导航:
【Java笔记+踩坑汇总】Java基础+进阶+JavaWeb+SSM+SpringBoot+瑞吉外卖+SpringCloud+黑马旅游+谷粒商城+学成在线+MySQL高级篇+设计模式+常见面试题+源码_vincewm的博客-CSDN博客
目录
一、底层
1.1 HashMap数据结构
1.2 扩容机制
1.3 put()流程
1.4 HashMap是如何计算key的?
1.5 HashMap容量为什么是2的n次方?
1.5.1 原因
1.5.2 扩容均匀散列演示:从2^4扩容成2^5
二、线程安全问题
2.1 HashMap线程安全吗?
2.2 线程安全的解决方案
2.3 JDK7扩容时死循环问题
2.3.1 死循环问题演示
2.3.2 JDK8是怎么解决死循环问题的?
2.4 JDK8 put时数据覆盖问题
2.5 modCount非原子性自增问题
一、底层
1.1 HashMap数据结构
JDK1.7及之前版本,HashMap底层是“数组+单向链表”。
在JDK8中,HashMap底层是采用“数组+单向链表+红黑树”来实现的,使用红黑树主要是为了提高查询性能。数组用作哈希查找,链表用作链地址法处理冲突,红黑树替换长度为8的链表。
1.2 扩容机制
HashMap中,数组的默认初始容量为16,这个容量会以2的指数进行扩容。具体来说,当数组中的元素达到一定比例的时候HashMap就会扩容,这个比例叫做负载因子,默认为0.75。
自动扩容机制,是为了保证HashMap初始时不必占据太大的内存,而在使用期间又可以实时保证有足够大的空间。采用2的指数进行扩容,是为了利用位运算,提高扩容运算的效率。
数组每个元素存的是链表头结点地址,链地址法处理冲突,若链表的长度达到了8,红黑树代替链表。
1.3 put()流程
put()方法的执行过程中,主要包含四个步骤:
- 计算key存取位置,与运算hash&(2^n-1),实际就是哈希值取余,位运算效率更高。
- 判断数组,若发现数组为空,则进行首次扩容为初始容量16。
- 判断数组存取位置的头节点,若发现头节点为空,则新建链表节点,存入数组。
- 判断数组存取位置的头节点,若发现头节点非空,则看情况将元素覆盖或插入链表(JDK7头插法,JDK8尾插法)、红黑树。
- 插入元素后,判断元素的个数,若发现超过阈值则以2的指数再次扩容。
其中,第3步又可以细分为如下三个小步骤:
1. 若元素的key与头节点的key一致,则直接覆盖头节点。
2. 若元素为树型节点,则将元素追加到树中。
3. 若元素为链表节点,则将元素追加到链表中。追加后,需要判断链表长度以决定是否转为红黑树。若链表长度达到8、数组容量未达到64,则扩容。若链表长度达到8、数组容量达到64,则转为红黑树。
哈希表处理冲突:开放地址法(线性探测、二次探测、再哈希法)、链地址法
1.4 HashMap是如何计算key的?
key=value&(2^n-1) #结果相当于value%(2^n),使用位运算只要是为了提高计算速度。例如当前数组容量是16,我们要存取18,那么就可以用18&15==2。相当于18%16==2.
put()里,计算key的部分源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // 此处省略了代码 // i = (n - 1) & hash] if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // 省略了代码 } }
1.5 HashMap容量为什么是2的n次方?
1.5.1 原因
计算value对应key的Hash运算:
key=value&(2^n-1)#结果相当于value%(2^n)。例如18&15和18%16值是相等的2^n-1和2^(n+1)-1的二进制除了第一位,后几位都是相同的。这样可以使得添加的元素均匀分布在HashMap的每个位置上,防止哈希碰撞。
例如15(即2^4-1)的二进制为1111,31的二进制为11111,63的二进制为111111,127的二进制为1111111。
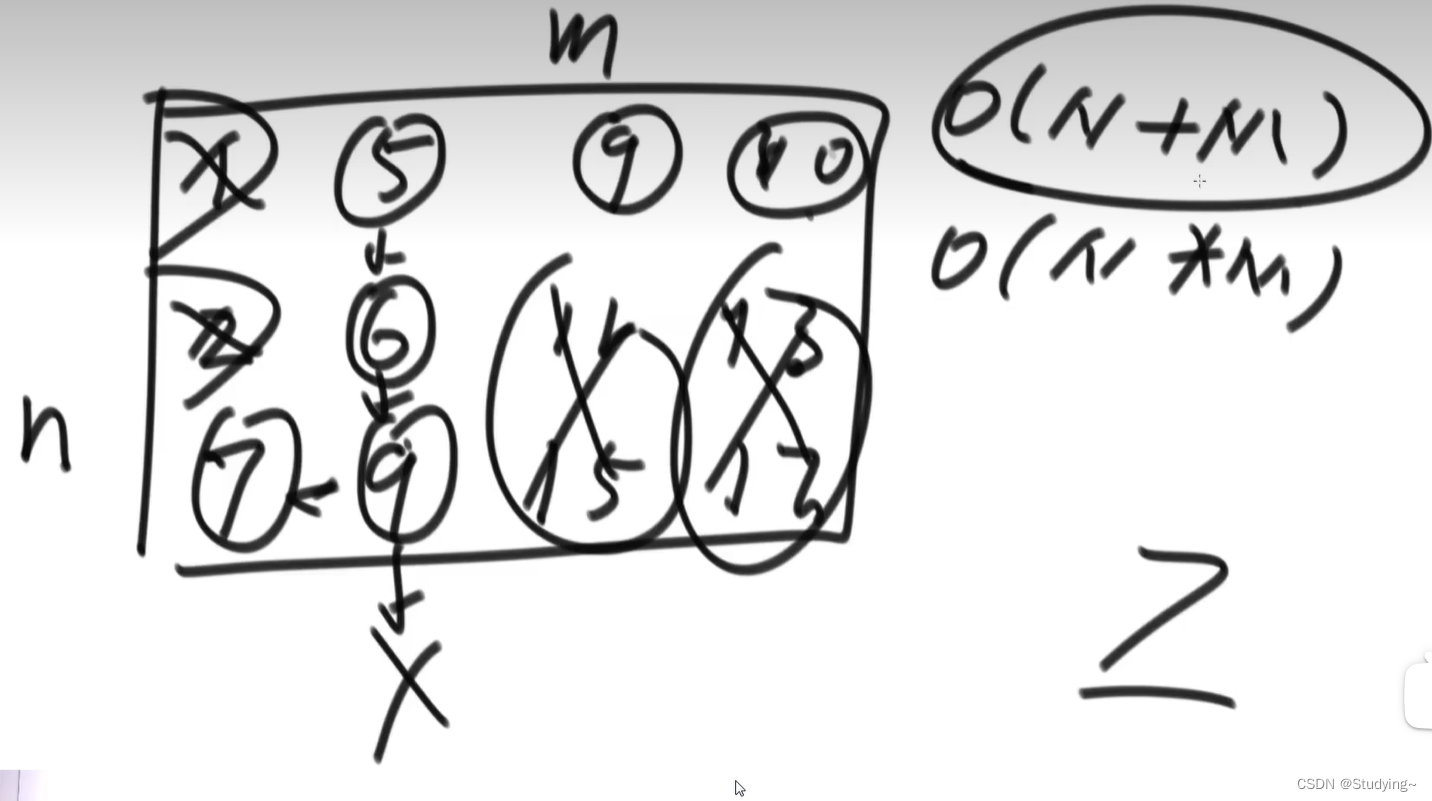
1.5.2 扩容均匀散列演示:从2^4扩容成2^5
0&(2^4-1)=0;0&(2^5-1)=0
16&(2^4-1)=0;16&(2^5-1)=16。所以扩容后,key为0的一部分value位置没变,一部分value迁移到扩容后的新位置。
1&(2^4-1)=1;1&(2^5-1)=1
17&(2^4-1)=1;17&(2^5-1)=17。所以扩容后,key为1的一部分value位置没变,一部分value迁移到扩容后的新位置。
用取余演示扩容:
如果觉得与运算有点难理解,我们可以用取余演示:
假设从16扩容到32:1%16=1,17%16=1;1%32=1,17%32=17。
1和17本来key都是1,扩容后1的key还是1,17的key变成17。这样原来key为1的value就均匀的散列在扩容后的哈希表里了(一部分value不变,一部分value移动到扩容后新位置)。
二、线程安全问题
2.1 HashMap线程安全吗?
HashMap是线程不安全的,多线程环境下可能出现死循环问题、数据覆盖问题。
多线程下建议使用Collections工具类和JUC包的ConcurrentHashMap。
2.2 线程安全的解决方案
- 使用Hashtable(古老api不推荐)
- 使用Collections工具类,将HashMap包装成线程安全的HashMap。
Collections.synchronizedMap(map); - 使用更安全的ConcurrentHashMap(推荐),ConcurrentHashMap通过对槽(链表头结点)加锁,以较小的性能来保证线程安全。
- 使用synchronized或Lock加锁HashMap之后,再进行操作,相当于多线程排队执行(比较麻烦,也不建议使用)。
2.3 JDK7扩容时死循环问题
2.3.1 死循环问题演示
单线程扩容流程:
JDK7中,HashMap链地址法处理冲突时采用头插法,在扩容时依然头插法,所以链表里结点顺序会反过来。
假如有T1、T2两个线程同时对某链表扩容,他们都标记头结点和第二个结点,此时T2阻塞,T1执行完扩容后链表结点顺序反过来,此时T2恢复运行再进行翻转就会产生环形链表,即B.next=A; A.next=B,从而死循环。
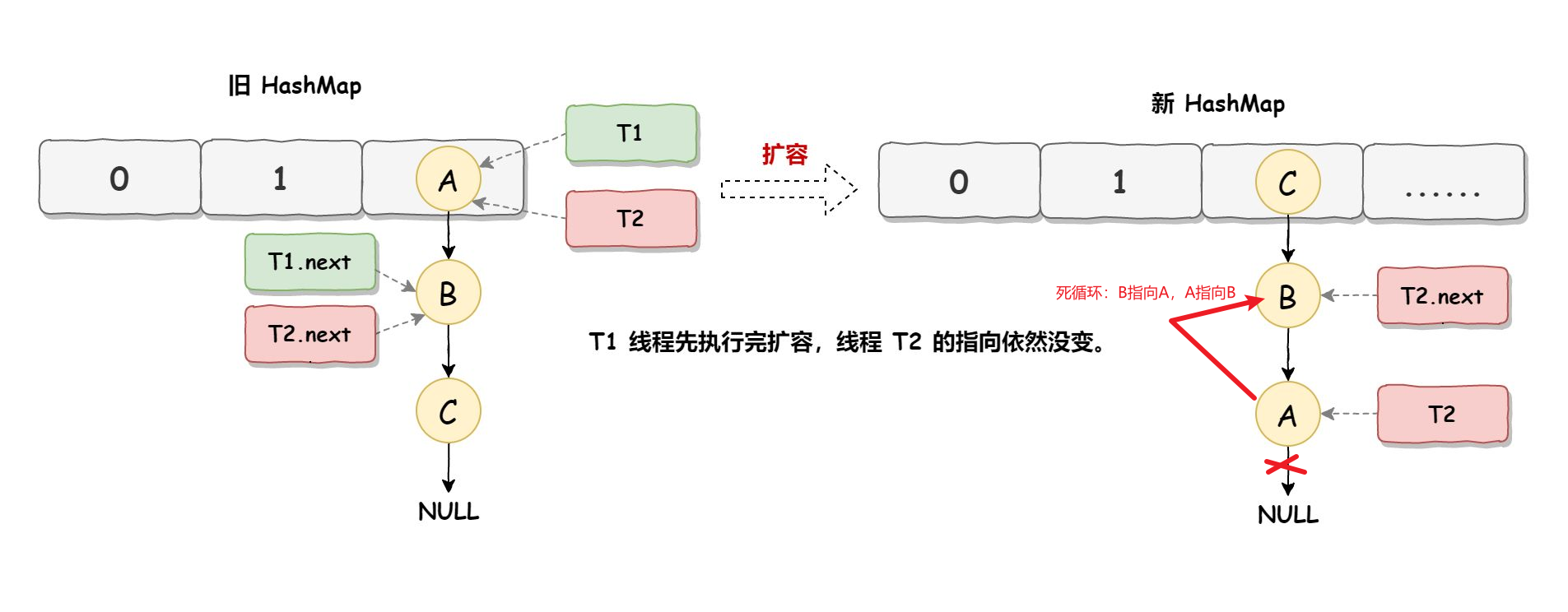
2.3.2 JDK8是怎么解决死循环问题的?
JDK8 尾插法解决了死循环问题。
JDK8中,HashMap采用尾插法,扩容时链表节点位置不会翻转,解决了扩容死循环问题,但是性能差了一点,因为要遍历链表再查到尾部。
例如A——>B——>C要迁移,迁移时先移动头结点A,再移动B并插入A的尾部,再移动C插入尾部,这样结果还是A——>B——>C。顺序没变,扩容线程
2.4 JDK8 put时数据覆盖问题
HashMap非线程安全,如果两个并发线程插入的数据hash取余后相等,就可能出现数据覆盖。
线程A刚找到链表null位置准备插入时就阻塞了,然后线程B找到这个null位置插入成功。借着线程A恢复,因为已经判过null,所以直接覆盖插入这个位置,把线程B插入的数据覆盖了。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 如果没有 hash 碰撞,则直接插入
tab[i] = newNode(hash, key, value, null);
}
2.5 modCount非原子性自增问题
modCount: HashMap的成员变量,用于记录HashMap被修改次数
put会执行modCount++操作,这步操作分为读取、增加、保存,不是一个原子性操作,也会出现线程安全问题。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//put会执行modCount++操作,这步操作分为读取、增加、保存,不是一个原子性操作,也会出现线程安全问题。
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}