知识蒸馏作为一种压缩方法,与剪枝、量化中直接在原模型上进行参数的剪枝或数据位宽的降低来压缩不同,知识蒸馏方法往往是通过将大模型上的精度转移到一个相对更小的模型上来完成对大模型的压缩。此处所说的大模型即知识蒸馏中的教师模型,而相对更小的模型即学生模型。本文所研究的知识蒸馏方法是为了构成一个完整的YOLO v5模型压缩框架,所以其主要目的是为了提升剪枝后模型的精度值,进而获得利用较小模型达到更高检测精度的效果。鉴于此,在本文后续的研究中,所选择的学生模型均为剪枝后的模型,而教师模型则为该剪枝模型在未剪枝情况下的完整模型。
同时,如之前博客中知识蒸馏算法的相关研究现状一节中所述,目前知识蒸馏方法主要分为了三类,即基于相应的、基于特征的以及基于关系的知识蒸馏三种,鉴于基于特征的蒸馏方法需要在网络模型中添加连接器,而基于关系的蒸馏方法则大多需要构建关系矩阵,应用在复杂的目标检测认识模型上时,计算冗余且耗时较长,鉴于此,后文相关研究中将选择基于响应的知识蒸馏方法。
下面即以Hinton等人的工作为基础[125],阐述在图像分类任务模型上应用基于响应的知识蒸馏的主要思想,后文在YOLO v5剪枝模型上开展蒸馏也将以此为基础来进行。
基于响应的蒸馏方法中将教师模型最后一层全连接层的输出作为“目标知识”,也被称为Logits,其与分类网络最终的输出相比,区别仅在于没有经过Softmax函数处理,因此其非预测目标类别对应的输出位置值未被抑制为0。在分别计算得到教师模型与学生模型的Logits后,利用优化的带有温度系数T的Softmax函数来对Logits进行软化,进而得到软标签与软预测值,再利用这两者计算得到蒸馏损失值,具体计算过程如式2.15中所示。
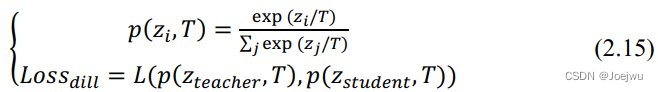
式2.15中,zi 即为Logits中第i 个类别的对应值,pzi,T 即为带有温度系数T的Softmax函数,损失函数L( ) 则一般采用KL散度计算。为了达到更好的“软化”效果,一般设置的温度系数T需要大于等于1,以便非目标类与目标类预测值之间的差距降低。在计算完蒸馏损失后,还需要按照正常网络训练中的流程计算学生模型在硬标签(即真实的标注数据)下的学生损失值。结合蒸馏损失值与学生损失值即可得到在知识蒸馏训练中的总损失值,如式2.16中所示。
![]()
式2.16中各损失值乘的系数一般需根据训练时的实际情况来确定,通常在图像分类任务中设置的α 要小于β ,以增强蒸馏损失的比重来加强蒸馏效果。