量化策略开发,高质量社群,交易思路分享等相关内容
一、相关性和平稳性
1、相关性
(1)皮尔森相关系数
皮尔森相关系数是最常见、最常用的一个相关系数计算方法。作为衡量两个随机变量x和y线性相关程度的重要指标,在这里不再赘述。
(2)斯皮尔曼相关系数
斯皮尔曼相关系数是基于随机变量秩的相关系数,该方法基于秩的理论,不需要假设变量之间是线性关系,也不需要对原始数据直接进行计算,而是将原始数据的秩作为变量计算斯皮尔曼相关系数。这句话看着挺拗口,并且抽象的,下面我会解释。
在给定一组数对(X1, Y1),...,(Xn,Yn)之后,要计算他们所代表的二元变量x和y的相关性,首先将x和y的变量值进行排序,分别得各自的秩统计量(r1,s1)...(rn,sn)。
斯皮尔曼相关系数是一种非参数相关分析方法,用于测量两变量之间的monotonic相关关系。在统计学和相关分析中,monotonic是指两个变量之间的关系呈单调变化趋势。也就是说,当一个变量增加时,另一个变量也增加;或当一个变量减少时,另一个变量也减少。
monotonic关系可以是:
1、 正相关—— 两个变量均增加或减少。例如:身高和体重。
2、 负相关—— 一个变量增加而另一个变量减少。
我们举例来说,价格和需求量,Spearman相关系数就是用于测量两个变量之间的monotonic相关关系的统计指数。因为它通过变量的rank比较两变量的协同变化,而不受变量的线性相关性影响。相比之下,Pearson相关系数测量的是线性相关关系,它要求变量满足正态分布,且两变量间存在线性关联。所以,总结来说:Monotonic相关关系是指两个变量的变化趋势是单调的,要么同向增加要么同向减少。它可以是正相关或负相关。- Spearman相关系数用于测量monotonic相关关系。- Pearson相关系数用于测量线性相关关系,它要求变量满足正态分布。- Monotonic相关关系概念更广,线性相关关系属于monotonic相关关系的一种特例。
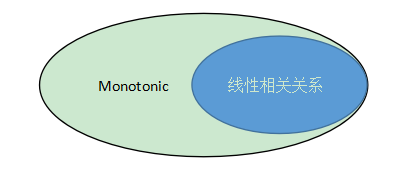
可以用这个客观但可能不是很严谨的图来理解一下。
它的计算原理和逻辑如下:
-
对数据集中的每个样本进行rank转换。也就是将每个变量的值映射到其相对大小的排名上,排名从1开始。
-
计算每个样本在两个变量上的rank差值的平方和。
-
计算rank差值的平方和之和。
-
计算每个变量的rank值之和。
-
将上述求和结果代入Spearman相关系数的公式:ρ = 1 - 6*∑d2 / (n(n2-1))这里ρ表示Spearman相关系数,d表示rank差值,n表示样本量。
举例说明:
有5个样本,变量x的观测值为[15, 20, 40, 10, 50],变量y的观测值为[20, 10, 60, 5, 30]。
-
对两个变量的观测值进行rank转换:x: [15, 20, 40, 10, 50] => [2, 3, 4, 1, 5]y: [20, 10, 60, 5, 30] => [3, 2, 5, 1, 4]
-
计算rank差值的平方和:
(2-3)2 = 1 (3-2)2 = 1
(4-5)2 = 1 (1-1)2 = 0
(5-4)2 = 1
∑d2 = 1 + 1 + 1 + 0 + 1 = 4
-
x的rank和 = 2 + 3 + 4 + 1 + 5 = 15
y的rank和 = 3 + 2 + 5 + 1 + 4 = 154.
-
ρ = 1 - 6*4 / 5*(5^2 - 5) = 1 - 0.2 = 0.8所以,在对数据分析过程中出现的错误进行修正后,x和y之间的Spearman相关系数ρ = 0.8。这表明x和y之间存在中等程度的monotonic相关关系。当x的值增大时,y的值也呈增大变化的趋势。
Spearman相关系数计算步骤:
-
对两个变量的观测值进行rank转换,将值从小到大排序并分配排名
-
计算rank差值的平方和∑d2
-
计算两个变量的rank值之和
-
将结果代入Spearman相关系数公式:ρ = 1 - 6*∑d2 / (n*(n^2-1)) ρ的值在0到1之间,值越大表示两个变量之间的monotonic相关关系越强。
(3)肯德尔相关系数
肯德尔相关系数是一种非参数相关分析方法,用于测量两个变量之间的秩相关。它通过计算变量的一致对数和非一致对数来度量两变量之间的相关性。与Pearson相关系数不同,肯德尔相关系数不要求变量遵循任何特定的分布,也不要求线性关系。它通过变量观测值的排列来判断变量变化的一致性,因此也称为秩相关系数。
在给定一组数对儿(X1,Y1),...(Xn,Yn)之后,若乘积(Xi- Xj)(Yi-Yj)>0,则称对子(Xi, Yi)与(Xj, Yj)为协同的,若乘积(Xi- Xj)(Yi-Yj)<0,则称该对子为不协同。
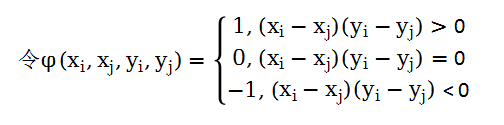
设nc是x与y协同的对子,nd是不协同的对子数,那么肯德尔系数定义为:
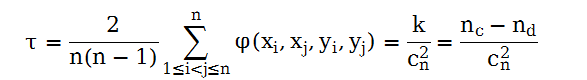
上述公式也可以用另外一种估算逻辑表示:
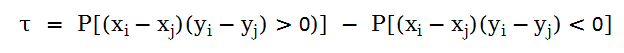
下面我们绘制一下贵州茅台和五粮液的月收益率散点图,如下图所示:
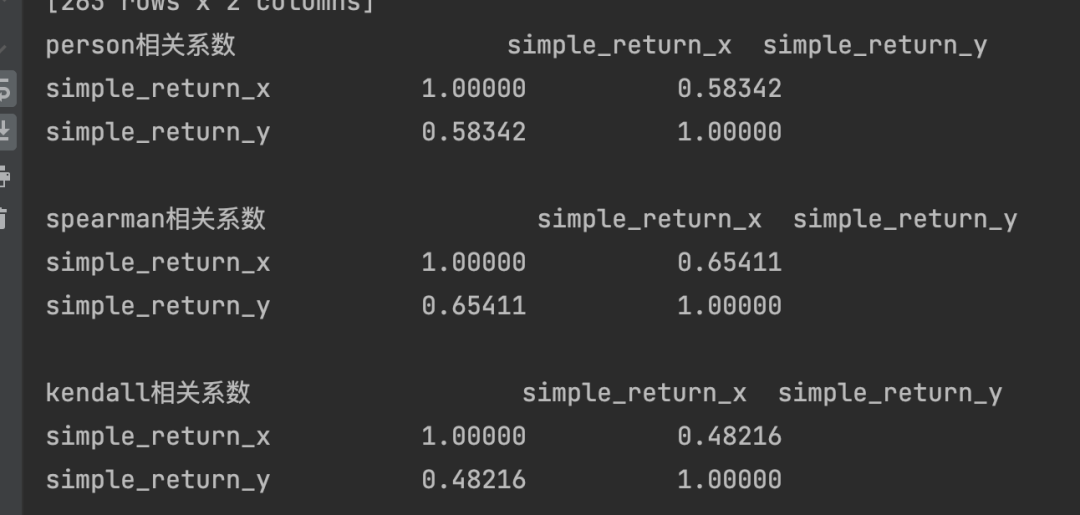
下面是两个股票的3种不同的相关系数计算,如下图所示:
2、平稳性
平稳性是时间序列的基础,判断一个序列是否平稳非常重要,对时间序列进行平稳性检验主要基于以下两方面的考虑。
首先,时间序列的平稳性可以替代随机抽样假定,采用平稳时间序列作为样本,建立计量经济学模型,在模型设定正确的前提下,模型随机扰动项仍然满足极限法则和经典模型的基本假设
其次,平稳时间序列建立计量经济学模型,可有效减少虚假回归。
时间序列一般分为若平稳和强平稳。
(1)平稳过程
如果一个时间序列{xt}的均值、方差在时间过程上保持常数,并且在任意两时期内的协方差仅依赖该两期间的距离或滞后阶数,而不依赖于计算这个协方差的实际时间,则称时间序列{xt}是弱平稳的。弱平稳的时间序列具有如下性质:
A、均值E(xt)=μ是与时间t无关的常数
B、方差Var(xt)=σ2是与时间t无关的常数
C、协方差Cov(xt,xt+k)=γk是只与时间间隔k有关、与时间t无关的常数如果对所有t,任意正整数m和任意n个正整数(t1,...t2),(xt1,...,xtn)的联合分布与(xt1+m,...,xtn+m)的联合分布都是相同的,则称时间序列{xt}为严平稳。
由此,如果一个时间序列概率分布的所有矩阵都不随着时间变化,那么它就是严平稳的;如果仅是一阶矩阵和二阶矩阵不随时间变化,那么他就是弱平稳的。
(2)自协方差函数
在给定的整数k,称协方γk=Cov(xk,xt-k)差是时间序列{xt}的间隔为k的自协方差,即:
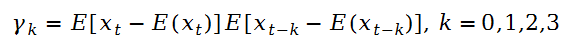
自协方差也称为自协方差函数,应用柯西-施瓦茨不等式,容易证明γk存在并且也具有时间不变性,也就是说,对于一个平稳时间序列,他只依赖于k。自协方差γk具有两个重要性质,即γ0=Var(xt)且γk=γ-k。
(3)自相关函数及其检验
给定一个随机时间序列,首先通过该序列的时间序列图来粗略判断他是不是平稳的,一个平稳的时间序列在图形上往往表现为一种围绕其均值不断波动的过程,而非平稳的的时间序列往往表现出不同时间段具有不同的均值。然而,这种直观的图形属于定性,需要定量数据进一步验证,通常做法是检验样本自相关函数。
自相关函数定义,考虑时间序列{xt},当xt与它过去变量值xt-k线性相关,可以把相关系数的概念推广到自相关系数,xt与xt-k的相关系数称为xt的间隔为k的自相关系数,通常记为ρk。
因为xt为弱平稳的,所以有Var(xt-k)=Var(xt)。根据定义,我们有ρ0=1,ρ1=ρ-1和-1≤ρ1≤1。自相关系数组成的集合{ρt}称为{xt}的自相关系数。一个弱平稳的时间序列是序列{xt}自身前后不相关的,当且仅当对所有k>0,有ρk=0。

下面我们来学习一个经典的自相关性检验——“Ljung-Box”检验,根据上个式子定义的统计量
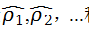
称为x的样本自相关函数。这个函数
在线性时间序列分析中起着重要作用,一个线性时间序列模型可完全由其 acf来刻画。并且线性时间序列的建模由样本acf决定数据的线性动态关系。在许多金融应用中,我们经常需要联合检验的多个自相关系数是否同时为0。也就是检验:
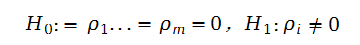
这里我们需要利用LB检验,统计量公式如下:
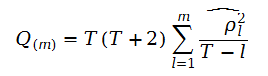
可以证明Q统计量近似服从自由度m的x2分布,在实际检验中,通常会计算出不同滞后阶数的Q统计量、自相关系数和偏自相关系数。一般取m = ln(T)。类似地,可采用P值来判断是否拒绝原假设。其中T代表数据观测值。
这就是我们经常所看到的LB检验,Ljung-Box检验(也称Q检验)是检验时间序列是否为白噪声序列的常用方法。它通过检验时间序列的自相关系数是否显著来判断序列的随机性,进而判断是否为白噪声序列。
Ljung-Box检验的基本思想是:
-
计算一定滞后阶数内的自相关系数,得到k个自相关系数r1, r2, ..., rk。
-
假设原始序列为白噪声序列,则理论上这k个自相关系数应当为0。
-
计算统计量Q,表达这k个自相关系数的总偏差程度:Q = n(n+2) ∑(rij)2 / (n-i)(i = 1, 2, ..., k) (n是序列长度)
-
根据自由度k和置信水平α选择临界值c,如果Q > c,则拒绝原假设,认为序列不为白噪声序列。
-
如果Q <= c,则无法拒绝原假设,无法证明序列不是白噪声序列。
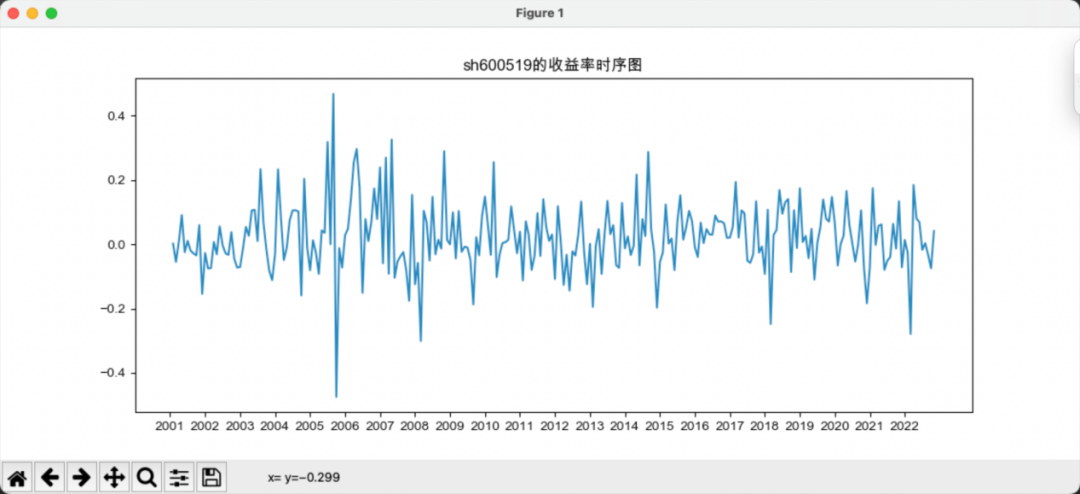
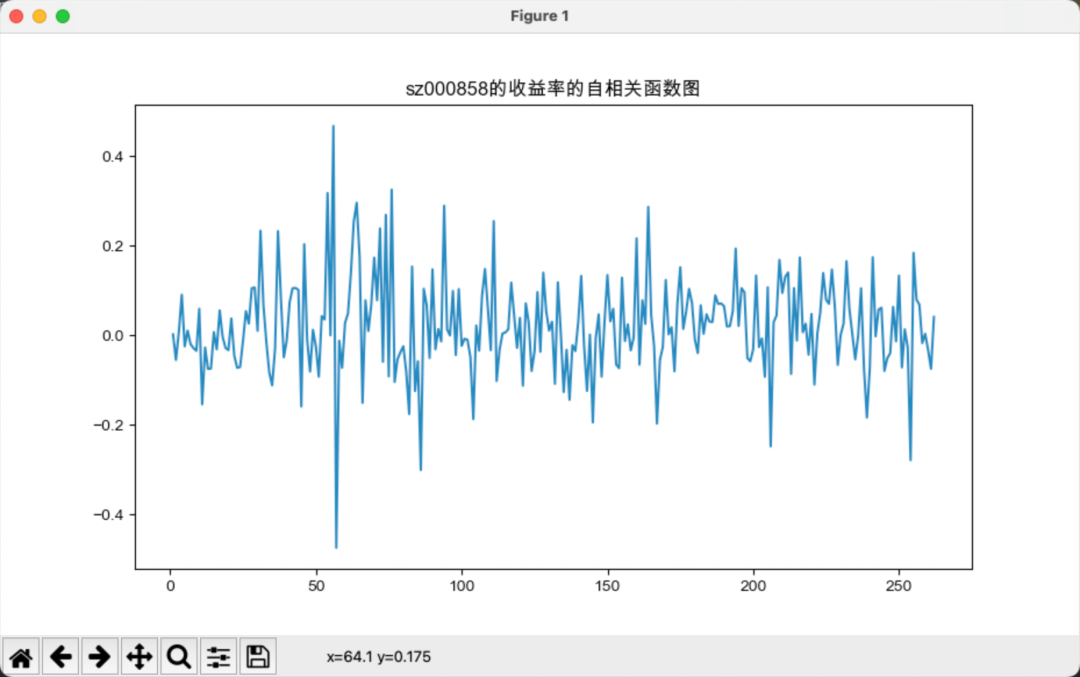
上图所示为“贵州茅台”的月收益率时序图,下图为“贵州茅台”和“五粮液”收益率序列的acf图。
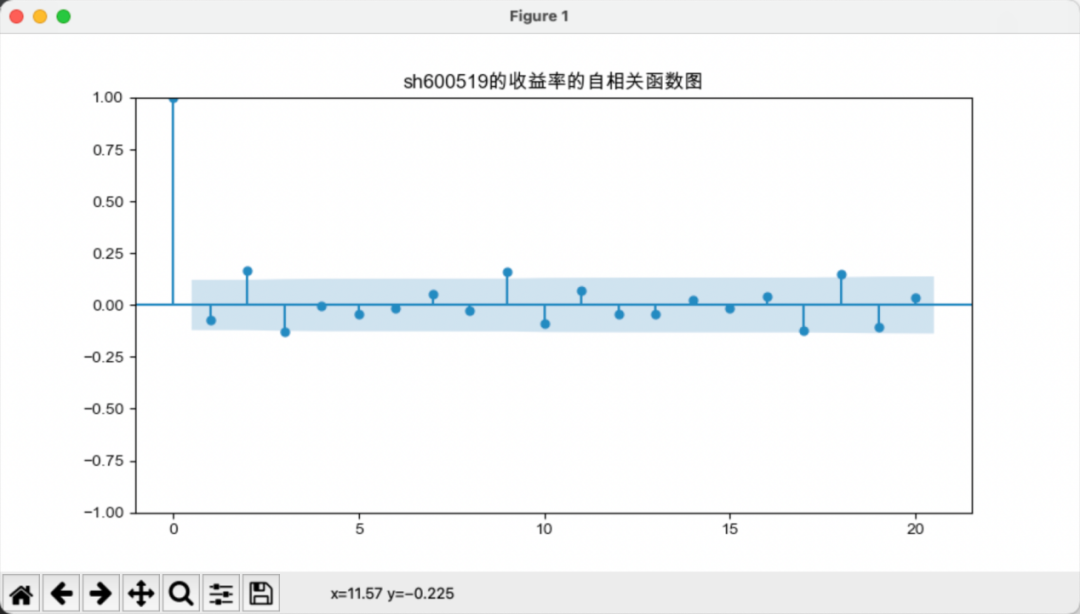
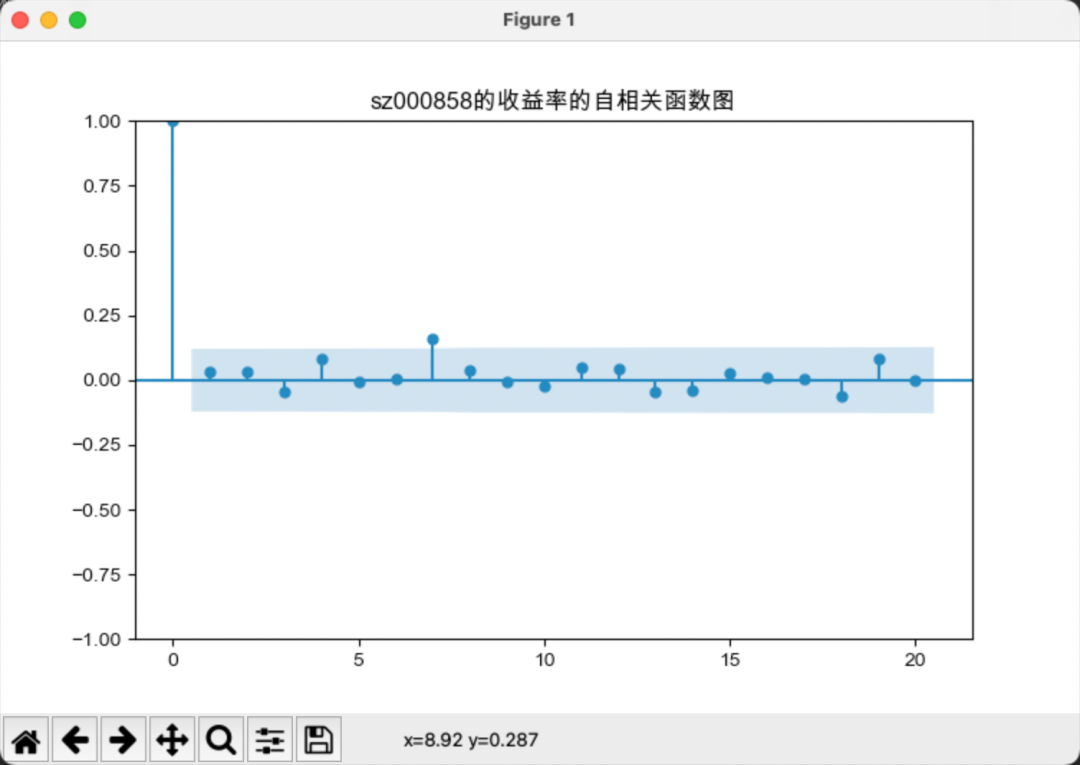
我们可以从以下几个方面解读自相关图:
-
自相关系数的大小:自相关系数的绝对值大小反映了同一时间序列上两个滞后观测值之间的线性相关性。其值在[-1, 1]区间,值越大表示相关性越强,值为0表示无相关性。
-
自相关系数的正负:自相关系数的正负号表示两个滞后观测值变化的方向性。正值表示同方向变化,负值表示相反方向变化。
-
自相关系数的下降速度:自相关系数随滞后阶的下降速度反映时间序列的随机性。下降越缓慢,时间序列越趋近非随机性。白噪声序列的自相关系数下降最快。
-
显著滞后阶:自相关系数较大的滞后阶可能反映时间序列的周期性成分。例如,滞后12阶较大可能表示年周期影响,滞后4阶较大可能表示季度周期影响。
-
置信区间:自相关系数超出置信区间的滞后阶可能较具统计显著性,反映时间序列的非随机性成分。但置信区间也与样本量相关,样本量较小时更容易超出置信区间。
下面我们通过LB统计量进行自相关性检验案例分析,根据

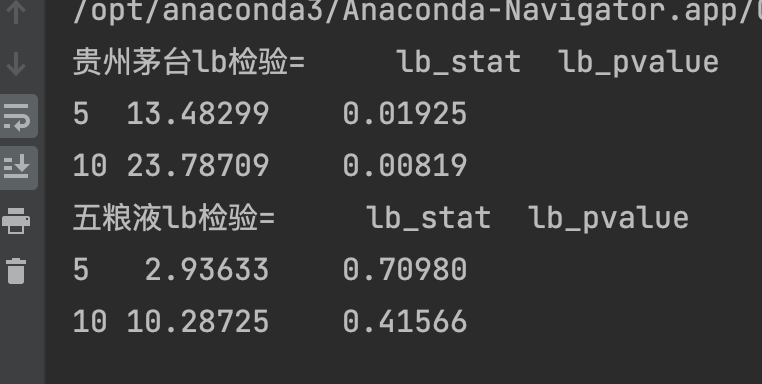
Ljung-Box统计量表明,在0.05的显著水平下,贵州茅台可以拒绝原假设,但是五粮液不可以,即支持五粮液月简单收益率没有相关性的假设。换句话说,是白噪声。
二、简单自回归模型
顾名思义,自回归模型就是变量对变量自身的滞后项进行回归。当xt具有统计显著的滞后为1的自相关系数时,滞后xt-1值可能会在预测xt时有用,设
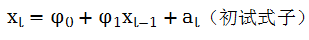
其中{at}是均值为0,方差为σ2的白噪声序列,上述模型称为一阶自回归模型,或简称AR(1)模型。
AR(1)模型有若干类似简单线性回归模型的性质,在弱平稳假定下,在过去收益率xt-1已知的情况下,由AR(1)模型可推:
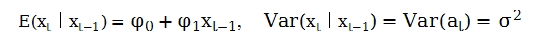
即给定过去收益率xt-1,本期收益率将以φ0+φ1xt-1为中心,以标准差σa上下波动。
一般地,AR(p)模型定义为:
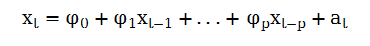
其中p为非负整数,{at}的定义与上面一样,AR(p)模型与以p个滞后项作为解释变量的多元线性回归有相同形式。
1、AR模型性质
本文从AR(1)和AR(2)模型入手,分析AR模型的基本性质。
(1)AR(1) 模型
假定序列{xt}是弱平稳的,则E(xt) = μ,Var(xt)=γo,Cov(Xt,Xt-1 )=γj,其中μ和γo是常数,γj是与j 的函数而与t无关。对“初试式子”两边求期望,因为E(at) =0,因此

在序列平稳的条件下,E(xt) =E(xt-1) =μ,从而
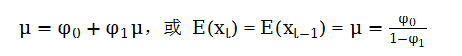
这个结果对xt有两个含义:第一,若φ1≠1,则xt的均值存在;第二,xt的均值为0当且仅当φ0=0。因此对平稳AR(1)过程,常数项φ0与xt的均值无关,φ0=0意味着E(xt)=0
利用φ0=(1-φ1) μ我们可以把AR(1)模型写成如下形式:

其中xt代表t时期的数据,xt-1代表t-1时期的数据,μ称为均值参数,at代表随机误差项。φ1代表影响系数,表示上一期数据对当前期数据的影响程度。
实际上就是将φ0=(1-φ1) μ这个公司代入“初试式子”中求的上式重复迭代,由上述方程可推:
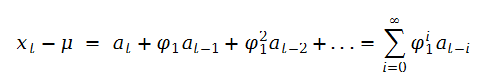
这块给大家手推了,如下图所示:
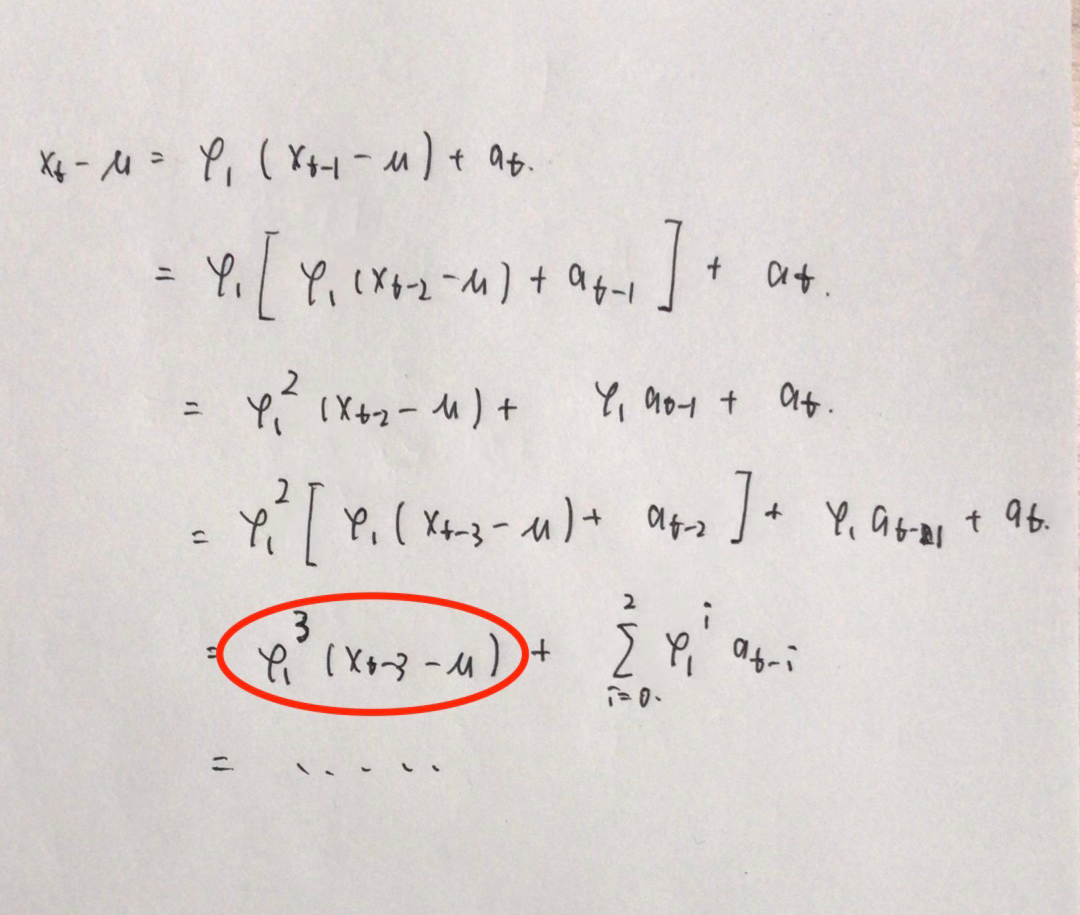
注:里面的...就是红色圆圈。
因此,xt-μ是at-i的线性函数。利用这个性质和{at}的独立性,我们有E[(Xt-μ)at+1]=0,根据平稳性假定,我们有Cov(Xt-1,at)= E[(Xt-1-μ)at]= 0,对AR(1)模型两边平方后取期望,得到:
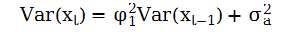
在平稳性对假定下,Var(xt)=Var(xt-1)因此
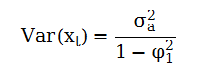
当
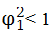
时成立,因此,由AR(1)模型的弱平稳性可推出-1<φ1<1,反之,若abs(φ1)<1,可以证明xt的均值、方差和自协方差是有限的,从而AR(1)模型是弱平稳的。
因此,AR(1)模型充分必要条件是abs(φ1)<1。
在AR(1)模型两边乘at,在取期望,利用at与xt-1的独立性,可得:
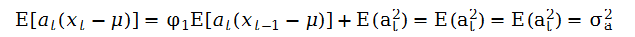
其中,
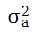
是at的方差,AR(1)模型两边同乘(xt-1-μ)后取期望,再利用上述结果可得:
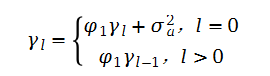
这里利用γ1=γ1-1了这个性质。因此,对弱平稳AR(1)模型,
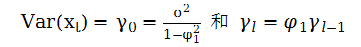
由后一个方程,xt的自相关函数ACF满足

因为ρ0=1,所以有
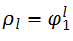
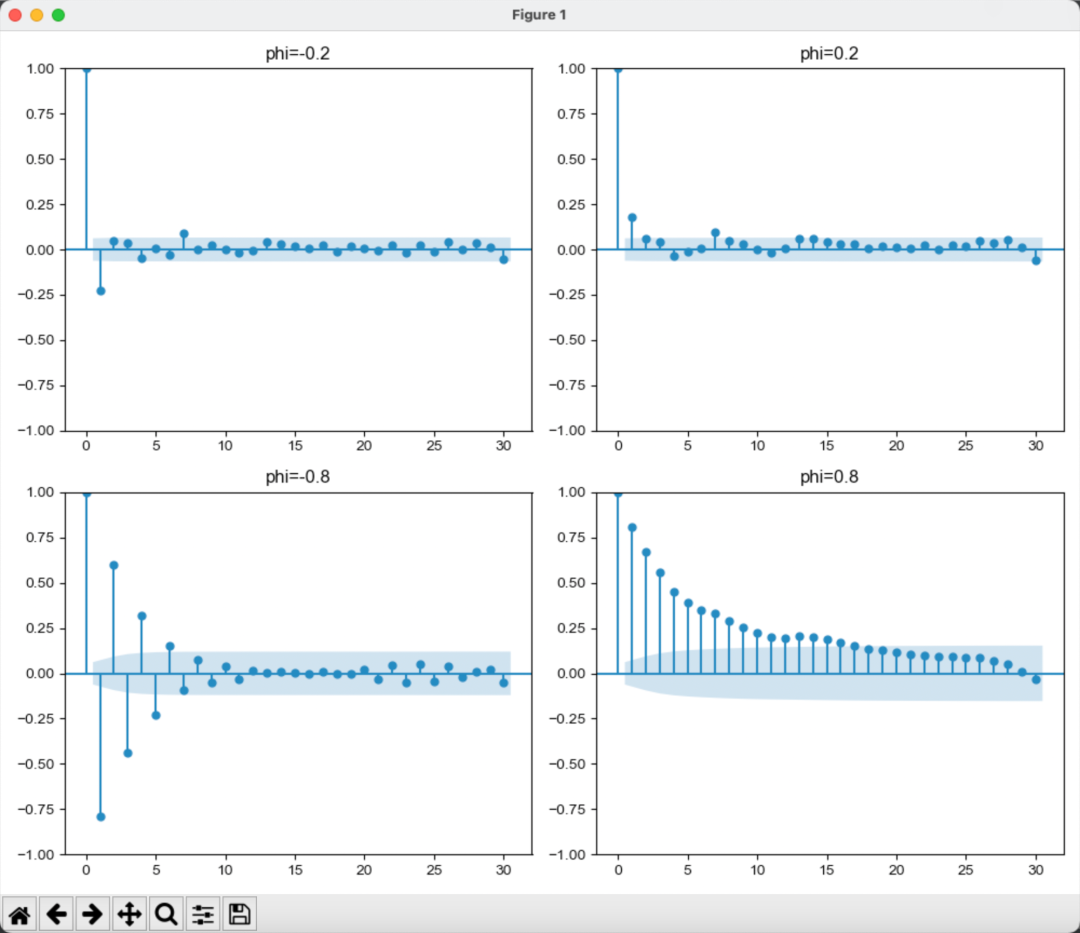
。这个性质表明弱平稳AR(1)序列的自相关函数从ρ0=1开始以比率为φ1的指数速度衰减。当φ1>0时,AR(1)模型的自相关函数图像呈现指数衰减。当φ1<0时,AR(1)模型的ACF由上下两个都以比率衰减的图像组成。
(2)AR(2)模型
AR(2)模型定义为xt=φ0+φ1xt-1+φ2xt-2+at
利用与AR(1)模型相同的方法可得到,只要,就有φ1+φ2≠1,就有
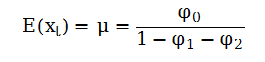
利用φ0=(1-φ1-φ2)μ,可把AR(2)改写为
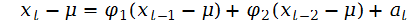
上式两端同乘xt-1-μ后取期望,并利用当L>0时E[(Xt-1-μ)at]=0.,可得
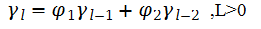
这个结果称为平稳AR(2)模型的矩方程,在上式两端同除以γ0,得到xt的ACF的性质:

因此,对平稳的AR(2)序列xt,我们
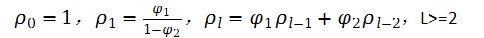
由xt的ACF公式,平稳AR(2)序列的ACF满足二阶差分方程

其中B是滞后蒜子,即Bρ1=ρ1-1。这个差分方程决定了平稳AR(2)序列的ACF性质,也决定xt了的预测能力。
与上面的差分方程对应的是二次多项式方程
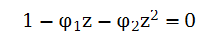
这个方程的解为
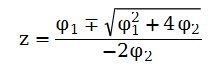
在时序文献中,称这两个解的倒数为AR(2)的特征根,用ω1和ω2来表示,如果都是实值,则模型的二阶差分能分解为(1-ω1B)(1-ω2B),这时xt的ACF是两个指数衰减的混合。如果
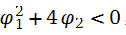
,则ω1和ω2都是复数,这时xt的ACF图形呈现出递减的正弦和余弦图像。
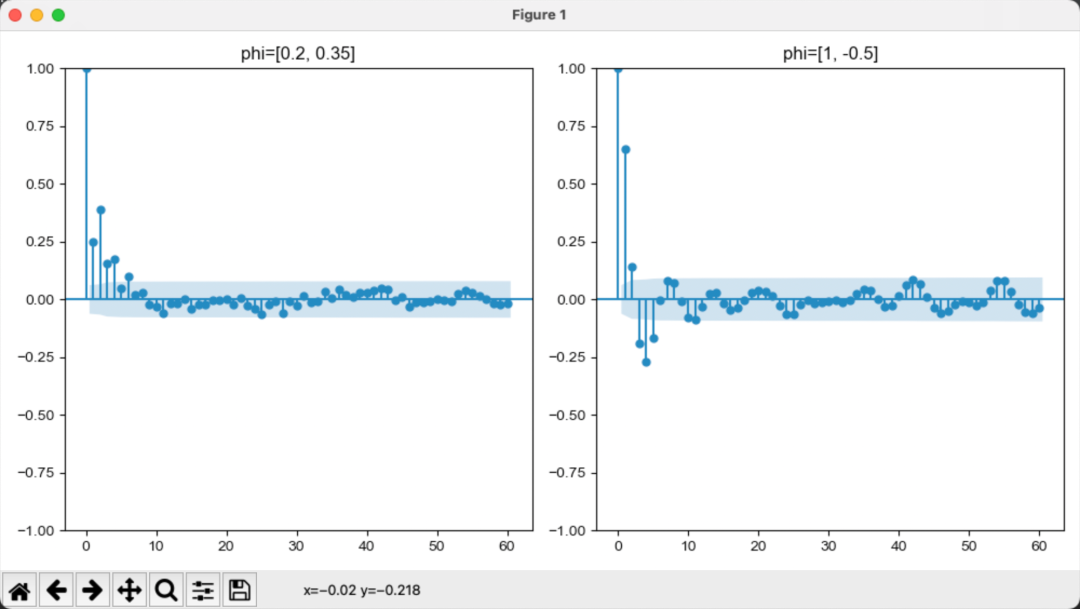
现在来考察AR(2)的平稳性。AR(2)满足平稳性的条件是它的两个特征根的绝对值都小于1,或者说,他的两个特征根的摸都小于1。因此,特征方程两个解的模都大于1。
在这里强调一点的是,方程的所有解的模都大于1,则序列xt是平稳的。同样,方程的解的倒数为该模型的特征根。因此,平稳性要求所有特征根的模都小于1。平稳AR(p)模型的自相关函数的图像呈现出减弱的正弦、余弦和指数衰减的混合状,具体形状取决于其特征根的性质。
今天先写到这里了,
文章相关数据和代码公众号后台回复“计量02”
由于各平台差异,回测绩效以QMT版本为准!!!
本策略仅作学习、交流使用,实盘交易盈亏投资者个人负责!!!