看初始化request的逻辑
-
org.springframework.data.elasticsearch.core.RequestFactory#searchRequest-
首先是:
org.springframework.data.elasticsearch.core.RequestFactory#prepareSearchRequest-
这里有段代码是对搜索结果的排序处理:
prepareSort(query, sourceBuilder, getPersistentEntity(clazz));重点就是这里的getPersistentEntity(clazz)
这段代码主要会识别当前类是否已经加载过,没有加载过则加载到内存中:@Nullable private ElasticsearchPersistentEntity<?> getPersistentEntity(@Nullable Class<?> clazz) { // 从convert上下文中获取判断该类是否已经加载过,如果没有加载过,就会重新解析加载并放入上下文 return clazz != null ? elasticsearchConverter.getMappingContext().getPersistentEntity(clazz) : null; }
-
-
具体加载的实现见: 具体实现见:org.springframework.data.mapping.context.AbstractMappingContext#getPersistentEntity(org.springframework.data.util.TypeInformation<?>)
/*
* (non-Javadoc)
* @see org.springframework.data.mapping.model.MappingContext#getPersistentEntity(org.springframework.data.util.TypeInformation)
*/
@Nullable
@Override
public E getPersistentEntity(TypeInformation<?> type) {
Assert.notNull(type, "Type must not be null!");
try {
read.lock();
// 从上下文获取当前类
Optional<E> entity = persistentEntities.get(type);
// 存在则返回
if (entity != null) {
return entity.orElse(null);
}
} finally {
read.unlock();
}
if (!shouldCreatePersistentEntityFor(type)) {
try {
write.lock();
persistentEntities.put(type, NONE);
} finally {
write.unlock();
}
return null;
}
if (strict) {
throw new MappingException("Unknown persistent entity " + type);
}
// 不存在时,添加该类型到上下文
return addPersistentEntity(type).orElse(null);
}
使用
上述是加载流程。执行查询后,我们还需要进行一次转换。这里就到了使用的地方:org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate#search中 callback.doWith(SearchDocumentResponse.from(response));
这里这个方法会请求内部的 doWith 方法。实现如下:
@Nullable
public T doWith(@Nullable Document document) {
if (document == null) {
return null;
}
// 获取到待转换的类实例
T entity = reader.read(type, document);
return maybeCallbackAfterConvert(entity, document, index);
}
其中的 reader.read 会先从上下文中获取上述加载到上下文的类信息,然后读取
@Override
public <R> R read(Class<R> type, Document source) {
TypeInformation<R> typeHint = ClassTypeInformation.from((Class<R>) ClassUtils.getUserClass(type));
typeHint = (TypeInformation<R>) typeMapper.readType(source, typeHint);
if (conversions.hasCustomReadTarget(Map.class, typeHint.getType())) {
R converted = conversionService.convert(source, typeHint.getType());
if (converted == null) {
// EntityReader.read is defined as non nullable , so we cannot return null
throw new ConversionException("conversion service to type " + typeHint.getType().getName() + " returned null");
}
return converted;
}
if (typeHint.isMap() || ClassTypeInformation.OBJECT.equals(typeHint)) {
return (R) source;
}
// 从上下文获取之前加载的类
ElasticsearchPersistentEntity<?> entity = mappingContext.getRequiredPersistentEntity(typeHint);
// 获取该类信息
return readEntity(entity, source);
}
读取会走 org.springframework.data.elasticsearch.core.convert.MappingElasticsearchConverter#readEntity
先是读取该类的初始化器:EntityInstantiator instantiator = instantiators.getInstantiatorFor(targetEntity);
-
是通过该类实现:
org.springframework.data.convert.KotlinClassGeneratingEntityInstantiator#createInstance- 然后到:
org.springframework.data.mapping.model.ClassGeneratingEntityInstantiator#doCreateEntityInstantiator
- 然后到:
/*
* (non-Javadoc)
* @see org.springframework.data.convert.ClassGeneratingEntityInstantiator#doCreateEntityInstantiator(org.springframework.data.mapping.PersistentEntity)
*/
@Override
protected EntityInstantiator doCreateEntityInstantiator(PersistentEntity<?, ?> entity) {
PreferredConstructor<?, ?> constructor = entity.getPersistenceConstructor();
if (ReflectionUtils.isSupportedKotlinClass(entity.getType()) && constructor != null) {
PreferredConstructor<?, ?> defaultConstructor = new DefaultingKotlinConstructorResolver(entity)
.getDefaultConstructor();
if (defaultConstructor != null) {
// 获取对象初始化器
ObjectInstantiator instantiator = createObjectInstantiator(entity, defaultConstructor);
return new DefaultingKotlinClassInstantiatorAdapter(instantiator, constructor);
}
}
return super.doCreateEntityInstantiator(entity);
}
这里先请求内部的:createObjectInstantiator
/**
* Creates a dynamically generated {@link ObjectInstantiator} for the given {@link PersistentEntity} and
* {@link PreferredConstructor}. There will always be exactly one {@link ObjectInstantiator} instance per
* {@link PersistentEntity}.
*
* @param entity
* @param constructor
* @return
*/
ObjectInstantiator createObjectInstantiator(PersistentEntity<?, ?> entity,
@Nullable PreferredConstructor<?, ?> constructor) {
try {
// 调用生成
return (ObjectInstantiator) this.generator.generateCustomInstantiatorClass(entity, constructor).newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
获取对象生成实例:generateCustomInstantiatorClass 这里获取类名称,会追加 _Instantiator_和对应类的 hashCode
/**
* Generate a new class for the given {@link PersistentEntity}.
*
* @param entity
* @param constructor
* @return
*/
public Class<?> generateCustomInstantiatorClass(PersistentEntity<?, ?> entity,
@Nullable PreferredConstructor<?, ?> constructor) {
// 获取类名称
String className = generateClassName(entity);
byte[] bytecode = generateBytecode(className, entity, constructor);
Class<?> type = entity.getType();
try {
return ReflectUtils.defineClass(className, bytecode, type.getClassLoader(), type.getProtectionDomain(), type);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
private static final String TAG = "_Instantiator_";
/**
* @param entity
* @return
*/
private String generateClassName(PersistentEntity<?, ?> entity) {
// 类名+TAG+hashCode
return entity.getType().getName() + TAG + Integer.toString(entity.hashCode(), 36);
}
到此我们元数据中的一堆 拼接了 Instantiator_xxxxx 的类来源就破案了。
真相大白
对应问题产生的问题也很简单。
// 每次search前 都new了个RestTemplate,导致上下文发生变化,每次重新生成加载
new ElasticsearchRestTemplate(cluster);
这里我们是双集群模式,每次请求时会由负载决定使用那一个集群。之前在这里每次都 new了一个待使用集群的实例。
内部的上下文每次初始化后都是空的。
-
请求查询ES
-
初始化ES查询
- 上下文为空
- 加载类信息(hashCode发生变化)
- 获取类信息(重计算类名)
- 重新加载类到元数据
-
最终长时间运行后元数据空间溢出;
事后结论
1.当时的临时方案是重启应用,元数据区清空,同时临时也可以放大元数据区大小。
2.元数据区的类型卸载或回收,8以后已经不使用了。
3.元数据区的泄漏排查思路:找到加载多的类,然后排查使用情况和可能的加载场景,一般在各种序列化反射场景。
4.快速排查可使用我们的方案。使用OQL来完成。
5.监控可以考虑加载类实例监控和元数据空间使用大小监控和对应报警。可以提前发现和处理。
6.ES查询在启动时对应集群内部初始化一个查询实例。使用那个集群就使用对应的集群查询实例。
附录
VisualVM下载地址:https://visualvm.github.io/
OQL: Object Query Language 可参看在VisualVM中使用OQL分析
获取路径下类加载数量,从高到低排序
var packageClassSizeMap = {};
// 遍历统计以最后一个逗号做分割
heap.forEachClass(function (it) {
var packageName = it.name.substring(0, it.name.lastIndexOf('.'));
if (packageClassSizeMap[packageName] != null) {
packageClassSizeMap[packageName] = packageClassSizeMap[packageName] + 1;
} else {
packageClassSizeMap[packageName] = 1;
}
});
// 排序 因为Visual VM的查询有数量限制。
var sortPackageClassSizeMap = [];
map(sort(Object.keys(packageClassSizeMap), function (a, b) {
return packageClassSizeMap[b] - packageClassSizeMap[a]
}), function (it) {
sortPackageClassSizeMap.push({
package: it,
classSize: packageClassSizeMap[it]
})
});
sortPackageClassSizeMap;
获取某个路径下类加载数量
var packageClassSizeMap = {};
// 遍历统计以最后一个逗号做分割
heap.forEachClass(function (it) {
var packageName = it.name.substring(0, it.name.lastIndexOf('.'));
// 加路径过滤版
if (packageName.indexOf('com.jd.bapp.match.sync.query.es.po')){
if (packageClassSizeMap[packageName] != null) {
packageClassSizeMap[packageName] = packageClassSizeMap[packageName] + 1;
} else {
packageClassSizeMap[packageName] = 1;
}
}
});
sortPackageClassSizeMap;
特别鸣谢
感谢黄仕清和Jdos同学提供的技术支持。
作者:京东零售 王建波
来源:京东云开发者社区