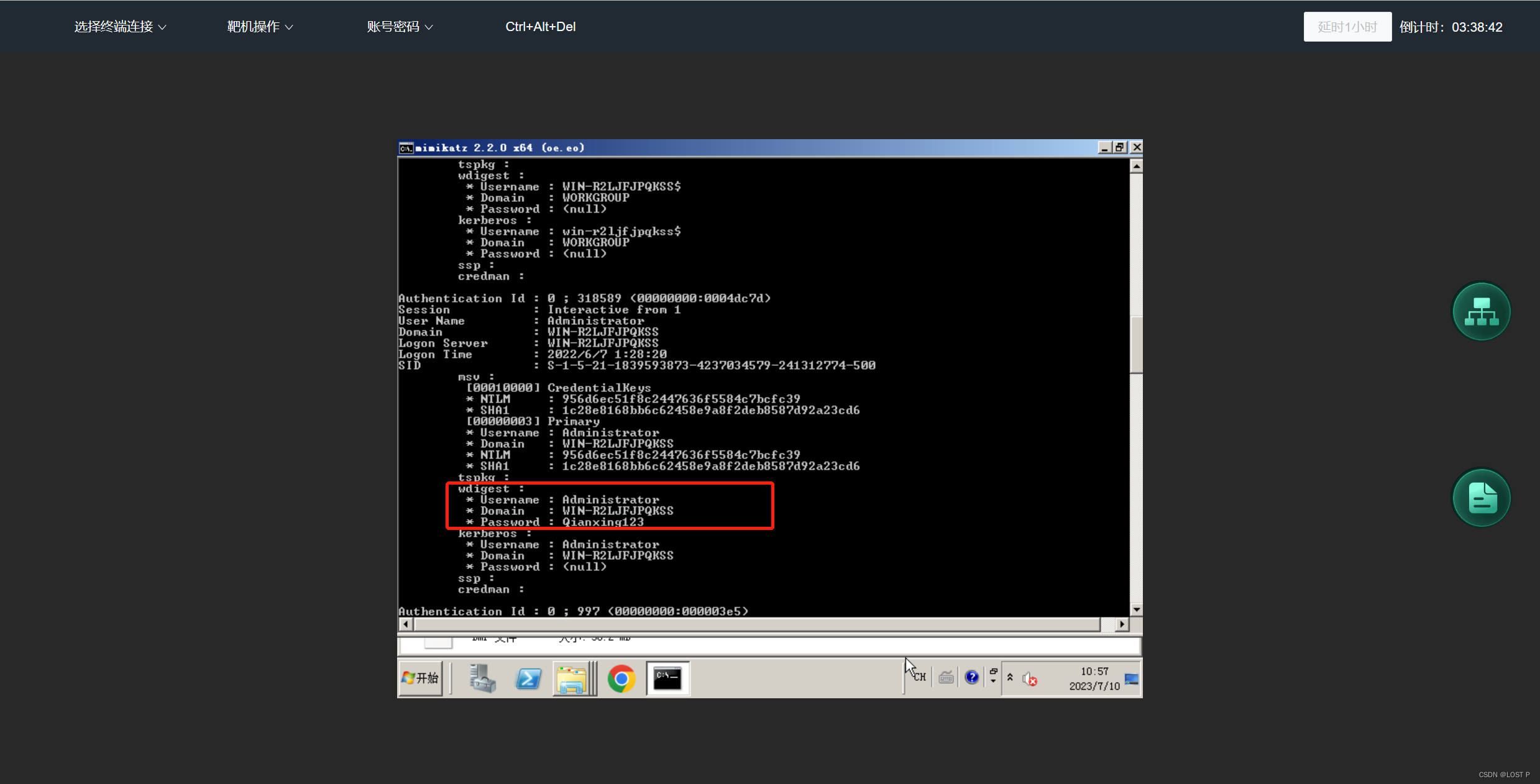
使用 torch.utils.data.dataset.Dataset 收集数据信息,创建数据集。
使用 import torch.utils.data.dataloader 创建一个可以批量迭代的数据载入器,并通过 for 循环批量读取所有文件的数据。
import torch.utils.data.dataset as dataset
import torch.utils.data.dataloader as dataLoader
from natsort import natsorted
import os
class data_set(dataset.Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.data_name = os.listdir(self.data_dir)
self.data_name = natsorted(self.data_name)
def __len__(self):
return len(self.data_name)
def __getitem__(self, idx):
data_file = os.path.join(self.data_dir, self.data_name[idx])
with open(data_file, mode='r', encoding='utf-8') as f:
data = f.read()
return data, data_file
def print_data_name(self):
print(self.data_name)
if __name__ == '__main__':
# 首先创建一个数据集,让数据集对象知道去哪里读取数据,并收集路径中文件的文件名信息
log_set = data_set('./log/i_loop1/')
print(log_set.print_data_name())
# 打乱数据集内的数据排序
log_set = torch.utils.data.DataLoader(
dataset=log_set,
batch_size=4,
pin_memory=True,
shuffle=False,
sampler=None,
drop_last=True,
num_workers=0
)
for idx, (data, file) in enumerate(log_set):
print(idx)
print(data)
print(file)输出为
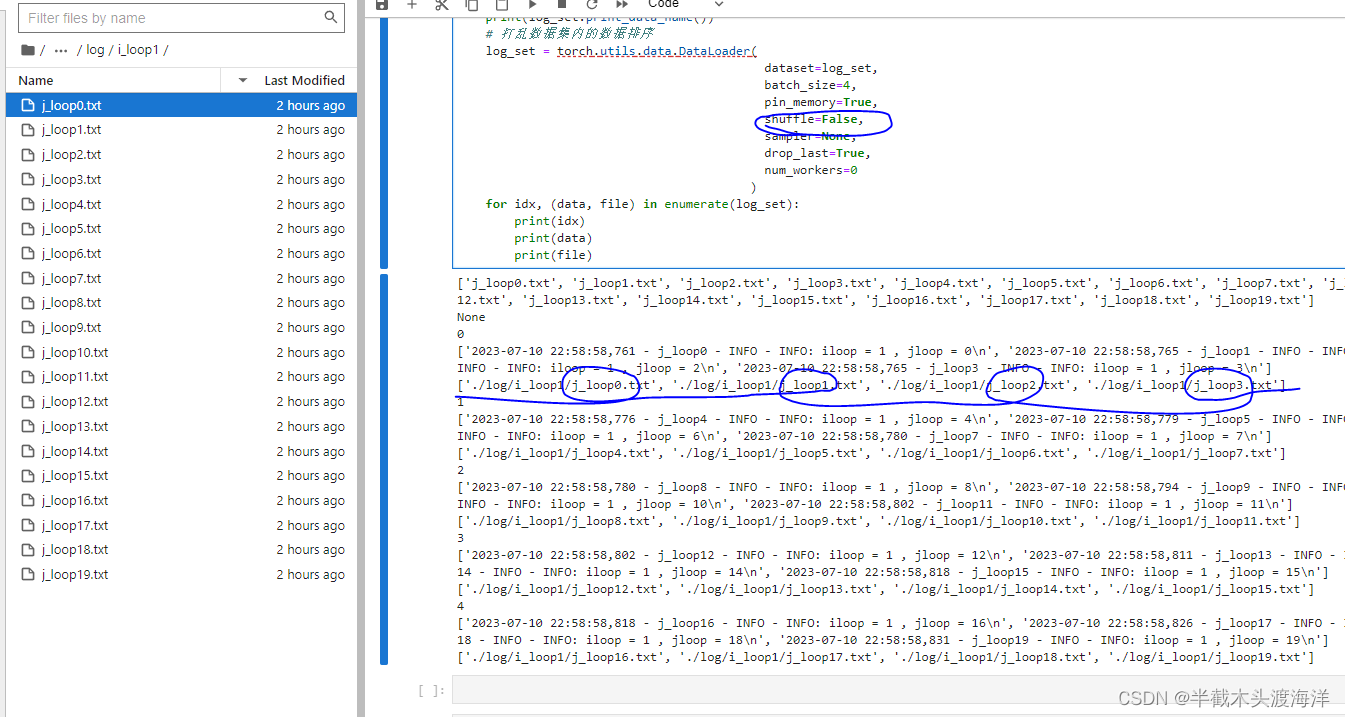
随机的批量遍历数据